Transformer模型
https://blog.csdn.net/m0_67084346/article/details/128138486
https://blog.csdn.net/benzhujie1245com/article/details/117173090
2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。
• 功能亮点:
(1)编码器-解码器架构(Encoder-Decoder Architecture)
(2)多头自注意力机制(Multi-head Self Attention)
(3)位置编码(Positional EnCoding)
(4)残差结构(Residuals)
\qquad
使得模型能够保留更多原始输入的信息,同时有效地缓解梯度消失问题
(5)层归一化(Layer Normalization)
\qquad
加速网络的训练和收敛
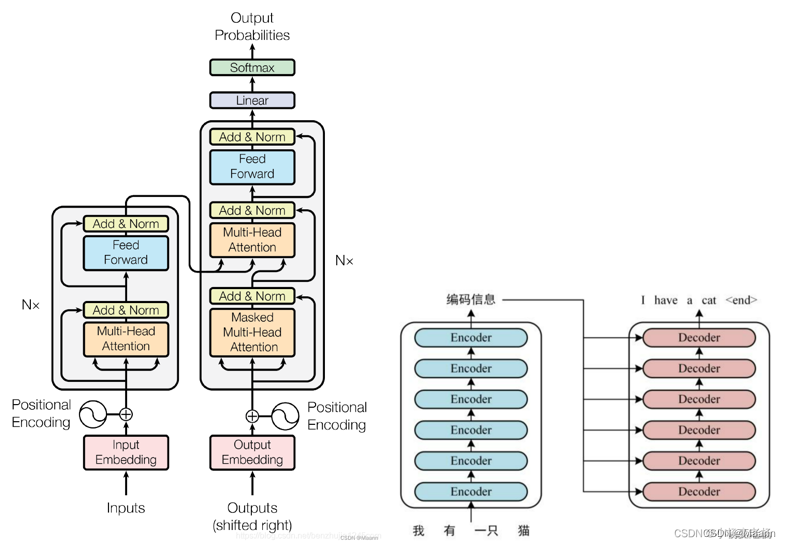
Transformer: 编码器组件和解码器组件中分别为连续 N(在 Transformer模型中 N = 6)个具有相同结构的编码器和解码器,每个编码器的结构都是相同的,但是它们使用不同的权重参数。
编码器:多头的self-Attention + 标准化残差 + 前馈神经网络 +标准化残差
解码器:多头遮蔽的self-Attention + 标准化残差 + 多头的全局的Attention(编码-解码/交叉注意力) + 标准化残差 + 前馈神经网络 + 标准化残差
encoder-decoder Attention就是一个普通的Attention是判断编码的输出语义向量C和当前翻译的一个Attention关系的。因此解码器相比较编码器来说仅仅多了一个mask和encoder-decoder Attention。
编码阶段都是为了得到一个语义向量C
解码阶段都是通过语义向量C得到一个一个的输出
(1)第一层的self—attention作用:对自己本身加权(提取自身信息)
\qquad 多头机制作用:为了提取更多更全的信息
(2)为什么transformer当中要加入位置嵌入?
\qquad LSTM时间步潜在就是位置的信息,但是transformer当中是把整句话一块作为输入, 那么就丧失了词与词之间的位置信息。
(3)如何做位置嵌入?
