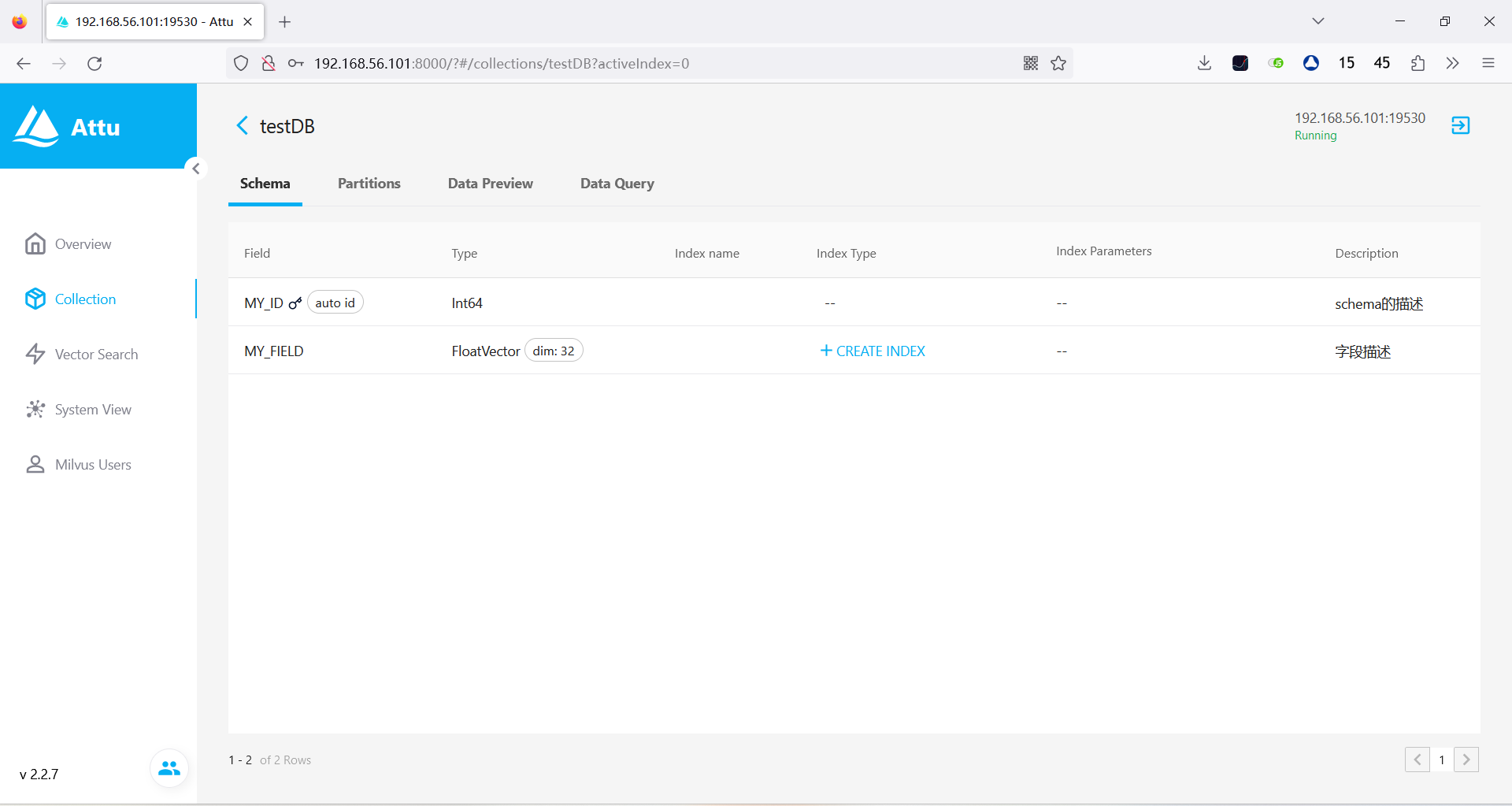
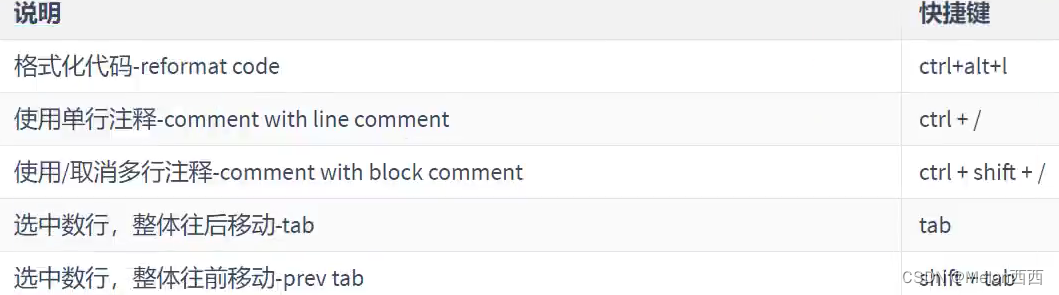
概述
在先说链表前,我们先来理清几个概念。
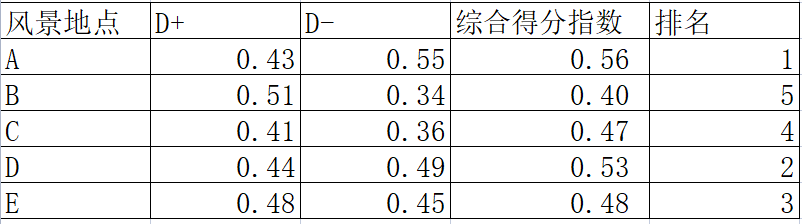
什么是线性表、顺序表和链表?三者有什么关系?
线性表:元素线性排列,在逻辑上具有次序的存储结构。
顺序表:线性表的顺序存储称为线性表。它是用一组地址连续(逻辑上连续、物理上也连续)的存储单元依次存储线性表中的数据元素。比如,数组。
链表:线性表的链式存储称为线性表。由一组任意的存储单元来存储线性表中的数据元素。存储单元只是在逻辑上连续,在物理地址上可以不连续。
三者关系:顺序表和链表都是线性表,顺序表和链表的存储结构不同。
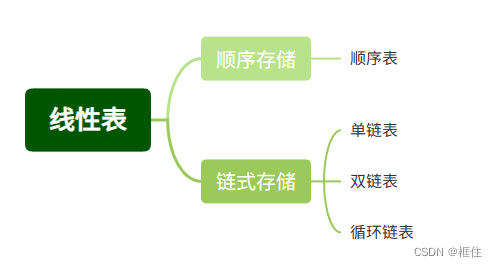
什么是逻辑上连续?什么又是物理上连续?
我们都知道,程序使用的数据都存放在一块存储空间中。为了便于在存储空间中查找我们存储的数据,我们会给这段存储空间进行地址编号,类似家庭住址。
物理上连续:存储地址编号相邻。这样地址不同地址,就能顺序访问所有元素。
逻辑上连续:不要求存储地址编号相邻,但要求根据前一个数据地址,能找到下一个逻辑连续的数据地址。
举个例子:
现在我们要存储A,B,C,D 。要求,依次访问A,B,C,D。
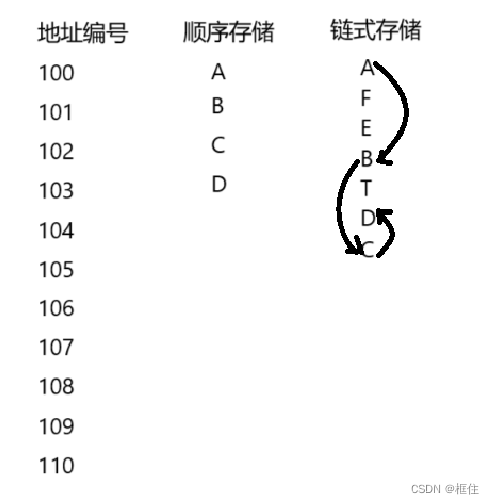
对于顺序存储,我们将A存放在地址为100的位置,那么B,C,D的地址就确定下来了,依次是101,102,103。这样依次访问A,B, C, D就是从编号为100的位置依次取出四个数据。
对于链式存储,我们也把A存放在地址为100的位置,由于A,B,C,D只要求逻辑上连续,不要求物理地址连续。所以我们并不能由A的地址,推出B,C,D的地址。但我们会将A,B,C,D链接起来,这样也可以实现访问A后依次访问B,C,D。
