前言:
今天我们再来分享一个开源代码项目,这个代码项目是通过读取本地的TS文件,然后推流到RTMP服务器上面。
一、项目框图和运行效果:
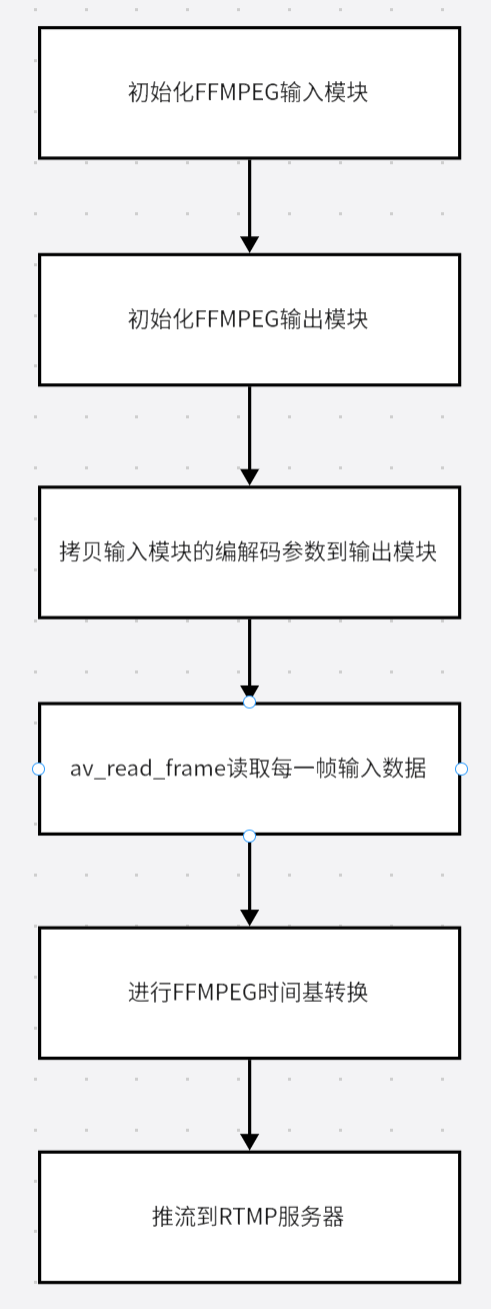
1.1.项目的框图:
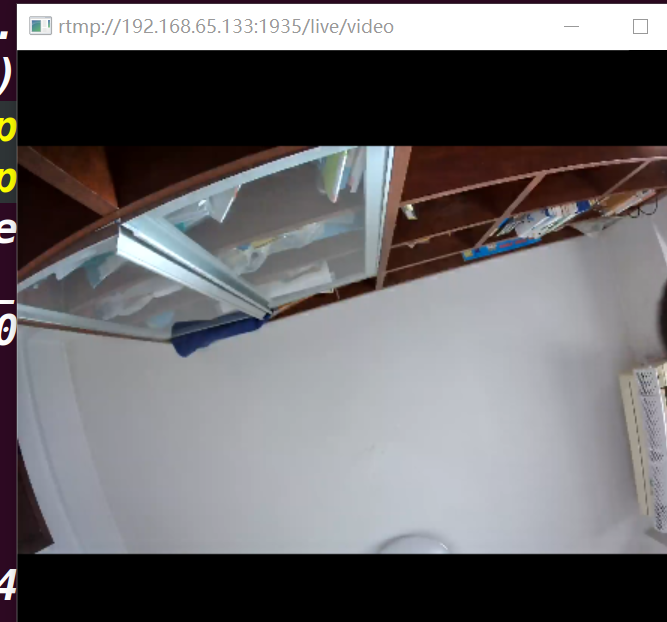
1.2.运行效果:
二、模块的讲解:
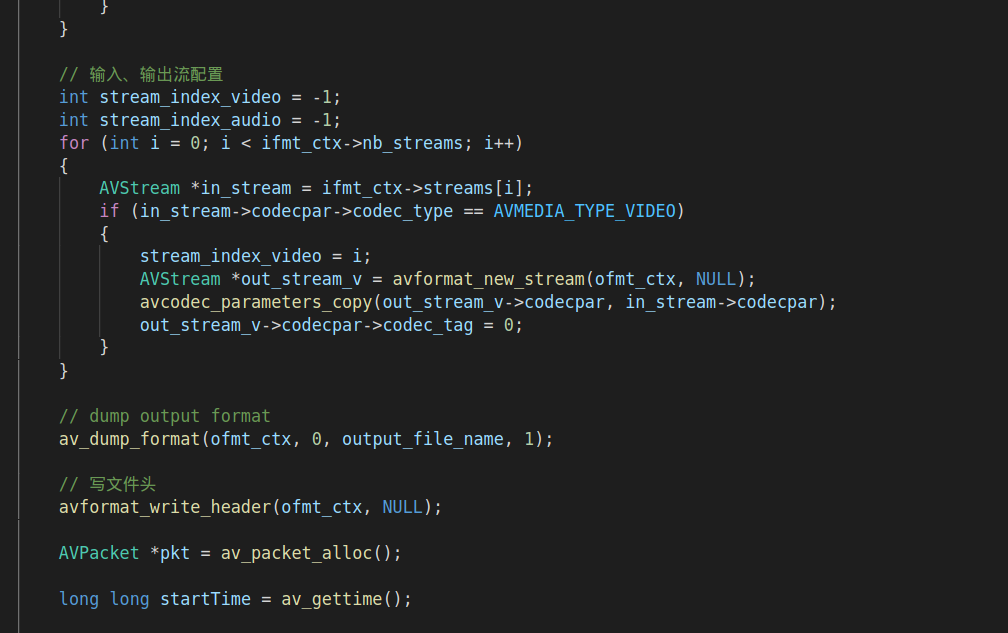
2.1.初始化文件读取模块:
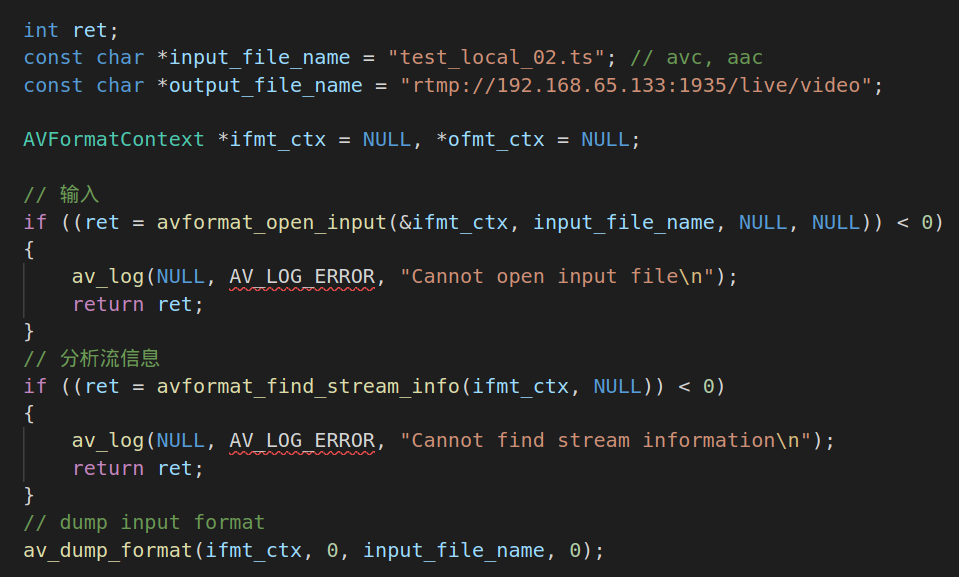
