1、引言
在大数据时代,实时数据处理和流式数据分析变得越来越重要。为了应对大规模数据的高吞吐量和低延迟处理需求,出现了各种分布式流处理平台。其中,Apache Kafka作为一种高性能、可扩展的分布式消息系统,成为了广泛应用于实时数据处理和数据管道的核心组件。

2、Kafka概念

Apache Kafka 是一个分布式事件流平台:
- 发布和订阅事件流,类似于消息队列或企业消息传递系统。
- 以容错持久的方式存储事件流。
- 在事件流发生时对其进行处理。
要更详细地了解分布式事件流,您应该首先了解事件是世界或您的业务中“发生的事情”的记录。例如,在拼车系统中,您可能会看到以下事件:
- 事件key: “Alice”
- 事件value: “Trip requested at work location”
- 事件 timestamp: “Jun. 25, 2020 at 2:06 p.m.”
事件数据描述了发生的事情、时间以及涉及的人员。事件流是从数据库、传感器、移动设备、云服务和软件应用程序等源实时捕获示例中的事件的实践。

事件流平台按顺序捕获事件,并持久存储这些事件流,以便实时处理、操作和响应或稍后检索。此外,事件流可以根据需要路由到不同的目标技术。事件流可确保数据的连续流动和解释,以便在正确的时间、正确的地点提供正确的信息。
为了实现这一目标,Kafka 作为集群运行在一台或多台可以跨越多个数据中心的服务器上。并以分布式、高度可扩展、弹性、容错和安全的方式提供其功能。此外,Kafka 可以部署在裸机硬件、虚拟机、容器、本地以及云端。
借助 Kafka,您可以获得用于管理任务的命令行工具,以及用于为您的场景构建事件流解决方案的 Java 和 Scala API。
事件流适用于众多行业和组织的各种用例。例如:
- 作为消息系统。例如,Kafka 可用于实时处理支付和金融交易,例如在证券交易所、银行和保险公司。
- 活动跟踪。例如,Kafka 可用于实时跟踪和监控汽车、卡车、车队和货运,例如出租车服务、物流和汽车行业。
- 收集指标数据。例如,Kafka 可用于连续捕获和分析来自物联网设备或其他设备(例如工厂和风电场)的传感器数据。
- 用于流处理。例如,使用 Kafka 收集客户交互和订单并做出反应,例如零售、酒店和旅游业以及移动应用程序。
- 解耦系统。例如,使用 Kafka 连接、存储并提供公司不同部门生成的数据。
- 与其他大数据技术(例如 Hadoop)集成。
Kafka的核心概念包括以下几个部分:
1.主题(Topic)
主题是数据流的类别或标签,用于将数据进行分类。生产者将数据发布到特定的主题,消费者订阅这些主题以接收数据。
2.分区(Partition)
每个主题可以分为一个或多个分区,每个分区是数据的有序序列。分区允许在多个服务器上并行处理和存储数据,并实现高吞吐量和负载均衡。
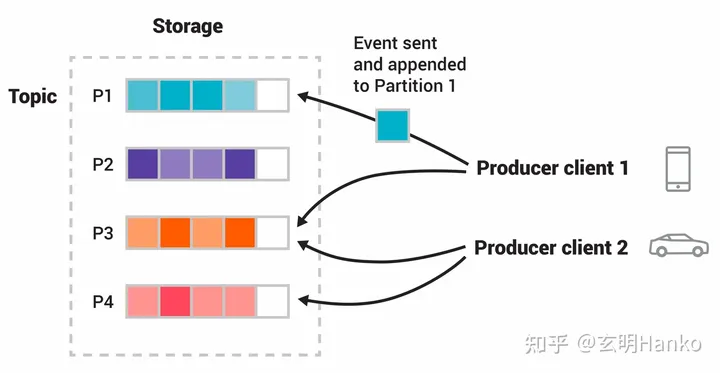
3.生产者(Producer)
生产者是将数据发布到Kafka主题的应用程序。它负责将数据发送到指定的主题,并根据分区策略选择目标分区。4.消费者(Consumer)
消费者是从Kafka主题中订阅和读取数据的应用程序。它可以订阅一个或多个主题,并从指定的偏移量开始消费消息。
5.偏移量(Offset)
偏移量是分区中每条消息的唯一标识符,表示消息在分区中的位置。消费者可以指定偏移量来读取特定位置的消息。
Kafka可以用于多种场景,包括日志收集、事件驱动架构、实时分析、指标监控、流式ETL等。它提供了可靠的数据传输、持久化存储、数据复制和容错机制,使得大规模数据处理和流式数据分析变得更加高效和可靠。
3、Kafka特性

