目录
- 1 问题描述
- 2 分析 checkpointLocation 配置
- 2.1 checkpointLocation 在源码调用链
- 2.2 MetadataLog(元数据日志接口)
- 3 分析 checkpointLocation 目录内容
- 3.1 offsets 目录
- 3.2 commitLog 目录
- 3.3 metadata 目录
- 3.4 sources 目录
- 3.5 sinks 目录
- 4 解决方案
- 4.1 File 作为接收端
- 4.2 Elasticsearch 作为接收端
内容可能持续性修改完善,最新专栏内容与 spark-docs 同步,源码与 spark-advanced 同步。
1 问题描述
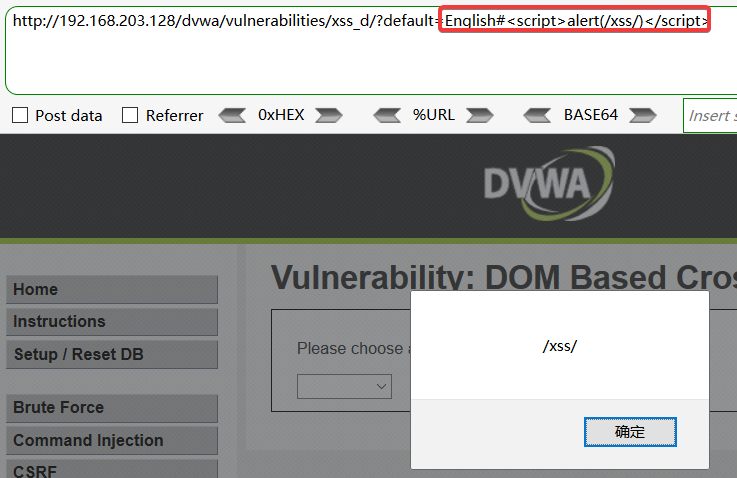
Spark StructuredStreaming 实时任务 kafka -> elasticsearch、kafka -> hdfs(parquet格式文件) 任务运行过程中每隔固定时间后某个出现耗时较长。
本内容以kafka -> elasticsearch为例说明,生产环境版本号 Spark-2.4.0,下图为 SQL-UI Job 运行耗时情况:

问题定位 分析耗时较长任务出现时间,发现出现该问题间隔时间点固定,怀疑是spark某种机制导致,与任务逻辑无关性较大。
查看指定的 checkpointPath 目录发现,在 $checkpointPath/sinks/elasticsearch 下与SQL-UI Job 长时间耗时的时间点一致。初步判断控制生成大文件的方式或者策略即可解决问题。

2 分析 checkpointLocation 配置
2.1 checkpointLocation 在源码调用链
分析源码查看 StructuredStreaming 启动流程发现,DataStreamWriter#start 方法启动一个 StreamingQuery。 同时将 checkpointLocation 配置参数传递给StreamingQuery管理。
StreamingQuery 接口实现关系如下:

- StreamingQueryWrapper 仅包装了一个不可序列化的
StreamExecution - StreamExecution 管理Spark SQL查询的执行器
- MicroBatchExecution 微批处理执行器
- ContinuousExecution 连续处理(流式)执行器
因此我们仅需要分析 checkpointLocation 在 StreamExecution中调用即可。
StreamExecution 中
protected def checkpointFile(name: String): String方法为所有与 checkpointLocation 有关逻辑,该方法返回 $checkpointFile/name 路径
2.2 MetadataLog(元数据日志接口)
spark 提供了org.apache.spark.sql.execution.streaming.MetadataLog接口用于统一处理元数据日志信息。
checkpointLocation 文件内容均使用 MetadataLog进行维护。
分析 MetadataLog 接口实现关系如下:

