1. 概述
说到热点问题,首先我们先理解一下什么是热点?
热点通常意义来说,是指在一段时间内,被广泛关注的物品或事件,例如微博热搜,热卖商品,热点新闻,明星直播等等,所以热点产生主要包含 2 个条件:1. 有限时间, 2 流量高聚。

而在互联网领域,热点又主要分为 2 大类:
1. 有预期的热点:比如在电商活动当中推出的爆款联名限量款的商品,又或者是秒杀的会场活动等
2. 无预期的热点:比如受到了黑客的恶意攻击,网络爬虫频繁访问,又或者突发新闻带来的流量冲击等
针对于有预期的热点可以通过热点数据预热, 流量限制和异步队列进行处理。但是对于突发性无感知的热点数据流量,往往由于请求过于集中,导致访问数据流量超出的 server 的正常负载水位,从而出现服务过载不可用的情况,这种问题被称之为热点问题。
2. 热点场景
看完关于热点问题的简单介绍,我们已经理解了热点产生的条件是短时间内被频繁访问导致流量高聚,而流量高聚就会出现一系列的热点问题。那被频繁访问的 Key,就是我们通常所说的热 Key。
接下来我们来看一下哪些场景会导致热点问题以及对应的热 Key:
-
MySQL 中被频繁访问的数据 ,如热门商品的主键 Id
-
Redis 缓存中被密集访问的 Key,如热门商品的详情需要 get goods$Id
-
恶意攻击或机器人爬虫的请求信息,如特定标识的 userId、机器 IP
-
频繁被访问的接口地址,如获取用户信息接口 /userInfo/ + userId
3. 热点探测技术原理
了解完什么是热点问题和热 Key 出现的场景以后,我们会提出一个疑问,如何去提前感知这些热点数据?这里就需要聊到热点探测技术。
3.1 热点探测可以带来什么好处?
3.1.1 提升性能
解决热点问题通常会使用分布式缓存,但是在读取时还是需要进行网络通讯,就会有额外的时间开销。那如果能对热点数据提前进行本地缓存,即本地预热,就能大幅提升机器读取数据的性能,减轻下层缓存集群的压力。
- 注意,本地缓存与实时数据存在不一致的风险。需要根据具体业务场景进行评估,缓存级数越多,数据不一致的风险就越大!
3.1.2 规避风险
对于无预期的热数据(即突发场景下形成的热 Key),可能会对业务系统带来极大的风险,可将风险分为两个层次:
- 对数据层的风险
正常情况下,Redis 缓存单机就可支持十万左右 QPS,并能通过集群部署提高整体负载能力。对于并发量一般的系统,用 Redis 做缓存就足够了。但是对于瞬时过高并发的请求,因为 Redis 单线程原因会导致正常请求排队,或者因为热点集中导致分片集群压力过载而瘫痪,从而击穿到 DB 引起服务器雪崩。
- 对应用服务的风险
每个应用在单位时间所能接受和处理的请求量是有限的,如果受到恶意请求的攻击,让恶意用户独自占用了大量请求处理资源,就会导致其他人畜无害的正常用户的请求无法及时响应。
因此,需要一套动态热 Key 检测机制,通过对需要检测的热 Key 规则进行配置,实时监听统计热 Key 数据,当无预期的热点数据出现时,第一时间发现他,并针对这些数据进行特殊处理。如本地缓存、拒绝恶意用户、接口限流 / 降级等。
3.2 如何进行热点探测?
