下面是我们整理的钱彦旻教授、张王优、李晨达在第二届SH语音技术研讨会和第七届Kaldi技术交流会的报告内容,如果有误,欢迎指正。

基本情况
今天我们主要是围绕ESPnet-SE这个工具做一个简单的介绍,我会大概讲一下ESPnet-SE的情况,然后后面的部分会由我的两位博士生张王优和李晨达给大家做一个详细的介绍。
要讲ESPnet-SE,那就离不开介绍一下ESPnet。我相信这几年大家对ESPnet已经用的越来越多也越来越熟悉了,就是所谓的End-to-end Speech Processing,ESP就是这几个单词的缩写。

ESPnet是CMU的Shinji Watanabe教授主导的一个开源项目,其实ESPnet很早就已经开始做了,他在MERL的时候就已经在做这套工具了,但那时候还不是很成熟,并且由于MERL的一些license问题所以还没对外围去做release,他去JHU之后可能各种东西都变得灵活,所以又做了很多的开发。刚开始的时候这个工具主要是做识别的,大家知道Shinji以前也主要做识别的,然后ESPnet的功能越来越丰富,现在是Text-to-speech(TTS)、Voiceconversion(VC)、Speechtranslation(ST)、Speechenhancement(SE&SS)等等各种模块都在往里面添加,所以它的整个支持的领域已经变得越来越广泛,基本上现在主流的Speech Processing的一些任务下如何去用Neural Nets做end-to-end modeling的这些事情在ESPnet这个大的工具包下都能找到,整个工具现在很完善,有3个特点,刚才讲了第一个特点——它现在有各种各样的功能支持。
我们的SE其实也只是ESPnet下的一个子工具包,还有很多其它任务,这里列了一些,还有很多也在后续的计划中,相当于是一个one-in-all的recipe的形式。
它跟Kaldi其实也蛮相像的,从数据处理到特征提取到模型的training到inference和evaluation还有最后模型的sharing等等都有一套完整的recipe。对每一个benchmark都基本是这样规划的,它模块化的设计是比较灵活的,现在主流的一些architecture包括RNN、Transformer、Conformer等等,或者说在enhancement当中用的比较多的TCN、U-Net等等对这些主流的组件都有很好的支持。然后包括对On-the-fly feature extraction and preprocessing这些处理方式,它里面也有很好的工具。还包括它对多机多卡的并行化处理等等。现在整个ESPnet的license都是比较开放的,都是基于Apache 2.0的。大家可以看到它在GitHub上的stars已经到5.7k了,虽然跟Kaldi还有很大的差距,毕竟Kaldi已经这么多年了,但除了Kaldi之外,在现在语音处理领域一些主流工具中,比如说ESPnet、SpeechBrain、Wenet等等,ESPnet还是算排最高的,所以大家可以看到它现在在学术界和工业界的地位还是比较明显的。
当然一个好的工具包除了有好的工具和易读的代码之外,它还应该有很好tutorials ,这里大概列了一下,大家如果感兴趣的话可以去看一些参考的documents或者教程,另外,Shinji在去年和今年它在JHU的课程上也有比较完整地对ESPnet的介绍和demo使用方面的一些介绍。

刚刚也讲了,SE其实是ESPnet这一系列子工具中的一部分,也是目前主流的这个语音信号处理的重要的部分。这里所指的speech enhancement其实是比较宽泛的,包括了denoising、dereverberation、separation,这几个模块从single microphone到multi microphone array这都是包含的,所以大家要知道现在我们的ESPnet-SE,既可以做基本的降噪也可以做去混响还可以做人声分离或者多元的其它声源的分离;它既支持单麦下的一些处理的模型或方法,也支持多麦的一些方法,基本上都提供了一些比较主流的SOTA的一些结果或者recipe。
下面三篇文章是针对ESPnet-SE到目前主要可参考的文章,等会张王优会介绍下整个数据库的发布的历史。

