爬虫项目练习
- 前言
- 任务
- 基本爬虫框架
- URL管理器
- Html 下载器
- HTML 解析器
- 数据存储器
- 爬虫调度器
- 效果分析
前言
自学,参考书籍为 Python爬虫开发与项目实战 ,具体参考了该书的第六章。过程中出现两个问题:
- 在 Pycharm 上实现时发现有些库名更改及合并
- 爬取的网站增加了反爬机制
代码的框架与原书是一模一样的,若该文章有幸被原作者所浏览且认为这算抄袭,请联系我。
以下代码会具体标出与原书不同的地方(以 #!!!!!!!!!!! 标注)以及记录自己的想法
任务
爬取数条(自己定)百度百科爬虫词条以及相关词条的标题、摘要和链接信息
基本爬虫框架
这里参考原书
URL管理器
- 这一部分代码同原书
class URLManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def has_new_url(self):
return self.new_url_size() != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def new_url_size(self):
return len(self.new_urls)
def old_url_size(self):
return len(self.old_urls)
- 使用set数据结构:利用set去重功能,防止链接被重复爬取
- 若将来需求变大,需要存储的 url 增多,应该链接数据库保存
- 提出问题:获得新的 url 的顺序是否合理?如何获得与原词条相关性更强的 url 呢?
最终的运行文件所用到的代码如下:
import pickle
import hashlib
class _URLManager(object):
def __init__(self):
self.new_urls = self.load_process('new_urls.txt')
self.old_urls = self.load_process('old_urls.txt')
def has_new_url(self):
return self.new_url_size() != 0
def get_new_url(self):
new_url = self.new_urls.pop()
m = hashlib.md5()
#!!!!!!!!!!!
m.update(new_url.encode(encoding='utf-8'))
self.old_urls.add(m.hexdigest()[8:-8])
return new_url
def add_new_url(self, url):
if url is None:
return
m = hashlib.md5()
#!!!!!!!!!!!
m.update(url.encode(encoding='utf-8'))
url_md5 = m.hexdigest()[8:-8]
if url not in self.new_urls and url_md5 not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def new_url_size(self):
return len(self.new_urls)
def old_url_size(self):
return len(self.old_urls)
def save_process(self, path, data):
with open(path, 'wb') as f:
pickle.dump(data, f)
def load_process(self, path):
print('[+] 从文件加载进度: %s' % path)
try:
with open(path, 'rb') as f:
tmp = pickle.load(f)
return tmp
except:
print('[!] 无进度文件,创建: %s' % path)
return set()
Html 下载器
# coding: utf-8
import requests
import random
import time
class HtmlDownloader(object):
#!!!!!!!!!!!
@staticmethod
def download(url):
if url is None:
return None
proxies = {
}
#!!!!!!!!!!!
user_agents = [
# Opera
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
# Firefox
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
# Safari
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
# chrome
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
# 360
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
# 淘宝浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
# 猎豹浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
# QQ浏览器
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E) ",
# sogou浏览器
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
# maxthon浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36",
# UC浏览器
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 13_3_1 like Mac OS X; zh-CN) AppleWebKit/537.51.1 (KHTML, like Gecko) Mobile/17D50 UCBrowser/12.8.2.1268 Mobile AliApp(TUnionSDK/0.1.20.3)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36",
"Mozilla/5.0 (Linux; Android 8.1.0; OPPO R11t Build/OPM1.171019.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/11.19 SP-engine/2.15.0 baiduboxapp/11.19.5.10 (Baidu; P1 8.1.0)",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 13_3_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 SP-engine/2.14.0 main%2F1.0 baiduboxapp/11.18.0.16 (Baidu; P2 13.3.1) NABar/0.0 ",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/17.17134",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Mozilla/5.0 (iPhone; CPU iPhone OS 12_4_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148 MicroMessenger/7.0.10(0x17000a21) NetType/4G Language/zh_CN",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36"
]
#!!!!!!!!!!!
