torch分布式通信基础
- 1. 点到点通信
- 2. 集群通信
官网文档:WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
1. 点到点通信
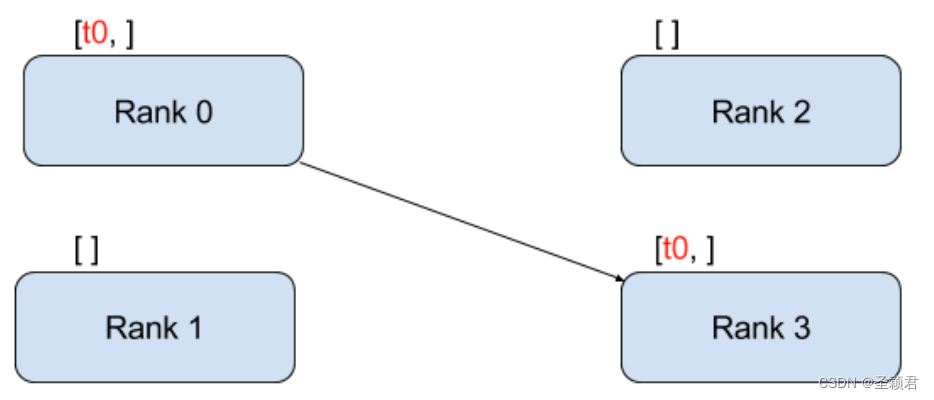
# 同步,peer-2-peer数据传递
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def test_send_recv_sync(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
dist.send(tensor=tensor, dst=1) # 需要指定dst,发送的目标
else:
dist.recv(tensor=tensor, src=0) # 需要指定src,从哪儿接收
print('Rank ', rank, ' has data ', tensor[0])
# 异步
def test_send_recv_async(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
req = dist.isend(tensor=tensor, dst=1)
else:
req = dist.irecv(tensor=tensor, src=0)
req.wait()
print('Rank ', rank, ' has data ', tensor[0])
def init_process(rank, size, backend='gloo'):
""" 这里初始化分布式环境,设定Master机器以及端口号 """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29598'
dist.init_process_group(backend, rank=rank, world_size=size)
#test_send_recv_sync(rank, size)
test_send_recv_async(rank, size)
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size))
p.start()
processes.append(p)
for p in processes:
p.join()
2. 集群通信
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
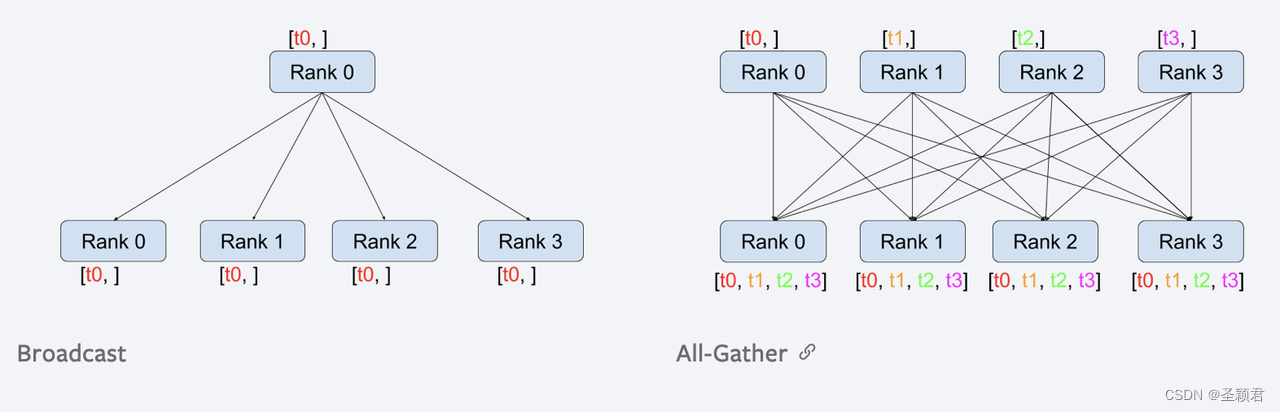