在2020年我们就开始一起做了,在2021年1月的SLT我们正式发布这篇文章,前三位作者分别是李晨达、张王优、还有自动化所的石晶,这三位同学是当时主要的开发者,在文章上标的也是equally contribution。在这之后陆续还有两篇文章,包括我们在今年的InterSpeech上还有一篇ESPnet-SE++的文章,这些都是后续的一些工作。
到目前为止,整个ESPnet-SE的一些模块和recipe都是比较完善的,包括一些现在比较典型的方法,里面都有实现。包括Shinji、我们组、还有其它组最近做的一些新的技术,基本上在里面都会有比较及时的deliver,包括我们2019年做的,那篇best paper的MIMO的这一套东西在里面也都有release。
以上就是基本情况的介绍,接下来把时间留给我的两位学生张王优和李晨达,由他们来围绕以下四个部分来做主要的介绍:发展历程、特色功能、样例展示、未来展望。
发展历程
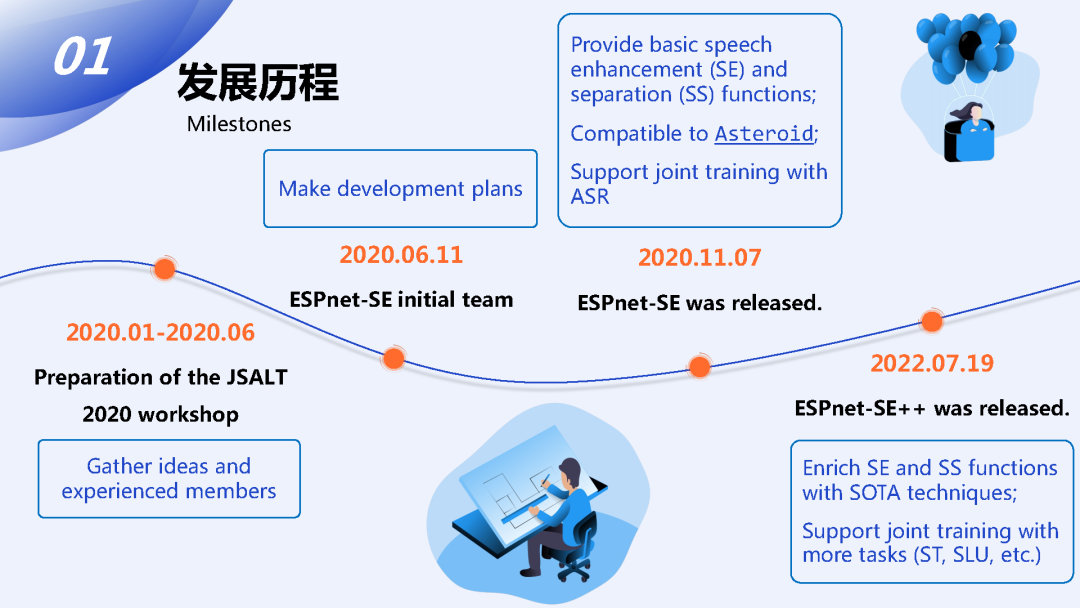
我是张王优,下面我来给大家介绍一下ESPnet-SE这个工具包的发展历程,最初的时候是在2020年的上半年的时候,我和李晨达以及钱老师在准备JSALT 2020 workshop,在准备期间我们和CMU以及来自其他地区的研究者进行了讨论,然后发现目前缺少一个比较完善的具有增强声乐前端处理的功能的工具包,所以在这个阶段我们就跟不同的研究者进行了沟通,收集了很多比较有用的idea,然后也聚集了一批比较有经验的研究者,那么在接下来的2020年的6月份我们就初步组建了最初的ESPnet-SE的小组并制定了相关的开发计划,并在当年年末的时候,最终发布了ESPnet-SE的初版的工具包,它提供了基本的SE的相关的功能并且支持跟另一个语音分离相关的工具包Asteroid的兼容,最后它也支持跟后端的ASR任务的联合优化,而到了今年年中的时候我们发布了第二个版本的ESPnet-SE叫做ESPnet-SE++,它进一步丰富了现有的ESPnet-SE的功能,加入了很多SOTA相关的方法,并且在联合训练方面也跟更多的下游任务比如语音翻译和口语语义理解进行了更深度的结合。
经过这两年半的开发ESPnet-SE能够支持这么多的功能,这离不开广大的贡献者,所以在这里我们也想借机感谢一下所有为这个项目提供代码的贡献者们。值得一说的是,这个代码里面除了第一位是Shinji Watanabe教授之外,贡献量前三的三个学生分别是我、李晨达以及我们实验室毕业的一位硕士生,目前他在CMU读博士,以及后面的两位同学也都是来自我们实验室,所以也感谢他们的贡献!
特色功能
接下来我来介绍一下这个工具包的主要的功能,前面提到它经过了一个发展的过程,所以它的功能也是一个逐渐完善的过程,最初的版本只支持一些基础的增强和分离的方法以及提供了一些比较受欢迎的术语集上的recipe,经过一段时间的开发之后在正式发布的版本里我们加入了跟下游ASR任务的紧密的结合,包括支持它跟ASR任务的联合评估和联合训练,增加了对Asteroid工具包的代码层面的兼容性。到了最新发布的版本,我们进一步加强了跟下游任务的结合,支持了更多的类似speech-to-text类型的任务的结合。