\qquad 1) 位置信息能在某个小范围里,例如(0,1) (-1,1)
\qquad @为什么要在小范围:
\qquad \qquad 可以反映出位置之间的关系
\qquad 2) 能表示出来位置之间的关系
\qquad sin-cos函数可以满足上边两点
\qquad 和差化积公式
\qquad 奇数用cos编码,偶数用sin编码
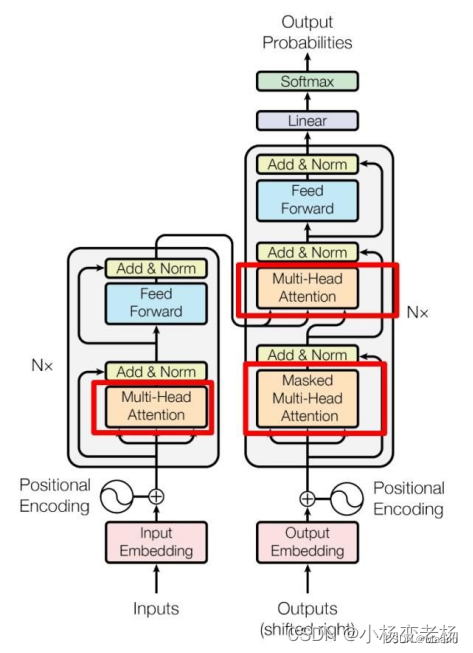
红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
1. 自注意力(Self-Attention )
目的:对自己本身加权(提取自身信息),让机器注意到整个输入中不同部分之间的相似性
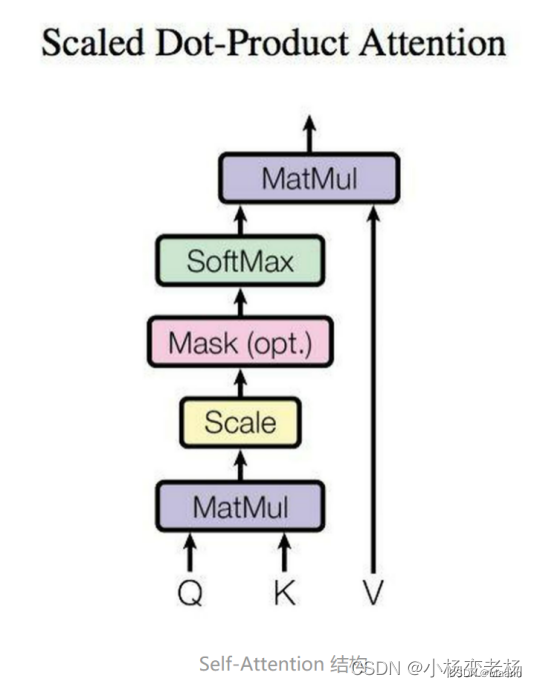
给定一个Query(查询)和一系列的Key-Value对一起映射出一个输出。包括下面三个关键性步骤:
\quad
• 将Query与Key进行相似性度量
\quad
• 将求得的相似性度量进行缩放标准化
\quad
• 将权重与value进行加权
在计算的时候需要用到矩阵Q(Query查询),K(Key键值),V(Value值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V
Attention(Q,K,V)=softmax(dkQKT)V
具体步骤:
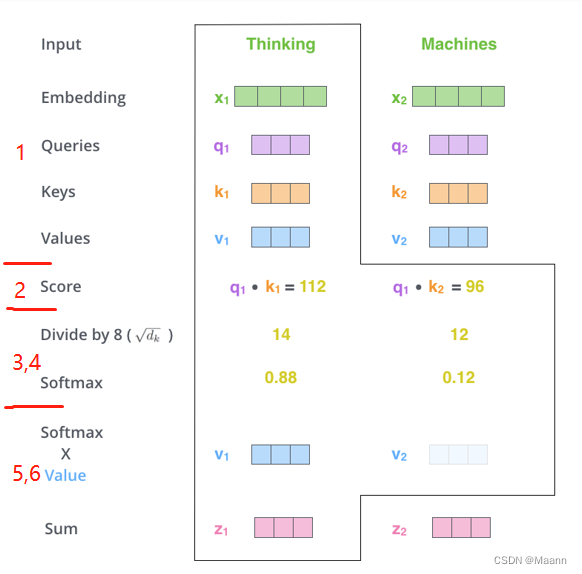
第 1 步:对编码器的每个输入向量(在本例中,即每个词的词向量)创建三个向量:Query 向量、Key 向量和 Value 向量。它们是通过词向量分别和 3 个矩阵相乘得到的,这 3 个矩阵通过训练获得。
\qquad
请注意,这些向量的维数小于词向量的维数。新向量的维数为 64,而 embedding 和编码器输入/输出向量的维数为 512。新向量不一定非要更小,这是为了使多头注意力计算保持一致的结构性选择。
第 2 步:计算注意力分数。假设我们正在计算这个例子中第一个词 “Thinking” 的自注意力。我们需要根据 “Thinking” 这个词,对句子中的每个词都计算一个分数。
\qquad