各类作用说明:
- NullMetadataLog 空日志,即不输出日志直接丢弃
- HDFSMetadataLog 使用 HDFS 作为元数据日志输出
- CommitLog 提交日志
- OffsetSeqLog 偏移量日志
- CompactibleFileStreamLog 封装了支持按大小合并、删除历史记录的 MetadataLog
- FileStreamSourceLog 文件类型作为数据源时日志记录
- FileStreamSinkLog 文件类型作为数据接收端时日志记录
- EsSinkMetadataLog Es作为数据接收端时日志记录
分析 CompactibleFileStreamLog#compact 合并逻辑简单描述为:
假设有 0,1,2,3,4,5,6,7,8,9,10 个批次依次到达,合并大小为3
当前合并结果为 `0,1,2.compact,3,4`
下一次合并结果为 `0,1,2.compact,3,4,5.compact` , **说明:5.compact 文件内容 = 2.compact + 3 + 4**
last.compact 文件大小会随着批次运行无限增大
...
分析 CompactibleFileStreamLog 删除过期文件逻辑:
// CompactibleFileStreamLog#add 方法被调用时,默认会判断是否支持删除操作
override def add(batchId: Long, logs: Array[T]): Boolean = {
val batchAdded =
if (isCompactionBatch(batchId, compactInterval)) { // 是否合并
compact(batchId, logs)
} else {
super.add(batchId, logs)
}
if (batchAdded && isDeletingExpiredLog) { // 添加成功且支持删除过期文件
// 删除时判断当前批次是否在 spark.sql.streaming.minBatchesToRetain 配置以外且在文件保留时间内
// 配置项参考 第4节 解决方案配置说明
deleteExpiredLog(batchId)
}
batchAdded
}
3 分析 checkpointLocation 目录内容
目前 checkpointLocation 内容主要包含以下几个目录(子小节中逐个介绍目录数据来源及功能性)
- offsets
- commits
- metadata
- sources
- sinks
3.1 offsets 目录
记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据,在处理数据前将其写入此日志记录。 此日志中的第 N 条记录表示当前正在已处理,第 N-1 个条目指示哪些偏移已处理完成。
// StreamExecution 类中声明了 OffsetSeqLog 变量进行操作
val offsetLog = new OffsetSeqLog(sparkSession, checkpointFile("offsets"))
// 该日志示例内容如下,文件路径=checkpointLocation/offsets/560504
v1
{"batchWatermarkMs":0,"batchTimestampMs":1574315160001,"conf":{"spark.sql.streaming.stateStore.providerClass":"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider","spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion":"2","spark.sql.streaming.multipleWatermarkPolicy":"min","spark.sql.streaming.aggregation.stateFormatVersion":"2","spark.sql.shuffle.partitions":"200"}}
{"game_dc_real_normal":{"17":279843310,"8":318732102,"11":290676804,"2":292352132,"5":337789356,"14":277147358,"13":334833752,"4":319279439,"16":314038811,"7":361740056,"1":281418138,"10":276872234,"9":244398684,"3":334708621,"12":290208334,"15":267180971,"6":296588360,"0":350011707}}
3.2 commitLog 目录
记录已完成的批次,重启任务检查完成的批次与 offsets 批次记录比对,确定接下来运行的批次
// StreamExecution 类中声明了 CommitLog 变量进行操作
val commitLog = new CommitLog(sparkSession, checkpointFile("commits"))
// 该日志示例内容如下,文件路径=checkpointLocation/commits/560504
v1
{"nextBatchWatermarkMs":0}
3.3 metadata 目录
metadata 与整个查询关联的元数据,目前仅保留当前job id
// StreamExecution 类中声明了 StreamMetadata 变量进行操作,策略如下:
/** Metadata associated with the whole query */
protected val streamMetadata: StreamMetadata = {
val metadataPath = new Path(checkpointFile("metadata"))
val hadoopConf = sparkSession.sessionState.newHadoopConf()
StreamMetadata.read(metadataPath, hadoopConf).getOrElse {
val newMetadata = new StreamMetadata(UUID.randomUUID.toString)
StreamMetadata.write(newMetadata, metadataPath, hadoopConf)
newMetadata
}
}
// 该日志示例内容如下,文件路径=checkpointLocation/metadata
{"id":"5314beeb-6026-485b-947a-cb088a9c9bac"}
3.4 sources 目录
sources 目录为数据源(Source)时各个批次读取详情
3.5 sinks 目录
sinks 目录为数据接收端(Sink)时批次的写出详情
例如: es 作为 sink 时,内容如下
目前 Es 支持配置自定义写出目录,如果未配置写入 checkpointLocation/sinks/ 目录,参考
SparkSqlStreamingConfigs
文件路径=checkpointLocation/sinks/elasticsearch/560504
v1
{"taskId":0,"execTimeMillis":1574302020143,"resource":"rs_real_{app}.{dt}","records":220}
{"taskId":1,"execTimeMillis":1574302020151,"resource":"rs_real_{app}.{dt}","records":221}
{"taskId":2,"execTimeMillis":1574302020154,"resource":"rs_real_{app}.{dt}","records":219}
{"taskId":3,"execTimeMillis":1574302020151,"resource":"rs_real_{app}.{dt}","records":221}
{"taskId":4,"execTimeMillis":1574302020154,"resource":"rs_real_{app}.{dt}","records":220}