首先我们要定义一下如何才能算是一个热点,我们知道热点产生的条件是 2 个:一个时间,一个流量。那么根据这个条件我们可以简单定义一个规则:比如 1 秒内访问 1000 次的数据算是热数据,当然这个数据需要根据具体的业务场景和过往数据进行具体评估。
对于单机应用,检测热数据很简单,直接在本地为每个 Key 创建一个滑动窗口计数器,统计单位时间内的访问总数(频率),并通过一个集合存放检测到的热 Key。

而对于分布式应用,对热 Key 的访问是分散在不同的机器上的,无法在本地独立地进行计算,因此,需要一个独立的、集中的热 Key 计算单元。
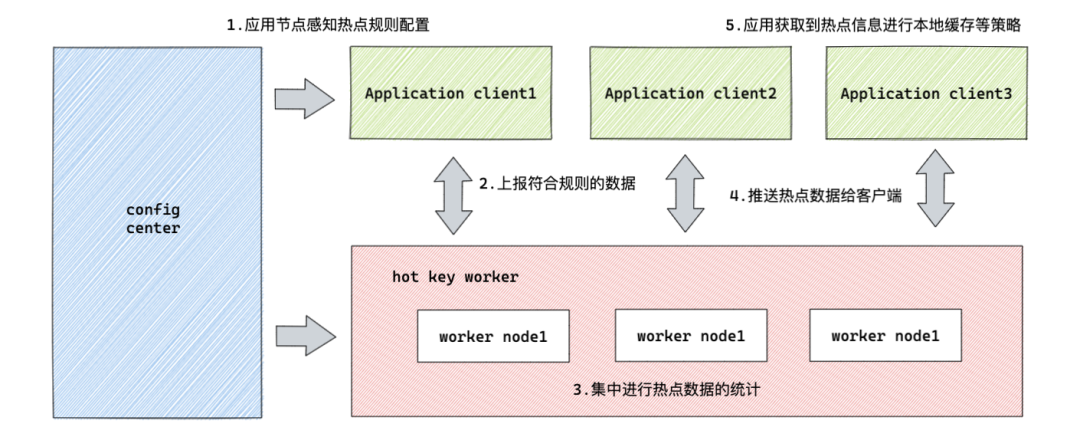
我们可以简单理解为:分布式应用节点感知热点规则配置,将热点数据进行上报,工作节点进行热点数据统计,对于符合阈值的热点进行推送给客户端,应用收到热点信息进行本地缓存等策略这五个步骤:
1. 热点规则:配置热 Key 的上报规则,圈出需要重点监测的 Key
2. 热点上报:应用服务将自己的热 Key 访问情况上报给集中计算单元
3. 热点统计:收集各应用实例上报的信息,使用滑动窗口算法计算 Key 的热度
4. 热点推送:当 Key 的热度达到设定值时,推送热 Key 信息至所有应用实例
5. 热点缓存:各应用实例收到热 Key 信息后,对 Key 值进行本地缓存(此步骤根据具体业务策略调整)
4.Burning
理解完热点探测原理以后,我们来聊聊得物的热点探测中间件 Burning。
作为潮流互联网电商平台,得物的电商业务高速发展,突发性的热点数据不断的冲击着我们的系统服务,比如大促秒杀,热点商品,恶意攻击等等。针对于这种突发性的大流量,单纯的机器扩容并不是一个有效的解决手段,我们需要一个集热点探测,热点感知,热点数据推送,热点数据预热,热点监控分析等功能于一体的热点探测中间件,因此 Burning 应运而生。
4.1 价值意义
Burning 作为得物的热点探测中间件,提供可供业务方接入的 SDK 包和管理台规则配置,用于对热点数据的实时性监控,探测,操作和本地缓存等。主要解决了以下问题:
-
实时热点感知:能实时监控热点数据,包含热 Key,热数据,热接口等,秒级上报集群统一计算
-
本地数据预热:对于特定场景可以通过动态本地缓存配置,防止流量突增导致 Redis 或 DB 数据流量压力过大导致系统雪崩
-
周期热点统计:对热点数据进行周期性统计分析,标记出热 Key 规则及分布比例等,可以帮助业务方进行针对性优化治理和营销策略选择
-
系统安全治理:可以通过热点 Key 探测分析,对于刷子用户,问题 IP,机器人和爬虫进行标识,可实时熔断存在安全风险的请求,提高系统安全和可用性
4.2 关键指标
为满足高并发场景,热点探测中间件 Burning 在设计的时候,重点关注了如下指标:
1. 实时性:热点问题往往具备突发性,客户端必须能够实时发现可疑热 Key 并推送给计算单元进行探测
2. 高性能:热点探测往往需要处理大量的热点探测请求和热点计算,因此热点探测中间件的性能要求较高,才能满足巨量的并发并有效降低成本
3. 准确性:热点探测需要精准的探测符合规则热 Key,实时监听规则的变化,正确的进行热 Key 上报和热 Key 计算
4. 一致性:热点探测需要保证应用实例的本地缓存热 Key 一致,当热 Key 变更导致 value 失效时,应用需要同时进行失效来保证数据一致性,不能出现数据错误
5. 可扩展:热点探测需要统计和计算的 Key 量级很大,而且存在突发流量的情况,统一计算集群需要具备水平扩展的能力
4.3 架构设计
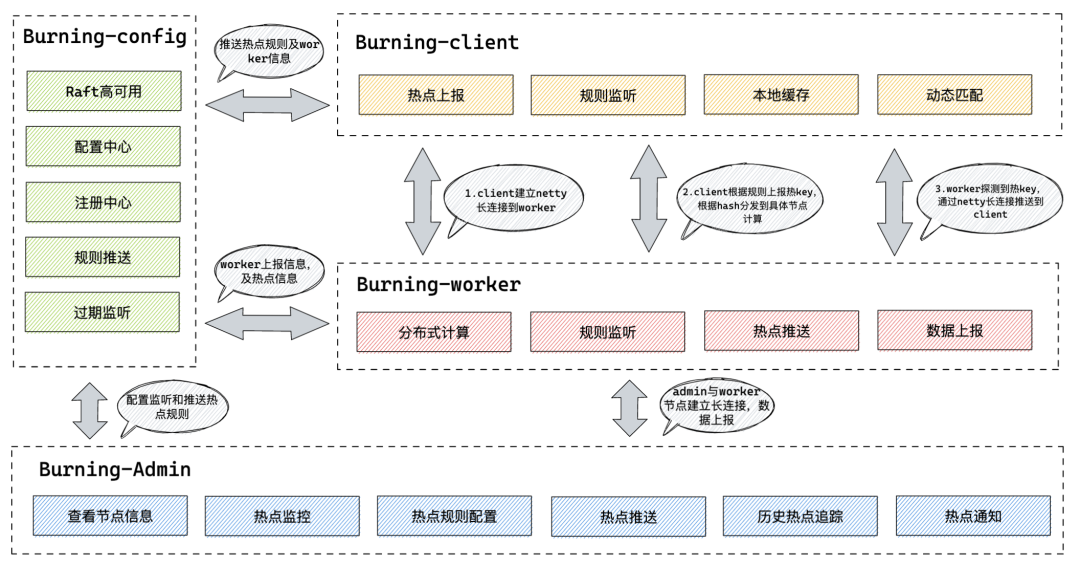
Burning 的架构设计遵循了以上热点探测的技术原理,同时借鉴了 jd-hotKey 的设计思路,主要分为 Burning-Admin、Burning-Worker、Burning-Config、Burning-Client 四个模块:
-
Burning-Admin (热点探测管理台):与 Worker 节点 Netty 长链接通信,提供不同维度的应用管理和热点规则配置,提供查询热点数据统计,规则和热点数据监控大盘,提供工作集群信息查询及客户端节点信息查询,提供本地缓存动态配置及热点信息实时通知
-