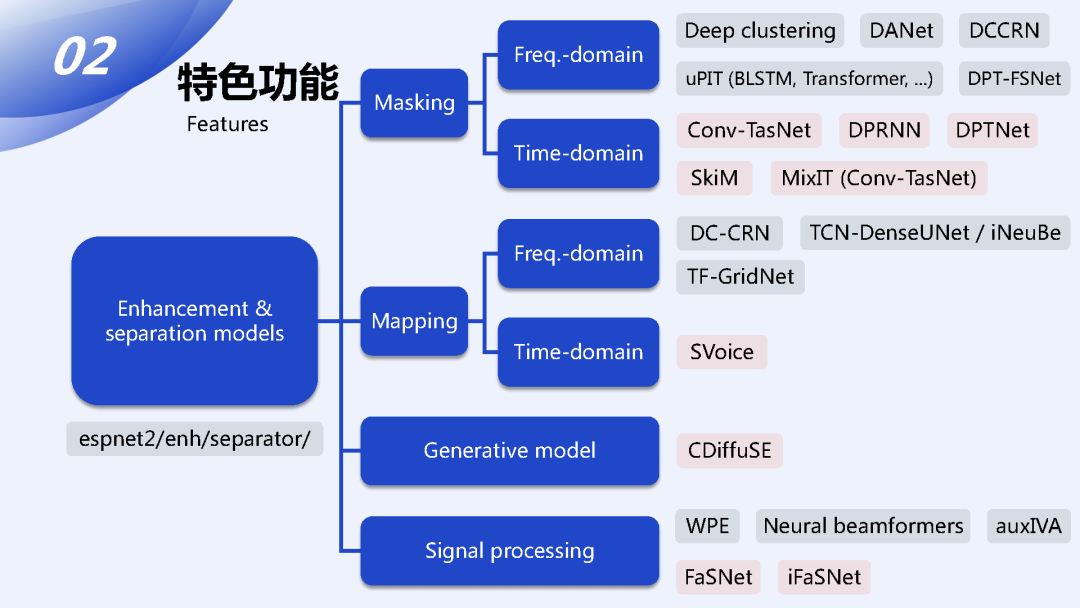
下面来具体看一下每一项功能支持的模型或方法。在模型方面,ESPnet里面所有支持的模型的实现都放在espnet2/enh/separator/ 这个数据目录底下,然后按照研究上的方法进行分类的话,我们把它归成了四大类:
-
基于Masking的方法
-
基于Mapping的方法
-
生成式的模型
-
跟信号处理紧密相关的方法
mapping跟masking这两种方法都可以化成时域跟频域两种类型,然后我们在现在实现的代码库中支持了主流的以及比较典型的方法,也包括现在像wsj0_2mix这种比较受欢迎的benchmark上的SOTA的方法。
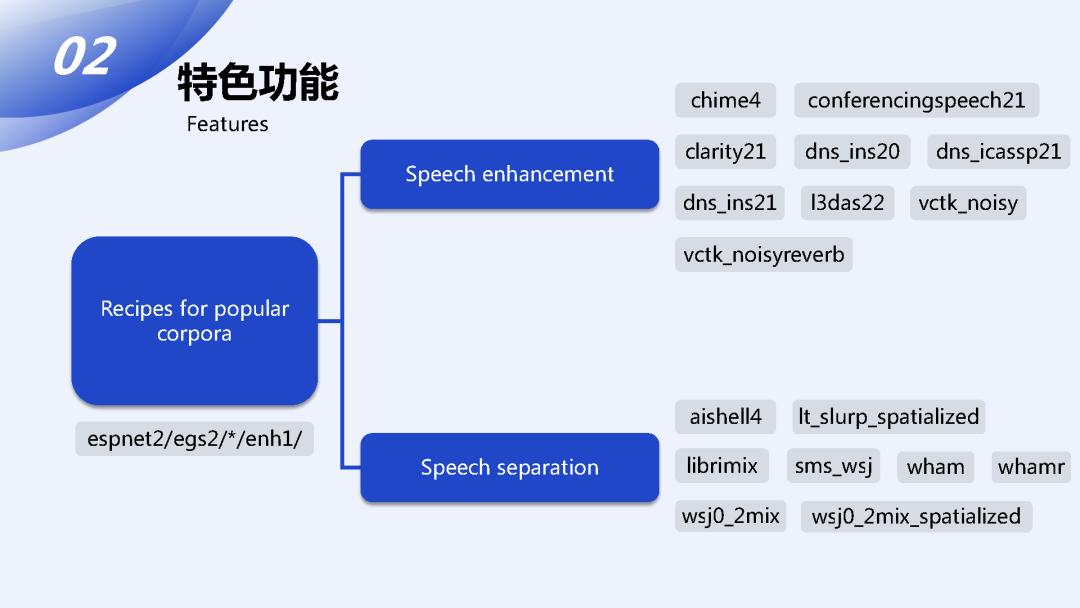
在recipe方面,仅关注前端的方向的话,我们支持Speech enhancement 和Speech separation 这两种类型的数据集,前者是针对单人的数据对语音进行增强而把其它的背景声给去掉,语音分离则更加关注把不同声源的声音给分离开。我们都支持了主流研究上会使用的数据集以及我们自己发布的一些最新的数据集,它的数据目录是在espnet2/egs2/*/enh1/ 路径底下。
