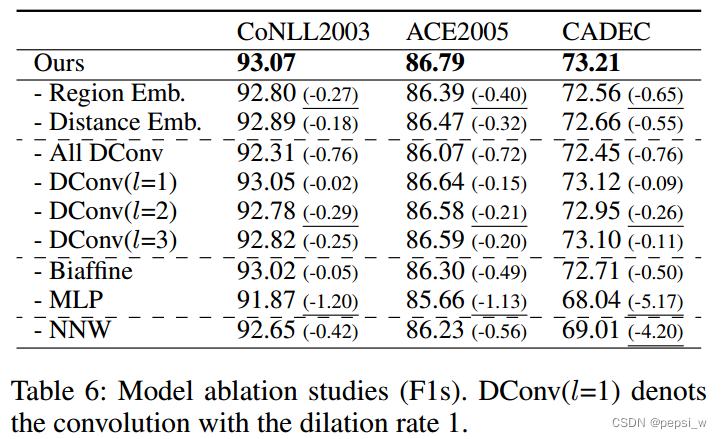
在处理音频文件时,有时候我们只希望提取其中的纯人声,以便进行后续处理或编辑。本文将介绍三种简单有效的方法,帮助您提取音频中的纯人声。方法一使用记灵在线工具,方法二使用Audacity,方法三则为您补充其他可选方案。
方法一:记灵在线工具
记灵是一款强大的在线音频编辑工具,它提供了音频分离功能,可将音频中的人声与背景音分离开来。以下是使用记灵在线工具提取音频纯人声的步骤:
-
打开记灵官方网站,找到“音乐人声提取”工具打开。
-
在线工具页面上传需要提取人声的文件,我们也可以通过拖拽上传音频文件。
-
上传完成后,点击“确认转换”按钮把音频文件提交到服务器进行转换。
-
稍等片刻,记灵将自动分离音频中的人声和背景音。
-
分离完成后,您可以点击人声或背景音轨道上的"下载文件"按钮,将其保存到您的设备中。

方法二:使用Audacity
Audacity是一款免费开源的音频编辑软件,它提供了一些简单但强大的工具来提取音频中的人声。以下是使用Audacity提取音频纯人声的步骤:
-
下载和安装Audacity。
-
打开Audacity,点击"File"(文件)菜单,选择"Open"(打开)并导入要处理的音频文件。
-
选择音频文件上的整个轨道,点击"Effect"(效果)菜单,选择"Vocal Reduction and Isolation"(人声减少和隔离)。
-
在弹出的对话框中,您可以选择"Remove Vocals"(去除人声)或"Isolate Vocals"(隔离人声),根据您的需求进行选择。
-
调整其他参数如"Slider"(滑块)和"Preview"(预览)选项,直到达到您满意的效果。
-
点击"OK"(确定)应用效果,Audacity将自动处理音频并分离人声。
-
完成后,您可以点击"File"(文件)菜单,选择"Export"(导出)将提取的纯人声保存为新的音频文件。

方法三:使用深度学习模型
除了上述两种方法,还可以利用深度学习模型进行音频纯人声提取。深度学习模型通常需要进行训练,但一些预训练模型已经提供了相应的功能。您可以使用已训练好的模型,如Spleeter或OpenUnmix,它们可以有效地分离音频中的人声和伴奏。

结论:
无论您是选择记灵在线工具、Audacity还是深度学习模型,提取音频中的纯人声都变得相对简单。根据您的需求和个人偏好,选择适合您的方法,并开始提取音频中的纯人声吧!