Burning-Worker(热点集中计算单元):无状态 server 端,与管理台和客户端进行 Netty 长链接通信,获取规则,滑动窗口计算热点,将热点记录推送到管理台展示和客户端处理
-
Burning-Config(热点配置中心):作为热点、规则配置中心和注册中心,将规则配置下发到 Worker 节点和客户端,通过 Raft 算法进行系统高可用一致性保证
-
Burning-Client(热点客户端 SDK):与 Worker 节点建立 Netty 长链接通信,监听配置中心配置变化定时推送热 Key 数据,获取热 Key 推送本地内缓存设置,与 Redis-client 无缝集成及其他 ORM 框架无缝集成
4.4 链路流程
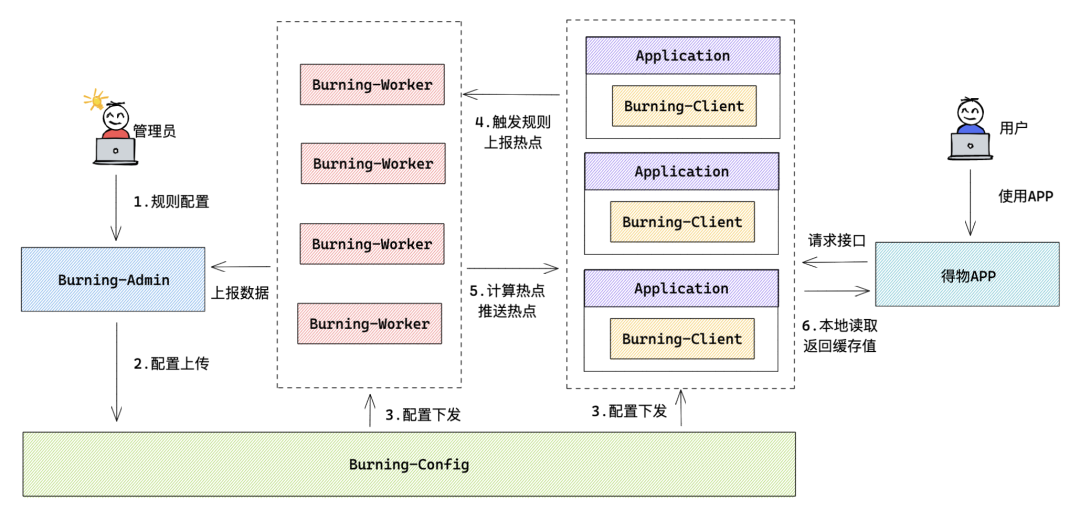
热点探测主要包含以下几个主要流程:
1. 用户在管理后台(Burning-Admin)进行热点规则配置并进行热点数据实时监控
2. 管理后台(Burning-Admin)将规则配置信息上传给配置中心(Burning-Config)
3. 配置中心(Burning-Config)将热点规则下发给客户端(Buring-Client)和工作节点(Burning-Worker)
4. 客户端(Burning-Client)获取到规则, 将指定规则的热 Key 定时上报给工作节点(Burning-Worker)
5. 工作节点(Burning-Worker)获取到上报的热 Key 后进行滑动时间窗口计算,对于满足阈值的热点推送给客户端(Burning-Client)
6. 客户端(Burning-Client)拿到热点数据后,进行对应的本地缓存配置
4.5 核心代码
- 客户端启动器 ClientStarter,启动配置中心和注册中心,Worker 建连,注册事件监听,设置 app_name、port、caffeine 缓存大小、cache 配置、监控配置等
public synchronized static void startPipeline(BurningCommonProperties burningCommonProperties) {
if (STARTED.get() == Boolean.FALSE) {
DwLogger.info("start pipeline");
// 设置参数上下文
setToContext(burningCommonProperties);
// 配置中心启动
EtcdConfigFactory.buildConfigCenter(burningCommonProperties.getConfigServer());
ConfigStarter starter = EtcdConfigStarter.getInstance();
starter.start();
// 注册中心启动
RegisterFactory.buildRegisterCenter(burningCommonProperties);
RegisterStarter registerStarter = RegisterStarter.getInstance();
registerStarter.start();
// 热点探测启动
DetectFactory.startDetect(burningCommonProperties.getPushPeriod());
// 开启worker重连器
WorkerRetryConnector.retryConnectWorkers();
// 注册事件监听
registEventBus();
// 开启监控
MetricsFactory.startMetrics();
STARTED.set(Boolean.TRUE);
}
}
- 客户端进行热 Key 判断,如果符合规则就上报给 Worker 节点计算,同时进行统计计数
public static Object dynamicGetValue(String key, KeyType keyType) {
try {
//如果没有为该key配置规则,就不用上报key
Boolean dynamicRule = dynamicRule(key);
if (dynamicRule == null) {
return null;
}
Object userValue = null;