def test_broadcast(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 2
else:
tensor += 1
dist.broadcast(tensor=tensor,src=0) # src指定broad_cast的源
print("******test_broadcast******")
print('Rank ', rank, ' has data ', tensor) # 结果都是 2
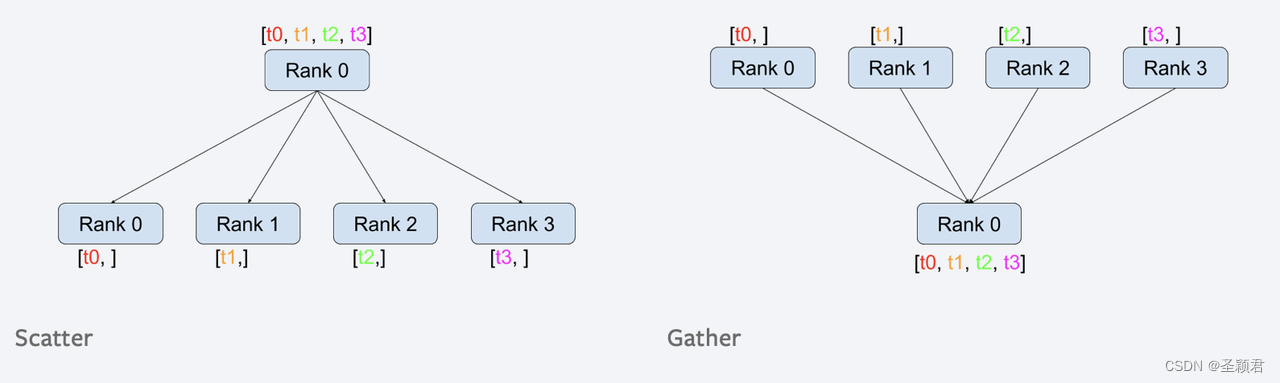
def test_scatter(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor_list = [torch.tensor([1.0]), torch.tensor([2.0]), torch.tensor([3.0]), torch.tensor([4.0])]
dist.scatter(tensor, scatter_list = tensor_list, src = 0)
else:
dist.scatter(tensor, scatter_list = [], src = 0)
print("******test_scatter******")
print('Rank ', rank, ' has data ', tensor) # 结果是[[1], [2], [3], [4]]
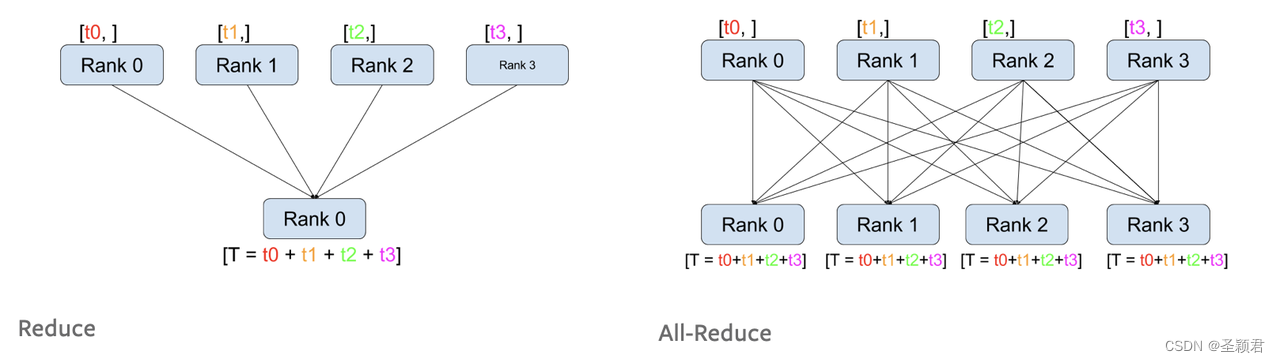
def test_reduce(rank, size):
tensor = torch.ones(1)
dist.reduce(tensor=tensor, dst=0) # dst指定哪个进程进行reduce, 默认操作是加法
print("******test_reduce******")
print('Rank ', rank, ' has data ', tensor)
def test_all_reduce(rank, size):
tensor = torch.ones(1)
dist.all_reduce(tensor=tensor,op=dist.ReduceOp.SUM)
print("******test_all_reduce******")
print('Rank ', rank, ' has data ', tensor) # 结果都是 4
def test_gather(rank, size):
tensor = torch.ones(1)
if rank == 0:
output = [torch.zeros(1) for _ in range(size)]
dist.gather(tensor, gather_list=output, dst=0)
else:
dist.gather(tensor, gather_list=[], dst=0)
if rank == 0:
print("******test_gather******")
print('Rank ', rank, ' has data ', output) # 结果是 [[1,1,1,1]]
def test_all_gather(rank, size):
output = [torch.zeros(1) for _ in range(size)]
tensor = torch.ones(1)
dist.all_gather(output, tensor)
print("******test_all_gather******")
print('Rank ', rank, ' has data ', output) # 结果都是 [1,1,1,1]
def init_process(rank, size, backend='gloo'):
""" 这里初始化分布式环境,设定Master机器以及端口号 """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29596'
dist.init_process_group(backend, rank=rank, world_size=size)
test_reduce(rank, size)
test_all_reduce(rank, size)
test_gather(rank, size)
test_all_gather(rank, size)
test_broadcast(rank, size)
test_scatter(rank, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size))
p.start()
processes.append(p)
for p in processes:
p.join()
需要注意的一点是:
这里面的调用都是同步的,可以理解为,每个进程都调用到通信api时,真正的有效数据传输才开始,然后通信完成之后,代码继续往下跑。实际上有些通信进程并不获取数据,这些进程可能并不会被阻塞。
文档最后,提供了一个简单的类似 DDP 的实现,里面核心的部分就是:
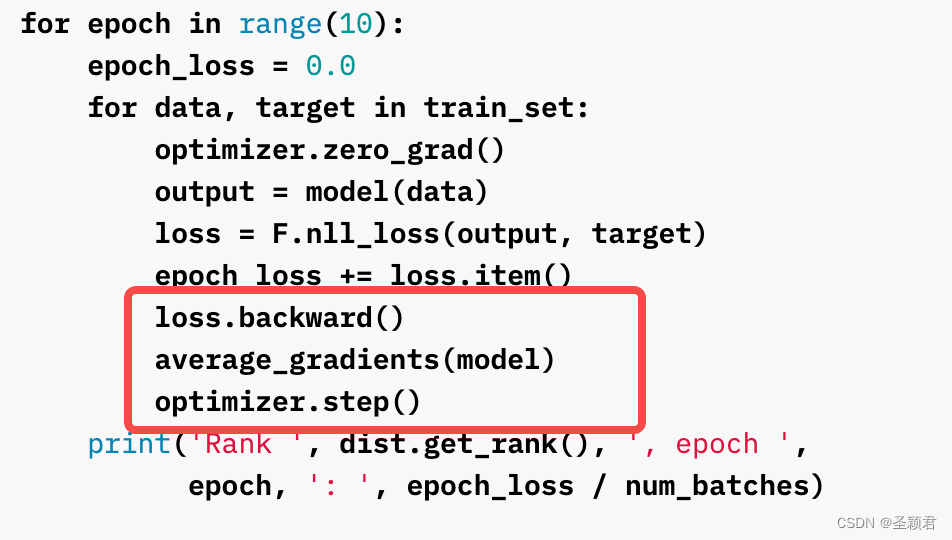

这也进一步阐释了DDP的核心逻辑:
反向计算完成之后,汇总梯度信息(求均值),然后再更新参数