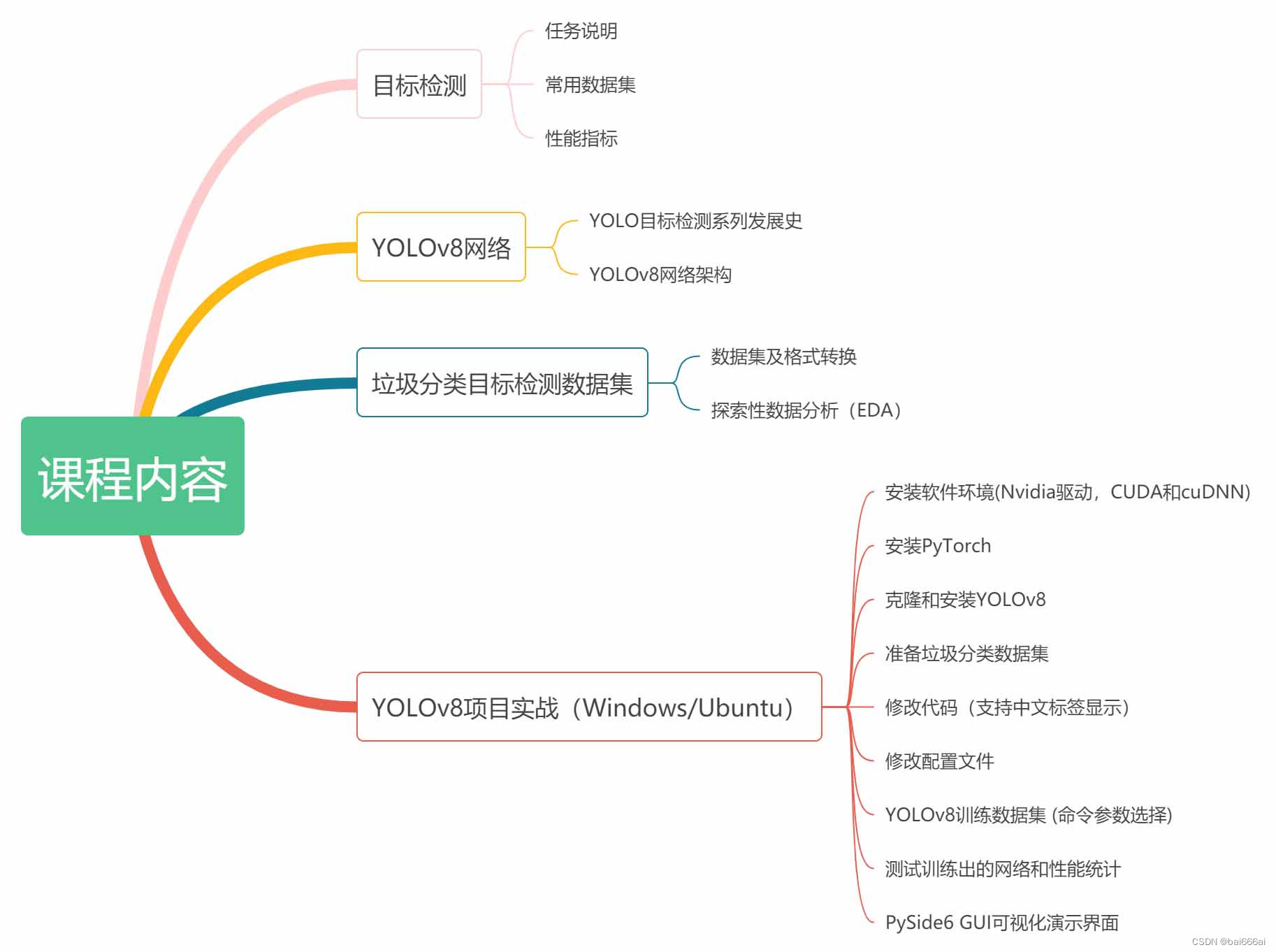
一、处理用户在浏览器地址栏中输入的URL(统一资源定位符)
用户在地址栏输入内容并按下回车,浏览器会检查输入是否符合 URL 规则,以Chrome为例,它会根据相应的规则,将地址栏输入解析成搜索请求或者URI请求。如果是搜索,解析处搜索关键字,然后与搜索引擎地址组装成一个URI请求;否则,浏览器就会将地址与相关协议HTTP,HTTPs等,组装成一个完整的URI请求;如果已有打开的页面,unload当前页面。解析地址栏输入。回车前,当前页面执行 onbeforeunload 事件; 浏览器进入加载状态。
二、浏览器进程接收到URL,并将其发送到网络进程。
在触发DNS Lookup 之前(DNS(Domain Name System)是域名系统, 可将域名解析成对应的IP地址,从而用户可以通过域名在英特网上访问特定Web 服务器提供的在线信息或服务。),浏览器会首先确认缓存中是否存在域名的IP地址。浏览器会依次检查浏览器缓存,操作系统缓存,路由缓存和ISP DNS缓存,如果在缓存中找到了域名的IP地址,那么就可以直接使用改IP地址发起网络请求;反之,DNS Lookup就会发生。需要指出的是:并非URI不同,域名就不同,事实上不同的URI可以有相同的域名,也就是所谓相同的源,这个可以参考Web请求的header的origin字段。缓存中不光会有关于域名的信息,也包括网址重定向信息和离线网页信息等。如果缓存中有网址重定向信息,那么就会向重定向的网址发出请求;如果缓存中有离线网页信息,那么会直接打开离线网页。

永久重定向(状态码301),即原域名已经永久修改成新域名,浏览器会缓存永久重定向的DNS解析记录。
临时重定向(状态码302),浏览器不会缓存当前域名的解析记录。
当IP地址被确认后,浏览器会根据这个IP,通过TCP三次握手(TCP three-way handshake)的方式,和服务器建立连接。所谓TCP三次握手:
第一次: 浏览器发送一个TCP 同步包(SYNchronize package)给服务器,等待确认。
第二次: 服务器收到SYN包,并返回一个同步确认包(SYNchronize-ACKnowledgement package)。
第三次: 浏览器收到服务器的SYN-ACK,向服务器发送一个确认包(ACKnowledgement package)。当服务器收到ACK后,TCP的socket连接就建立了。
如果要建立基于HTTPS的安全连接,那么TLS协商(TLS Negotiation)就会发生。浏览器和服务器需要更多次的握手。在TCP连接建立后,浏览器就会向相应的HTTP(S)服务器发送请求。
三、浏览器接受,解析Response数据并渲染
浏览器接受到response数据后,就会开始解析,一个网页可能需要多个HTTP请求,比如,主体的HTML文件是一个请求,而其相关的CSS,图片和JS文件等也需要一一请求。浏览器并不会等待所有的数据接收完成才开始解析,而只保证所有的数据最终都会被解析,且默认一个页面一个进程;从a打开b,并且是同一站点(相同的协议和根域名),会复用渲染进程。最后,渲染进程将布局和绘制的信息发送给浏览器进程,浏览器进程将其显示在用户界面上,呈现为最终的页面。
这只是一个简化的浏览器工作流程,实际中会有更多细节和优化。此外,现代浏览器通常采用多进程架构,如Chrome就分别有浏览器进程、渲染进程、网络进程等,这些进程间还会进行通信和协作来提高性能和安全性。
