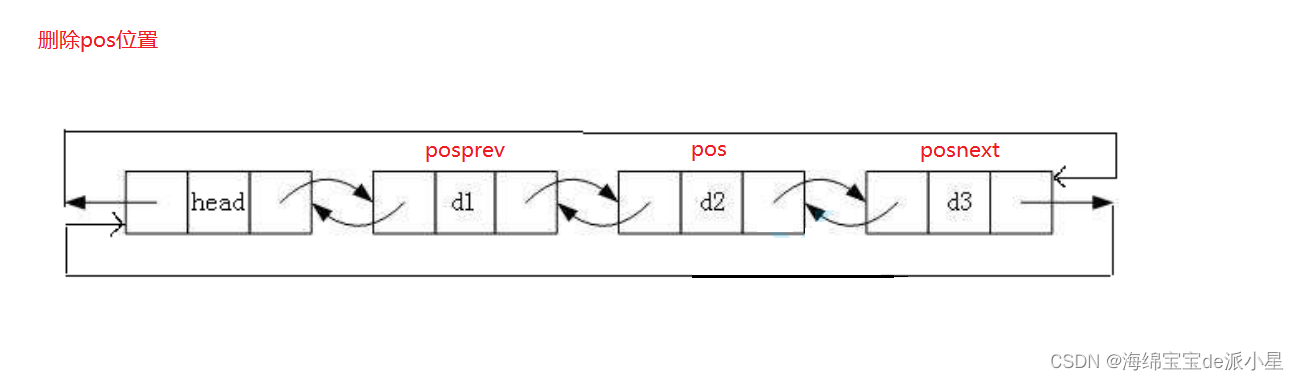
一、说明
使用BERT,UMAP和HDBSCAN捕获文档主题,紧随最先进的BERTopic架构(transformer编码器)。
主题检测是一项 NLP 任务,旨在从文本文档语料库中提取全局“主题”。例如,如果正在查看书籍描述的数据集,主题检测将使我们能够将书籍分类,例如:“浪漫”、“科幻”、“旅行”等。
在本教程中,我们将使用BERT的HuggingFace库实现以及用于聚类的HDBSCAN和用于降维的UMAP来实现。该管道将遵循Maarten Grootendorst提出的BERTopic结构:

伯特皮克管道
二、开始实践
为了简单起见,我建议在Google Coolab中运行代码,但另一个平台也很好。
首先安装必要的依赖项:
!pip install pandas numpy umap-learn transformers plotly hdbscan然后继续加载输入数据:
import pandas as pd
data = pd.read_csv("ecommerce.csv", on_bad_lines='skip', nrows=500)
data = data[[""]]
在我们的示例中,数据对应于从 Kaggle 中提取的电子商务商店。我已将数据采样到 500 行以使代码运行得更快,但如果需要,您可以使用完整的数据集。数据如下所示:

输入数据集
如我们所见,“文本”列包含文章描述。我们的主题建模目标是为每个文章描述找到正确的文章类别。例如:“Joyo多功能紧凑型折叠桌”的描述可以标记为“家用”物品。
我们将整个数据集称为语料库,每个文本行一个文档,每个(子)单词一个标记。
三、BERT 查找文档编码
为了能够正确地将文章聚类到正确的部门中,我们需要将文本描述矢量化并嵌入到潜在空间中,以便属于同一部门的元素在几何上彼此更接近。我们将使用 BERT 作为数据编码器。
首先加载BERT模型。HuggingFace允许我们从给定的模型实例(又名“检查点”)下载预先训练的模型。这样我们就不必自己训练完整的BERT!
# load BERT model (for embeddings)
from transformers import BertTokenizer, TFBertModel
checkpoint = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(checkpoint)
model = TFBertModel.from_pretrained(checkpoint)然后我们加载分词器。分词器将做 3 件主要事情:
- 将每个文档分解为一组单词/子单词(也称为标记),以便模型可以消化它们。
例如:“Hello World!”→ ['hello', 'world', '!']
- 将每个单词标记映射到一组给定的索引 ID
例如: ['hello', 'world', '!'] → [7592, 2088, 999]
请注意,id 不是嵌入,而只是模型用来将文档中的标记映射到其词汇表中的标记的数字标识符。通过预训练,模型知道自己词汇表中标记之间的关系。
- 添加特殊标记,以便模型知道句子何时开始/结束、分隔等。例如: [EOS], [SEP], ...
标记化解释如下:
# Tokenize corpus with the BERT tokenizer (WordPiece algorithm)
descr_processed_tokenized = tokenizer(
list(data["text"]),
return_tensors="tf",
truncation=True,
padding=True,
max_length=128,
)
标记化后,我们的文本数据(现在以数字表示为一组令牌 ID)可以被 BERT 模型摄取
# Encode corpus using BERT
output_bert = model(descr_processed_tokenized)
这将为整个输入数据生成嵌入。当应用于单个句子时,模型输出将如下所示:

