1前言
启动速度优化是 android 开发中的常见需求,除了一些常规的手段之外,也有一些黑科技手段,我们来看一下这些黑科技手段是否有效,以及如何实现
本文主要是对Android 性能优化小册相关内容的学习实践,加入了自己的理解与实践内容,感兴趣的同学可以点击查看小册。
2线程优先级设置
线程优先级设置的概念很容易理解,优先级越高的线程越容易获取 CPU 时间片,那么为了保证 app 的流畅运行,那么我们就应该将核心线程的优先级提高,而将其他线程的优先级调低。对于 app 来说,核心线程就是主线程 + RenderThread,那么我们是否有必要手动设置线程优先级呢?我们可以通过以下命令获取当前的线程优先级。
adb shell
ps -A | grep 包名 // 根据包名找到Pid
top -H -p PID // 查看线程优先级命令

运行结果如上图所示,要看懂上面的图我们要先了解一点背景知识。
- PR: 优先级 (priority),值越小优先级越高,会受NI的值的影响。
- NI: 即 Nice 值,我们可以通过Process.setThreadPriority设置,同样是值越小优先级越高。
其实我们只需要知道它们都是值越小优先级越高就好了,可以看出主线程与 RenderThread 的优先级都挺高的,仅次于 Binder 线程。
我看到一些启动优化的文章谈到线程优先级设置,但测试结果似乎是没有必要?难道是版本问题?有了解的同学可以在评论区说下。
3核心线程绑定大核
绑定大核是否有必要?
核心线程绑定大核的思路也很容易理解,现在的 CPU 都是多核的,大核的频率比小核要高不少,如果我们的核心线程固定运行在大核上,那么应用性能自然会有所提升。就拿我手上的小米10来说,使用的是骁龙865的 CPU,由一颗A77超大核+三颗A77大核+四颗A55小核心组成,我们可以通过/sys/devices/system/cpu/目录下的文件获取各个核的频率,如下所示:
cas:/sys/devices/system/cpu $ cat cpu0/cpufreq/cpuinfo_max_freq
1804800
cas:/sys/devices/system/cpu $ cat cpu1/cpufreq/cpuinfo_max_freq
1804800
cas:/sys/devices/system/cpu $ cat cpu2/cpufreq/cpuinfo_max_freq
1804800
cas:/sys/devices/system/cpu $ cat cpu3/cpufreq/cpuinfo_max_freq
1804800
cas:/sys/devices/system/cpu $ cat cpu4/cpufreq/cpuinfo_max_freq
2419200
cas:/sys/devices/system/cpu $ cat cpu5/cpufreq/cpuinfo_max_freq
2419200
cas:/sys/devices/system/cpu $ cat cpu6/cpufreq/cpuinfo_max_freq
2419200
cas:/sys/devices/system/cpu $ cat cpu7/cpufreq/cpuinfo_max_freq
2841600
可以看出,cpu0 到 cpu3 是4个小核, cpu4 到 cpu6 是3个大核,cpu7 是超大核,它们之间的频率还是相差挺大的。同时通过 systrace 工具可以发现,主线程基本都运行在 cpu7 这个超大核上,而 RenderThread 会在 cpu4 到 cpu6 间切换,有时甚至会调度到小核上。因此可以看出还是有必要把 RenderThread 绑定到一个大核上的,绑定可以更好的利用缓存以及减少线程的上下文切换。
绑定大核实现
绑定大核是通过函数sched_setaffinity实现的。
extern "C" JNIEXPORT void JNICALL
Java_com_zj_android_startup_optimize_StartupNativeLib_bindCore(
JNIEnv *env,
jobject /* this */, jint thread_id, jint core) {
cpu_set_t mask; //CPU核的集合
CPU_ZERO(&mask); //将mask置空
CPU_SET(core, &mask); //将需要绑定的cpu核设置给mask,核为序列0,1,2,3……
if (sched_setaffinity(thread_id, sizeof(mask), &mask) == -1) { //将线程绑核
LOG("bind thread %d to core %d fail", thread_id, core);
} else {
LOG("bind thread %d to core %d success", thread_id, core);
}
}
如上所示,sched_setaffinity共有 3 个参数。
- 参数 1 是线程的 id,如果为 0 则表示主线程。
- 参数 2 表示 cpu 序列掩码的长度。
- 参数 3 则表示需要绑定的 cpu 序列的掩码。
以上是线程绑定大核的核心代码,可以看到我们还需要获取 RenderThread 的 id ,以及 cpu 大核的序列。应用中线程的信息记录在 /proc/pid/task 的文件中,通过解析 task 文件就可以获取当前进程的所有线程,而 cpu 大核序列也可以通过解析 /sys/devices/system/cpu 目录实现。
具体代码就不在这里粘贴了,完整代码可见文末链接。
4GC 抑制
GC 抑制是否有必要?
我们知道 Java 的垃圾回收机制,在 Android 5.0 之后,ART 取代了 Dalvik,ART 虚拟机在垃圾回收的时候虽然没有像 Dalvik 一样 stop the world,但在启动阶段如果发生垃圾回收,GC 线程同样抢占了不少系统资源。
Google 也注意到启动阶段 GC 对启动速度的影响,并在 Android 10 之后做了一定的优化,详情可见如下提交:

