哈喽大家好,我是咸鱼
之前写过一篇获取知网文献信息的文章,看了下后台数据还挺不错
所以咸鱼决定再写一篇知网文献信息爬取的文章
需要注意的是文章只是针对某一特定期刊的爬取,希望小伙伴们把关注点放在如何分析网页以及如何定位元素上面
这样就能写出适合自己的爬虫代码了,而不是照搬我的
网址链接:https://navi.cnki.net/knavi/journals/RKYZ/detail?uniplatform=NZKPT
需求分析
我们来分析下网页结构
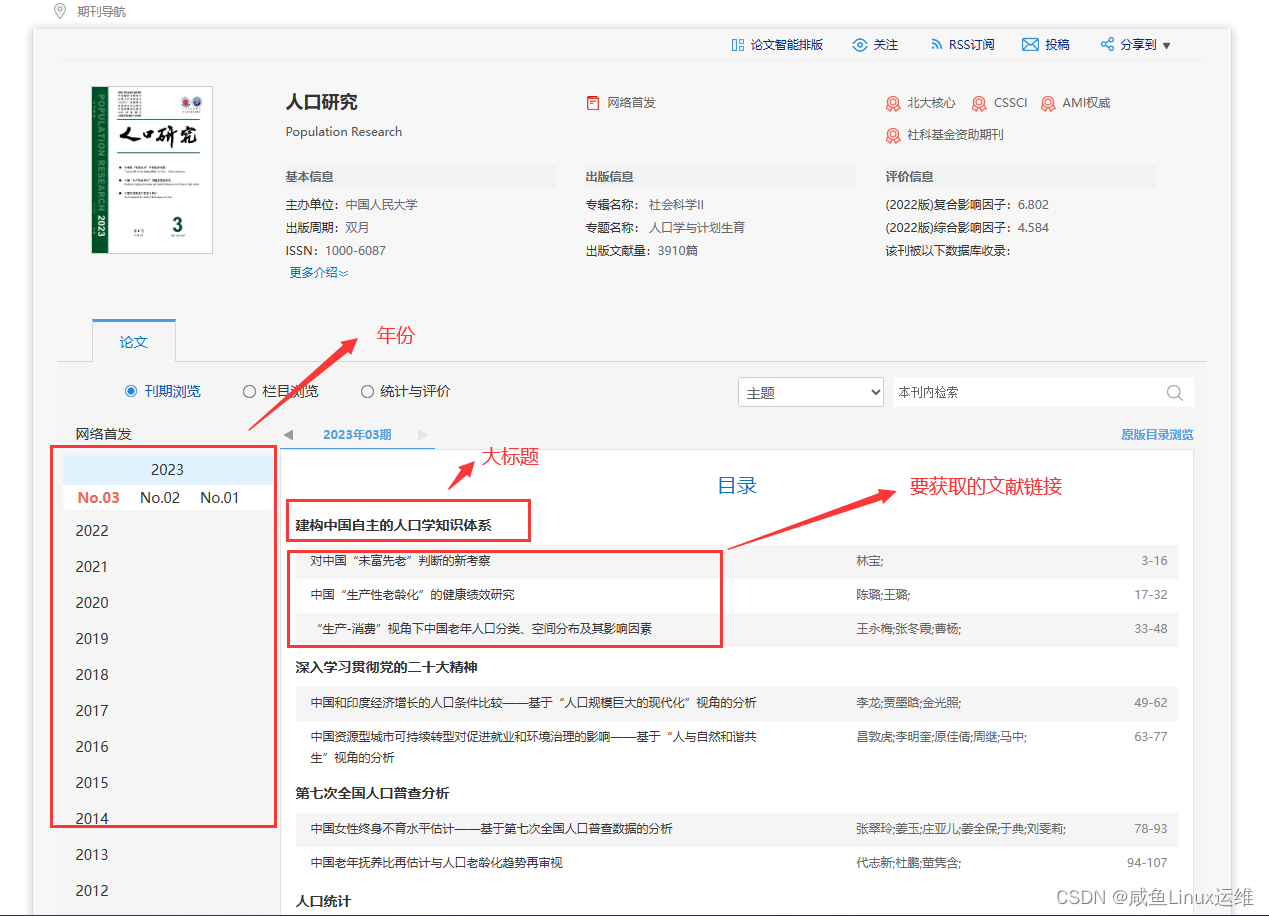
由上图可得知:
- 左边是一个个年份(2023、2022、2021),年份下面还有期数(No.03、No.02、No.01)
- 右边加粗的字体看作是大标题,每一个大标题下面都有要获取的文献标题(其实是一个个链接)
那我们需要做的就是把这些文献的链接一个个先获取下来,然后再打开每一条链接去获取对应文献的信息(摘要、关键词…)
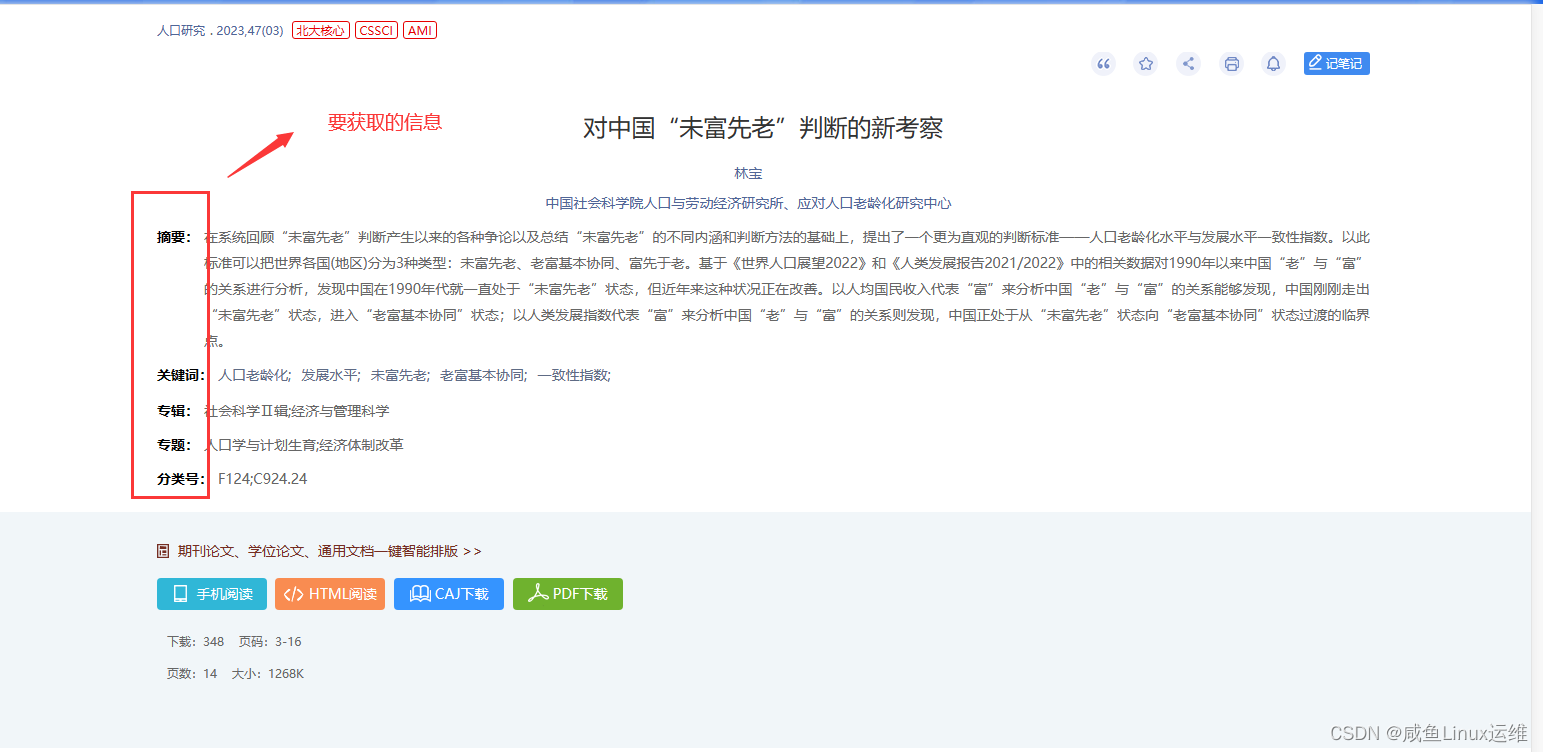