单个文本示例的 BERT 输出
正如我们所看到的,BERT使用768长度的嵌入向量对输入中的每个标记进行了编码。
但是,我们对整个文章描述的嵌入感兴趣,而不仅仅是单词嵌入的列表。为了提取整个文档的嵌入,我们只需平均文档中的所有单词嵌入。
# Get sentence embeddings from BERTs word embeddings
import numpy as np
mean_vect = []
for vect in output_bert.last_hidden_state:
mean_vect.append(np.mean(vect, axis=0))
data = data.assign(descr_vect=mean_vect)
现在,最后,我们为输入表中的每个元素分配了一个向量,这称为文档嵌入
四、使用 BERT 进行文档嵌入
UMAP 将向量嵌入投影到较低维度
由于维度的诅咒,在 768 维空间上应用聚类算法是不可行的。因此,有必要应用降维技术。
一种非常流行的技术被称为UMAP(均匀流形近似和投影)。这种技术以尊重归约后数据的全局和局部结构而闻名。
数学说明:UMAP基于数据类可以表示为流形(流形假设)的假设,以及这些流形是可微的假设,因此UMAP的模糊逻辑是适用的。
我们将嵌入向量的维度减少到 3 维,以便我们可以可视化结果,让我们执行以下操作:
# Use UMAP to lower the dimensionality of the embedding to 3D
import umap
descr_vect_3d = umap.UMAP(n_components=3).fit_transform(
np.stack(data["descr_vect"].values)
)
data["descr_vect_3d"] = list(descr_vect_3d)
堆栈将嵌套数组(array(array(...)))映射到单个数组中。我们的数据现在如下所示
将嵌入的维度从 768D 减小到 3D 后的数据
数学说明:从理论上讲,将 UMAP 用于下游处理任务(如基于密度的聚类)是不正确的。众所周知,UMAP产生的嵌入可能不保持密度,并且可能在潜流形中产生密度不连续性。然而,这在实践中往往不是问题。在此处了解更多信息。
五、将聚类分析应用于捕获主题
至此,我们已经成功地将文档映射到 3D 潜在空间上的向量。现在是时候应用聚类分析算法来查找相关主题了。
我们使用HDBSCAN进行聚类,因为它对数据结构的假设很少,同时即使几乎没有参数调整也能产生一流的结果
# Use BERT's + UMAP vector embeddings for clustering using HDBSCAN
import hdbscan
clustering = hdbscan.HDBSCAN().fit(np.stack(data["descr_vect_3d"].values))
data["cluster_label"] = clustering.labels_
绘制数据[“descr_vect_3d”].值作为 3D 散点图,我们得到以下内容
在 3D 文档嵌入空间上检测到的主题(颜色)

这里的主题由颜色表示。该算法将它们简单地标记为 {0, 1, 2}。
数学说明:HDBSCAN 是 DBSCAN 的扩展,使用图形修剪来揭示数据中底层集群的最佳规模,从而解决集群层次结构中的内在非唯一性。因此,算法会自动找到聚类的数量。
六、查找主题
在简单检查集群标签及其背后的描述后,我们识别出一些明显的主题类别:
主题 = 0 → 书籍
主题 = 1→ 家庭
主题 = 2→ 服装和配饰
最后,让我们用相应的文章类别(即文档主题)注释我们的数据。
data["article category"] = data["cluster_label"].map(
{0: 'Books', 1: 'Household', 2: 'Clothing & Accessories'})那么我们的最终数据如下所示:

使用所需文章类别注释的数据,这是我们想要的结果。