1、怎么使用预训练网络?
使用预训练网络有两种方法:特征提取(feature extraction)和微调模型(fine-tuning)。
1、特征提取
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征。然后将这些特征输入一个新的分类器,从头开始训练。
用于图像分类的卷积神经网络包含两部分:首先是一系列池化层和卷积层,最后是一个密集连接分类器。第一部分叫作模型的卷积(convolutional base)。对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,在上面运行新数据,然后在输出上面训练一个新的分类器。如图一所示:卷积基不变,改变分类器
为什么只使用预训练模型的卷积基?
原因在于卷积基学到的表示可能更加通用,因此更适合重复使用。分类器学到的表示必然是针对于模型训练的类别,其中仅包含某个类别出现在整张图像中的概率信息,因此预训练模型密集连接层的特征在很大程度上是无用的。
如何进行特征提取(两种方法实现)
1、在你的数据集上运行卷积基,将输出保存成硬盘中的 Numpy 数组,然后用这个数据作为输入,输入到独立的密集连接分类器中(与本书第一部分介绍的分类器类似)。
优点:速度快,计算代价低,因为对于每个输入图像只需运行一次卷积基。
缺点:不允许你使用数据增强。
2、在顶部添加 Dense 层来扩展已有模型(即 conv_base),并在输入数据上端到端地运行整个模型。
优点:可以使用数据增强。
缺点:计算代价高,因为每个输入图像进入模型时都会经过卷积基。
注意:第二种方法要“冻结”卷积基,冻结(freeze)一个或多个层是指在训练过程中保持其权重不变。如果不这么做,那么卷积基之前学到的表示将会在训练过程中被修改。因为其上添加的 Dense 层是随机初始化的,所以非常大的权重更新将会在网络中传播,对之前学到的表示造成很大破坏。
2、微调模型
模型微调(fine-tuning)与特征提取互为补充。对于用于特征提取的冻结的模型基,微调是指将其顶部的几层“解冻”,并将这解冻的几层和新增加的部联合训练。之所以叫作微调,是因为它只是略微调整了所复用模型中更加抽象的表示,以便让这些表示与手头的问题更加相关。
只有上面的分类器已经训练好了,才能微调卷积基的顶部几层。如果分类器没有训练好,那么训练期间通过网络传播的误差信号会特别大,微调的几层之前学到的表示都会被破坏。因此,微调网络的步骤如下。
(1) 在已经训练好的基网络(base network)上添加自定义网络。
(2) 冻结基网络。
(3) 训练所添加的部分。
(4) 解冻基网络的一些层。
(5) 联合训练解冻的这些层和添加的部分。
为什么不微调更多层?为什么不微调整个卷积基?
(1)卷积基中更靠底部的层编码的是更加通用的可复用特征,而更靠顶部的层编码的是更专业化的特征。微调这些更专业化的特征更加有用,因为它们需要在你的新问题上改变用途。微调更靠底部的层,得到的回报会更少。
(2)训练的参数越多,过拟合的风险越大。卷积基有 1500 万个参数,所以在你的小型数据集上训练这么多参数是有风险的。
来自博客:采用预训练模型来训练新的模型_胜寒君的博客-CSDN博客
2、预训练会提高模型的鲁棒性和不确定性
来自文章:Using Pre-Training Can Improve Model Robustness and Uncertainty
链接:https://arxiv.org/pdf/1901.09960.pdf
《Rethinking ImageNet pre-training》这篇论文指出从头开始(train from scratch)的预训练经常产生和引入预训练模型一样的效果。我们展示尽管预训练可能不会提高传统分类测度上的表现,但是它能够提高模型的鲁棒性和不确定性估计。通过adversarial examples, label corruption, class imbalance, out-of-distribution detection, and confidence calibration 一系列实验,我们证明了预训练的作用和任务特殊方法的补偿影响。
3、How transferable are features in deep neural networks?
《How transferable are features in deep neural networks?》
模型的第一层参数和Gabor filters的参数非常相似,即模型在一开始也要完成一些常规模型的的图像检测过程,第一层(或前几层)的特征并不是特定于某一数据集或某一任务,而是通用特征,他们适用于许多数据集和普遍任务,在较深的(最后几层)模型层,特征会从通用特征逐渐转化为与任务和数据集紧密相关的特征。
1.背景和动机
本文全篇通过实验说明神经网络的可迁移性,通篇没有一个公式,但是却是2014年NIPS的oral presentation。
本文实验使用12年ImageNet大赛的冠军模型AlexNet进行了一系列关于网络各个层级上的可迁移性的实验。因为CNN在提取特征时,前面几层学习到的都是边边角角,线条这样的可以泛化的特征,而随着层级上升,慢慢地特征变得specific。那么问题来了,当我们打算迁移这些层次的时候,怎么知道哪些层可以不动,哪些层是specific的呢?
