目录
暴力破解
KMP 算法
构造 next 数组
KMP代码
BM 算法
Sunday 算法
参考资料
又通过leetcode复习了之前的知识:
找出字符串中第一个匹配项的下标
暴力破解
你的面前有两段序列 S 和 T,你需要判断 T 是否可以匹配成为 S 的子串。
你可能会凭肉眼立即得出结论:是匹配的。可是计算机没有眼睛,只能对每个字符进行逐一比较。
对于计算机来讲,首先它会从左边第一个位置开始进行逐一比较:

这样,当匹配到 T 的最后一个字符时,发现不匹配,于是从 S 的第二个字符开始重新进行比较:

仍然不匹配,再次将 T 与 S 的第三个字符开始匹配......不断重复以上步骤,直到从 S 的第四个字符开始时,最终得出结论:S 与 T 是匹配的。

我们在进行每一轮匹配时,总是会重复对 A 进行比较。也就是说,对于 S 中的每个字符,我们都需要从 T 第一个位置重新开始比较,并且 S 前面的 A 越多,浪费的时间也就越多。假设 S 的长度为 m,T 的长度为 n,理论上讲,最坏情况下迭代 m−n+1 轮,每轮最多进行 n 次比对,一共比较了 (m−n+1)×n 次,当 m>>n 时,渐进时间复杂度为 O(mn)。
而 KMP 算法的好处在于,它可以将时间复杂度降低到 O(m+n),字符序列越长,该算法的优势越明显。
KMP 算法
Knuth–Morris–Pratt(KMP)算法是一种改进的字符串匹配算法,它的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。它的时间复杂度是 O(m+n)。
KMP算法回答了一个问题,那就是当模式串不匹配时是不是只能向前移动一位重新匹配?如果不是,那么能够移动几位?
针对这个问题,KMP提出了通过找到最长公共前缀后缀来决定模式串不同位置在匹配时需要移动的位数。
现在有如下字符串 S 和 P,判断 P 是否为 S 的子串。