这一块代码的作用是打开本地ts文件,avformat_open_input的作用是打开本地流媒体文件,并获得ts流文件的基本信息。并利用avformat_find_stream_info检测文件信息,包括编码的宽和高。
2.2.初始化FFMPEG输出模块:
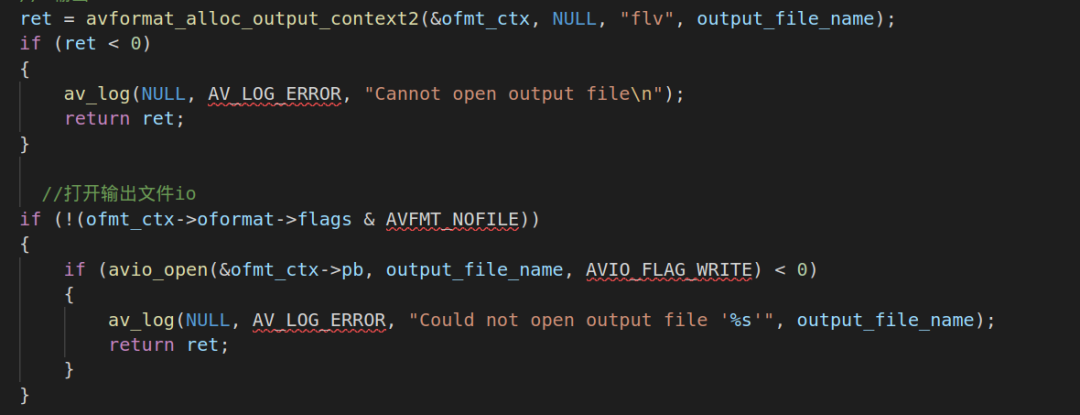
输出模块使用avformat_alloc_output_context2的API进行初始化,并利用avio_open打开输出的IO文件流。
2.3.把输入模块的编解码参数拷贝到输出模块中:
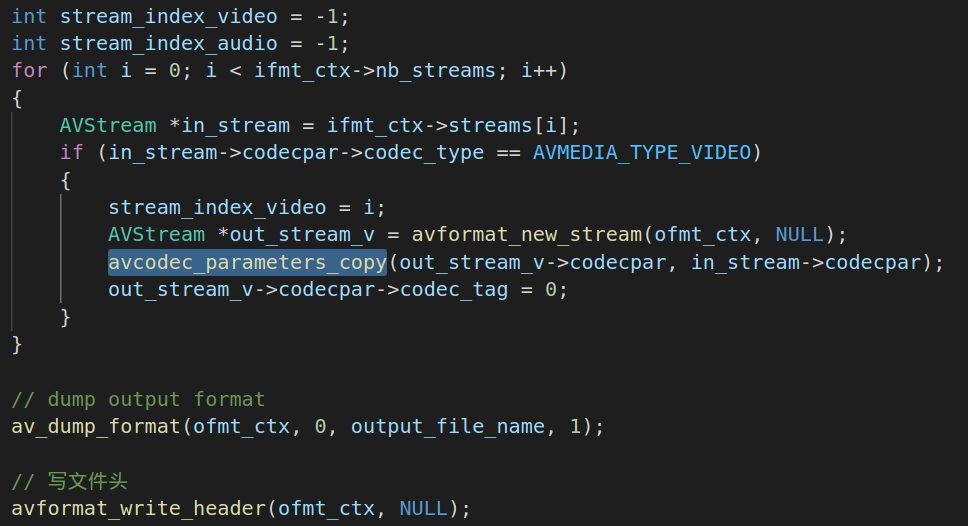