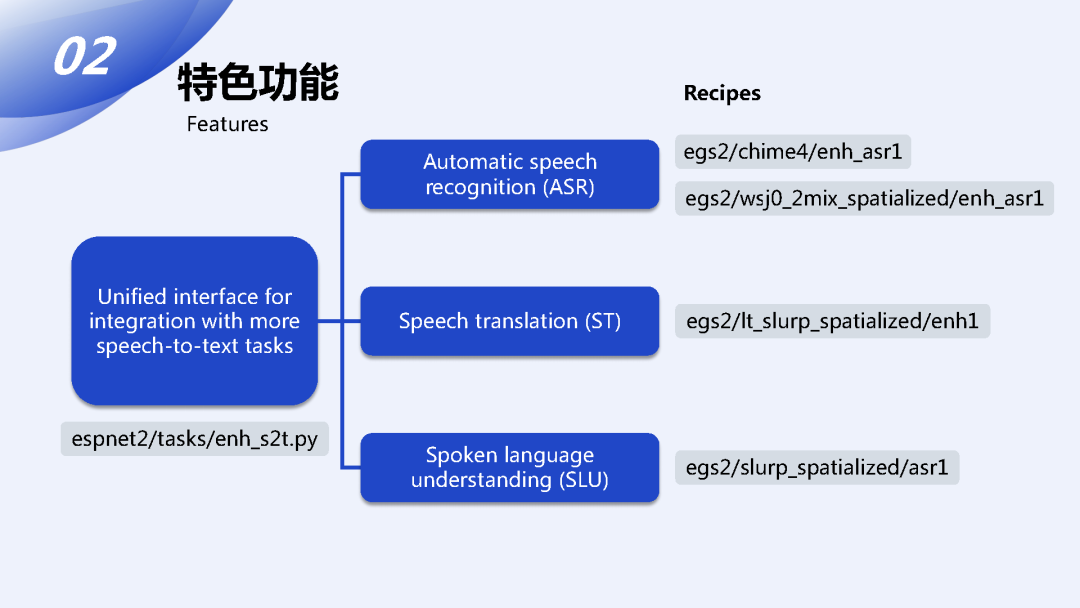
在最新公开的工具包中,我们进一步加入了更多下游任务的支持,也就有相对应的recipe,比如在chime4和wsj0_2mix_spatialized这两个数据集上我们提供了跟ASR进行联合训练的recipe以及另外两个跟语音翻译和口语语义理解这两个任务相关的recipe。
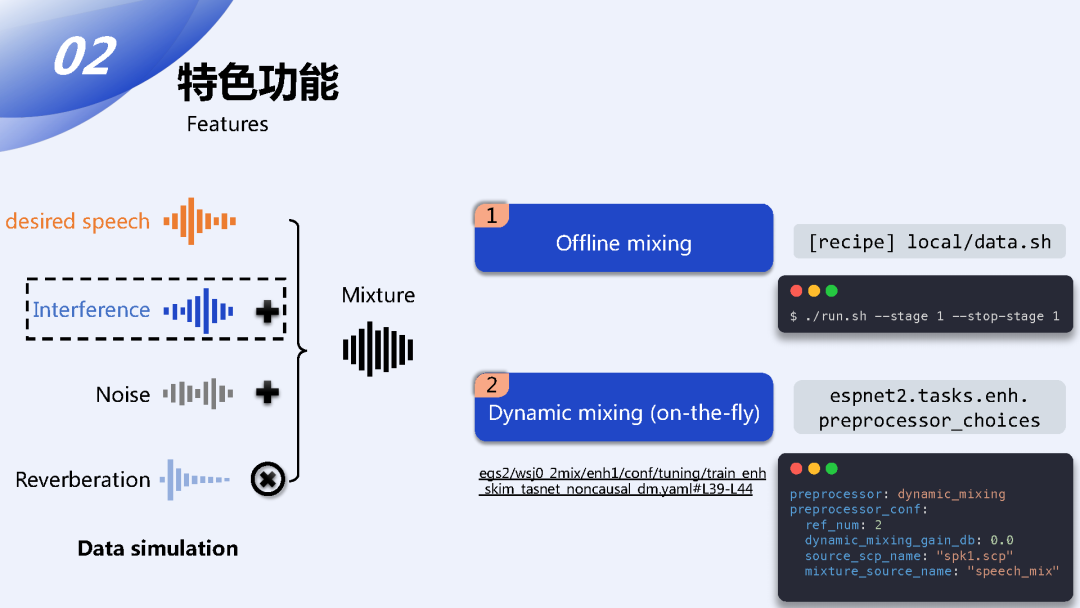
总的来说ESPnet里面的数据流向是我们先构造出为了前端训练而构造的仿真的数据,然后将仿真的数据送入模型,那么在准备仿真的数据的时候我们会需要将干净的采集到的信号和根据任务的需求和噪声混响或者是其它的干扰声源混合在一起得到一个混合的信号用来做训练,那么在进行仿真的过程我们有两种仿真的方式,一种是离线的处理,这种在recipe的目录下我们通过预先准备好的脚本来直接进行离线的生成,这种一般直接在recipe的目录下运行