ValueModel value = getValueSimple(key);
if (value == null) {
HotKeyPusher.push(key, keyType);
} else {
//临近过期了,也发
if (isNearExpire(value)) {
HotKeyPusher.push(key, keyType);
}
Object object = value.getValue();
//如果是默认值,也返回null
if (object instanceof Integer && Constant.MAGIC_NUMBER == (int) object) {
userValue = null;
} else if (Boolean.FALSE.equals(dynamicRule)) {
userValue = null;
} else {
userValue = object;
}
}
//统计计数
MetricsFactory.metrics(new KeyHotModel(key, value != null));
return userValue;
} catch (Exception e) {
DwLogger.error(DwHotKeyStore.class, "get value error");
return null;
}
}
- Worker 节点启动 nettyServer,用于各个业务服务实例进行长连接,接收客户端上报数据
public void startNettyServer(int port) throws Exception {
//boss单线程
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
//worker节点组
EventLoopGroup WorkerGroup = new NioEventLoopGroup(CpuNum.WorkerCount());
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, WorkerGroup)
.channel(NioServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.INFO))
.option(ChannelOption.SO_BACKLOG, 1024)
//保持长连接
.childOption(ChannelOption.SO_KEEPALIVE, true)
//出来网络io事件,如记录日志、对消息编解码等
.childHandler(new ChildChannelHandler());
//绑定端口,同步等待成功
ChannelFuture future = bootstrap.bind(port).sync();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
bossGroup.shutdownGracefully (1000, 3000, TimeUnit.MILLISECONDS);
WorkerGroup.shutdownGracefully (1000, 3000, TimeUnit.MILLISECONDS);
}));
//等待服务器监听端口关闭
future.channel().closeFuture().sync();
} catch (Exception e) {
DwLogger.error("netty server start error.", e);
} finally {
//优雅退出,释放线程池资源
bossGroup.shutdownGracefully();
WorkerGroup.shutdownGracefully();
}
}
- Worker 节点通过监听客户端上报,异步消费队列 Client 消息
public void beginConsume() {
while (true) {
try {
HotKeyModel model = QUEUE.take();
if (model.isRemove()) {
iKeyListener.removeKey(model, KeyEventOriginal.CLIENT);
} else {
