文章目录
- SQL的执行顺序一般是怎样的
- SQL如何性能优化
- 1.select尽量不要查询全部*,而是查具体字段
- 2.避免在where子句中使用 or 来连接条件
- 3.尽量使用数值替代字符串类型
- tinyint,int,bigint,smallint类型
- 4.用varchar代替char
- 那什么时候要用char不用varchar呢
链接: 数据库系统知识
SQL的执行顺序一般是怎样的
from →join →on →where →group by→avg/sum …→ having →select →distinct →order by→limit
- from:确定查询表格;如果有join则对 FROM 子句中的前两个表执行笛卡尔积(交叉联接)生成临时表
- on :对以上临时表进行条件筛选
- where:过滤表中数据的条件;
- group by:如何将上面过滤出的数据分组;
- avg/sum/…:聚合函数;(与group by搭配使用,有group by 必有聚合函数)
- having:对上面已经分组的数据进行过滤的条件;
- select:查看结果集中的哪个列,或列的计算结果;
- distinct:去重
- order by:按照什么样的顺序来查看返回的数据
- limit:限制查询结果返回的数量
总结一下:
- 1.首先要确定查询、操作的表格内容
- from确定查询表格,join 确定连接表格,由on条件筛选,确定临时表
- 根据where再进一步筛选
- 2.聚合函数,统计分析数据
- 先group by确定分组数据,再聚合函数计算数据
- having对聚合结果做筛选
- 3.最后根据用户需求,返回数据结果
- select 确定返回列或列的计算结果
- distinct对数据去重
- order by将数据以什么顺序来返回
- limit限制查询结果返回数量
SQL如何性能优化
链接
1.select尽量不要查询全部*,而是查具体字段
×:select * from table
√:select id,area from table
原因:
1.节省资源、减少网络开销。
2.可能用到覆盖索引,减少回表,提高查询效率(啥意思,覆盖索引、回表查询?)
2.避免在where子句中使用 or 来连接条件
×:SELECT * FROM user WHERE id=1 OR salary=5000
√:用union all
SELECT * FROM user WHERE id=1
UNION ALL
SELECT * FROM user WHERE salary=5000
- sql语句中union的用法
- 竖着拼接起来,其中只用union,会删除重复行,union all则会保留所有满足条件的值
- 一般最好用union all,用union的话在输出结果时还会对其排序,又花了点时间
原因:
1.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
还有一种情况可能会用or,比如要查询某个字段等于好几个值
select * from Member where MemberName = '张三' or MemberName = '李四'
也可以改写成union all形式
select * from Member where MemberName = '张三'
union all
select * from Member where MemberName = '李四'
3.尽量使用数值替代字符串类型
- 主键primary key 优先使用int/tinyint(tinyint和int有啥不一样)
- 对其他字段,也是能用数字表示就别用字符表示
原因:
1.字符会降低查询和连接的性能,并会增加存储开销:因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
2.而对于数字型而言只需要比较一次就够了;
tinyint,int,bigint,smallint类型
在sql中,整型数据有以上四种类型
- tinyint:存储只占一个字节,范围是0~255
- smallint:存储占两个字节,范围是 − 2 15 ( − 32768 ) -2^{15}(-32768) −215(−32768)到 2 15 − 1 ( 32767 ) 2^{15}-1(32767) 215−1(32767)
- int:存储为4个字节,范围是 − 2 31 ( − 2147483648 ) -2^{31}(-2147483648) −231(−2147483648)到 2 31 − 1 ( 2147483647 ) 2^{31}-1(2147483647) 231−1(2147483647)
- bigint:存储占8个字节,范围是 − 2 63 -2^{63} −263到 2 63 − 1 2^{63}-1 263−1
4.用varchar代替char
- varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间;
- char按声明大小存储,不足会补空格,一定把空间占满
- 对于查询来说,char的效率应该更高一点(为啥?我看有的地方还说数据长度小更有利于查找效率提升呢)
这个问题有人从存储角度说明: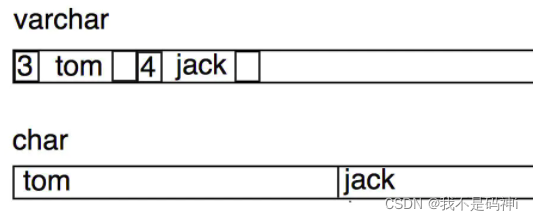
- 用varchar存储时,两个数据之间还需要用空格隔开,而且要得到下一个数据可能需要不断累加字段长度,增加计算过程,但是之间用char不一样,要查哪个,一次就能定位
那什么时候要用char不用varchar呢
- 1.存储很短的数据,用char效率更高,因为varchar还需要一个字节存储信息长度
- 2.定长数据,理由同上,varchar动态根据长度的特性就消失了,而且还需要一个字节存储信息长度
- 3.十分频繁改变的column,因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个非常频繁改变的,那就要有很多的精力用于计算,而这些对于char来说是不需要的
577-728-257 11点45



![[附源码]Python计算机毕业设计SSM基于社区人员管理系统(程序+LW)](https://img-blog.csdnimg.cn/2c924641d0814e8297191bb0c381c22e.png)