一个简单的命令就可以完成;第二种是在线的进行动态的混合,这种做法的好处是它可以极大地扩充训练数据的数据量,因为每一个epoch理论上都是随机混合的,所以数据量可以增大很多,这种方式是通过在我们定义的这个enh任务底下的preprocessor_choices这个类来进行选择的。我们只需要在模型的训练的配置文件中指定一些对应的配置项就可以让模型动态的在训练过程中去生成训练数据。
准备好仿真数据之后我们会把数据送入模型进行训练或者推理。在ESPnet里面所有的模型都遵从一个统一的设计方式,它会分为三个子模块:Encoder、Separator和Decoder。
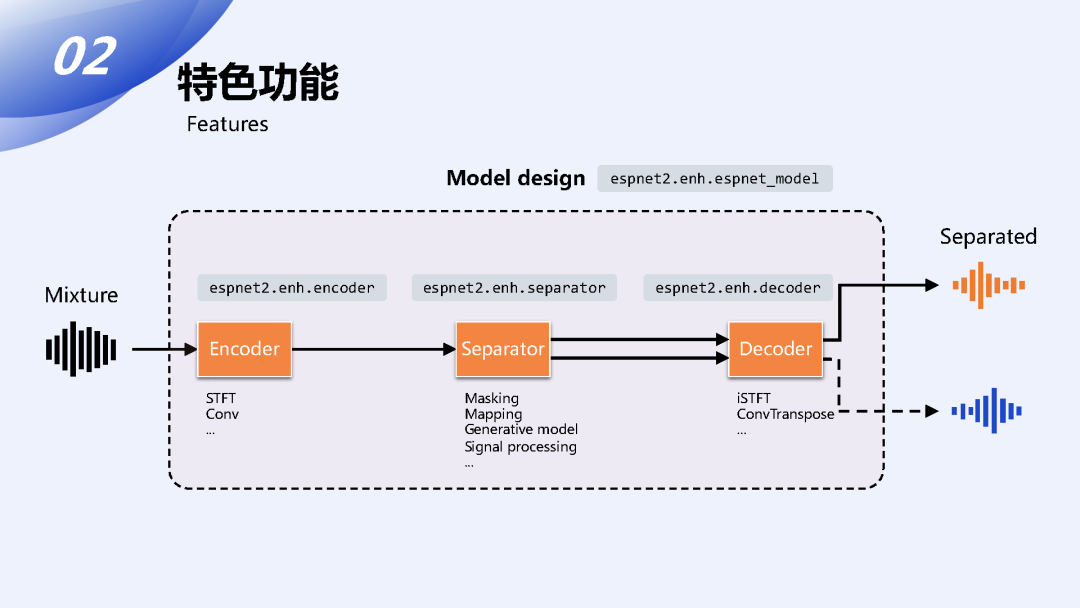
通常来说像时域模型会固定地采用CONV或者CONVTranspose来组成Encoder、Decoder,频域模型就会用STFT和对应的iSTFT来组成Encoder、Decoder。而Separator就是核心的方法部分,前面我们提到的那些分离的方法和增强的方法就是在Separator里面体现的。
最后来看一下代码的结构:

在recipe上面一般SE这个任务底下不管是单人的增强还是多人的分离它们都是用enh1这个子目录名字来进行标识,一般在这个目录下一个完整的实验目录你会观察到以下这些典型的文件,像conf这个目录包含模型训练和和推理时候所用到的配置文件;local目录下一般是用来做数据准备的一些跟每一个数据集相关的脚本;data目录是在recipe运行的过程中会产生的Kaldi格式的数据文件;dump是对data这个目录进行更进一步处理统一格式之后得到的最终用于训练的数据文件;exp是存放了所有实验相关的目录;enh.sh和run.sh是我们最终来使用这个recipe的入口,更具体来说enh.sh是一个统一化的模板脚本,在不同SE recipe中都是相同的脚本。而run.sh通过向enh.sh里面传入不同的参数来完成跟这个数据集相关的不同的训练方法。
模型的脚本方面主要分为三大目录,都在espnet2这个目录底下,在bin目录下是Python 文件形式的入口脚本,我们可以用训练、推理或者打分这三个作为入口,它们都会调用tasks底下定义的enh.py里面定义的增强任务这个大的模块,然后这个大的模块里面会进一步去访问enh这个子目录下定义的具体的模型文件。这是它们大概的依赖的关系。

然后由李晨达来介绍demo和后续开发计划。
样例展示
接下来由我来给大家介绍一下ESPnet-SE的样例展示,主要包括了两个部分的介绍,首先第一部分是关于模型训练的recipe的流程的部分,这部分主要是面向于希望自己动手搭建一套可以训练的模型并在此基础上进行进一步研究的用户;第二部分是利用一个预训练好的模型进行快速的上手,进行语音的增强或分离,这个主要是面向于对分离或增强的模型并不关心但是希望将这个模型应用在其它语音处理任务上的用户。
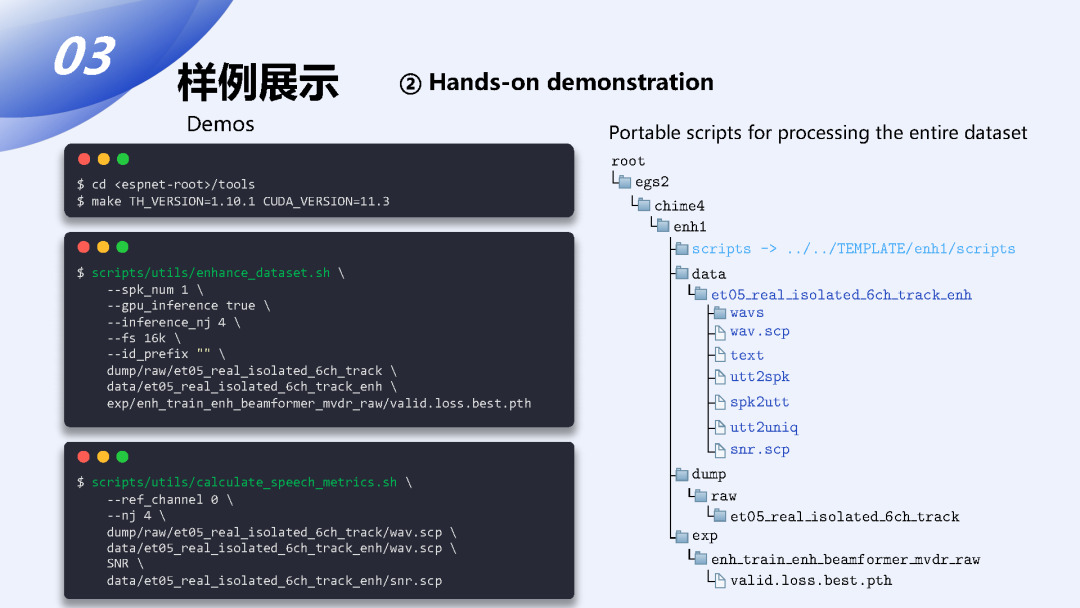
首先我们来看一下recipe的部分,刚刚王优已经介绍过了ESPnet-SE的根目录下具体的结构,从我们这个入口脚本run.sh开始,它其实是一个一键式的的脚本,如果不加stage的参数它是会从头到尾一次全部跑完的,像这边为了便于介绍我们就一步一步的来看。首先第一个stage是用于数据准备的,run.sh会去调用enh.sh,它是一个统一的模板针对于各种不同的数据集都是一种统一的方式进行处理的,然后第一步它会去调用这个local目录下的一个用于当前这个recipe数据处理的一个脚本,用于把各种不同格式的数据规整化成一个统一的Kaldi风格的数据集,这个数据集下整理好的数据项主要包含这几个文件,首先是一个wav.scp文件,里面描述了混合音频的输入ID和对应的音频文件的位置;然后是这个说话人映射文件;接下来是对应的目标说话人声音的标签文件;对于这种需要联合训练的其它下游任务还有一个可选的对应的文本标签,比如说ASR的文本标注;对于需要对一个或多个噪音进行噪声估计的任务,还需要额外准备一个噪音的标签文件。