iKeyListener.newKey(model, KeyEventOriginal.CLIENT);
}
//处理完毕,将数量加1
totalDealCount.increment();
} catch (Exception e) {
DwLogger.error("consumer error.", e);
}
}
}
- 如果是新增一个 Key,就生成滑动窗口,基于时间窗口数据判断是否热 Key
@Override
public void newKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//cache里的key
String key = buildKey(hotKeyModel);
String name = StringUtils.isBlank(hotKeyModel.getGroup()) ? hotKeyModel.getAppName() : hotKeyModel.getGroup();
//判断是不是刚热不久
Object o = hotCache.getIfPresent(key);
if (o != null) {
return;
}
SlidingWindow slidingWindow = checkWindow(hotKeyModel, key, name);
//看看hot没
boolean hot = slidingWindow.addCount(hotKeyModel.getCount());
if (!hot) {
//如果没hot,重新put,cache会自动刷新过期时间
CaffeineCacheHolder.getCache(name).put(key, slidingWindow);
} else {
hotCache.put(key, 1);
//删掉该key
CaffeineCacheHolder.getCache(name).invalidate(key);
//开启推送
hotKeyModel.setCreateTime(SystemClock.now());
//当开关打开时,打印日志。大促时关闭日志,就不打印了
if (ConfigStarter.LOGGER_ON) {
DwLogger.info(NEW_KEY_EVENT + hotKeyModel.getKey());
}
//分别推送到各client和etcd
for (IPusher pusher : iPushers) {
pusher.push(hotKeyModel);
}
}
}
- 如果是删除一个 Key,这里删除包含客户端发消息删除,本地线程扫描过期 Key 和管理台删除
@Override
public void removeKey(HotKeyModel hotKeyModel, KeyEventOriginal original) {
//cache里的key
String key = buildKey(hotKeyModel);
String name = StringUtils.isBlank(hotKeyModel.getGroup()) ? hotKeyModel.getAppName() : hotKeyModel.getGroup();
hotCache.invalidate(key);
CaffeineCacheHolder.getCache(name).invalidate(key);
//推送所有client删除
hotKeyModel.setCreateTime(SystemClock.now());
DwLogger.info(DELETE_KEY_EVENT + hotKeyModel.getKey());
for (IPusher pusher : iPushers) {
pusher.remove(hotKeyModel);
}
}
- Worker 计算完成后将结果异步推送给 Client,通过 app 进行分组批量推送
@PostConstruct
public void batchPushToClient() {
AsyncPool.asyncDo(() -> {
while (true) {
try {
List<HotKeyModel> tempModels = new ArrayList<>();
//每10ms推送一次