user_agent = random.choice(user_agents)
headers = {'User-Agent': user_agent}
#!!!!!!!!!!!
time.sleep(random.randint(0, 5) * 0.05 + random.randint(4, 20) * 0.01)
# r = requests.get(url, headers=headers, proxies=proxies)
r = requests.get(url, headers=headers)
if r.status_code == 200:
r.encoding = 'utf-8'
return r.text
else:
print("DownLoad Failed")
return None
- 由于百度百科的反爬比作者写书时稍有变化,对代码进行改进使得顺利爬虫
- 改进1:随机选择 user_agent 进行访问,随机选择使用 random.choice 函数。该 user_agents 引用自 https://blog.csdn.net/a_123_4/article/details/119718509
- 改进2:采用随机延迟时间,实践证明,这一点十分有效
- 后续: 可以使用不同 Ip 代理
HTML 解析器
import re
#!!!!!!!!!!!
from urllib import parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parser(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
new_urls = set()
#!!!!!!!!!!!
pattern_one = re.compile(r'/item/.+?/\d+')
pattern_two = re.compile(r'/item/.+?(?=")')
# class="para MARK_MODULE"
# links = soup.find_all('div', class_='para MARK_MODULE').find_all('a', href=re.compile(r'/item/.+/\d+'))
#!!!!!!!!!!!
links = soup.find_all('div', class_="para MARK_MODULE")
#!!!!!!!!!!!
if len(links):
print("Crawl Successful")
if len(links) > 10:
links = links[:10]
else:
print("Crawl Failed")
#!!!!!!!!!!!
for link in links:
tmp = re.search(pattern_one, str(link))
if tmp:
new_full_url = parse.urljoin(page_url, tmp.group())
new_urls.add(new_full_url)
else:
tmp = re.search(pattern_two, str(link))
if tmp:
new_full_url = parse.urljoin(page_url, tmp.group())
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
data = dict()
data['url'] = page_url
#!!!!!!!!!!!
# <dd class="lemmaWgt-lemmaTitle-title J-lemma-title" data-pid="0">
title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title J-lemma-title').find('h1')
data['title'] = title.get_text()
print(data['title'])
#!!!!!!!!!!!
summary = soup.find('div', class_='lemma-summary J-summary')
data['summary'] = summary.get_text()
return data
- 这一部分是修改最多的一部分,基本重写了 _get_new_urls 函数
- 一方面来自于百度百科的 html 与之前有所不同,另一方面来自于有选择性地找链接(正文的链接)
数据存储器
import codecs
import time
class DataOutput(object):
def __init__(self):
self.datas = []
def store_data(self, data):
if data is None:
print("Data Exception")
return
self.datas.append(data)
# print(self.datas)
def output_html(self):
fileout = codecs.open('baike.html', 'w', encoding='utf-8')
fileout.write("<html>")
fileout.write("<body>")
fileout.write("<table>")
for data in self.datas:
fileout.write("<tr>")
fileout.write("<td>%s</td>" % data['url'])
fileout.write("<td>%s</td>" % data['title'])
fileout.write("<td>%s</td>" % data['summary'])
fileout.write("</tr>")
#!!!!!!!!!!!
fileout.write("</html>")
fileout.write("</body>")
fileout.write("</table>")
fileout.close()
- 注意! 删除原书中 self.datas.remove(data) 语句,这是个很致命的错误,会导致最终爬取到的信息是预期的一半。在遍历过程中删除遍历对象的元素是极其不明智的!
