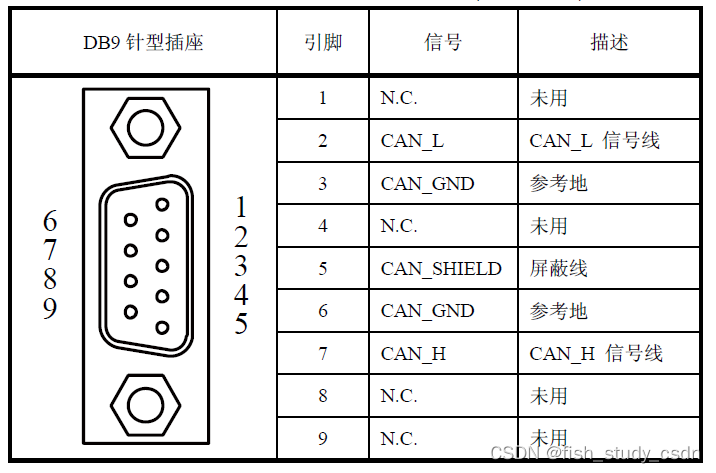
任务型对话(TOD)系统旨在帮助用户解决从天气咨询到计划安排的一系列问题。完成任务的途径有二。
其一是端到端途径:直接将当前对话内容与系统的自然语言反映相关联。此种方法多是采用序列到序列的模型,然后进行监督训练。
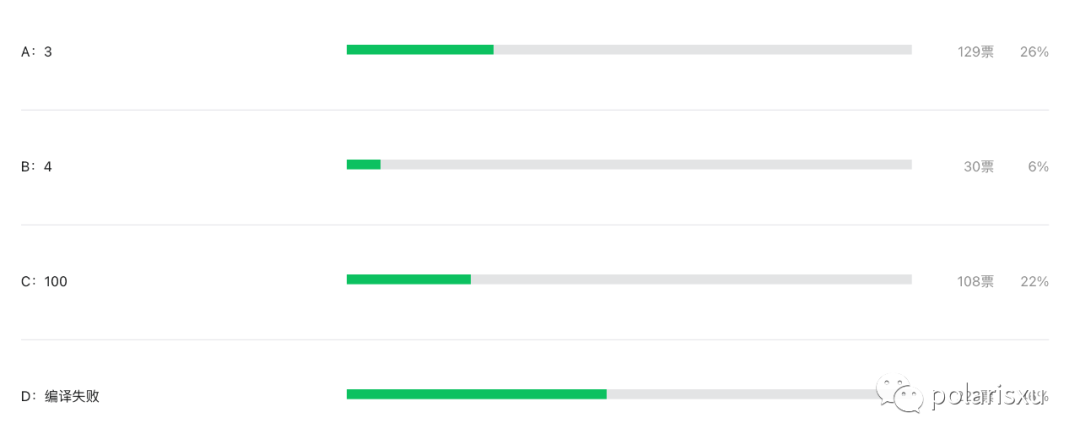
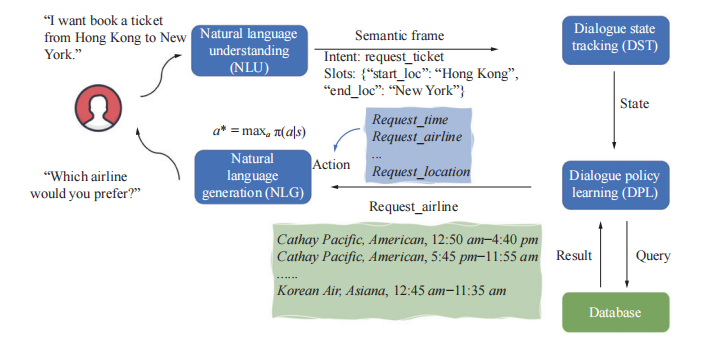
第二种是模组途径:将系统分为四个相互依存的的组成部分:自然语言理解(NLU)、对话状态追踪(DST)、对话策略学习(DPL)和自然语言生成(NLG),如图1所示。
两种方法都有各自的优劣。端到端途径更灵活且对数据注释的需求更少。但却需要大量数据,且其黑盒结构完全不进行说明与控制。相反,模组途径更易理解和实施。尽管整个系统很难进行整体优化,但大部分商业对话系统都更倾向于管道途径。本文的研究也是对模组途径进行综述并总结对话策略学习的当前进展。文章会简单介绍管道途径四个模块的不同功能,然后对对话策略学习模块进行进一步说明。
四个模块中,NLU旨在将输入句子的意图和槽位识别为第一个直接与用户交互的模块。然后,DST将先前提取出的所有意图和槽位作为一个内部对话状态来呈现。接着,DPL模块根据输入的状态采取行动,来满足用户需求。最后,NLG模块将行动转变为自然语言形式并输出。在管道途径中,DPL是联系DST模块和NLG模块的中间纽带,直接关系到对话系统的成败,故相当重要。
当前,强化学习(RL)算法的发展极大推动了DPL研究的发展。列文等人(Levin et al.)是第一个把DPL当作马尔可夫决策过程(MDP)问题处理的团队。他们列出了将DPL建模为一个MDP问题的复杂度,并证明了将RL算法用于优化对话策略的合理性。此后,大部分研究都开始研究将RL算法实际应用于对话系统时出现的技术问题,并提出解决方案。同时,还有一批研究者则在试图将监督学习(SL)技巧运用在DPL。他们的主要想法就是将对话策略学习当作一个多级分类问题,将行动和状态反应分别当作标签和输入来处理。但是,SL技术有一个臭名昭著并且代价高昂的缺陷,那就是它并不考虑当前决定对于未来的影响,故所作决定多为次优。
深度学习领域的突破,使得把神经网络同RL结合起来的深度强化学习(DRL)方法让很多顺序决策问题的学习策略获得成功。其中包括像雅达利开发的游戏、围棋游戏Go以及多种多样的机器人任务等模拟环境。因此,DRL在单域对话领域受到了许多关注,并取得了可喜成果。神经模型可以提取高水平对话状态和解码复杂较长的语句。这是早期的所面临的最大挑战。随着对DPL的研究兴趣逐渐转移到更复杂的多域数据集,许多RL算法开始面临可扩展性问题。
当前,已有不少关注如何让RL个体在多域对话场景中更适应以及表现更好的研究。但几乎没有对过往大量有关将强化学习(RL)应用于TOD系统中的DPL的文献综述。格拉斯尔(Grassl)研究过RL在四种对话系统中的使用情况,即社交聊天机器人(chatbots)、信息机器人(infobots)、任务型对话机器人和个人助理机器人。但是,其对于将RL应用于TOD系统的过程和挑战并未充分讨论。类似地,戴氏(Dai et al.)等人虽对对话管理的进展和挑战进行了综述,但由于其研究兴趣的涵盖面广,故其中涉及到有关DPL中RL方法的讨论相当有限。而且,RL对话系统在五个核心的RL要素,即环境、策略、状态、行动和奖励方面通常有不同的设置。以往研究并没有考虑到不同系统的不连续设置,因而对这些系统之间进行的比较并不公平。