大数据简介
- 大数据基础
- 平台架构
- 实际应用
- 关键技术
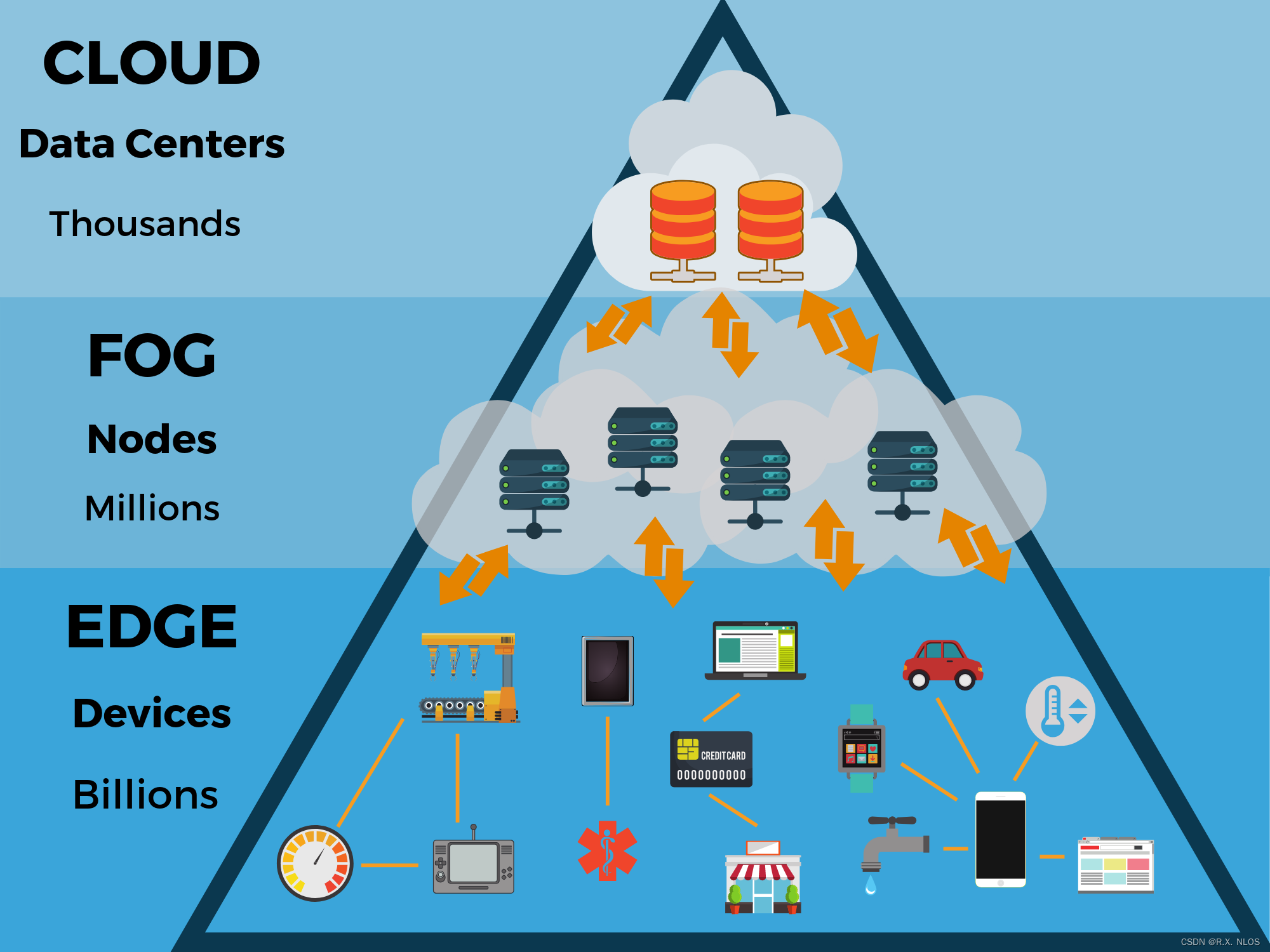
- Hadoop 分布式计算平台
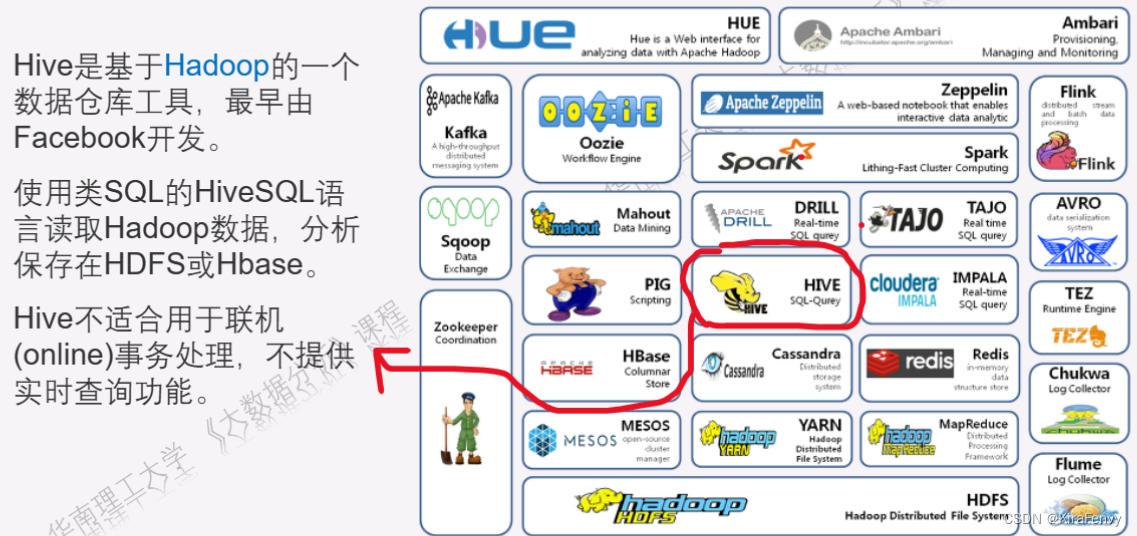
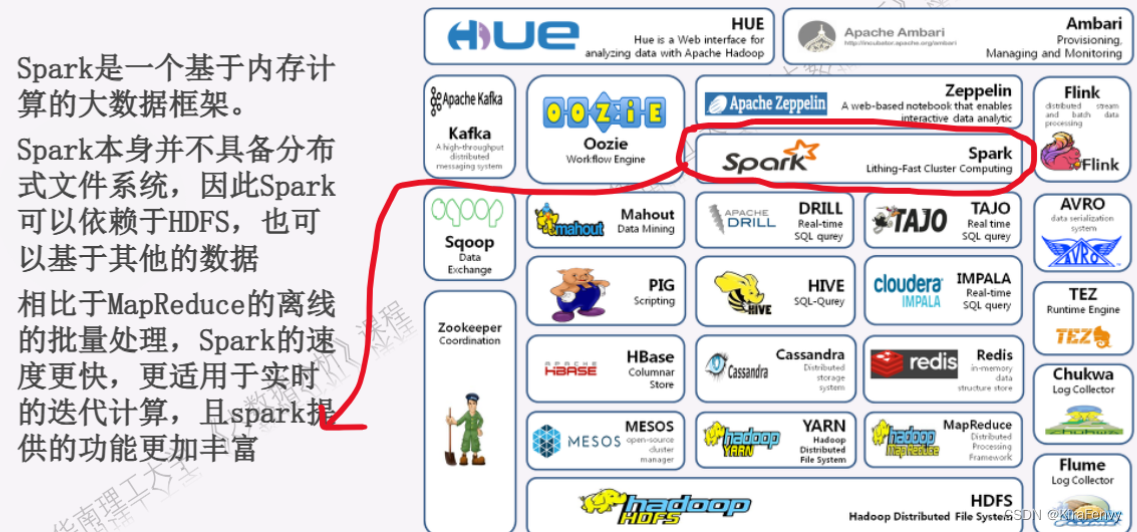
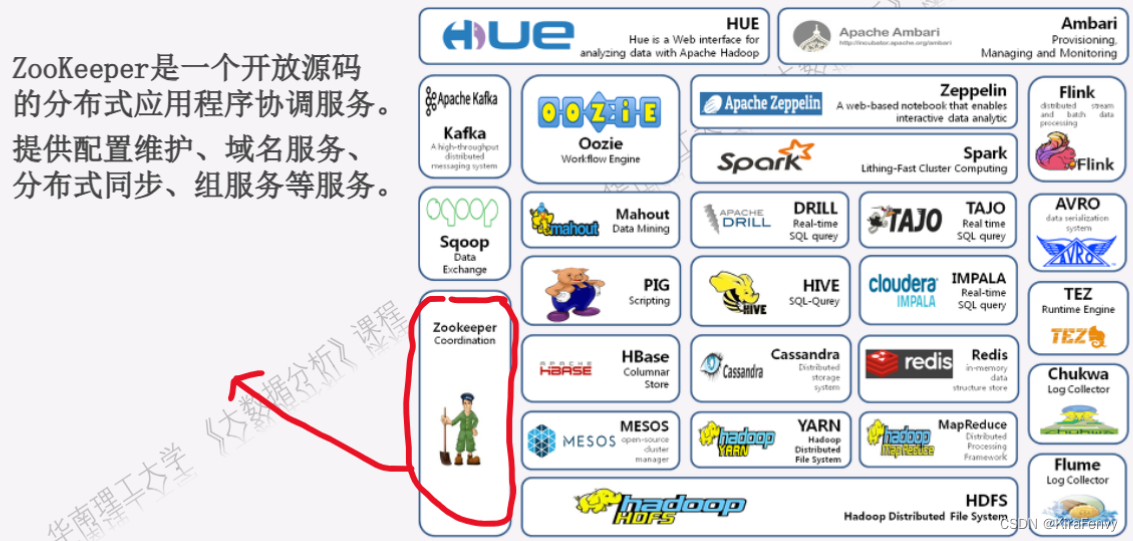