爬虫调度器
from DataOutput import DataOutput
from HtmlDownloader import HtmlDownloader
from HtmlParser import HtmlParser
from URLManager import URLManager, _URLManager
class SpiderMan(object):
def __init__(self):
#!!!!!!!!!!!
self.manager = _URLManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
#!!!!!!!!!!!
self.correct = []
def crawl(self, root_url):
self.manager.add_new_url(root_url)
while self.manager.has_new_url() and self.manager.old_url_size() < 300:
try:
new_url = self.manager.get_new_url()
print("当前解析的是%s" % new_url)
html = self.downloader.download(new_url)
new_urls, data = self.parser.parser(new_url, html)
self.manager.add_new_urls(new_urls)
self.output.store_data(data)
#!!!!!!!!!!!
print("已经抓取%s个链接" % self.manager.old_url_size())
print("成功抓取%s个链接" % len(self.output.datas))
except Exception as e:
print("crawl failed")
print(e.args)
finally:
#!!!!!!!!!!!
if self.manager.old_url_size() != 0:
self.correct.append(len(self.output.datas) / self.manager.old_url_size())
self.output.output_html()
#!!!!!!!!!!!
with open('ana.txt', 'w') as f:
f.write(str(self.correct))
f.close()
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
spider_man = SpiderMan()
spider_man.crawl("https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB?fromModule=lemma_search-box")
- 存储 ana.txt 便于我们事后分析爬虫效果
效果分析
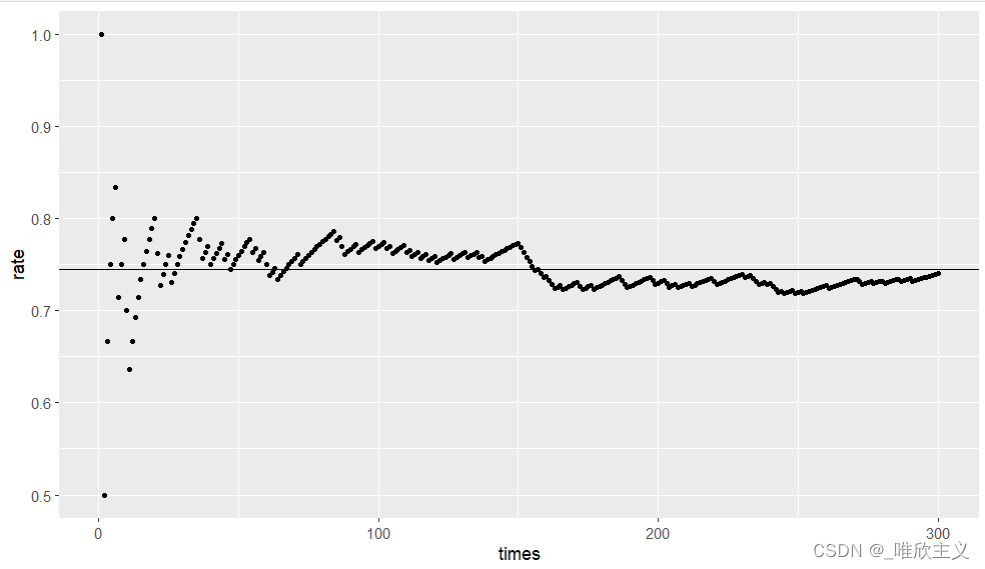
利用 ana.txt 中的数据,选择作者较为熟悉的R分析
ana <- read.csv("D:/PycharmProjects/Basic_crawl/ana.txt", header=FALSE)
ana[1] = 1.0
ana[300] = 0.76
Data = cbind(times = c(1:300), rate = as.numeric(ana))
ggplot(data = as.data.frame(Data), mapping = aes(times, rate)) + geom_point(size = 1) + geom_hline(yintercept = mean(Data[,2]))
Data2 = as.data.frame(Data[50:300,])
ggplot(data = as.data.frame(Data2), mapping = aes(times, rate)) + geom_point(size = 1) + geom_hline(yintercept = mean(Data2[,2]))






![P1095 [NOIP2007 普及组] 守望者的逃离](https://img-blog.csdnimg.cn/c25c6f6e29d54824a47632beb08c564f.png)