但是今天咸鱼先只写爬到文献链接那一步,后面的打开每条链接获取文献信息这部分小伙伴们可以先自己尝试一下,
我们以爬取 2022 年相关文献为例子,得出 selenium 模拟人浏览网页的操作,然后分析网页并定位元素
首先点击年份 2022,然后依次点击期数(No.06、No.05…)
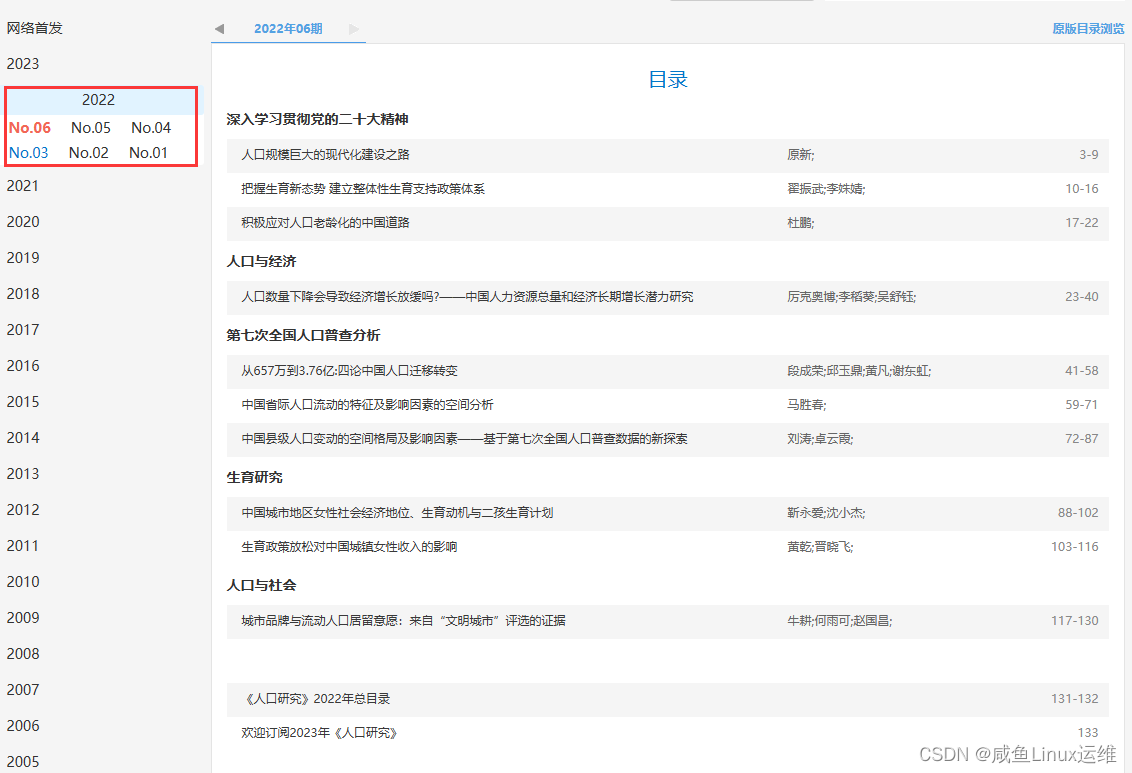
我们每点击一次期数,然后就爬取对应期数下面的文献链接,并用大标题分类
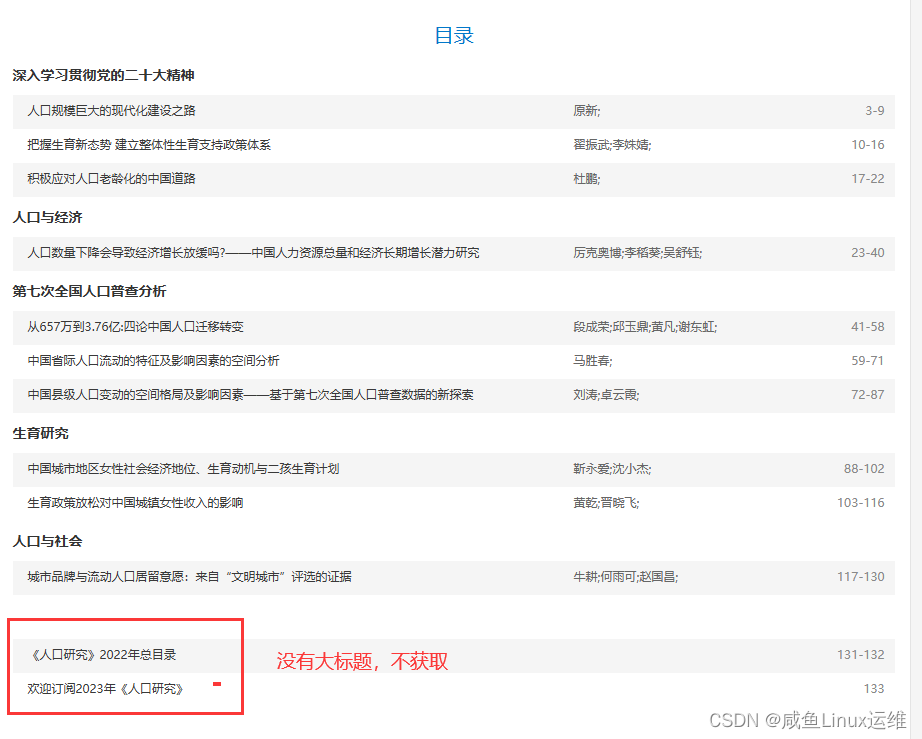
需要注意的是:每一期最后可能会有几篇没有大标题的链接,那个不是我们要获取的文献,所以我们需要做一个判断:
- 如果大标题存在,就获取下面的内容
- 如果没有大标题,就跳过不获取
最后我们将获取到的链接和标题保存在 csv 文件里面,如下所示

元素定位
首先我们来分析一下年份的元素路径,F12 打开开发者工具
然后点击元素,把鼠标移到对应元素那里
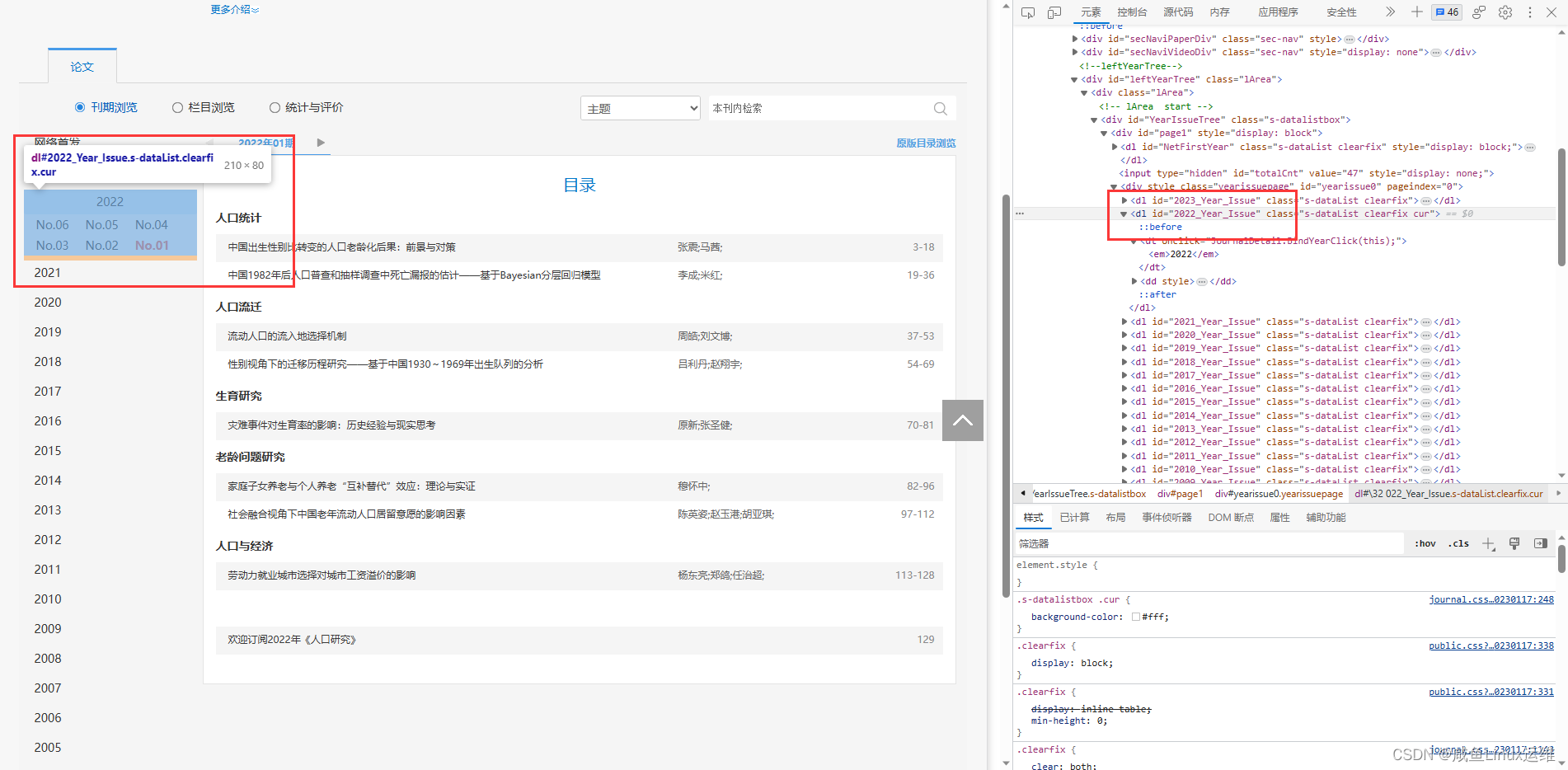
#年份 xpath 路径
//dl[@id='2022_Year_Issue']