1. 我们仍然按照原来的方式进行比较,比较到 P 的末尾时,我们发现了不匹配的字符。
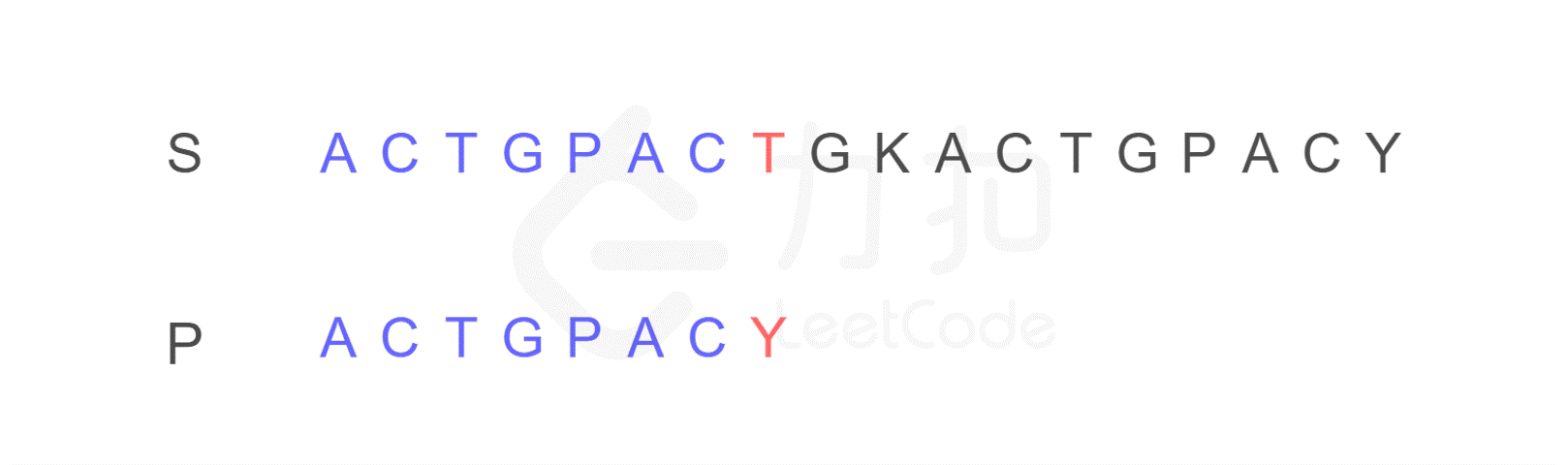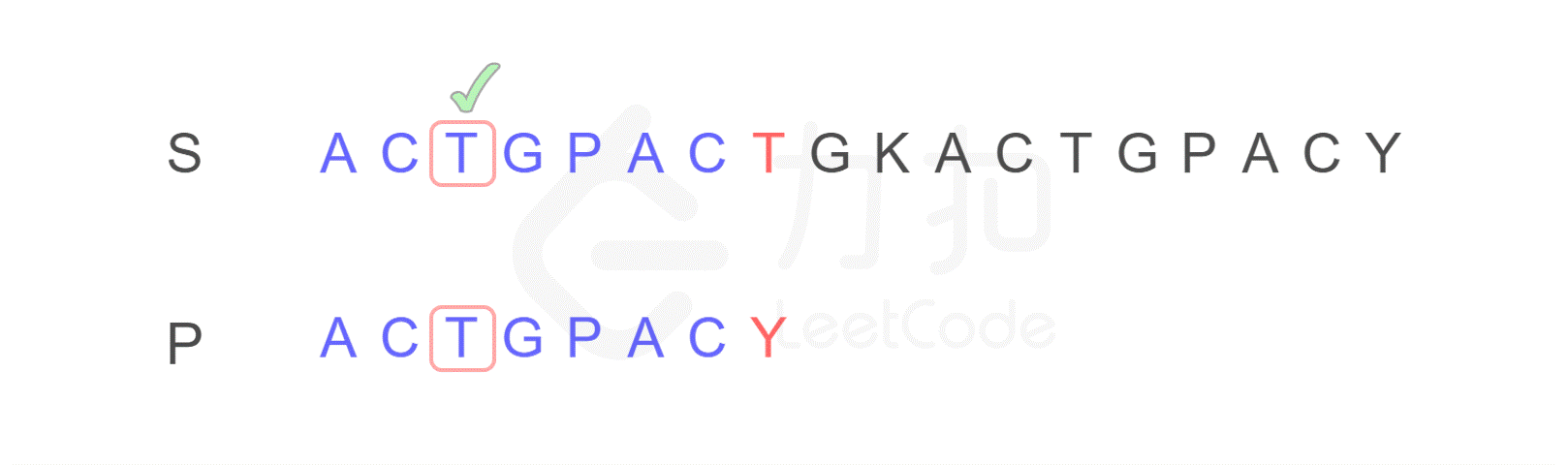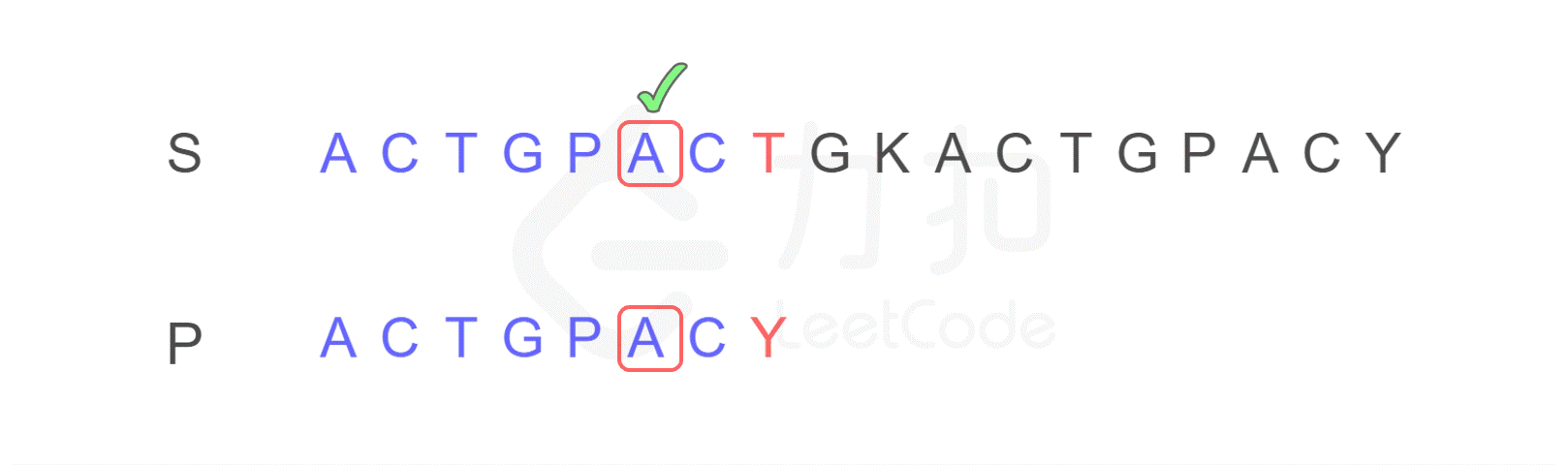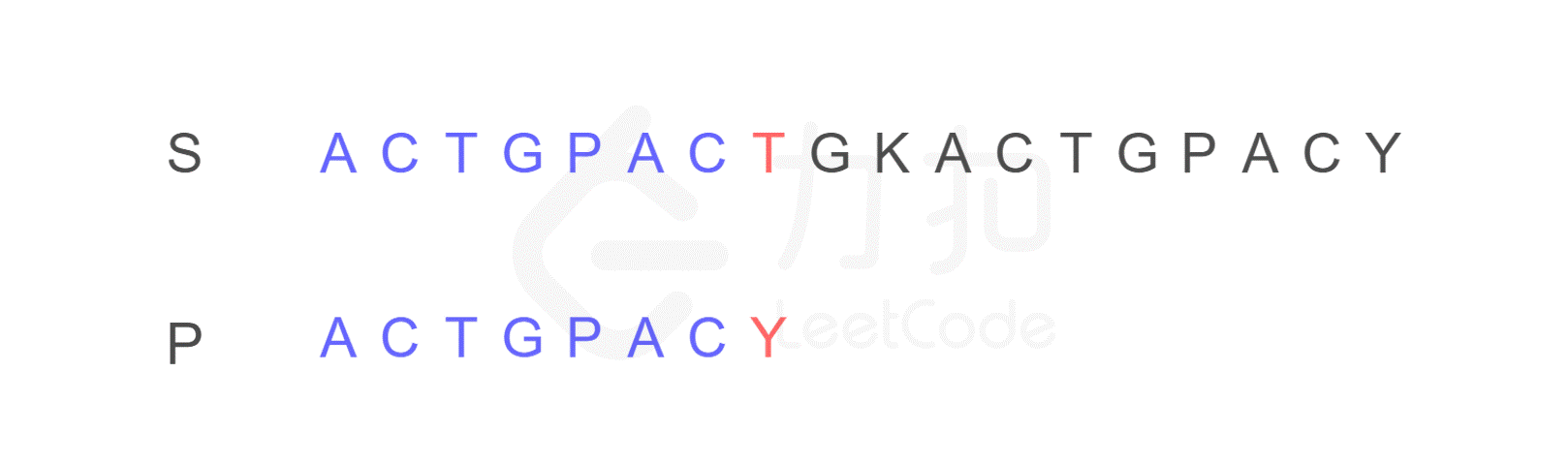
2. 按照原来的思路,我们下一步应将字符串 P 的开头,与字符串 S 的第二位 C 重新进行比较。而 KMP 算法告诉我们,我们只需将字符串 P 需要比较的位置重置到图中 j 的位置,S 保持 i 的位置不变,接下来即可从 i,j 位置继续进行比较。