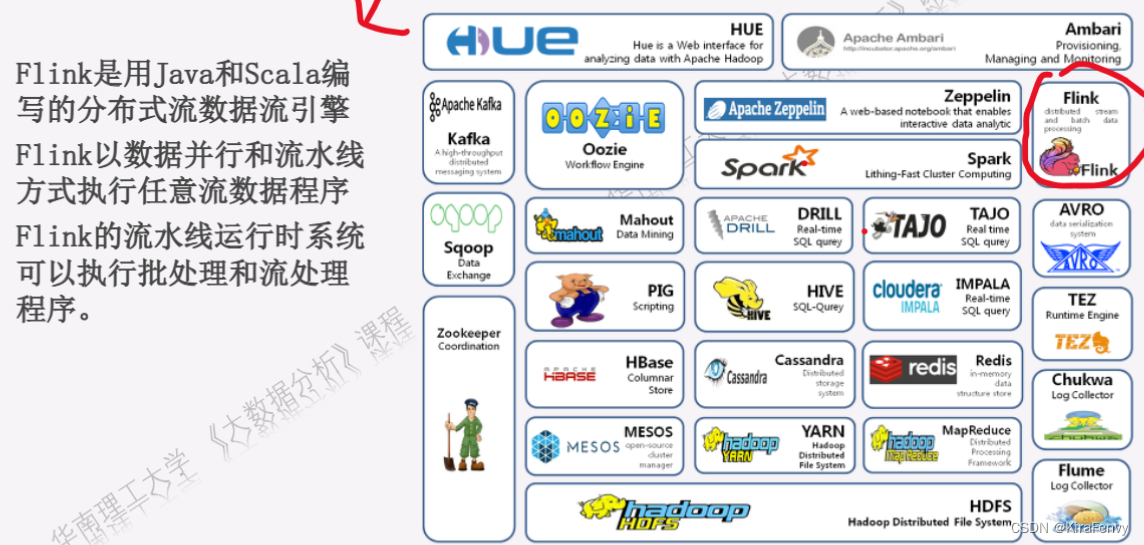
- Hadoop生态系统
- Hadoop安装和使用
- HDFS分布式文件系统
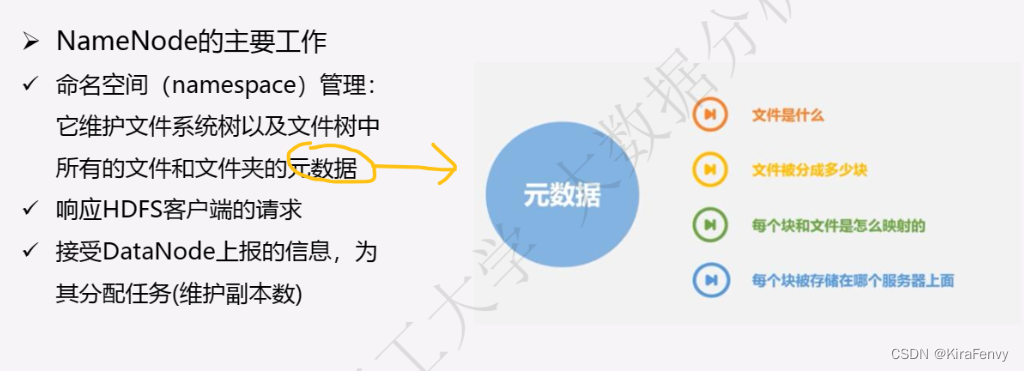
- Namenode
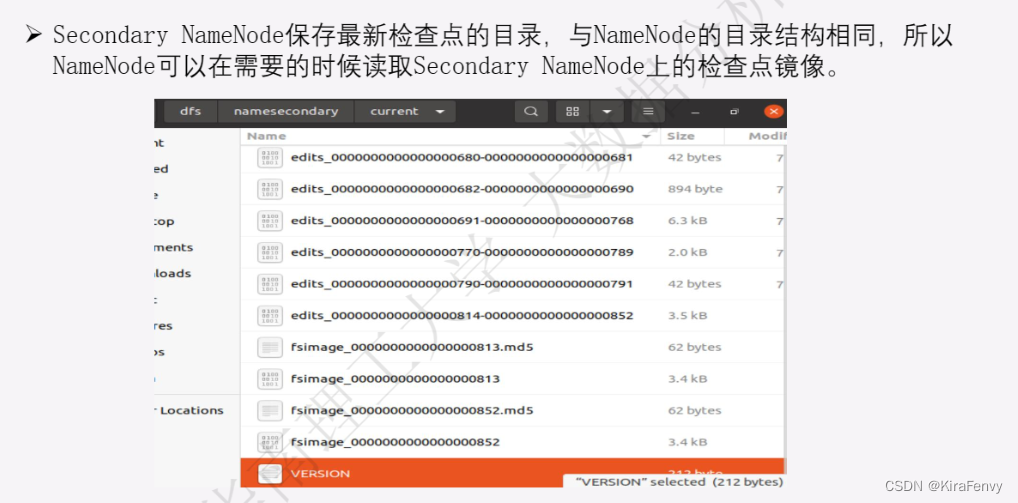
- Secondary Namenode
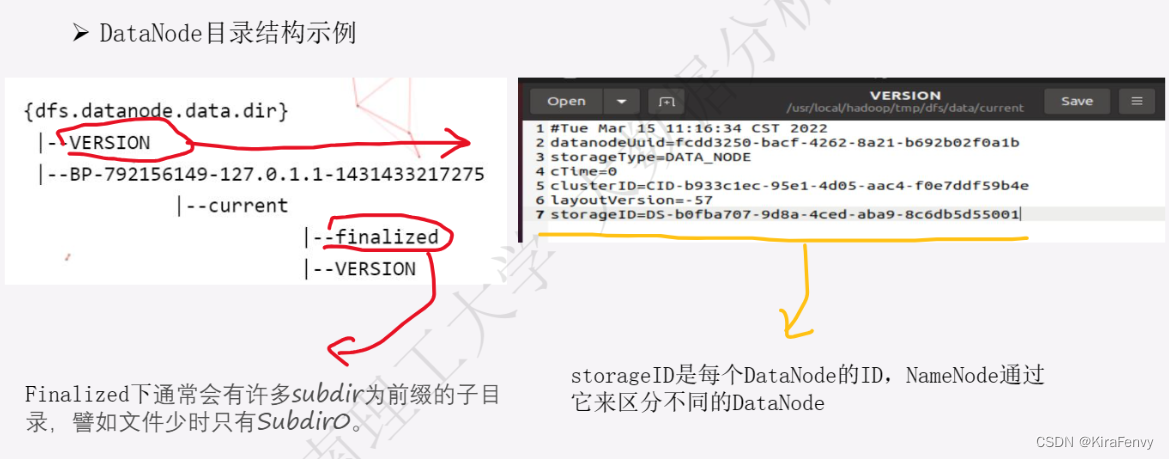