按照上面的方法我们依次来定位
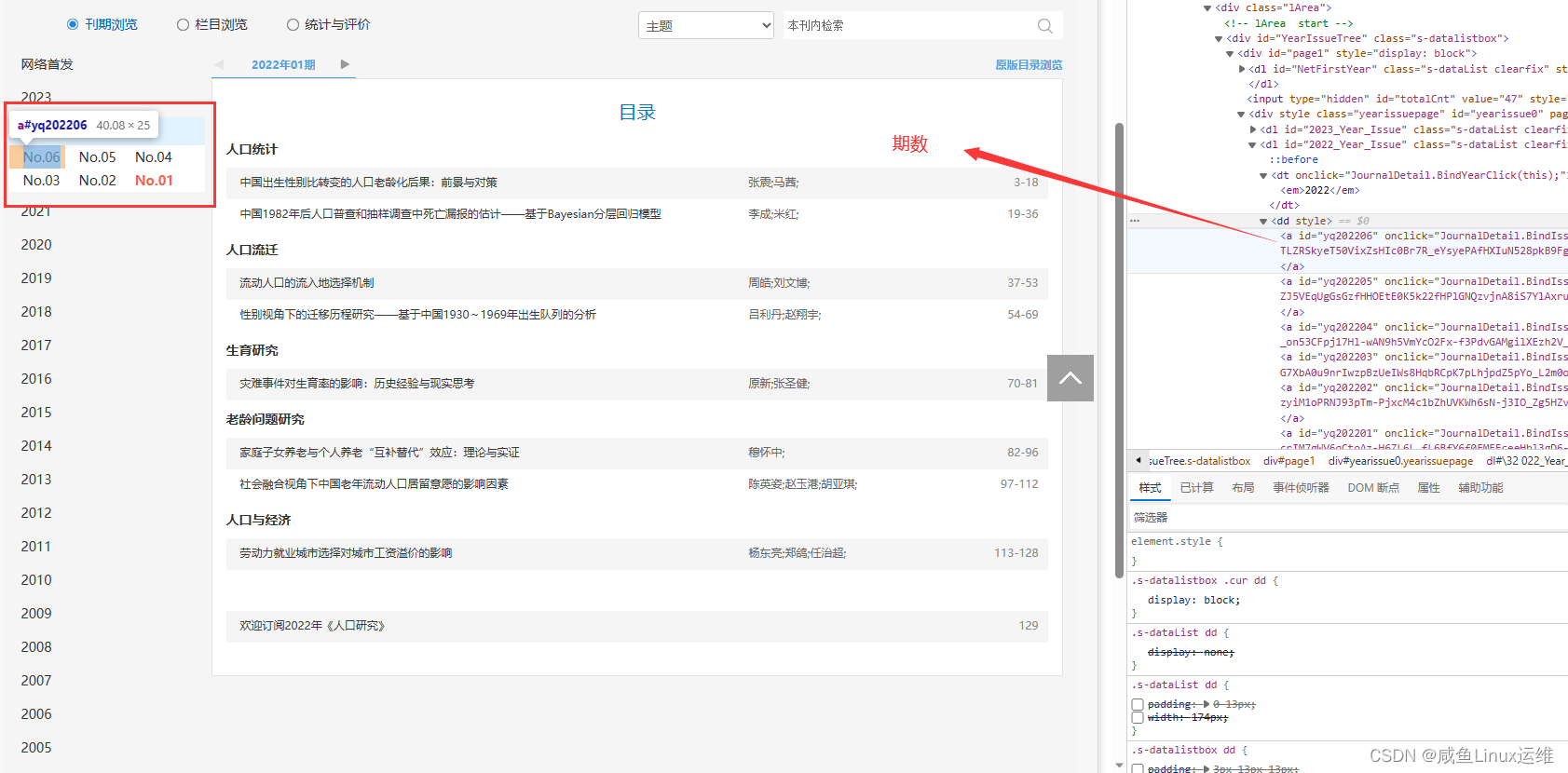
得到定位路径如下:
# 期数 xpath 路径
//dl[@id='2022_Year_Issue']/dd/a[starts-with(@id, 'yq')]
# 大标题 xpath 路径
./dt[@class="tit"]
# 文献链接 xpath 路径
./dd/span/a
代码实现
源码如下:
# -*- coding:utf-8 -*-
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class CnkiSpider(object):
def __init__(self):
self.url = "https://navi.cnki.net/knavi/journals/RKYZ/detail?uniplatform=NZKPT"
# get直接返回,不再等待界面加载完成
self.desired_capabilities = DesiredCapabilities.CHROME