可以看出,基本思路是在 2s 内提高后台 GC 的阈值,减少启动阶段的 GC 次数,根据 Google 的测试,抑制 GC 后效果如下:

可以看出,GC 次数明显减少,启动速度也有一定的提升。那么我们是不是可以使用一些手段让 Android 10 以下也能实现这个效果呢?同时我们也可以通过以下代码获取 gc 的次数与耗时,方便统计 gc 对启动耗时的影响,以评估是否有必要做 GC 抑制。
Debug.getRuntimeStat("art.gc.gc-count") // gc 次数
Debug.getRuntimeStat("art.gc.gc-time") // gc 耗时
Debug.getRuntimeStat("art.gc.blocking-gc-count") // 阻塞 gc 次数
Debug.getRuntimeStat("art.gc.blocking-gc-time") // 阻塞 gc 耗时
GC 抑制实现
HeapTaskDaemon 执行流程
GC 主要是通过 HeapTaskDaemon 线程实现的,这是一个守护线程,在 Zygote 线程启动后这个线程也就启动了,启动后主要做了以下工作:

- 从HeapTaskDaemon.runInternal()方法开始一步步调用到 native 层的 task_processor.RunAllTasks() 方法。
- 当TaskProcessor中的tasks为空时,会休眠等待,否则会取出第一个HeapTask并执行其Run方法。
而HeapTask的Run方法是一个虚函数,需要子类来实现。
class HeapTask : public SelfDeletingTask {
};
class SelfDeletingTask : public Task {
};
class Task : public Closure {
};
class Closure {
public:
virtual ~Closure() { }
// 定义 Run 虚函数
virtual void Run(Thread* self) = 0;
};
HeapTask就是垃圾回收的任务,有多个子类,比如最常见的 ConcurrentGCTask 就是其子类,在 Java 内存达到阈值时就会执行这个 Task,用于执行并发 GC。
方案设计
在了解了 HeapTaskDaemon 的执行流程之后,我们想到,如果启动时在ConcurrentGCTask的Run方法执行前休眠一段时间,不就可以实现 GC 抑制了吗?而Run方法正好是虚函数,虚函数与 Java 中的抽象函数类似,留给子类去扩展实现多态。虚函数和外部库函数一样都没法直接执行,需要在表中去查找函数的真实地址,那么我们是不是可以使用类似 PLT Hook的思路,使用自定义函数的地址替换原有函数地址,实现 Hook 呢?