例如: 文件类型作为 sink,默认写出到各个 $path/_spark_metadata 目录下 ,参考 FileStreamSink
hdfs 写出时内容为,文件路径=$path/_spark_metadata/560504
v1
{"path":"hdfs://xx:8020/$path/1.c000.snappy.parquet","size":8937,"isDir":false,"modificationTime":1574321763584,"blockReplication":2,"blockSize":134217728,"action":"add"}
{"path":"hdfs://xx:8020/$path/2.c000.snappy.parquet","size":11786,"isDir":false,"modificationTime":1574321763596,"blockReplication":2,"blockSize":134217728,"action":"add"}
4 解决方案
根据实际业务情况合理调整日志输出参数(配置见4.1/4.2说明):
- 关闭日志输出
- 控制保留并可以恢复的最小批次数量且减小日志文件保留时间
- 调整日志文件合并阈值
无论如何调整参数,.compact(合并的文件)大小会一直增长,目前关闭可以解决。调整其他阈值可减小任务出现耗时情况次数。 针对该问题已提交给官方 SPARK-29995尝试解决
4.1 File 作为数据源或者数据接收端
spark.sql.streaming.minBatchesToRetain(默认100) 保留并可以恢复的最小批次数量spark.sql.streaming.commitProtocolClass默认:org.apache.spark.sql.execution.streaming.ManifestFileCommitProtocol 合并实现类,其余支持实现参考FileCommitProtocol实现类
fileSource 数据源端:配置在 FileStreamSourceLog 引用
spark.sql.streaming.fileSource.log.deletion(默认true),删除过期日志文件spark.sql.streaming.fileSource.log.compactInterval(默认10),日志文件合并阈值spark.sql.streaming.fileSource.log.cleanupDelay(默认10m),日志文件保留时间
fileSink 接收端:配置在 FileStreamSinkLog 引用
spark.sql.streaming.fileSink.log.deletion(默认true),删除过期日志文件CompactibleFileStreamLogspark.sql.streaming.fileSink.log.compactInterval(默认10),日志文件合并阈值spark.sql.streaming.fileSink.log.cleanupDelay(默认10m),日志文件保留时间
4.2 Elasticsearch 作为接收端
elasticsearch-spark 官方文档,es 官方重写变量命名及赋值方式,参考EsSinkMetadataLog
es.spark.sql.streaming.sink.log.enabled(默认true) 启用或禁用流作业的提交日志。默认情况下,该日志处于启用状态,并且具有相同批次ID的输出批次将被跳过,以避免重复写入。设置false为时,将禁用提交日志,并且所有输出都将发送到Elasticsearch,无论它们是否在先前的执行中已发送。es.spark.sql.streaming.sink.log.path设置存储此流查询的日志数据的位置。如果未设置此值,那么Elasticsearch接收器会将其提交日志存储在中给定的路径下checkpointLocation。任何与HDFS客户端兼容的URI都是可以接受的。es.spark.sql.streaming.sink.log.cleanupDelay(默认10m) 提交日志通过Spark的HDFS客户端进行管理。一些与HDFS兼容的文件系统(例如Amazon的S3)以异步方式传播文件更改。为了解决这个问题,在压缩了一组日志文件之后,客户端将等待此时间,然后再清理旧文件。es.spark.sql.streaming.sink.log.deletion(默认true) 确定日志是否应删除不再需要的旧日志。提交每个批次后,客户端将检查是否有已压缩且可以安全删除的提交日志。如果设置为false,日志将跳过此清理步骤,为每个批次保留一个提交文件。es.spark.sql.streaming.sink.log.compactInterval(默认10) 设置压缩日志文件之前要处理的批次数。默认情况下,每10批提交日志将被压缩为一个包含所有以前提交的批ID的文件。
问题:_spark_metadata/0 doesn't exist while compacting batch error
Sample code of application:
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", <server list>)
.option("subscribe", <topic>)
.load()
[...] // do some processing
dfProcessed.writeStream
.format("csv")
.option("format", "append")
.option("path",hdfsPath)
.option("checkpointlocation","")
.outputmode(append)
.startExample :
df.writeStream
.format("parquet")
.outputMode("append")
.option("checkpointLocation", "D:/path/dir/checkpointLocation")
.option("path", "D:/path/dir/output")
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()The error message
_spark_metadata/n.compact doesn't exist when compacting batch n+10解决方案一: How to recover from a deleted _spark_metadata folder in Spark Structured Streaming - DEV Community
解决方案二:
增加:option('retention', retention_value)
df.writeStream
.format("parquet")
.outputMode("append")
.option("checkpointLocation", "D:/path/dir/checkpointLocation")
.option("path", "D:/path/dir/output")
.option('retention', retention_value)
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()

https://github.com/apache/spark/blob/master/docs/structured-streaming-programming-guide.md
https://github.com/apache/spark/pull/24128
参照:https://github.com/GourdErwa/awesome-spark/blob/master/docs/structured-streaming/Spark-StructuredStreaming%20checkpointLocation%E4%BC%98%E5%8C%96%E7%82%B9%E5%88%86%E6%9E%90.md
Configuration Properties · The Internals of Spark Structured Streaming
FileStreamSinkLog - The Internals of Spark Structured Streaming