- 高吞吐量
Kafka设计用于处理高吞吐量的数据流。它能够处理每秒数百万条消息,并支持同时处理大量的生产者和消费者。Kafka通过分区和并行处理来实现高吞吐量的数据传输。
2.可扩展性
Kafka是一个分布式系统,可以在集群中添加更多的服务器来扩展其容量和性能。它使用分区机制将数据分布到多个节点上,允许并行处理和水平扩展。
3.持久性存储
Kafka提供持久化的数据存储,即使消息被消费,它们仍然会被保留在磁盘上一段时间。这使得应用程序可以随时回放历史数据,进行批处理操作或重新处理数据。
4.高可用性
Kafka通过数据的复制和分布式副本机制来提供高可用性。每个分区都有多个副本,其中一个副本被选为Leader,负责处理读写请求,其他副本则作为Followers,用于备份和数据复制。如果Leader副本失效,Followers中的一个会被选举为新的Leader,以确保数据的可用性和连续性。
5.多语言支持
Kafka提供了多种编程语言的客户端API,包括Java、Python、Go和.NET等,方便开发者使用各种编程语言进行消息的生产和消费。

4、Kafka应用

Kafka在大数据和实时数据处理领域有广泛的应用场景。以下是一些常见的Kafka应用场景:
- 日志收集和分析
Kafka能够高效地收集和存储大量的日志数据。应用程序可以将日志消息发布到Kafka主题中,而日志分析系统可以通过订阅主题来实时消费和处理日志数据,进行实时监控、故障排查和数据分析等操作。
2.实时流处理
Kafka作为流处理平台,可以进行实时的数据处理、转换和聚合。它提供了Kafka Streams库,使得开发者能够轻松构建和部署实时流处理应用程序。实时流处理场景包括实时计算、实时监控、实时推荐等。
3.事件驱动架构
Kafka作为事件驱动架构的核心组件,能够实现松耦合的异步通信和事件驱动的处理。不同的服务和组件可以通过Kafka进行事件的发布和订阅,实现解耦、可扩展和高可用的架构。
4.指标监控
Kafka可以作为指标数据的收集和传输平台,用于实时监控系统的性能和状态。应用程序可以将指标数据发送到Kafka,监控系统订阅相应的主题来实时消费和处理指标数据,进行实时监控、报警和分析。
5.数据管道和ETL
Kafka可以作为数据管道,连接不同的数据系统和应用程序。它可以与消息队列、数据库、数据湖等系统进行集成,实现异构系统之间的数据流动和交互。同时,Kafka的持久化存储和流处理能力也使得它成为实时ETL(Extract, Transform, Load)的理想选择。
6.媒体流处理
Kafka可以用于处理媒体数据流,如音频、视频等。它能够高效地处理和传输大规模的媒体数据,并支持流媒体处理和实时分析,适用于实时广播、视频直播等场景。
5、使用者
Apache Kafka 是最流行的开源流处理软件,用于大规模收集、处理、存储和分析数据。它以其出色的性能、低延迟、容错和高吞吐量而闻名,每秒能够处理数千条消息。Kafka 用例超过 1,000 个,并且数量还在不断增加,一些共同的好处是构建数据管道、利用实时数据流、启用运营指标以及跨无数来源的数据集成。
如今,Kafka 被数千家公司使用,其中包括超过 80% 的财富 100 强企业。其中包括Box,Goldman Sachs,Target,Cisco,Intuit等。作为授权和创新公司的可靠工具,Kafka 允许组织通过事件流架构实现数据策略的现代化。了解 Kafka 如何被各行各业的组织使用 - 从计算机软件、金融服务和医疗保健到政府和交通。

如果文章对你有帮助,欢迎关注+点赞,必回关!!!