作者:陈祖龙(葬青)
一、前言
最近大模型真的很火,从个人到公司,各行各业都在学习大模型、总结大模型和尝试应用大模型。大模型其实不是一个新的产物,已经在NLP发展了很多年。ChatGPT的诞生,经验的效果震惊了所有人,虽然也有一些瑕疵,但是瑕不掩瑜。微软投资OpenAI看到了它的未来。微软快速围绕ChatGPT对相关的产品进行了产品升级,从搜索到微软365各种产品。
5.29号有机会和部门的一些同事一起到上海微软进行了参观访问,微软给我们从内部产品升级到针对企业级的ChatGPT,全方位进行了解读,很震撼。一个大象级别的公司,竟然在AI面前这么灵活,而且有决心、有魄力对全部产品进行改造,ALL IN AI 。微软的几个点给我印象深刻:
-
50%左右的人没有用过AIGC;
-
80%的人只用过简单的提示词,把AI作为知识库;
-
90%的人过度理解AI,AI可以解决一切。
微软用ChatGPT把New-Bing进行了升级之后,给了业界很大的震撼,搜索的范式发生了变化,基于大模型的生成式搜索随之引入眼帘。这个文章《大模型时代的文本检索》详细的介绍了生成式搜索。
最近在看一些LLM相关的文章,组内也基于小蜜快速搭建了基于检索增强的全流程,顺便撸了一下推荐方面的LLM的一些相关的论文,这个行业开始有一点动静了。搜索慢慢的被大模型渗透,那么很自然很多人想到了推荐,但是推荐是不是真的可以被大模型渗透呢?大模型能改变推荐的范式吗?
刚好我们在通过对相关的推荐场景快速的进行个性化升级之后,在最近尝试了基于LLM相关的推荐改造,目前从离线来看效果还是蛮不错的。
二、现状
2.1 推荐系统
推荐系统发展了这么多年,只要是做过推荐系统的下面的架构大家已经耳熟能详了。