- DataNode
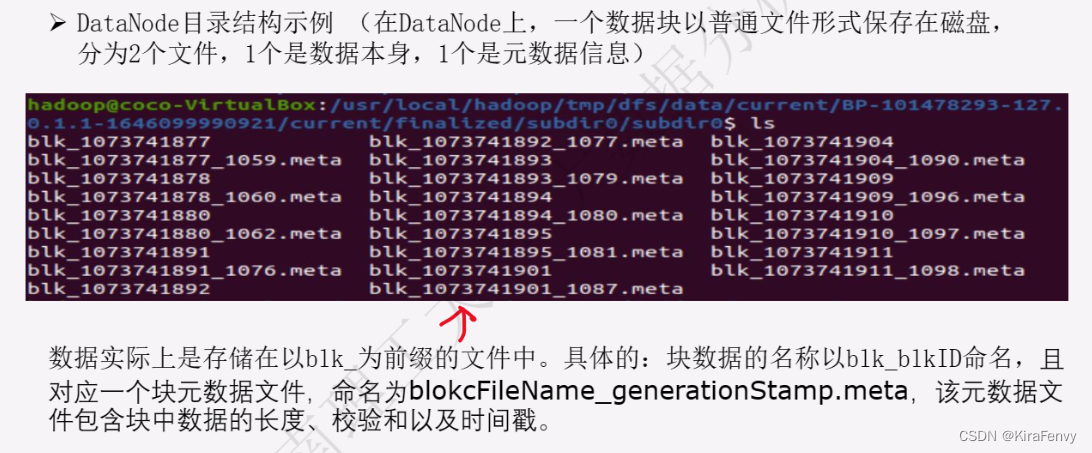
- block
大数据基础
平台架构







实际应用
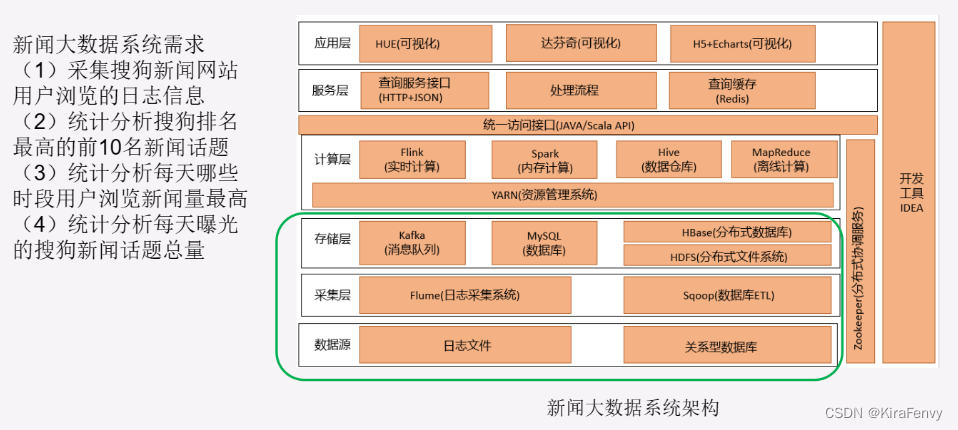
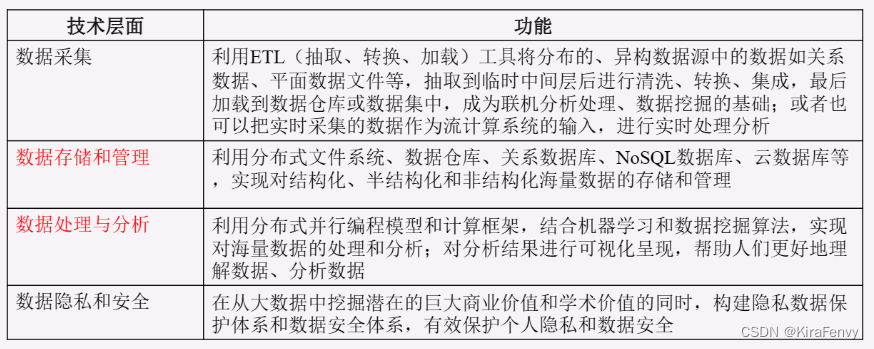
关键技术
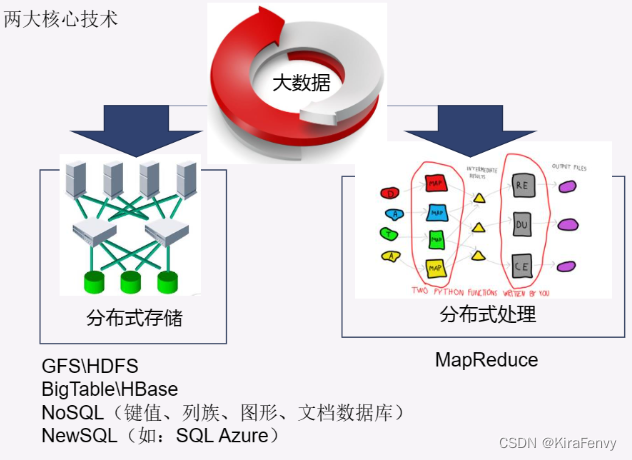