顺序表
数组是一种常用的顺序表。
你还我们当初为什么会引出数组吗?数组的提出是为了解决什么问题》
简单的说,数组可以存储大量的、相同数据类型的数组。比如,我需要记录一个10个整数的值,我们就可以创建一个大小为10的整型数组 a [ 10 ] a[10] a[10], 这个十个整型依次就是 a [ 0 ] , a [ 1 ] , a [ 2 ] . . . , a [ 9 ] a[0],a[1],a[2]...,a[9] a[0],a[1],a[2]...,a[9] 。
数组支持随机访问,给出元素的下标i,直接通过a[i]就可访问元素,无需从第一个元素依次遍历,直至第 i 个元素。
单链表
介绍一个我们最场使用的链表,就是单链表。
什么是单链表?单链表被提出是为了解决什么问题的?它有什么特点?
首先,我们先来看看顺序表有什么不足吧?
(1)数组大小固定。创建数组的时候,创建数组时必须给出数组的大小。
- 现在有这么个需求,让你从读入用户输入的数字,用户输入的数字的个数在
1
−
1000
1-1000
1−1000 之间。为了使数组够用,我们得就会这样创建数组
int a[1000];但你发现,大多数用户,只输了10多个数字,只有个别用户会输入1000个数字,很多时候数组都设置大了,导致有很多设置的空间都没用上,浪费了空间。如何解决?
(2)插入、删除数据复杂。每次在数组中插入或者删除数据,都要不停的移动数据,来移出或填补空位,太浪费时间了,如何解决?
你可能已经猜到了,单链表能很好得解决上面的问题。接下来,然我们来见识见识它。
什么是单链表?
还是那个问题,读入用户的输入的数字,用户输入数字的个数在1-1000之间。
我们可以这样读,每次读入一个整数,用int 型的数据变量存储。但这样就有大量的变量,如何保证这些变量的次序关系呢?
能不能用一个链条把这些变量链接起来呢,串成一个表。每次有新的输入,我们就设置个变量读入,然后加入这个表中。