这个问题对于理解神经网络以及迁移学习很有意义,也是此论文的研究点。下面来看看
2.简介
本文通过实验说明结果,在ImageNet的1000个类中,作者将其分成2份(A与B),每份包含500个类,这里是随机分的。然后分别针对A和B份,分别训练一个AlexNet网络。关于AlexNet的结构就不多说了,一共8层,前面5层是卷积层,后面3层是FC层。作者分别对n=1~7进行了实验,
举个例子:比如n=3,那么AnB就是说在一个新的AlexNet上,前三层采用A网络的前三层并且将其frozen,后5层随机初始化,然后在B数据上去训练。
那么BnB就是用B网络的前三层frozen,剩下的5层初始化,然后在B上实验。
而AnB+是指使用A网络的前三层,后5层随机初始化,但是不做frozen,整个网络拿来做BP训练。
围绕着神经网络的可迁移性,作者设计了两大方面的实验:
迁移A网络的某n层到B(AnB) vs 固定B网络的某n层(BnB)
权重初始化与迁移表现
3.实验结果
我们来分析下结果:先看蓝色的BnB和BnB+
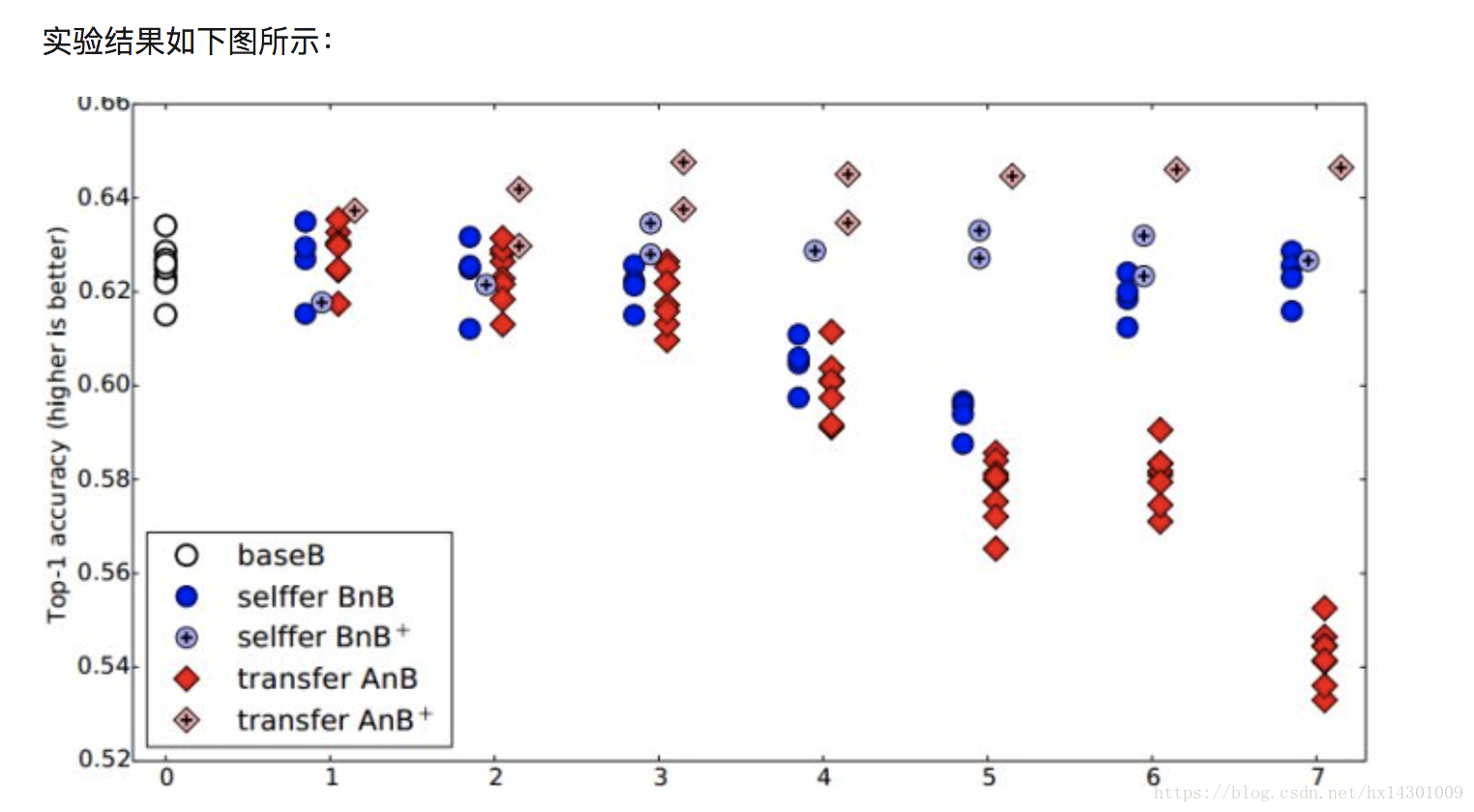
对于BnB而言,原来训练好的B模型的前两层直接拿来就可以用,而且不需要调整,不会对精度造成影响。从3层开始有点下降,到了第4~5层,模型精度开始下降,然而到了6-7层,模型精度又奇迹般地回升了!这是为什么呢?