Hadoop 分布式计算平台

Hadoop生态系统

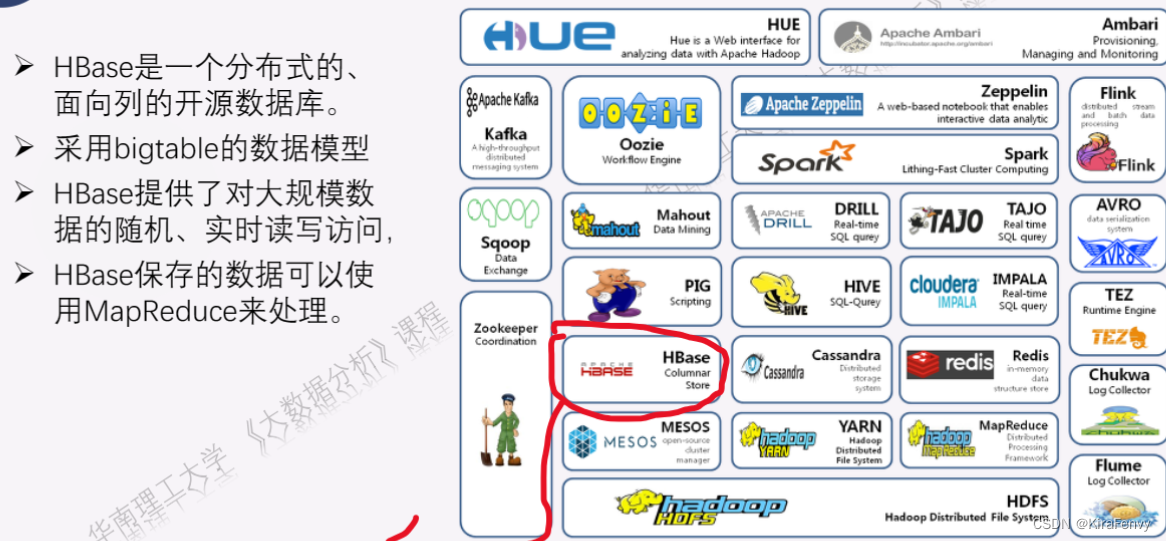
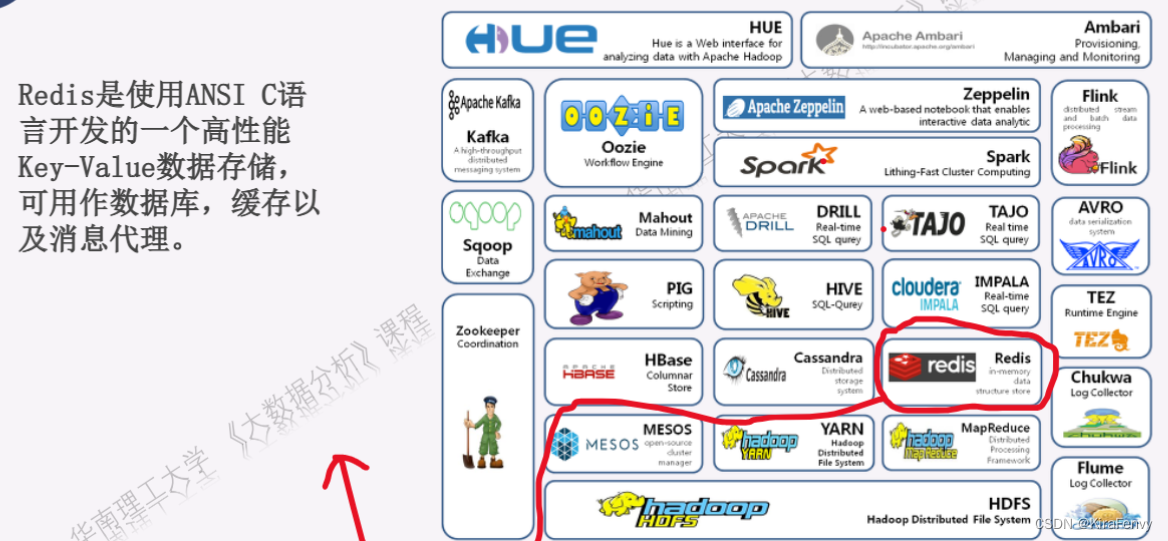

Hadoop安装和使用


参考http://dblab.xmu.edu.cn/blog/2441-2/
HDFS分布式文件系统

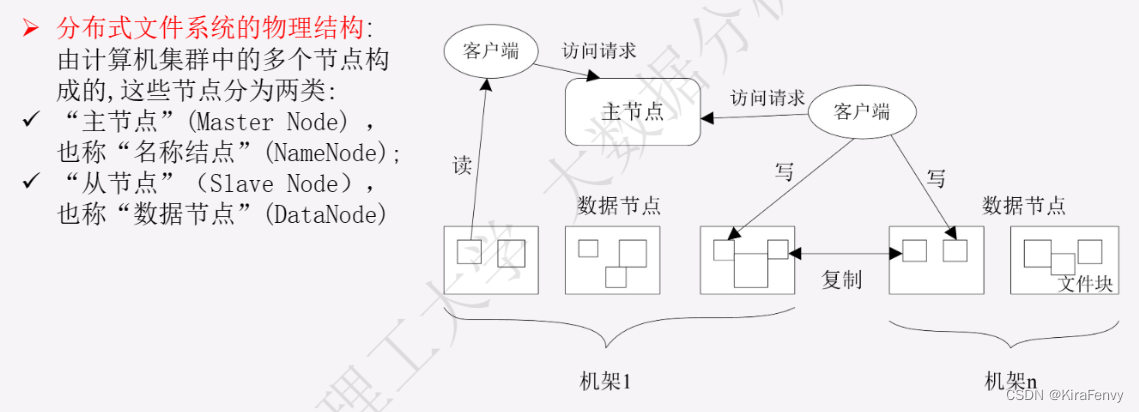
