普通索引
B+树的叶子节点上记录的是聚簇索引(主键索引)的值。

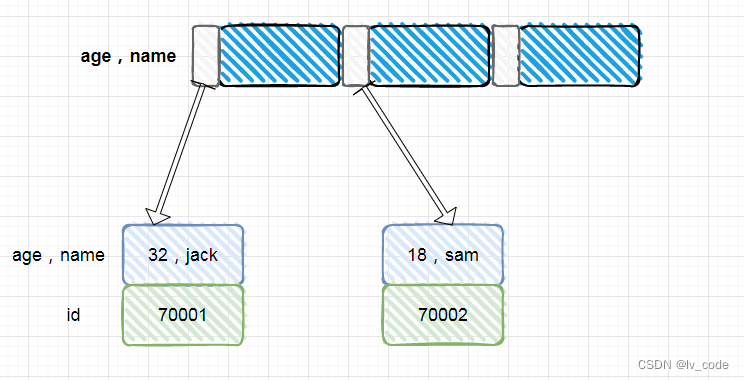
联合索引
叶子节点中记录的是name,age两个字段以及主键id的值。
MySQL一定是遵循最左前缀匹配的,这句话在mysql8以前是正确的,没有任何毛病。但是在MySQL 8.0中,就不一定了。
索引跳跃扫描(Index Skip Scan)
官网示例
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL, PRIMARY KEY(f1, f2));
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;
ANALYZE TABLE t1;
EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40;
原文
A range scan is more efficient than a full index scan, but cannot be used in this case because there is no condition on f1, the first index column. However, as of MySQL 8.0.13, the optimizer can perform multiple range scans, one for each value of f1, using a method called Skip Scan that is similar to Loose Index Scan
mysql5.6 explain结果
> select version()
version() |
----------+
5.6.40-log|
1 row(s) fetched.
> EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40
id|select_type|table|type |possible_keys|key |key_len|ref|rows|Extra |
--+-----------+-----+-----+-------------+-------+-------+---+----+------------------------+
1|SIMPLE |t1 |index| |PRIMARY|8 | | 160|Using where; Using index|
1 row(s) fetched.
mysql8 explain
> select VERSION()
VERSION()|
---------+
8.0.29 |
1 row(s) fetched.
> EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 > 40
id|select_type|table|partitions|type |possible_keys|key |key_len|ref|rows|filtered|Extra |
--+-----------+-----+----------+-----+-------------+-------+-------+---+----+--------+--------------------------------------+
1|SIMPLE |t1 | |range|PRIMARY |PRIMARY|8 | | 53| 100.0|Using where; Using index for skip scan|
1 row(s) fetched.
这里面的type指的是扫描方式,range表示的是范围扫描,index表示的是索引树扫描,通常情况下,range要比index快得多。
从rows上也能看得出来,使用index的扫描方式共扫描了160行,而使用range的扫描方式只扫描了16行。
MySQL 8.0中的扫描方式可以更快,主要是因为Using index for skip scan 表示他用到了索引跳跃扫描的技术。
也就是说,虽然我们的SQL中,没有遵循最左前缀原则,只使用了f2作为查询条件,但是经过MySQL 8.0的优化以后,还是通过索引跳跃扫描的方式用到了索引了。
索引跳跃扫描优化原理
mysql8.013后通过优化器帮我们加了联合索引,如下
SELECT f1, f2 FROM t1 WHERE f2 = 40;
执行的最终SQL:
SELECT f1, f2 FROM t1 WHERE f1 =1 and f2 = 40
UNION
SELECT f1, f2 FROM t1 WHERE f1 =2 and f2 = 40;
所以对于对于f1值很少,区分度不高的情况索引跳跃扫描会快一些;
反之查询效率慢些。
故,
我们不能依赖他这个优化,建立索引的时候,还是优先把区分度高的,查询频繁的字段放到联合索引的左边。
参考
https://dev.mysql.com/doc/refman/8.0/en/range-optimization.html#range-access-skip-scan