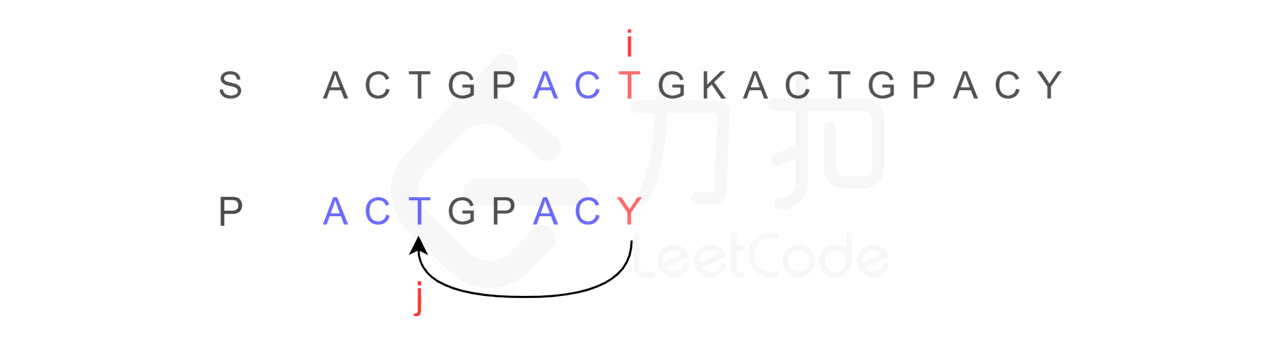
因为可以发现字符串 P 有子串 ACT 和 ACY,当 T 和 Y 不匹配时,我们就确定了 S 中的蓝色 AC 并不匹配 P 右侧的 AC,但是可能匹配左侧的 AC,所以我们从位置 i 和 j 继续比较。
换句话说,Y 对应下标 2,表示下一步要重新开始的地方。
既然如此,如果每次不匹配的时候,我们都能立刻知道 P 中不匹配的元素,下一步应该从哪个下标重新开始,这样不就能大大简化匹配过程了吗?这就是 KMP 的核心思想。
KMP 算法中,使用一个数组 next 来保存 P 中元素不匹配时,下一步应该重新开始的下标。由于计算机不能像我们人类一样,通过视觉来得出结论,因此这里有一种适合计算机的构造 next 数组的方法。
构造 next 数组
构造方法为:P[i] 对应的下标,为 P[0...i + 1] 的最长公共前缀后缀的长度,令 P[0] = -1。 具体解释如下:
例如对于字符串 abcba:
- 前缀:它的前缀包括:a, ab, abc, abcb,不包括本身;
- 后缀:它的后缀包括:bcba, cba, ba, a,不包括本身;
- 最长公共前缀后缀:abcba 的前缀和后缀中只有 a 是公共部分,字符串 a 的长度为 1。
所以,我们将 P[0...i + 1] 的最长公共前后缀的长度作为 P[i] 的下标,就得到了 next 数组。