答案是肯定的,如上图所示,一个类中如果存在虚函数,那么编译器就会为这个类生成一张虚函数表,并且将虚函数表的地址放在对象实例的首地址的内存中。同一个类的不同实例,共用一张虚函数表的。因此我们的主要思路如下:
- 启动时将虚函数表中的 Run 函数地址替换为自定义函数地址。
- 在自定义函数内部休眠一段时间,抑制 GC。
- 休眠完成后将虚函数表中的函数地址替换回来,避免影响后续执行。
具体实现
很显然要想实现 Hook,我们首先需要获取ConcurrentGCTask对象地址与其Run方法地址那么我们可以如何获取方法地址呢?dlopen 函数和 dlsym 可以用于打开动态链接库中的函数,通过函数的符号返回函数地址。因此我们需要做下面两件事:
- 获取函数符号。
- 根据函数符号获取函数地址。
adb pull /system/lib64/libart.so // Android 10 以前系统,Android 10 之后换了位置
aarch64-linux-android-readelf -s --wide libart.so
通过以上方式可以导出 so 中的符号,查找到结果如下:
_ZTVN3art2gc4Heap16ConcurrentGCTaskE // ConcurrentGCTask
_ZN3art2gc4Heap16ConcurrentGCTask3RunEPNS_6ThreadE // Run 方法
可以看出,符号是原来的名字做了一定的变换,这是 c++ 的 name mangling 机制,mangling的目的就是为了给重载的函数不同的签名,具体的规则可以自行查阅,这里就不赘述了。还有需要注意的一点是,Android 7.0 以上对 dlsym 的调用有限制,同时从 aarch64-linux-android-readelf 的结果可以看出, ConcurrentGCTask 在 .dynsym 段,而 Run 方法在 .symtab 段,而 dlsym 只能搜索 .dynsym 段,而无法搜索 .symtab 段,因此我们这里使用enhanced_dlsym开源库,既支持 Android 7.0 以上调用,也可以查找 .stymtab 段。好了,前置知识讲完了,下面来看下代码:
void delayGC() {
//以RTLD_NOW模式打开动态库libart.so,拿到句柄,RTLD_NOW即解析出每个未定义变量的地址
void *handle = enhanced_dlopen("/system/lib64/libart.so", RTLD_NOW);
//通过符号拿到ConcurrentGCTask对象地址
void *taskAddress = enhanced_dlsym(handle, "_ZTVN3art2gc4Heap16ConcurrentGCTaskE");
//通过符号拿到run方法
void *runAddress = enhanced_dlsym(handle, "_ZN3art2gc4Heap16ConcurrentGCTask3RunEPNS_6ThreadE");
//由于 ConcurrentGCTask 只有五个虚函数,所以我们只需要查询前五个地址即可。
for (size_t i = 0; i < 5; i++) {
//对象头地址中的内容存放的就是虚函数表的地址,所以这里是指针的指针,即是虚函数表地址,拿到虚函数表地址后,转换成数组,并遍历获取值
void *vfunc = ((void **) taskAddress)[i];
// 如果虚函数表中的值是前面拿到的 Run 函数的地址,那么就找到了Run函数在虚函数表中的地址
if (vfunc == runAddress) {
//这里需要注意的是,这里 +i 操作拿到的是地址,而不是值,因为这里的值是 Run 函数的真实地址
mSlot = (void **) taskAddress + i;
}
}
// 保存原有函数
originFun = *mSlot;
// 将虚函数表中的值替换成我们hook函数的地址
replaceFunc(mSlot, (void *) &hookRun);
}
//我们的 hook 函数
void hookRun(void *thread) {
//休眠3秒
sleep(3);
//将虚函数表中的值还原成原函数,避免每次执行run函数时都会执行hook的方法
replaceFunc(mSlot, originFun);
//执行原来的Run方法
((void (*)(void *)) originFun)(thread);
}
核心代码就是上面这些,主要做了这么几件事:
- 通过符号获取Run方法地址。
- 遍历虚函数表,找到虚函数表中存放Run方法真实地址的位置。
- 保存原函数地址,并将虚函数表中的值替换成我们 hook 的函数地址。
- 在 hook 函数中休眠一段时间,休眠结束后还原虚函数表,避免影响后续任务。
5总结
在性能优化中除了一些常规手段外,也经常有一些黑科技手段,本文主要介绍了启动优化中的线程优先级设置,核心线程绑定大核,GC 抑制等手段, 讲解了一下这些黑科技手段是否有效,以及具体是怎么实现的,希望对你有所帮助。
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的核心笔记(还该底层逻辑):https://qr18.cn/FVlo89
性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化

网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化

体积包优化

《Android 性能监控框架》:https://qr18.cn/FVlo89

《Android Framework学习手册》:https://qr18.cn/AQpN4J
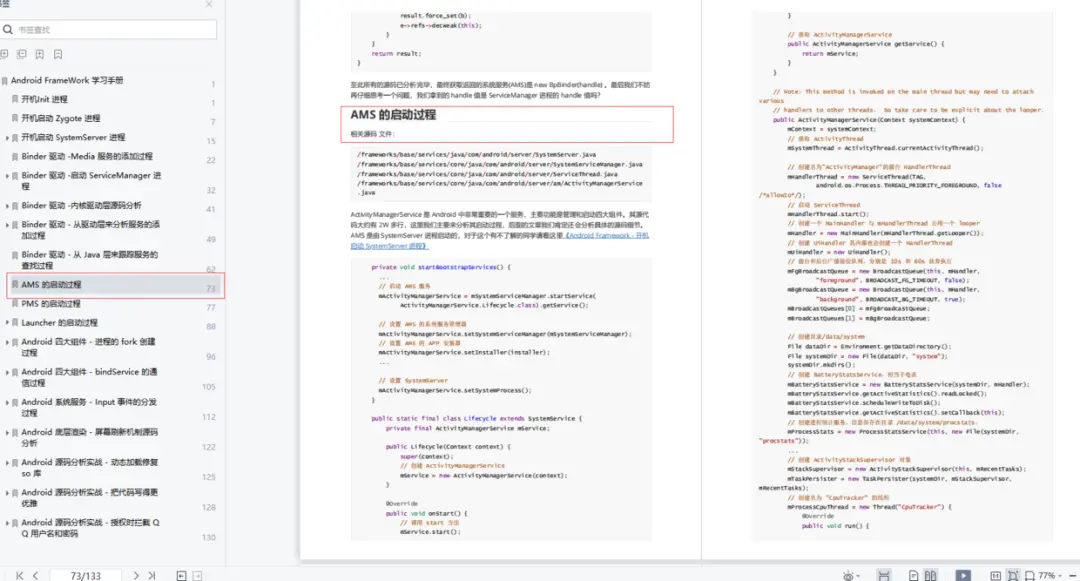
- 开机Init 进程
- 开机启动 Zygote 进程
- 开机启动 SystemServer 进程
- Binder 驱动
- AMS 的启动过程
- PMS 的启动过程
- Launcher 的启动过程
- Android 四大组件
- Android 系统服务 - Input 事件的分发过程
- Android 底层渲染 - 屏幕刷新机制源码分析
- Android 源码分析实战