根据nb_streams来创建AVStream,并利用avcodec_parameters_copy把输入模块的编解码参数拷贝到output的avstream。此时output的avstream就有了输入模块的编解码参数。并利用avformat_write_header来初始化模块的头部。
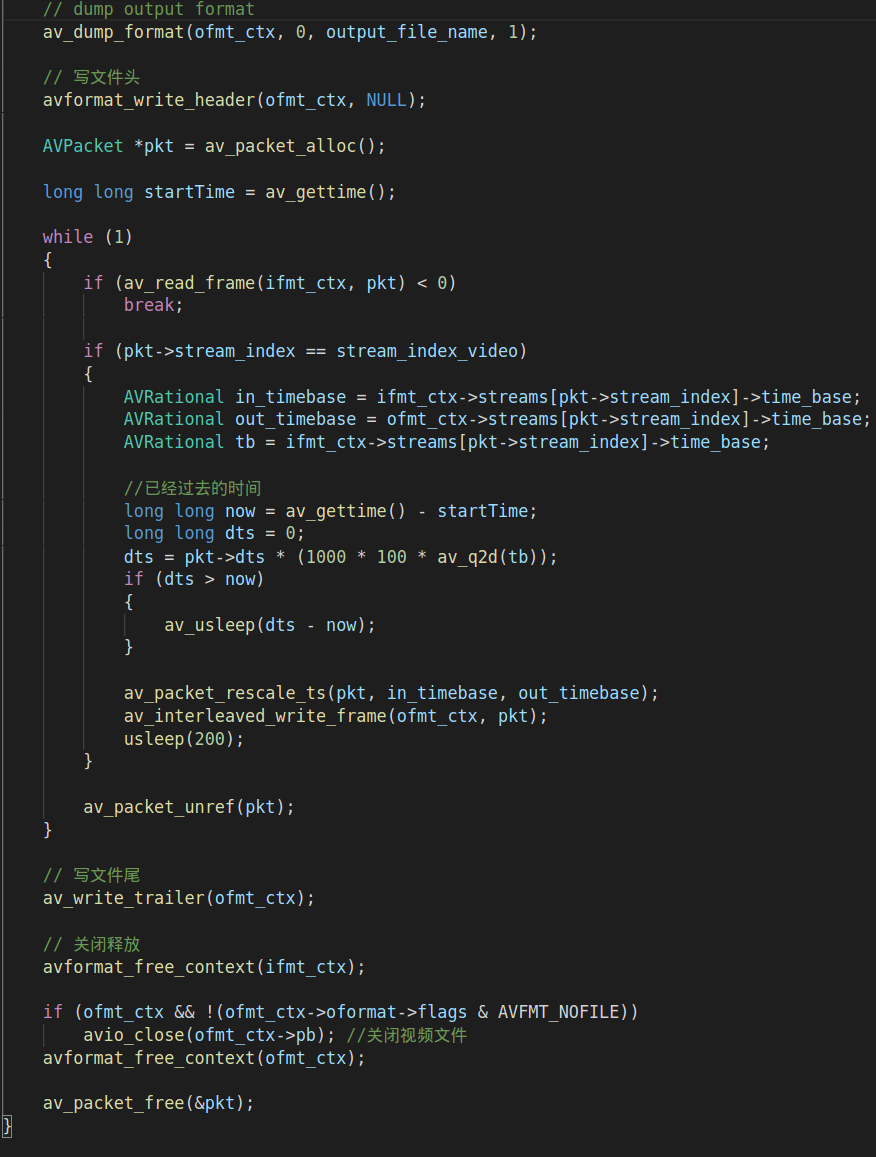
2.4.av_read_frame读取ts流每一帧数据,并进行时间基转换,然后推流到RTMP服务器:
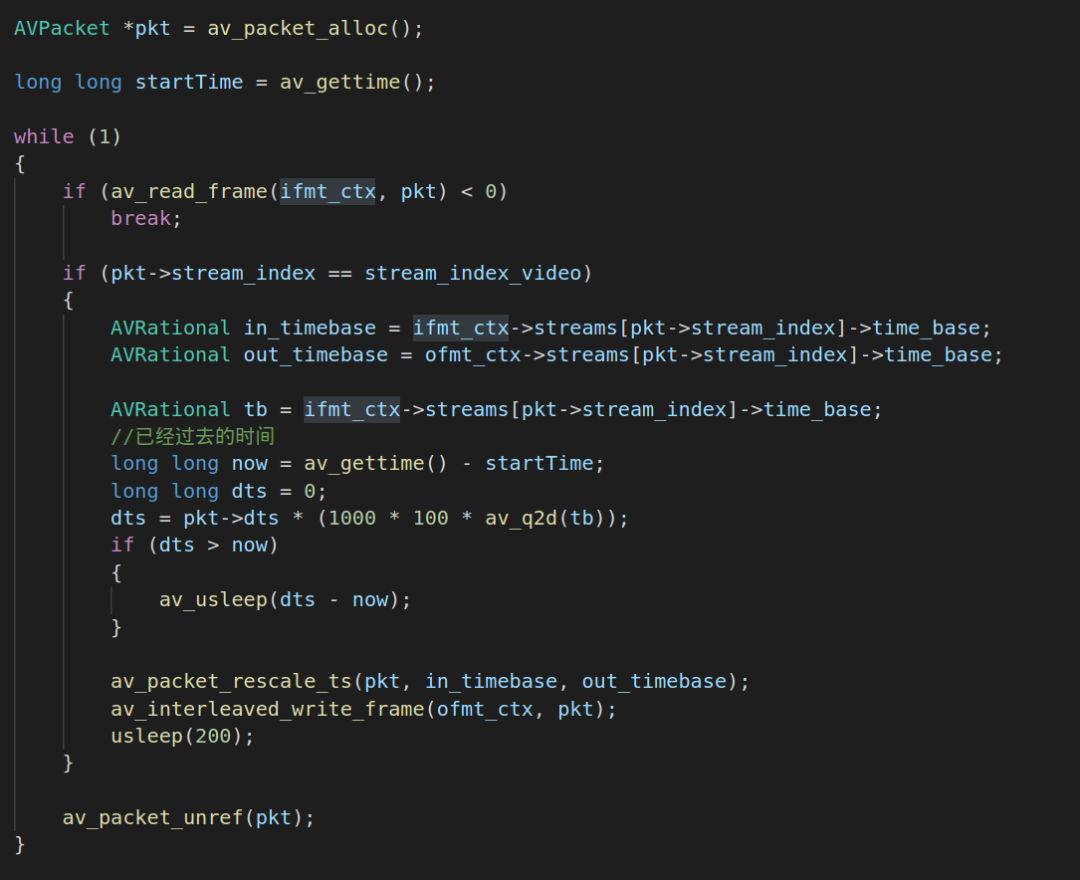