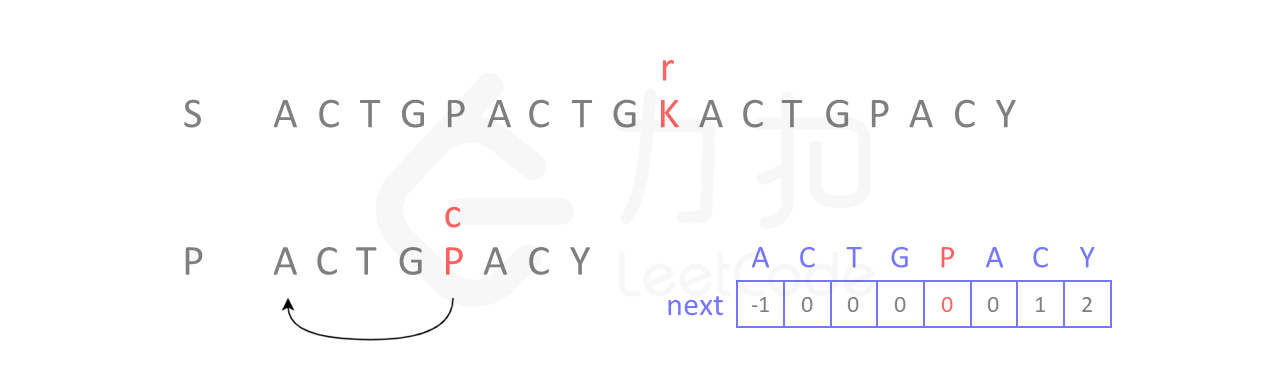
4. 了解next数组之后。上次我们还停留在位置 i 和 j,现在继续进行比较。从如下图所示,由于我们已经构造了 next 数组,当继续移动到图中的 r 和 c 位置时,发现不匹配,根据 next 数组,我们可以立即将位置 c 回到下标 0 的位置:
5. 之后的情形就很简单了:
- K 与 A 不匹配,查看 next 数组,A 对应 next 中的元素为 -1,表示不动,r 加 1;
- 位置 r 字符与位置 c 字符匹配,继续比较下一位;
- 后面元素均匹配,最终找到匹配元素。
KMP代码
public class KMP {
public static void main(String[] args) {
System.out.println(kmpMatch("actgpactgkactgpacy", "actgpacy"));
}
/**
* 对主串s和模式串t进行KMP模式匹配
* @param s 主串
* @param t 模式串
* @return 若匹配成功,返回t在s中的位置(第一个相同字符对应的位置),若匹配失败,返回-1
*/
public static int kmpMatch(String s, String t){
char[] s_arr = s.toCharArray();
char[] t_arr = t.toCharArray();
int[] next = getNextArray(t_arr);
// j 代表 模式串t的位置指针
int i = 0, j = 0;
while (i<s_arr.length && j<t_arr.length){
// 如果j = -1,或者当前字符匹配成功,都令i++,j++
if(j == -1 || s_arr[i]==t_arr[j]){
i++;
j++;
}
else{
// 如果j != -1,且当前字符匹配失败,则令 i 不变,j = next[j]
// next[j]即为j所对应的next值
j = next[j];
}
}
// 遍历结束
if(j == t_arr.length)
return i-j;
else
return -1;
}
/**
* 求出一个字符数组的next数组
* @param t 字符数组
* @return next数组
*/
public static int[] getNextArray(char[] t) {
int[] next = new int[t.length];
next[0] = -1;
next[1] = 0;
int k;
for (int j = 2; j < t.length; j++) {
k=next[j-1];
while (k!=-1) {
// 最长的 前缀和后缀匹配,根据 刚进入子串的 j-1 和之前的匹配结果对比匹配
// 匹配成功
if (t[j - 1] == t[k]) {
next[j] = k + 1;
break;
}
else {
k = next[k];
}
//当k==-1而跳出循环时,next[j] = 0,否则next[j]会在break之前被赋值
next[j] = 0;
}
}
return next;
}
}BM 算法
KMP的匹配是从模式串的开头开始匹配的,而BM(Boyer-Moore)算法是从模式串的尾部开始匹配,且拥有在最坏情况下O(N)的时间复杂度。在实践中,比KMP算法的实际效能高。
BM算法定义了两个规则:
- 坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 = 坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。此外,如果"坏字符"不包含在模式串之中,则最右出现位置为-1。
- 好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
例如,给定文本串“HERE IS A SIMPLE EXAMPLE”,和模式串“EXAMPLE”,现要查找模式串是否在文本串中,如果存在,返回模式串在文本串中的位置。
1. 首先,"文本串"与"模式串"头部对齐,从尾部开始比较。"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符,它对应着模式串的第6位。且"S"不包含在模式串"EXAMPLE"之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到"S"的后一位。