这些分数决定了我们在编码 “Thinking” 这个词时,需要对句子中其他位置的每个词放置多少的注意力。这些分数,是通过计算 “Thinking” 的 Query 向量和需要评分的词的 Key 向量的点积得到的。如果我们计算句子中第一个位置词的注意力分数,则第一个分数是
q
1
q_1
q1和
k
1
k_1
k1的点积,第二个分数是
q
1
q_1
q1和
k
2
k_2
k2的点积。
第 3 步:将每个分数除以 d k \sqrt{d_{k}} dk( d k d_{k} dk是 Key 向量的维度)。目的是在反向传播时,求梯度更加稳定。实际上,你也可以除以其他数。
第 4 步:将这些分数进行 Softmax 操作。Softmax 将分数进行归一化处理,使得它们都为正数并且和为 1。
\qquad
这些 Softmax 分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力。很明显,当前位置的词汇有最高的分数,但有时注意一下与当前位置的词相关的词是很有用的。
第 5 步:将每个 Softmax 分数分别与每个 Value 向量相乘。这种做法背后的直觉理解是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放在它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大,我们就可以忽略这些位置的词。
第 6 步:将加权 Value 向量(即上一步求得的向量)求和。这样就得到了自注意力层在这个位置的输出。
2. 多头自注意力(Multi-head Self Attention)
目的:让词向量学习到上下文语境信息(为了提取更多更全的信息)
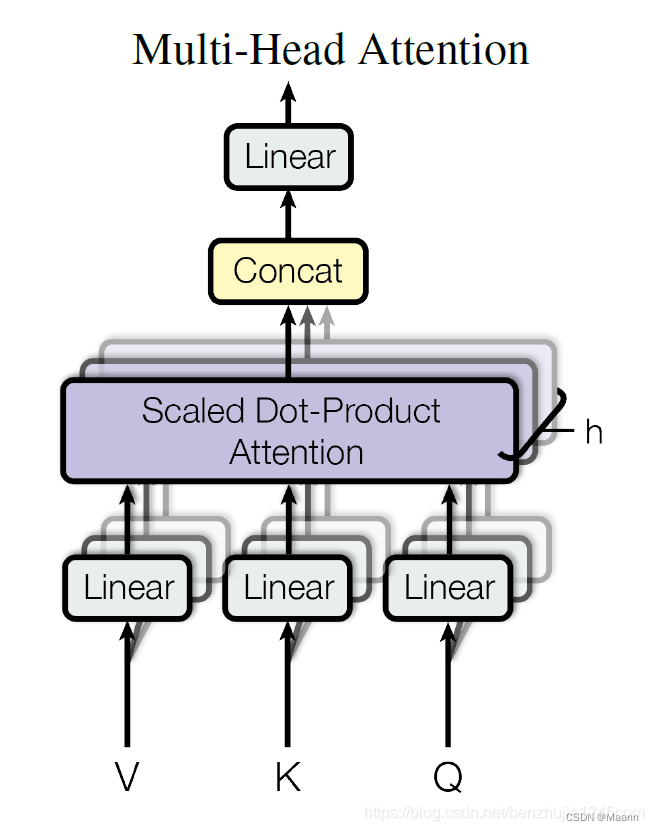
在 Transformer 论文中,通过添加一种多头注意力机制,进一步完善了自注意力层。具体做法:首先,通过 h 个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。
