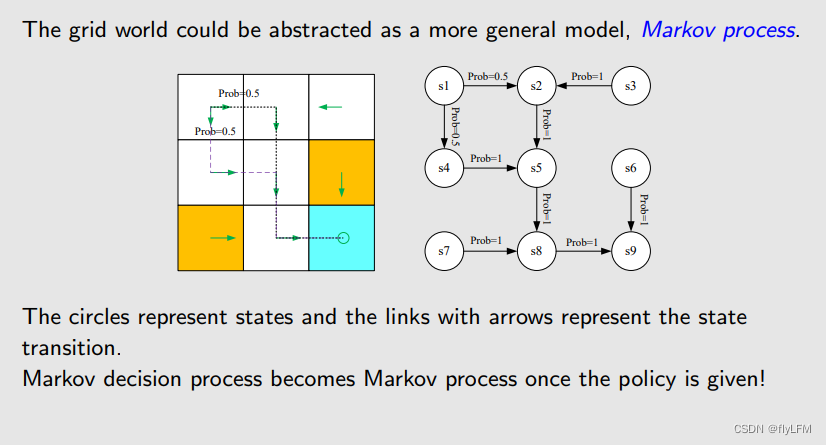
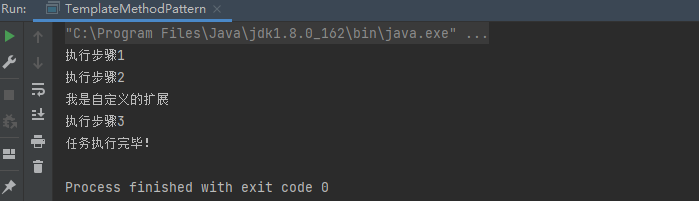
强化学习基础概念及MDP算法,如图1所示

这张ppt上就展现了一节课全部的内容:
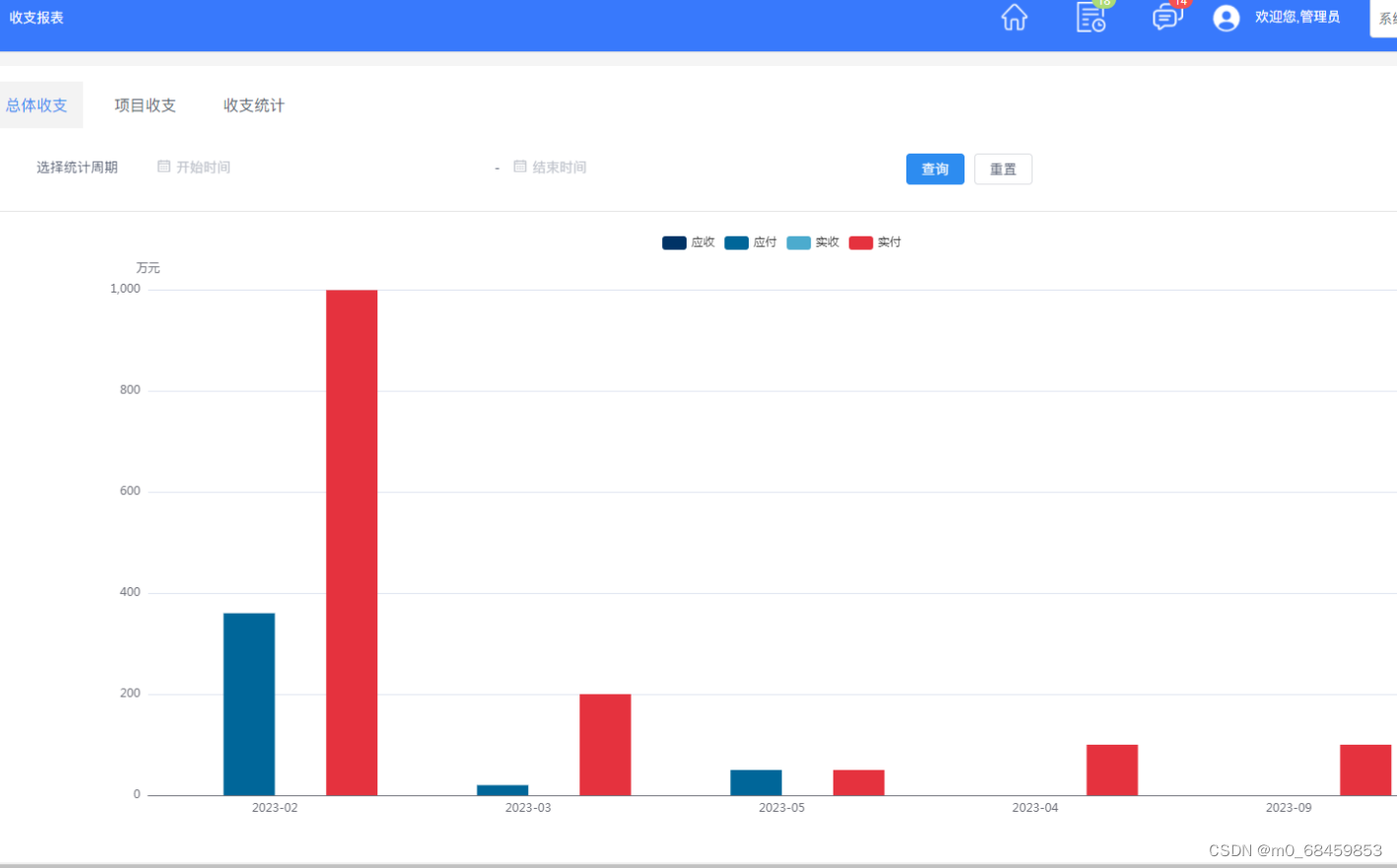
Sets中有表示状态的S、有表示动作的A(s)、有表示奖励的R(s,a),如图二所示

也介绍了概率分布(Probability distribution)
其中State transition probability为p(s’∣s,a)
Reward probability为p(r∣s,a)
还有策略(Policy)
最重要的马尔科夫决策就是下一步的状态只受当前状态的影响,不受先前状态的影响,其实是因为当前状态所展现的东西,就是先前状态的影响不断累计的产物,以此形成了马尔科夫链。如图三所示