2. 依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在模式串"EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。

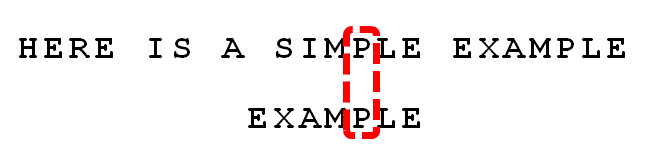
3. 依次比较,得到 “MPLE”匹配,称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。

4. 发现“I”与“A”不匹配:“I”是坏字符。如果是根据坏字符规则,此时模式串应该后移2-(-1)=3位。问题是,有没有更优的移法?
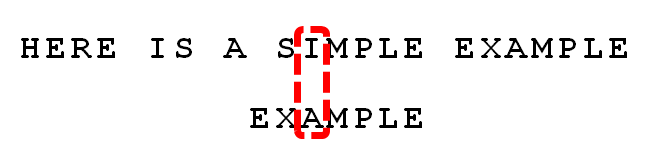
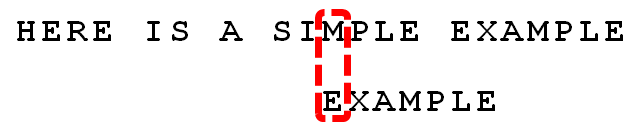
5. 更优的移法是利用好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串中上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
所有的“好后缀”(MPLE、PLE、LE、E)之中,只有“E”在“EXAMPLE”的头部出现,所以后移6-0=6位。
可以看出,“坏字符规则”只能移3位,“好后缀规则”可以移6位。每次后移这两个规则之中的较大值。这两个规则的移动位数,只与模式串有关,与原文本串无关。
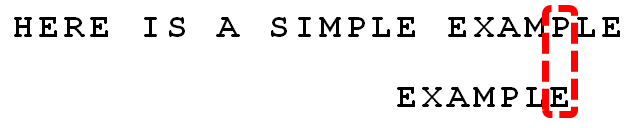
6. 继续从尾部开始比较,“P”与“E”不匹配,因此“P”是“坏字符”,根据“坏字符规则”,后移 6 - 4 = 2位。因为是最后一位就失配,尚未获得好后缀。
由上可知,BM算法不仅效率高,而且构思巧妙,容易理解。
Sunday 算法
Sunday算法的思想跟BM算法很相似,只不过Sunday算法是从前往后匹配,在匹配失败时关注的是文本主串中参加匹配的最末位字符的下一位字符。
平均性能的时间复杂度为(n)
最差情况的时间复杂度为O(n * m)
- 如果该字符没有在模式串中出现则直接跳过,即移动位数 = 匹配串长度 + 1;
- 否则,其移动位数 = 模式串中最右端的该字符到末尾的距离+1。
下面举个例子说明下Sunday算法。假定现在要在主串”substring searching”中查找模式串”search”。
1. 刚开始时,把模式串与文本串左边对齐:

2. 结果发现在第2个字符处发现不匹配,不匹配时关注文本串中参加匹配的最末位字符的下一位字符,即标粗的字符 i,因为模式串search中并不存在i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符n)开始下一步的匹配,如下图:

3. 结果第一个字符就不匹配,再看文本串中参加匹配的最末位字符的下一位字符,是'r',它出现在模式串中的倒数第3位,于是把模式串向右移动3位(r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个'r'对齐,如下:

4. 匹配成功。
回顾整个过程,我们只移动了两次模式串就找到了匹配位置,缘于Sunday算法每一步的移动量都比较大,效率很高。
参考资料
(选修)字符串匹配算法:KMP
从头到尾彻底理解KMP