接下来还有个第二步,是一个用于speed perturb数据增强的步骤,但是在语音分离和增强任务中一般不常用,所以我就跳过了。
第三步和第四步是用来对整理好的数据进行进一步的规整,主要包括不同音频文件格式的统一、采样率的统一,在第四步会对规整好的数据进行进一步的筛选去掉一些设定好的过长或过短的音频,方便后面的训练,这样统一处理好的数据会放在新生成的dump目录下,对应的它会分成三个或多个不同的集合,包括至少一份训练集、一份验证集和若干个测试集。

第五个stage是主要用于对训练前数据的预统计,主要是为了获取每一个数据的形状和长度,这一步的预统计主要是用于某些特定的data sample length,它需要一些提前准备好的数据的长度用于数据的每一个batch的构成。

从第五步开始,这个训练的脚本会读取run.sh传进去的一个配置文件来进行后续的训练和推理。
我们来看一下这个配置文件:
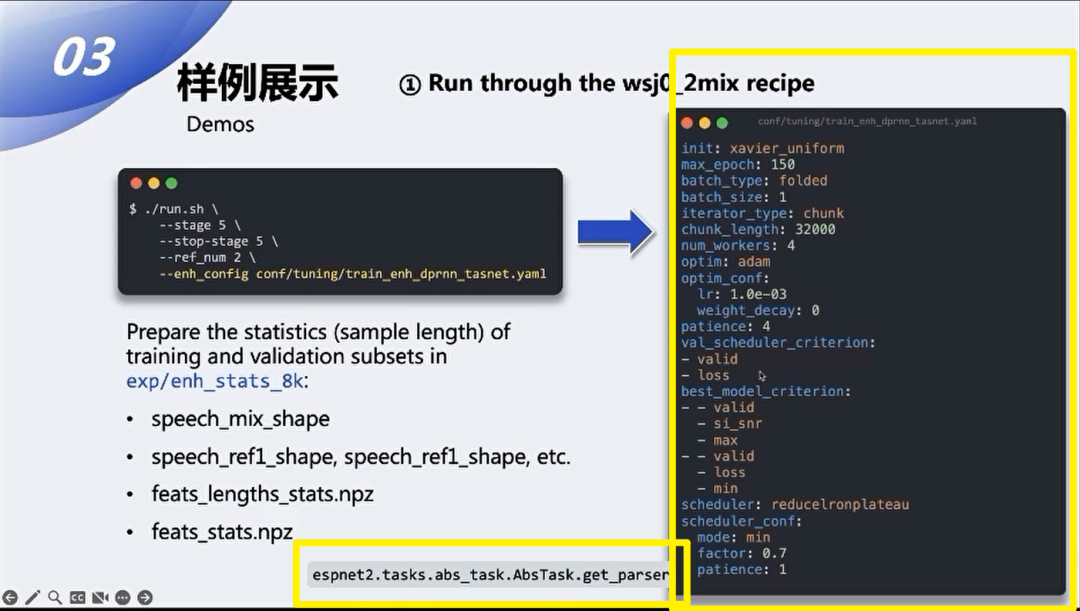
这个配置文件具体的所有的可选项可以在task定义的get_parser下面进行细节的查看,我这边主要介绍一下几个常见的比较重要的配置选项。首先这部分是一个通用的优化器和训练器的超参数的定义,是我们这边模型部分的各种参数的定义,之前王优也介绍了,ESPnet-SE中所有的模型都被抽象成了Encoder、Decoder、Separator。对于不同的Encoder,我们可以选择具体的实现的类型,中间用于增强的网络我们也可以选择具体实现的类型,然后下面对应具体的参数,然后实际中可用的模块的类型可以在代码中的选择器中查看到,目前我们支持的Separator的种类已经非常的多了。

接下来是损失函数的定义,在ESPnet-SE中损失函数被定义成了一个multi-task组合的形式。我们可以针对多种不同的优化的目标为每一个准则去具体地设置准则的类型以及对应的权重,最终的训练准则是以各种不同的损失函数组合的形式来表示的,当然也可以只选择其中一个目标进行优化。
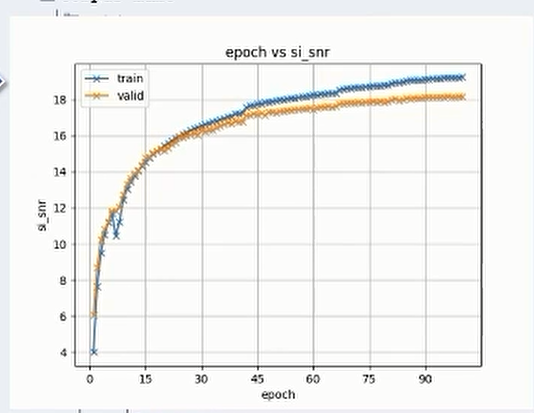
第六步就开始了正式的训练过程。ESPnet工具本身对多机多卡的支持就已经比较完善了,可以通过命令行参数的形式来指定具体的分布情况,训练完成后对应的训练过程中生成的日志、模型文件、相关的监测用的图表tensorboard都会生成在exp目录下,用于监测和模型筛选,通过这个生成图表也可以观测优化的曲线。

第七步是用于对之前训练好的模型进行一遍推理,推理好之后会生成增强或分离好的音频存放在实验目录下。
第八步会对生成好的音频进行打分,打分的指标的种类也可以通过命令行传参的形式给出,最后生成的报告会存放在对应的实验目录下。
第九步和第十步是一个可选的过程,可以在第九步和第十步中选择对应的下游任务,比如语音识别,以这个下游任务的指标来进一步对增强好或者分离好的语音进行一个其它任务的评估。