Queues.drain(hotKeyStoreQueue, tempModels, 10, 10, TimeUnit.MILLISECONDS);
if (CollectionUtil.isEmpty(tempModels)) {
continue;
}
Map<String, List<HotKeyModel>> allAppHotKeyModels = Maps.newHashMap();
Map<String, List<HotKeyModel>> allGroupHotKeyModels = Maps.newHashMap();
//拆分出每个app的热key集合,按app分堆
for (HotKeyModel hotKeyModel : tempModels) {
if (StringUtils.isNotBlank(hotKeyModel.getGroup())) {
List<HotKeyModel> groupModels = allGroupHotKeyModels.computeIfAbsent(hotKeyModel.getGroup(), (key) -> new ArrayList<>());
groupModels.add(hotKeyModel);
} else {
List<HotKeyModel> oneAppModels = allAppHotKeyModels.computeIfAbsent(hotKeyModel.getAppName(), (key) -> new ArrayList<>());
oneAppModels.add(hotKeyModel);
}
}
CustomizedMetricsProcessor processor = CustomizedMetricsProcessor.builder(MetricsConstant.BURNING_NETTY_OUT).build();
// group hot key push
pushGroup(processor, allGroupHotKeyModels);
// app hot key push
pushApp(processor, allAppHotKeyModels);
} catch (Exception e) {
DwLogger.error("push to client error.", e);
}
}
});
}
4.6 最佳实践
Burning 提供了 2 种使用方式,一是通过原生方法调用,二是通过声明式注解 @EnableBurning , 以下对使用注解进行热点探测的部分场景提供最佳实践:
1. 进行热点判断,用于热点拦截和自定义处理实现
@Component
public class Cache {
@EnableBurning(prefix = "hot_Key_", cache = false, hitHandler = ExceptionHitHandler.class)
public String getResult2(String Key) {
return "这是一个测试结果" + Key;
}
}
2. 命中热点规则处理类,可进行自定义实现 hitHandler 接口(注意 cache=false)
public class ExceptionHitHandler implements HitHandler {
@Override
public Object handle(String Key, ProceedingJoinPoint joinPoint) {
//此处可自定义实现
throw new RuntimeException("对不起,您没有权限访问: " + Key);
}
}
3. 用于 Redis 缓存热点探测
@Component
public class Cache {
@Resource
private RedisTemplate<String, String> RedisTemplate;
@EnableBurning
public String getResult(String Key) {
return RedisTemplate.opsForValue().get(Key);
}
}
4. 用于 MySQL 热数据缓存
@Repository
public class SmsSignRepo {
@Autowired