这一块的代码主要是利用av_read_frame的api读取每一帧音视频数据,然后利用av_packet_rescale_ts的api进行时间基转换。这个转换是把FFMPEG文件输入的时间基传输到output的时间基,视频转换的时间基是以帧率为单位。转换时间基完成之后就使用av_interleaved_write_frame把转换后的数据推流到RTMP服务器。
2.5.释放所有资源:
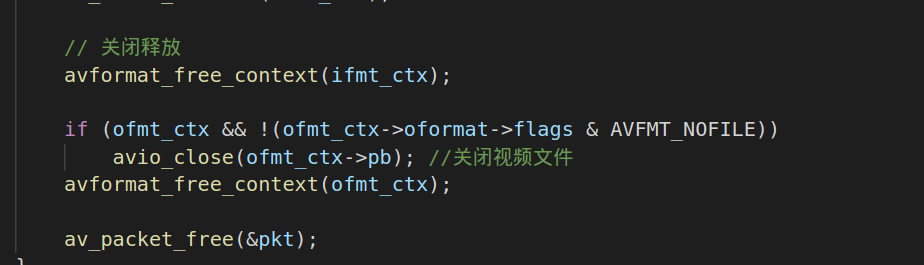
当推流完成之后,就要释放资源。avformat_free_contex的api主要是释放AVFormatContext的资源,avio_close主要是释放AVIOContext的资源。av_packet_free释放的是packet资源。
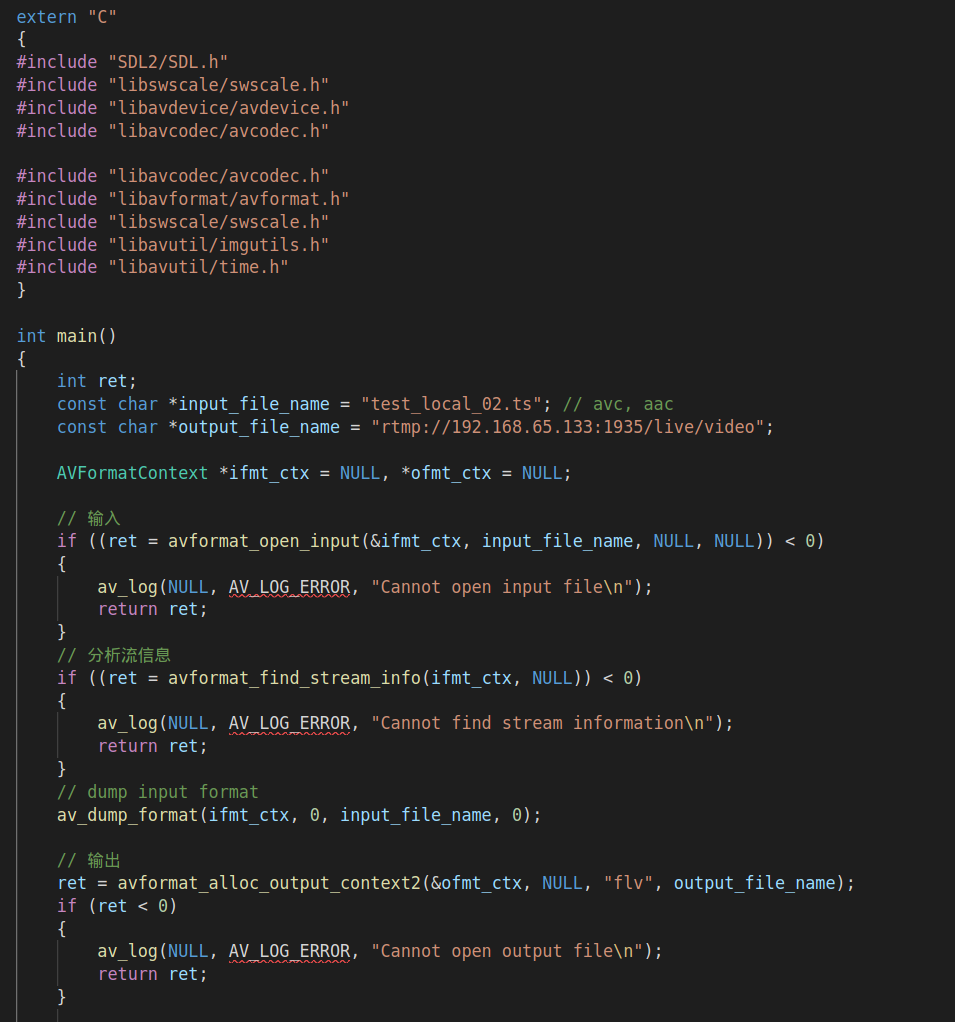
三、完整的代码:
下面我们来看看一个完整的代码:
最后:
对嵌入式音频开发感兴趣的朋友,可以加入星球来学习,课程内容说明如下:
ai识别加音视频推流实战项目进度,整个项目从7月份开始,前两部分的ai识别工程基本上已经讲解完了(还有人脸识别的工程代码会进行重新重构一篇),当然这里面等录制完了第三部分的音视频推流开发内容,还会对ai识别这部分做补充,比如说yolo或者ssd等算法模型的原理讲解,还有就是自己怎么去训练模型;目前已经开始在录制音视频推流开发的第三部分,已经录制了两个小节部分,第三部分的内容会多搞点,比如理论知识的讲解,然后再结合我们的推流代码工程,可以学习到mpp和ffmpeg,以及rtmp、srt等相关协议,还包括h264、h265的码流结构和编码结构等相关知识点,甚至还包括工作当中常遇见家的问题,比如说,音视频不同步的问题,同时最近又添加了最新的课程内容:

最新课程内容更新:
可以直接扫码加入星球:

最后感谢大家的支持哈,加入了星球的朋友,记得加我微信:tu18879499804,我拉大家进解答群!