关于渲染的整个过程大概可描述为:
解析HTML标记符号,开始生成DOM树;解析CSS标记符号,开始生成CSSOM树;CSSOM树生成后,JS引擎会解析JS脚本,完成DOM树的创建;合并DOM树和CSSOM树,生成渲染树
基于渲染树和当前浏览器面板,计算页面元素的大小和相对位置,将渲染树里的每个节点,结合Layout的计算结果,渲染引擎将渲染树转换成屏幕上实际的像素,即绘制内容。
【 DOM是Document Object Model的缩写,即文档对象模型。是W3C推荐的一种处理可扩展标志语言的一种标准编程接口。浏览器将机构化的文档HTML/XML读入,将文档中的每个标签建模成一个节点(Node),每个节点有各自的属性(名称,类型,内容等等),节点之间有层级关系(父亲,孩子,兄弟等),从而形成了树形结构。DOM提供的编程接口,支持访问,修改,添加和删除DOM树的节点和内容。
CSSOM树: 类此与DOM树,浏览器会便利CSS文件中所有的规则,创建一棵树,这棵树包含多个节点,基本CSS选择器,这些节点之间也有着层级关系,比如父亲,孩子,兄弟等等
Render树: 将DOM树和CSSOM合并后,就形成了Render树。
Layout: 当渲染树生成后,就会开始layout。Layout负责计算渲染树的每个节点在屏幕上的位置和维度。比如,不同的设备上的浏览器的宽度可能不同,那么,基本屏幕宽度的显示,Layout会得出不同的实际显示宽度。】
二、现在浏览器为什么大多都是多进程,多进程之后这个过程又有什么变化?
现代浏览器普遍采用多进程架构的主要原因是为了提高性能、安全性和稳定性。
-
性能提升:多进程可以充分利用多核处理器的优势,将不同的任务分配给不同的进程并行处理。例如,渲染进程可以独立于浏览器进程运行,可以更快地响应用户操作,使页面加载更快,提升用户体验。
-
安全性增强:多进程架构通过进程隔离实现了沙盒机制,每个进程都运行在独立的环境中,互相之间无法访问对方的内存,从而有效地隔离恶意网站或插件对系统的攻击。即使一个进程崩溃或受到攻击,其他进程仍然可以正常工作,增加了整体系统的稳定性和安全性。
-
故障隔离:多进程架构降低了单一进程故障对整个浏览器的影响范围。如果一个标签页或插件崩溃,只会影响到相应的渲染进程或插件进程,而不会导致整个浏览器崩溃。
-
资源管理:多进程可以更好地管理系统资源,每个进程都有自己的内存空间和资源限制。这样可以避免某个页面或插件占用过多的内存导致浏览器整体性能下降。
在多进程架构下,从输入URL到页面显示的基本流程与单进程模型相似,但具体实现上会有一些变化:
- 浏览器进程负责接收用户输入,并将请求发送给适当的子进程(如渲染进程、网络进程、插件进程等)。
- 渲染进程负责解析HTML、构建DOM和CSSOM、进行布局和绘制,然后将渲染结果发送给浏览器进程进行显示。
- 网络进程负责处理网络请求和响应,但实际数据的传输可能会由操作系统的网络栈处理。
- 插件进程负责加载和运行浏览器插件,独立于其他进程运行。
通过多进程架构,浏览器可以更高效地处理复杂的网页和多个任务,并提供更好的安全性和稳定性。
![已解决 BrokenPipeError: [Errno 32] Broken pipe](https://img-blog.csdnimg.cn/5c362be60c6c42fbb7bec33aa09ecb1e.png)