self.desired_capabilities["pageLoadStrategy"] = "none"
# 设置浏览器驱动器的环境
self.options = webdriver.ChromeOptions()
# 设置浏览器不加载图片,提高速度
self.options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 设置不显示窗口
self.options.add_argument('--headless')
# 创建一个浏览器驱动器
self.driver = webdriver.Chrome(options=self.options)
def get_url(self):
url_dict = {}
self.driver.get(self.url)
time.sleep(3)
# 年份
WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, "//dl[@id='2022_Year_Issue']"))).click()
# 期数
for i in WebDriverWait(self.driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, "//dl[@id='2022_Year_Issue']/dd/a[starts-with(@id, 'yq')]"))):
# date = i.get_attribute('id') # yq202206
i.click()
time.sleep(3)
for j in WebDriverWait(self.driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//*[@id="CataLogContent"]/div/div'))):
href_list = []
# 大标题:例如深入学习贯彻党的二十大精神
theme = WebDriverWait(j, 10).until(EC.presence_of_element_located((By.XPATH, './dt[@class="tit"]'))).text
if theme:
for element in WebDriverWait(j, 10).until(EC.presence_of_all_elements_located((By.XPATH, './dd/span/a'))):
# 文献链接 (href 属性)
href = element.get_attribute('href')
href_list.append(href)
else:
continue
url_dict[theme] = href_list
return url_dict
# 关闭浏览器
self.driver.close()
def run(self):
url_dict = self.get_url()
# 写入 csv 文件
with open('test.csv', 'a+') as fd:
for key in url_dict.keys():
fd.write(key + '\n')
for value in url_dict.get(key, '不存在'):
fd.write(value + '\n')
if __name__ == "__main__":
spider = CnkiSpider()
spider.run()