如上图所示,一个完整的推荐系统包含召回、排序(粗排、精排、重排、端排序)、业务过滤层等几个重要的逻辑分层。这多年虽然很多论文层出不穷,但是主要框架没有发生很大的变化,围绕这个架构的各个层进行深入优化,通过分阶段的贪心的方式来优化算法的效果,来提升整体的业务指标,算法“卷”起来。
对于现在的整个推荐系统而言,虽然看似是一个智能化的推荐系统,但是本质还是在通过过拟合用户在场景内的行为来进行各种预测。过拟合是个毒药,效果好,但是会出现各种各样的问题(冷启动用户、买了还推、内容单一),于是也出现了很多算法来解决这一类问题的,怎么提高推荐系统的多样性?怎么了提高推荐系统的惊喜性。
所以说旧时代的推荐系统,还是不是一个真正意义上的智能的推荐系统,依靠过拟合用户行为来学习用户兴趣,并没有真正的了解用户的心智变化。
2.2 大模型
一般认为NLP领域的大模型>=10 Billion参数(也有人认为是6B、7B, 工业界用, 开始展现涌现能力);经典大模型有GPT-3、BLOOM、Flan-T5、GPT-NeoX、OPT、GLM-130B、PaLM、LaMDA、LLaMA等。
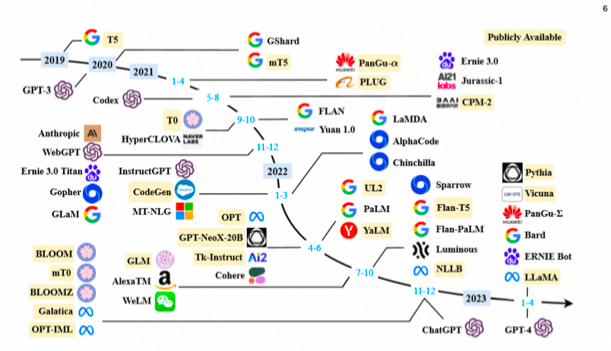
那么LLM为什么会被这么关注呢?大模型有哪些能力吗?
2.2.1 涌现
涌现, Emerge(abilities), 即一般指在大模型中出现而小模型没有的能力。所谓“涌现”,在大模型领域指的是当模型突破某个规模时,性能显著提升,表现出让人惊艳、意想不到的能力。比如语言理解能力、生成能力、逻辑推理能力等。一般来说,模型在100亿到1000亿参数区间,可能产生能力涌现。
关于涌现能力的更加详细的介绍可以读一下《大语言模型的涌现能力:现象和解释》。
2.2.2 上下文学习&COT能力
上下文学习(ICL)是指不需要微调,只需要少数几个样例作为示例,就能在未知任务上取得不错的效果(提升few-shot能力)。
ICL主要思路是,给出少量的标注样本,设计任务相关的指令形成提示模板,用于指导待测试样本生成相应的结果。
ICL的过程,并不涉及到梯度的更新,因为整个过程不属于fine-tuning范畴。而是将一些带有标签的样本拼接起来,作为prompt的一部分,引导模型在新的测试数据输入上生成预测结果。
COT能力,也是一种奇妙的能力,大模型涌现出来的COT能力,让模型可以解决复杂问题,而且具有了可解释性。
ICL方法的表现大幅度超越了Zero-Shot-Learning,为少样本学习提供了新的研究思路。因为ICL离不开与Prompt的结合,感兴趣的可以去读一下《A Survey on In-context Learning》和《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》这两个综述。
三、LLM4Rec
3.1 为什么要用LLM
LLM有很多特性可以被用来对推荐系统来进行改进。
-
可以利用大模型的知识和推理能力来对用户的上下文行为来进行深入理解
-
大模型有很强的zero-shot/few-shot的能力,可以很方便的进行下游任务的适配。相应的推荐也有很多的场景,有的场景样本多,有的场景样本小,这种范式给推荐提供了一种统一的可能,是否未来可以构建类似的高速适配的能力
-
推荐系统发展到今天,都离不开过拟合场景数据来提升效果,会带来很多的负向作用(各种公平性、bias问题),LLM型虽然也有问题,但是大模型是建立在巨大的知识之上的,可以利用这些知识来尝试去打破各种目前的问题。
-
多场景多任务、冷启动是推荐系统里面经常遇到的场景优化,很多的工作都在这个方向的优化。LLM提供了一种能力可以快速来进行一些冷启动场景的优化和多场景多任务的优化。
-
推荐系统的可解释能力一直被大家诟病,LLM有很丰富的知识,可以利用这部分知识来进行推荐结果的可解释性。
-
最后一种就是直接利用大模型来进行推荐结果的生成
总的来说,已经尝试的工作可以分为下面的三大类,当然有很多的划分方式:
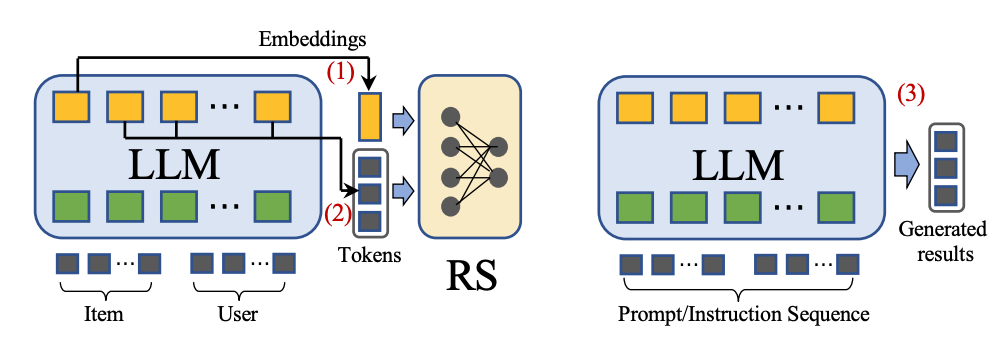
1)LLM Embeddings + RS
这种建模范式将语言模型视为特征提取器,将物品和用户的特征馈送到LLMs中,并输出相应的嵌入。传统的推荐系统模型可以利用知识感知嵌入来完成各种推荐任务。
2)LLM Tokens + RS
这种方法基于输入的物品和用户特征生成token。通过语义挖掘,生成的token可以捕捉潜在的偏好,这些偏好可以融入到推荐系统的决策过程中。
3)LLM AS RS
这种方式直接把LLM作为一个RS系统,不过这种对LLM精准性要求比较高。

3.2 Pretraining-FLM
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
在这个论文中作者提出了一个统一的架构来利用大模型来进行推荐。文章提出来对目前主流的推荐场景(序列推荐、评分预测、可解释性推荐、评论总结等)多个任务都进行了统一,构造了一个模型P5。
在预训练阶段,采用统一的一个模型结构,设计不同的prompt模版来进行个性化的推理,所有的任务做到很大程度的统一。预训练模型用了T5模型。通过自己场景的数据Pretraining之后,在各个数据集上的表现都还是不错的,不过在各个数据集合上的表现是不一样的。
但是这个论文感觉还是蛮不错的,可以做到各个任务的统一,而且最终效果还是可圈可点的,这个论文值得精读一下。