如何将这些数据链接起来呢?想一想哪个让我们很费解的,大名鼎鼎的“指针”,它就可以。
指针,存放数据地址的一种数据。可看成,指向了数据。

如果想到这,那说明你已经懂了单链表70%的内容了。
单链表,就是由一个个链表结点链接而成的数据结构。
结点由两部分组成,存放数据的数据域,和用来链接表的指针域。
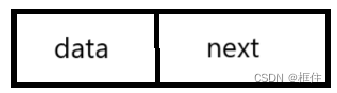
结点类型的描述如下:
// 链表结点
struct LNode{
DataType data; // 存放数据
struct LNode *next; // 指向下一个链表结点
};
对于任意一个非空结点node,我们知道它存放的数据为node.data或node->data ,它的下一个结点为nextnode = node.next或nextnode = node->next。
对于ABCD存放结构图如下:

查找C,得先依次访问A、B
单链表的特点
每个结点只能访问到它的下一个结点,所以结点只能一个接一个依次访问,不支持随机访问,单链表的查找速度变慢了。
每次插入数据,只需创建一个新结点,然后调节结点的next指针,就实现了插入。
比如,在BC间插入个E。

特殊的,对于链表的尾结点(最后一个结点),指针的指向?
链表尾结点的next指针指向空(NULL)。
这样,当遍历到的结点的next指针为空时,我们就知道此时已经遍历到链表的尾结点了,即链表已经遍历完了。
上面我们提到了尾结点,你可能会提出那有没有首结点呢?
有,我们一般称为头结点。
上面的A结点是不是就是头结点呢?
一般,我们认为头结点是不存放数据,所以A我们不认为是头结点。那头结点有什么用?
可以存放链表的长度,即链表的结点个数。当然,也可以什么元素都不存。但头结点,一定有个指针指向链表中第一个存放数据的结点。
添加头结点后的链表。

对于一个链表,头结点为head。如果head->next == NULL 说明链表为空链表。因为该链表没有存放数据的结点。
其实,头结点还有很多好处,他会让很多的操作统一,减小很多特殊判断。不展开说了。如果你发现链表操作需要很多特判,想想是否可以加一个头结点。
顺序表和链表的比较
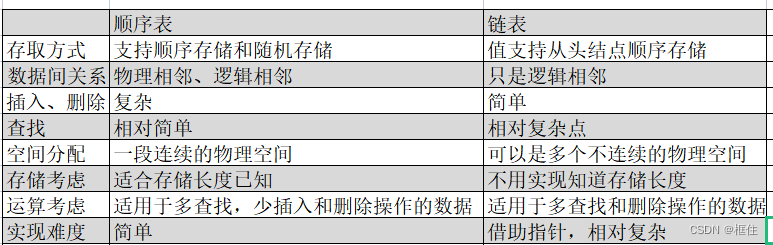
总结
这里具体的单链表的插入、删除、查找操作都没讲。其实,如果能理解单链表这个结构,对于这些基本操作还是很简单的。
单链表是一种常用的一种基本数据结构,重点就是理清楚结点指针。
双链表、循环链表和循环双链表这里没提,其实先搞懂单链表,之后的其他特殊链表都很好理解。