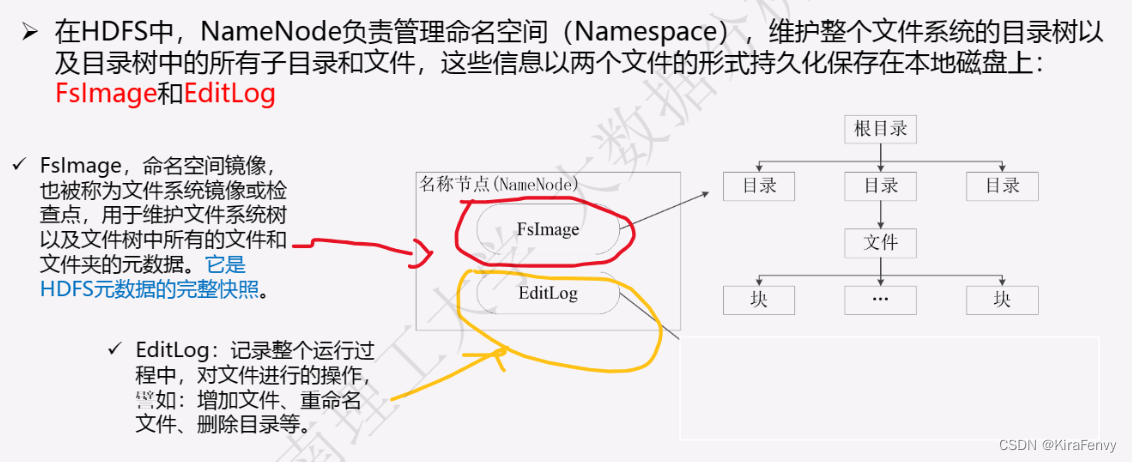
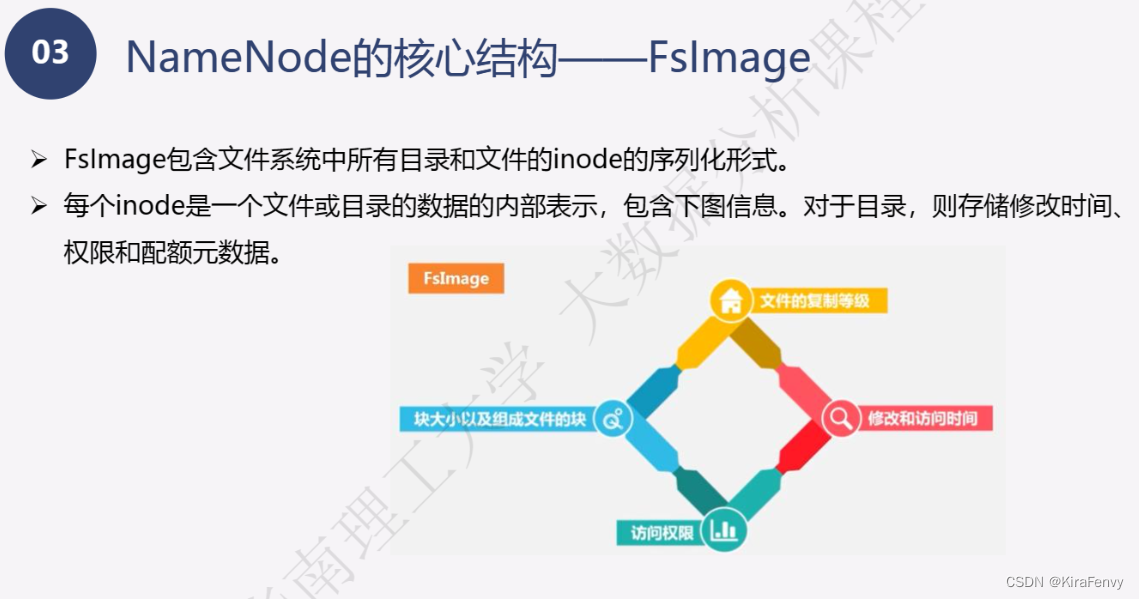
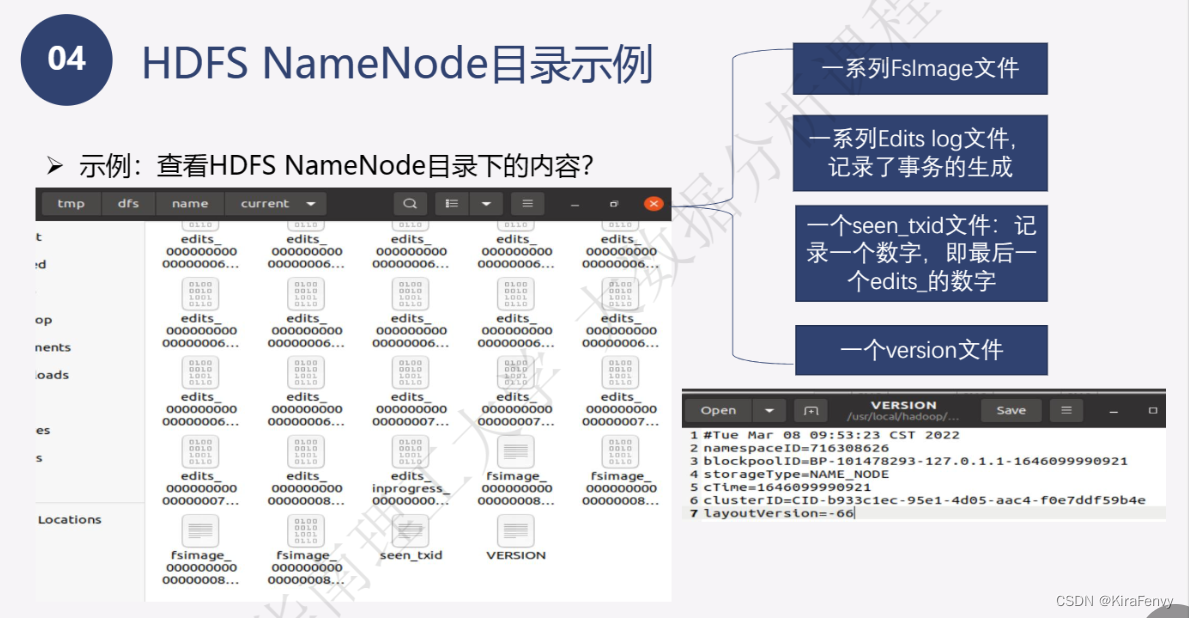
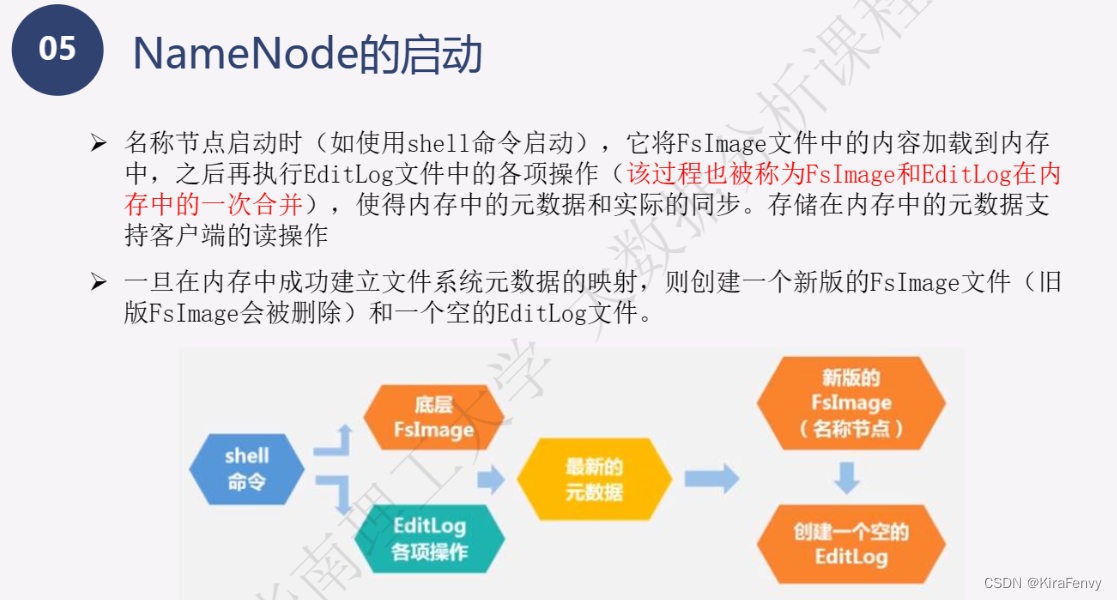
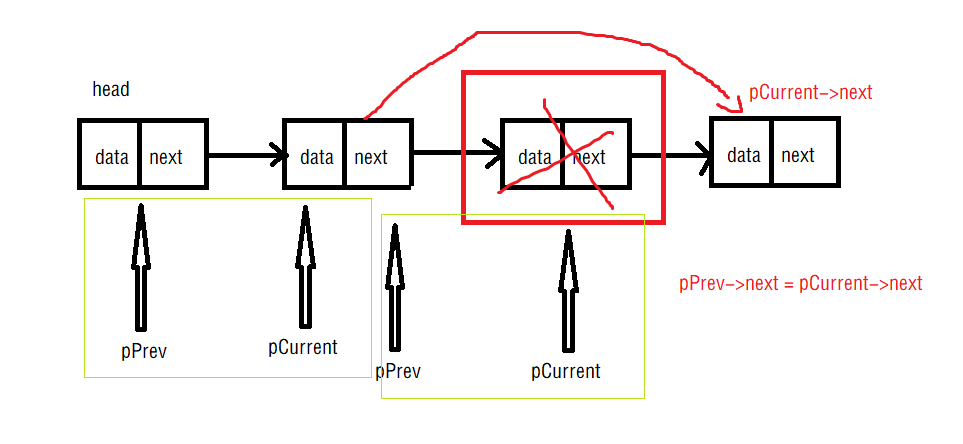
- Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。(NameNode是管理者,主要负责管理hdfs文件系统,具体包括namespace命名空间管理(即目录结构)和block管理)
- 客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。
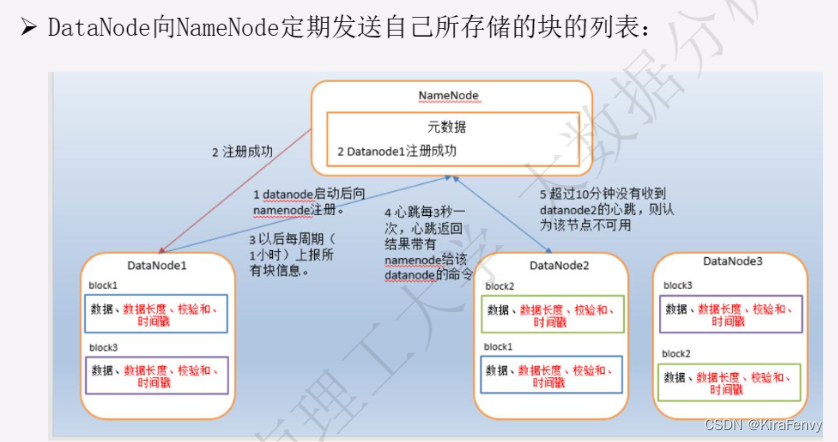
- Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。HDFS将一个文件分割成一个个的block,这些block可能存储在一个DataNode上或 者多个DataNode上。DataNode负责实际的底层的文件的读写。
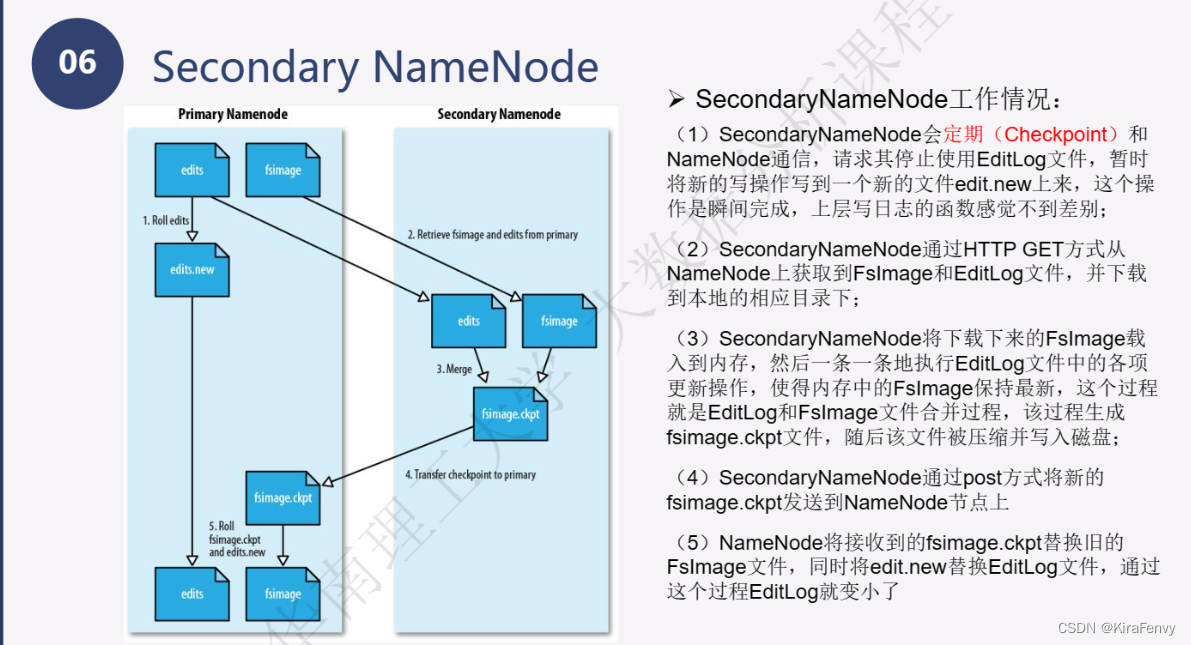
- SecondaryNameNode 主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。