3.3 Fine-Tuning-FLM
Chat-REC:Towards Interactive and Explainable LLMs-Augmented Recommender System
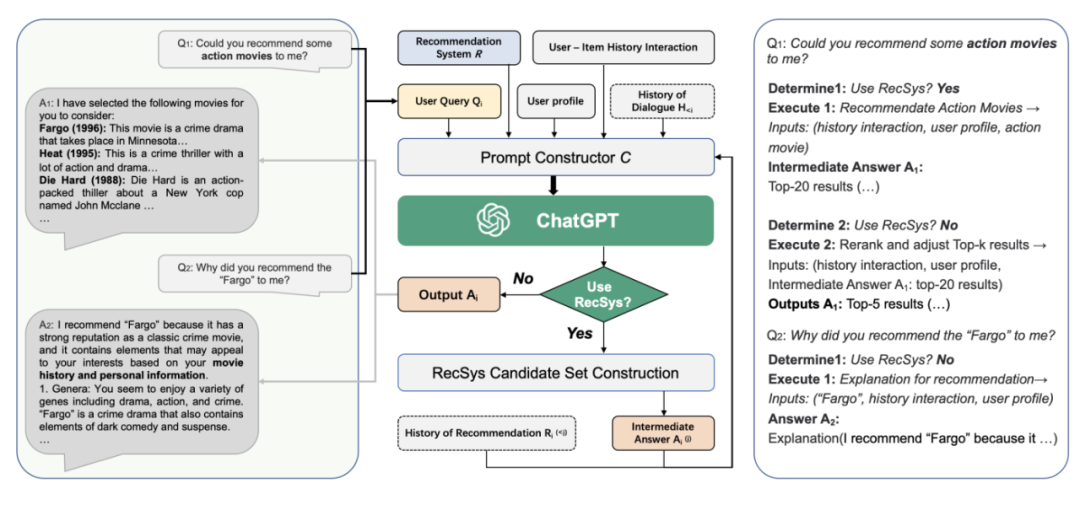
本文中提出了一种用 LLMs 增强传统推荐的范式 ,通过将用户画像和历史交互转换为 Prompt,Chat-Rec 可以有效地学习用户的偏好,它不需要训练,而是完全依赖于上下文学习,并可以有效推理出用户和产品之间之间的联系。
通过 LLM 的增强,在每次对话后都可以迭代用户偏好,更新候选推荐结果。和基于检索增强的QA一样,LLM与传统搜推系统结合,为了保证结果更加可靠,还需要增强一下。论文图如下,流程还是蛮清晰的。给推荐系统怎么使用LLM指明了一条路。
M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
整个推荐的思路是基于达摩院的M6的模型上进行的探索,并将推荐系统中的任务转换成了语言模型可以处理的语言理解或语言生成任务,主要贡献有这么几条:
1)作者提出了一种统一的推荐框架思路,这个框架是基于M6之上的,不仅可以做开放域的推荐,还可以针对下游任务进行简单的微调就可以用
2)为了减小推荐系统的推理延迟,本文在late interaction的基础上提出了multi-segment late interaction. 简单来说就是把transform的前几层的结果先缓存起来。

A First Look at LLM-Powered Generative News Recommendation
对于传统的新闻推荐,往往有如下的几个问题:
1)冷启动。对于长尾或新用户,模型无法较好的建模和理解他们的兴趣。冷启动是推荐系统经常遇到的问题
2)用户画像建模。出于隐私保护的考量,现有的数据集可能无法包含详细的用户画像信息。另外用户的兴趣往往是多样的,怎么能比较精准的客户还是蛮有挑战性的。
3)新闻内容理解。由于新闻数据中标题和内容存在不一致的问题,导致难以识别新闻中的关键概念和主题。而且新闻一般内容都会比较多。
本文提出来GENRE框架,这个框架可以提供一种灵活的,可以配置的,能快速把LLM的相关的能力引入进来来进行相关的推荐。

3.4 Prompt-Tuning
Is ChatGPT a Good Recommender? A Preliminary Study
这个文章是阿里内部自己写的一个文章,文章主要讲是设计了一系列的prompt并评估了 ChatGPT 在五种推荐场景的性能。在这个文章里面,并没有对LLM来进行微调,只是依靠prompt来进行全流程设计。
Prompt Learning for News Recommendation
代码:https://github.com/resistzzz/prompt4nr
采用了一种称为prompt learning的预训练、提示和预测范式。在这个框架中,任务被转化成一个填空式掩码预测任务,通过设计个性化的提示模板和相应的答案空间,以充分利用预训练过程中嵌入的丰富语义信息和语言知识。这种方式通过prompt learning的方式在预测的时候可以保证很好的性能,应用价值比较高。