作者说明如下:对于一开始精度下降的4~5层,确实是到了这一步,feature变得specific了,但是都是从B数据训练来的,就算4~5层的特征specific,那不也是数据B的特征吗?为什么会下降呢?作者认为:中间连续层之间存在一定的相互适应调整关系,这种关系是复杂而又脆弱的,这种关系不能够仅仅通过上层学习到,所以在3层开始,我们固定底层,导致网络无法进行上下之间的相互适应调整,使得3层之后的层无法进行很好地协调而学习到相对于task很specific的特征,使得精度开始下降。而到了6~7层,精度又回升了,这是因为网络一共就8层,你把6层都固定住了,基本上整个特征学习也被固定住了,因此精度和原来的B不会相差太多。因此作者认为:神经网络中间特征层的连续协调关系要强于最顶和最下层的,这是之前文献所没有注意到的。
对于BnB+来说,模型精度没有什么变化,说明finetune对模型没有损失,并且训练时间还可减少,对训练有促进作用。
我们重点看下AnB和AnB+
对AnB来说,直接将网络的前两层迁移到B,固定住,貌似对精度不会有什么影响,这说明AlexNet的前两层学习的特征是很基础,很泛化的,因此可以直接从A迁移到B而不损失精度。到了4~5层,精度开始大幅下降,而到了6~7层,精度出现小小上升然后又下降,这是为什么呢?根据BnB的结论,我们认为这种下降由两个因素导致:
中间层之间具有相互适应协调的依赖关系
特征太specific了,导致迁移到B上特征不适用
而在4~5层,是第一个因素占主导作用,使得模型在固定了前面4~5层后,之后的层无法学习进行上下层的相互协调,无法学习到针对B数据很specific的特征。而在6~7层,则是第二个因素起作用,此时整个网络差不多都被固定住了,模型提取的特征就和A差不多,自然无法在B上适用。因此中间出现一个过渡,然后又下降的情况。
再看AnB+,加入了finetune之后的模型,在任何时候表现都很好,甚至比base B的表现还好,这又一次说明finetune对模型有很好的促进作用!
4.结论
虽然该论文并没有提出一个创新方法,但是通过实验得到了以下几个结论,对以后的深度学习和深度迁移学习都有着非常高的指导意义(杨强教授非常赞赏该论文的工作):
- 神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
- 深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好;
- Fine-tune可以比较好地克服数据之间的差异性;
- 深度迁移网络要比随机初始化权重效果好;
- 网络层数的迁移可以加速网络的学习和优化。
文章来源:https://blog.csdn.net/hx14301009/article/details/82713371
4、DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
本篇文章提出问题:2012年Alexnet的出现使用CNN进行特征提取在多个视觉上取得了很好的效果,那么利用CNN提取的特征是否可以应用到其他数据集上,另外CNN的性能随着网络的深度如何变化?能否定量或定性地说明这两个问题?
为了验证特征泛化能力,使用起始层到中间的某层的网络作为特征提取,使用t-sne算法进行了可视化,可视化结果如下:

5、Big Transfer (BiT):General Visual Representation Learning
Key points:预训练+微调模式;上游预训练;下游迁移;更通用的视觉表征学习;BiT-HyperRule
对于预训练+微调模式的迁移学习来说,更有效的结果分为两种:1、在某一类下游任务中取得优秀的性能。2、能够完成尽可能多的下游任务,且都能够取得较为良好的成绩。
对于BiT来说,属于第二个,在近20个数据集上完成较好的结果,并且最关键的是,BiT在迁移的过程使用的是固定(相同)的处理方法,从而更能说明其具有较好的普适性。
没有太看懂