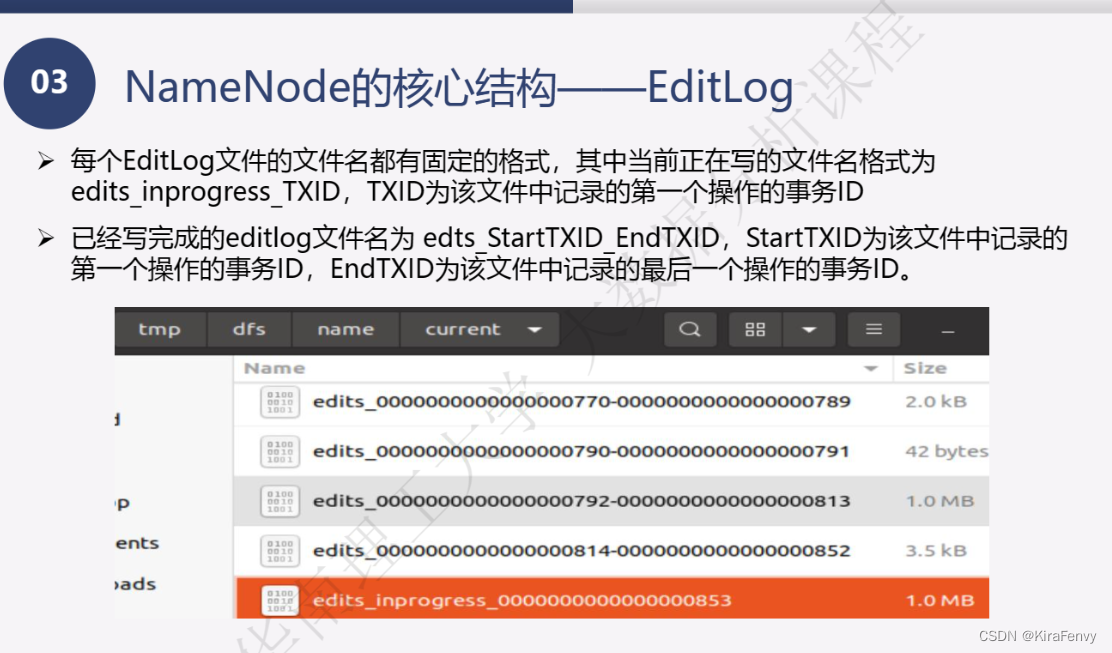
Namenode




Secondary Namenode


DataNode

block





![如何在 Windows 中免费合并 PDF 文件 [在线和离线]](https://img-blog.csdnimg.cn/11c35d35a15d4962a8169bc1df246439.png)