Zero-Shot Next-Item Recommendation using Large Pretrained Language Models
代码:https://github.com/AGI-Edgerunners/LLM-Next-Item-Rec
在这个论文里面作者提出了一种新的prompt策略来进行商品推荐,主要可以理解分为下面几个步骤:
1)候选生成
类似搜索检索增强一样,把推荐系统的召回部分保持不动,交给传统的(协同过滤或者其他向量)等方式来进行
2)Prompt策略
本文提出了多个环节设计Prompt:用户偏好理解Prompt、候选商品二次选择Prompt、最终推荐结果生成Prompt。用户偏好理解Prompt主要是对用户的行为进行理解。候选商品二次选择Prompt主要是根据用户偏好和候选商品,设计Prompt来选择对候选商品来排序。最终的推荐结果是在第二个基础上来对最终的结果进行选择组合。
3)结果抽取
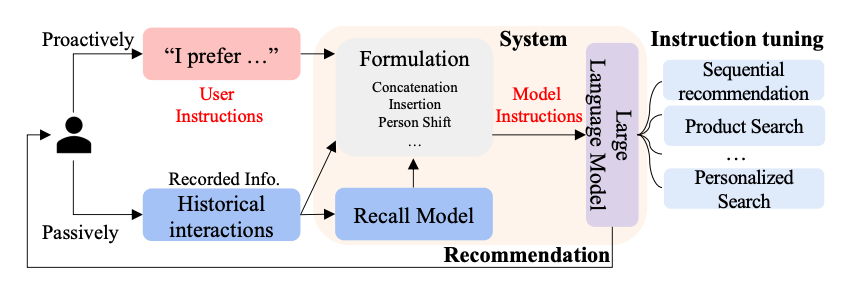
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
这个论文主要思想是,用户的偏好或需求可以用自然语言描述(称为指令),以便LLMs能够理解并进一步执行指令以满足推荐任务。主要是提出推荐系统的指令调优方法,名为InstructRec。该方法允许用户在与推荐系统交互时,用自然语言指令自由表达他们的信息需求。考虑与用户需求表达相关的三个关键方面,即偏好、意图和任务形式来设计指令。本文采用3B Flan-T5-XL作为骨干型号,Flan-T5基于T5进行了微调。
3.5 Survey
Language Models as Recommender Systems:Evaluations and Limitations Uncovering ChatGPT’s Capabilities in Recommender Systems
代码:https://github.com/rainym00d/LLM4RS
这篇论文从IR的角度,分别从point-wise, pair-wise, 和 list-wise ranking三个方面来对chatgpt在recommendation的角度来进行了能力分析。作者并没有对模型进行finetune,只是设计了很多domain-specific的prompt工程,并得到下面的几个不错的结论:
1)chatgpt相对于其他LLM模型,在三个ranking的方式上效果都是很明显;这本质还是由模型自己的精度来保证的;
2)综合性价比额,作者任务chatgpt在list-wise ranking 方面效果更好;
3)chatgpt在冷启动场景效果会更加显著一点(主要偷取外部知识);
A Survey on Large Language Models for Recommendation
这个综述是组内中科大的AIR实习生的一个组的老师发的,王老师把最近的一些关于LLM相关的推荐论文进行了详细的了解和梳理。
3.6 LLM-Based 长文档推荐
刚好我们在通过对相关的推荐场景快速的进行个性化升级之后,在新闻类的文章领域SOTA相关的论文有很多,在最近尝试了基于LLM相关的推荐改造,目前从离线来看效果还是蛮不错的。

几个改进点:
1)利用大模型的总结和推理能力来对长文档进行总结,因为本身长文档就是有很强的逻辑性的,普通的向量建模方式只能一定程度表征语义,如果用bert等传统的来说还有字数限制,对文章的内容进行高精准的提取(文章的表征放到离线),对于文章来说可以采用下面三种方式来进行总结;

