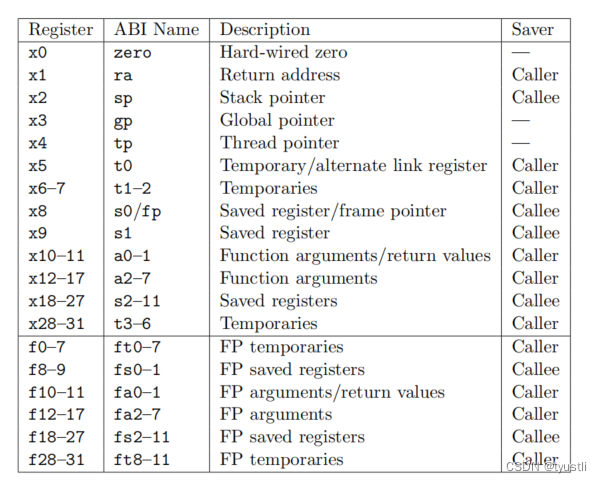
原文链接:https://arxiv.org/pdf/2112.10070.pdf
AAAI 2022
介绍
NER主要包括三种类型:flat、overlap和discontinuous。目前效果最好的模型主要是:span-based和seq2seq,但前者注重于边界的识别,后者可能存在exposure bias。
作者对entity words之间的相邻关系进行建模,将NER定义为一个word-word之间的关系分类任务,一共定义三种关系NONE、Next-Neighboring-Word(NNW)、Tail-Head-Word-*(THW-S)如下图所示:

方法
模型的整体架构如下图所示,主要包括三个部分:BERT和LSTM组合而成的encoder、用于建立和完善word-pair grid表征的卷积层,Biaffine和MLP联合的分类层:

Encoder Layer
使用BERT+BiLSTM来作为encoder,将一个词的pieces经过一个max pooling来得到该词的表征,送入到BiLSTM来进一步获取上下文信息,得到word表征为,
表示每个word embedding的维度。
Convolution Layer
使用CNN来优化表征,包括三个模块,1)condition layer,用于生成word-pair grid的表征;2)用于丰富word-pair grid表征的bert式grid表征;3)用于捕捉相邻词和distant word之间交互的多粒度扩张卷积。
Conditional Layer Normalization
为了预测word pairs之间的关系,将word-pair gird的表征视为3维的矩阵V,vij表示word pair(xi,xj),而不是(xj,xi),因为NNW和THW关系是有方向的,Vij由xi和ji计算得出。如下所示:

BERT-Style Grid Representation Build-Up
BERT中的输出由token embedding、position embedding和segment embedding组成,作者受此启发,使用(词的信息)、
(每对单词之间的相对位置)和
(区域信息,用于表示网格中上三角和下三角)这三种embedding进行concate后送入MLP得到最终的网格表征
:
![]()
Multi-Granularity Dilated Convolution
使用不同扩张率()的二维扩张卷积来捕获不同距离word之间的交互,经过多次扩张中,得到最终word-pair的表征
,

Co-Predictor Layer
作者使用MLP和biaffine分别进行预测分类(作者说是因为之前有论文说这样效果更好),最将两者的结果进行合并。不过biaffine模型是将encoder的输出作为输入(即图中虚线的表示) ,使用两个MLP分别计算xi和yj的word presentation,然后使用biaffine classifier来计算这对词之间的关系分数作为预测结果:

而NLP是基于word-pair grid表征,使用一个MLP来计算单词对之间的分数
,最后将两者的结果进行结合:
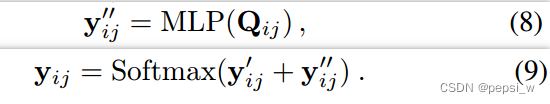
Decoder
以上步骤后,模型的输出可以视为一个词的有向图,解码的目标就是利用NNW在图中找到从一个词到另一个词的特定路径,每条路对应着一个实体部分。下图描述了4种从易到难的情况:

4)仅使用NNW关系的情况下能在这个例子中找到4条路径,如果只使用THW只能找到识别到ABCD,而不是ACD或者BCD,因此通过同时使用这两者关系来获得正确答案。
Learning
损失函数:

N是句子中单词的个数,y是gold relation labels的二值向量(xi,yj),r表示集合R中预定义好的第r种关系。
实验
对比试验
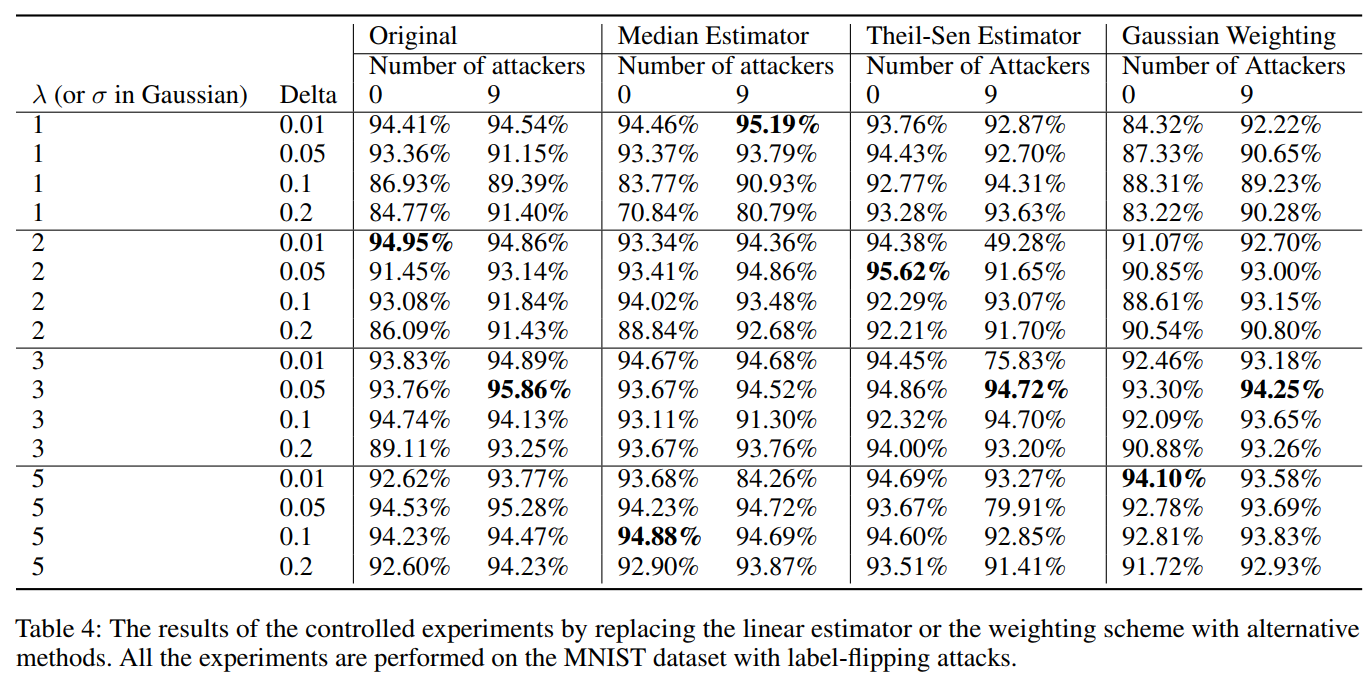
在英文flat NER数据集上进行实验,结果如下所示:

在中文flat NER数据集上进行实验,结果如下图所示:

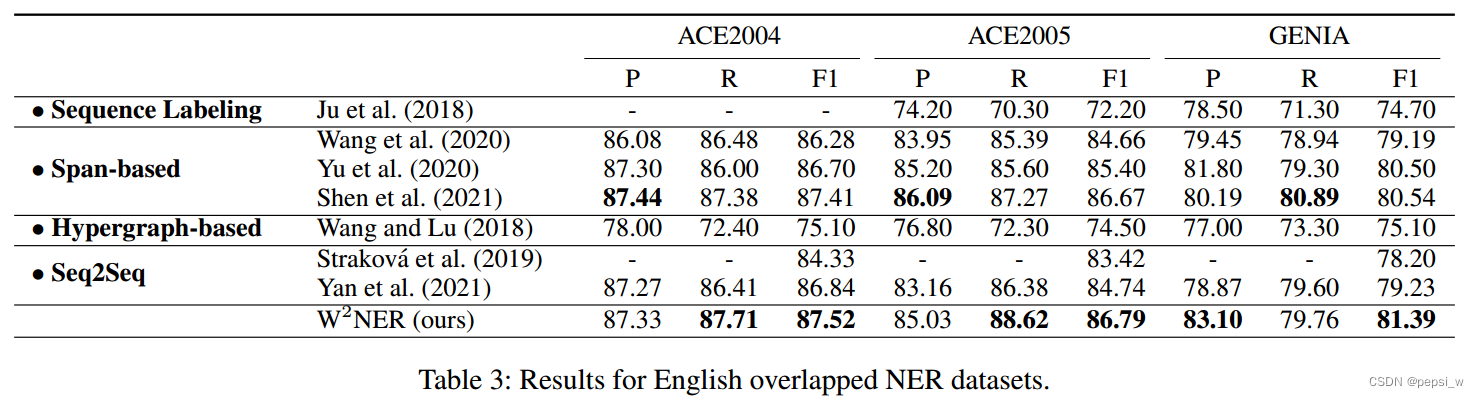
在英文overlap数据集上进行实验,结果如下图所示:
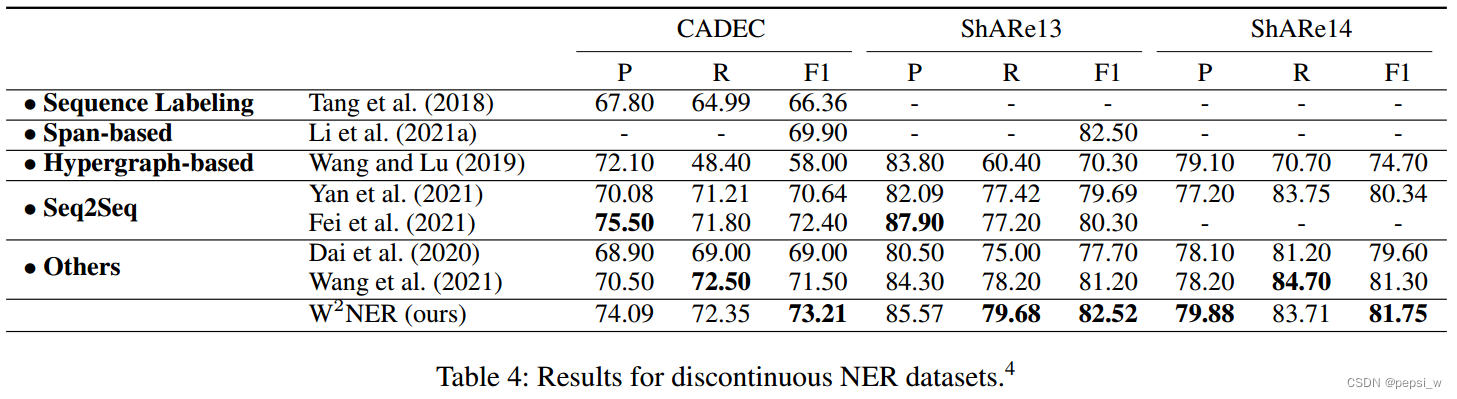
在discontinuousNER数据集上进行实验,结果如下图所示:
在中文overlapNER数据集上进行实验,结果如下图所示:

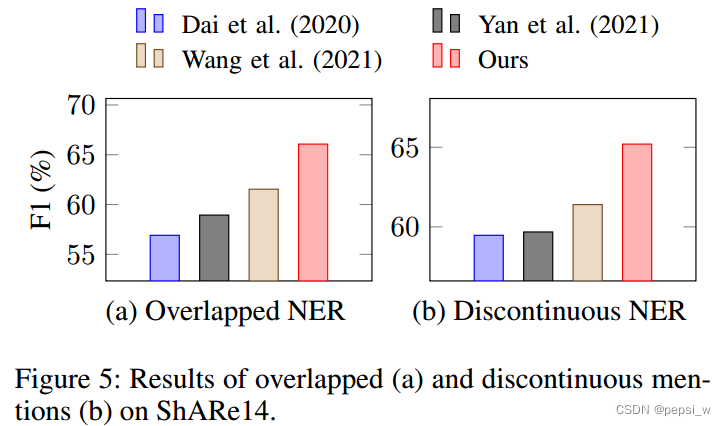
作者在只有overlap和discontinue的数据集进行了实验,结果如下图所示,这样一对比就突出了W2NER模型的优势。
消融实验
在三个数据集上进行消融实验,结果如下所示:
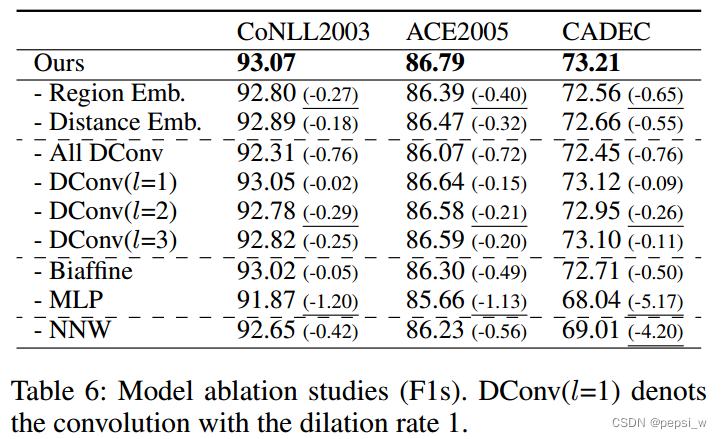
移除NNW关系时,所有数据集上的F1都有所下降,特别时CADEC数据集上,F1下降了4.2%,这是因为CADEC数据种包括不连续实体,如果没有NNW关系,discontinuedNER会被识别为连续span。
总结
作者将NER问题视为词与词之间的关系, 这样就能灵活的解决discontinueNER的问题,最后在discontinue的数据集上表现更为明显。不过感觉作者构建的网格有点复杂的亚子(不能用其他方式简化一下吗?),另外,作者也提到使用两个分类器进行分类,对模型的效果也有一定的提升,感觉可以借鉴一下。