前面介绍了recipe训练模型的过程,对于自己不需要训练模型,想快速使用ESPnet进行语音增强或分离的用户我们提供了可以快速上手的Python的API,这个过程非常简单,我这边展示了几个例子:

1、最小的安装就只需要安装ESPnet工具本身,再安装一个用于上传和下载模型的espnet_model_zoo工具包;
2、一个最简单的语音增强的例子,只需要几行代码就能实现,首先通过一个标签,这个标签可以在我们发布模型的这个网站上找到,通过一个标签可以把这个模型从hugging face等平台上下载来,然后把模型解包加载之后就可以用一个完全封装好的API对声音进行增强,大家可以右上角的二维码自行的查看例子。
3、分离任务也是一样的,在分离的过程中只要去选择一个对应的预训练好的分离模型就可以了,这个过程和前面增强是一致的。

4、对于连续语音的处理,我们在API设计的时候也进行了考虑,在实际的使用中我们可能会遇到比较长的输入,我们这个API是支持分段的处理的,可以使用一个在句子级别的数据上训好的模型,通过手动指定好的窗长和窗移的形式对连续的长语音进行进行整体的处理。

5、接下来展示对于分离好的音频使用其它的下游任务进行测试,比如说分离好的音频可以通过一个预训练的ASR模型对这个分离好的音频进行识别,然后通过识别的结果也可以对这个模型的分离效果进行评估,比如一个混合音频的例子经过我们的分离模型处理后,再由一个预训练好的单人的ASR模型进行测试,通过测试结果我们可以看到分离好的混合音频它用单人的ASR模型进行处理的时候,只出现了一个词插入错误。

前面介绍的是Python代码级别的一个API,对于希望通过预训练模型对整个数据集进行增强的需求,我们也提供了更高级封装的脚本,可以用它对ESPnet格式的数据进行整一个数据集层面的语音增强,使用这个脚本可以快速地用我们预训练好的前端模型对一整批数据进行离线的处理,生成一份增强过的数据集,这个脚本在其它的一些任务比如语音合成这种对训练语料的噪声比较敏感的任务上,我们就可以使用这个工具包先对收集好的数据进行一遍增强,对数据进行噪音的去除。
我列出了ESPnet预训练模型的hub的地址,我们主要把模型发布在了hugging face和zenodo这两个平台上,大家可以顺着这个链接去找到合适的模型,当然如果大家手头有自己准备好的recipe,有训练好的模型也是可以通过这个run.sh里面提供的步骤,可以很方便地把自己训好的模型传到这些平台上面去的。
ESPnet model hub:
-
https://huggingface.co/espnet
-
https://zenodo.org/communities/espnet
下面是两个colab交互式的demo,感兴趣的朋友可以通过前面的二维码或者这边的链接打开,自己可以玩一玩。
Demo pages:
-
https://colab.research.google.com/drive/1fjRJCh96SoYLZPRxsjF9VDv4Q2VoIckI(ESPnet-SE)
-
https://colab.research.google.com/drive/1hAR5hp8i0cBIMeku8LbGXseBBaF2gEyO (ESPnet-SE++)
我们主要是在GitHub的页面上面进行项目的文档和交流,大家有更多的建议或者问题都可以随时打开ESPnet项目找到enhancement这个子项目的issue,可以在这里留言或提出建议和需求。
Documentation:
https://github.com/espnet/espnet/blob/master/egs2/TEMPLATE/enh1/README.md
Suggestions and discussion:
https://github.com/espnet/espnet/issues/2200
未来展望
最后我来描述一下ESPnet-SE未来发展方向,我们近期正在为ESPnet-SE加入更多的目标说话人抽取或目标说话人增强的模型,同时也在更真实的应用场景下准备相关的recipe和适配的模型,然后会进一步加深和其它任务的整合,作为一个前端信号增强的工具我们希望更多的语音处理任务能够方便地来调用ESPnet-SE工具包,在ESPnet项目内部我们在前后端联合优化的任务中,比如多人的ASR或鲁棒的ASR,正在尝试将ESPnet-SE的前端模型和标准的单人ASR任务整合起来,使我们前端的增强模型成为ASR任务的一个可选的模块。
在ESPnet-SE项目中,目前实现的大部分的方法都是基于神经网络的,我们也在积极地添加更多传统的基于信号处理的方法来丰富ESPnet-SE的语音增强和分离的工具包,同时,我们也在跟torchaudio进行一些深入的合作,希望将一些传统的方式以一种可导的形式来实现到工具包中,以便于更好地联合的优化和训练。
以上就是我们今天主要的内容。