private SmsSignMapper smsSignMapper;
@EnableBurning(prefix = "SMS_SIGN", dynamic = false, KeyType = DATABASE_Key)
public List<SmsSign> getAll() {
Example example = new Example(SmsSign.class);
Example.Criteria criteria = example.createCriteria();
criteria.andEqualTo("status", 1);
return smsSignMapper.selectByExample(example);
}
}
4.7 性能表现
4.7.1 Worker 节点性能压测
上游 40 个测试调用实例共同调用的场景下,并发数 800,递进压测
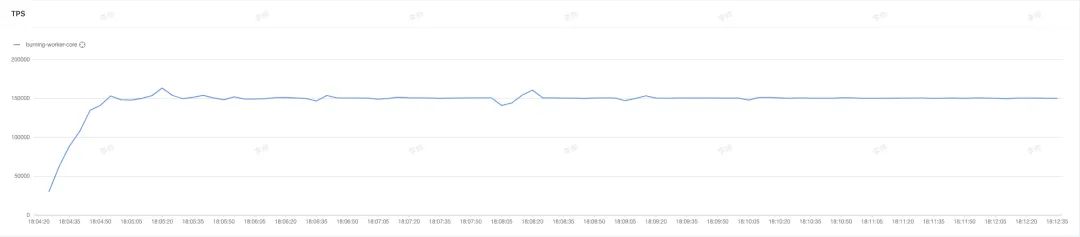
压测结果:1 个 4C8G 工作节点每秒可平稳处理约 15W 个 key 的热点探测,成功率大于 99.999%,worker 节点 CPU 平均占用为 80%,内存占用 60%
4.7.2 Client 业务应用性能压测
- DB 场景压测
Client 配置为 4C8G,120 个并发请求,压测时长 10min
1. 原生未接入 Burning 的 DB 操作接口场景

压测结果:未接入 burning,处理总请求数约 112 万,平均 TPS 约 1500,平均 RT 约 63MS。CPU 在压测满载情况下 100%,内存平均使用 48%
2. 接入 Burning 的 DB 操作接口场景

压测结果:接入 burning 后,处理总请求数 457 万(对比未接入 Burning 增加 345 万),平均 TPS 约 5800(对比未接入 Burning 增加 4300),平均 RT 约 8MS(对比未接入 Burning 下降 55MS)。CPU 在压测满载情况下 100%,内存平均使用 50%(对比未接入上升 2%,本地缓存消耗)
- Redis 场景压测
Client 配置为 4C8G,120 个并发请求,压测时长 10min
1. 原生未接入 Burning 的 Redis 操作接口场景

压测结果:未接入 burning,处理总请求数约 298 万,平均 TPS 约 3800,平均 RT 约 14MS。CPU 在压测满载情况下 100%,内存平均使用 48%
2. 已接入 Burning 的 Redis 操作接口场景

压测结果:已接入 burning,处理总请求数约 443 万(对比未接入增加 145 万),平均 TPS 约 5700(对比未接入上升 1900),平均 RT 约 8MS(对比未接入下降 6ms)。CPU 在压测满载情况下 100%,内存平均使用 48%,基本持平
4.7.3 压测报告
-
Burning 工作节点单机每秒处理 15 万个 key 的探测请求,CPU 稳定在 80% 左右,基本无任何异常
-
客户端应用接入 burning 后,对应用实例本身 CPU 负载基本无影响,内存占用上升主要取决于指定的本地缓存大小,接入后接口性能提升明显,QPS 明显上升,RT 明显下降
5. 总结
热点问题在互联网场景中屡屡出现,特别是电商业务的需求场景,例如对于大促期间或者活动抢购期间的某个爆品,可能会出现在几秒时间内流入大量的流量,由于商品数据在 Redis cluster 场景下会按照 hash 规则被存放在某个 Redis 分片上,那么这个瞬间流量也有可能出现打挂 Redis 分片,导致系统雪崩。所以我们要善于利用热点探测中间件进行热 Key 探测,通过预置本地缓存解决突发流量导致的系统瓶颈,也能通过热点数据监控分析进行针对性的系统调优。
得物热点探测组件 Burning 上线至今,支持了数十个交易核心链路服务,在满足基础热点探测的前提下,Burning 还支持本地缓存压测标 / 染色标识别能力,客户端本地 Ecache/Caffeine 缓存模式选择,热点规则 Group 聚合统计等扩展能力。应用服务接入 Burning 后对于热点数据探测及数据获取性能显著提高,通过预热 & 实时本地缓存,极大的降低了下层缓存集群和数据库的负载压力,为业务服务的健康运作保驾护航。
文 / Leo