2)利用大模型的推理能力来对用户上线文来进行离线的推理,对用户行为进行建模,从用户繁杂的行为中找到背后的逻辑(用户的理解也放到离线),用户历史浏览的文章都会首先被LLM表征,然后利用LLM的COT能力来对上线文进行总结和表征;
3)这里需要涉及两个Prompt,一个Prompt是对长文档进行summarize,另外一个Prompt是对用户浏览历史做summarize。
目前效果:
我们的场景式技术类文章的推荐场景(类似知乎、简书、CSDN等),这些场景的特点是技术文章逻辑性很强、文章通常很长。新文章也比较多,文章需要经过很长时间之后才能出来比较热的文章。我们在约1000W的样本量,30W+的候选长文档,模型可以选择(chatglm6b/chatm6等)是做的实验,实验效果如下:(其中NAML/NRMS/NPA/FedRec都是新闻领域SOTA的推荐排序模型)
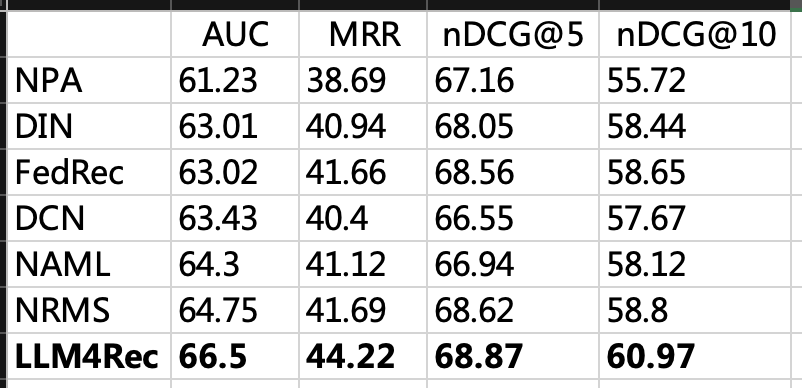
一些消融实验的效果:

从上面的实验可以初步得到一个结论,LLM对于文档类推荐效果还是比较显著,不论是用来做商品理解还是用户上下文理解。
四、总结&展望
不管你是主动接受还是被动接受,LLM相关的从底层硬件到上层应用已经全面开花。
大模型是目前推荐系统领域的热门话题之一,其将信息检索、自然语言处理和深度学习技术相结合,能够捕捉更多的用户兴趣和行为,提高推荐的准确性和效果。
未来,大模型在推荐系统中的应用将会越来越广泛。一方面,随着数据量的不断增长,大模型能够更好地处理这些数据,并从中发掘更深层次的用户兴趣和行为;另一方面,随着模型算法的不断升级,大模型将不断提高推荐的效果,并能够更好地应对多样化的推荐需求。
此外,大模型还有很多未被发掘的潜力。例如,将大模型应用于社交网络中的推荐、个性化广告推荐、音视频推荐等领域,都有很大的发展空间。
总之,大模型是未来推荐系统发展的一个趋势。同时大模型也给我们提供了一个统一的方式未来。
参考阅读
[01]Zero-Shot Next-Item Recommendation using Large Pretrained Language Models
https://arxiv.org/pdf/2304.03153.pdf
[02]Is ChatGPT a Good Recommender? A Preliminary Study
https://arxiv.org/pdf/2304.10149.pdf
[03]Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
https://arxiv.org/pdf/2303.14524.pdf
[04]A First Look at LLM-Powered Generative News Recommendation
https://arxiv.org/pdf/2305.06566.pdf
[05]Language Models as Recommender Systems: Evaluations and Limitations
https://openreview.net/pdf?id=hFx3fY7-m9b
[06]Prompt Learning for News Recommendation
https://arxiv.org/pdf/2304.05263.pdf
[07]Generating Personalized Recommendations via Large Language Models (LLMs)
https://www.tdcommons.org/cgi/viewcontent.cgi?article=6685&context=dpubs_series
[08]Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
https://arxiv.org/pdf/2203.13366.pdf
[09]Uncovering ChatGPT’s Capabilities in Recommender Systems
https://arxiv.org/pdf/2305.02182.pdf
[10]Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
https://arxiv.org/pdf/2305.07001.pdf
[11]A Survey on Large Language Models for Recommendation
https://arxiv.org/pdf/2305.19860.pdf
[12]M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
[13]PBNR: Prompt-based News Recommender System
https://arxiv.org/pdf/2304.07862.pdf
[14]LLM4Rec相关的论文
https://github.com/nancheng58/Awesome-LLM4RS-Papers
[15]Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models
https://arxiv.org/pdf/2305.13112.pdf
[16]Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction
https://arxiv.org/abs/2305.06474
[17]TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
[18]推荐策略产品经理必读系列—第二讲推荐系统的架构
https://www.woshipm.com/pmd/5541932.html
[19]《大语言模型的涌现能力:现象和解释》
https://zhuanlan.zhihu.com/p/621438653