Multi-head Attention 的本质是,在参数总量保持不变的情况下,将同样的 Query,Key,Value 映射到原来的高维空间的不同子空间中进行 Attention 的计算,在最后一步再合并不同子空间中的 Attention 信息。这样降低了计算每个 head 的 Attention 时每个向量的维度,在某种意义上防止了过拟合;由于 Attention 在不同子空间中有不同的分布,Multi-head Attention 实际上是寻找了序列之间不同角度的关联关系,并在最后拼接这一步骤中,将不同子空间中捕获到的关联关系再综合起来。
3. 编码器(Encoder)
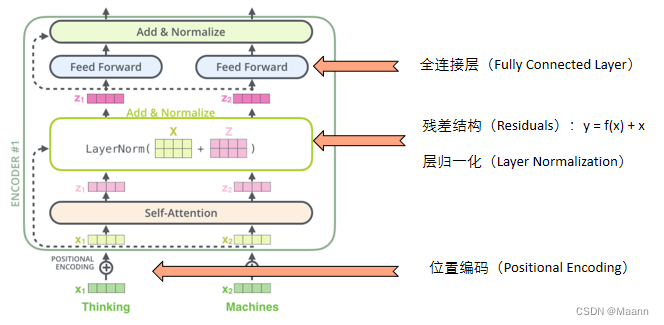
残差结构——使得模型能够保留更多原始输入的信息,同时有效地缓解梯度消失问题。
层归一化——加速网络的训练和收敛。
4. 解码器(Decoder)
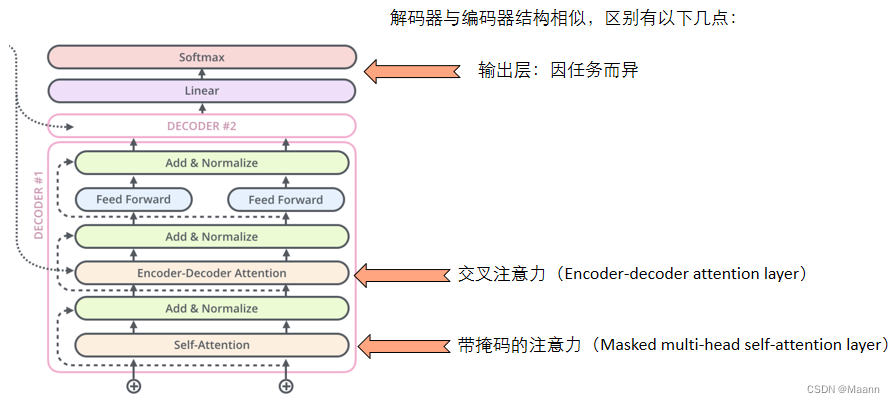
4.1 掩码(Masked)
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
下面的描述中使用了类似 Teacher Forcing 的概念。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 “ I” 预测下一个单词 “have”。

4.2 交叉注意力(Encoder-decoder attention)
Encoder-Decoder Attention 层的工作原理和多头自注意力机制类似。不同之处是:Encoder-Decoder Attention 层使用前一层的输出构造 Query 矩阵,而 Key 和 Value 矩阵来自于编码器栈的输出。
Q:解码器
K、V:编码器
用解码器的Query查询编码器的Key、Value
5. 基于Transformer架构的模型
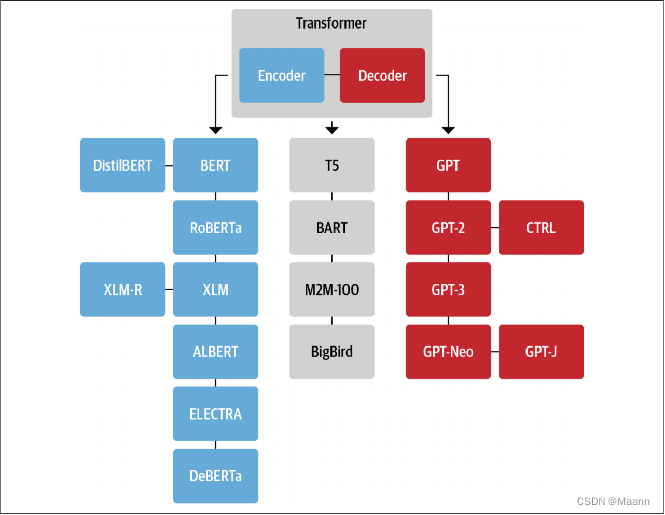
模型主要分三类:
(1)只包含编码器:BERT, RoBERTa, XLM
(2)只包含解码器:GPT, GPT-2, GPT-3
(3)包含编码器&解码器: T5, BART
演进思路:
(1)提升在各类任务中的性能表现
(2)减少参数,使模型轻量化,易于部署
Transformer总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。