近日,阿里云机器学习平台PAI与华南理工大学合作(阿里云与华南理工大学联合培养项目)在自然语言处理顶级会议ACL2023上发表了具有高效推理速度的中文领域文图生成扩散模型和工具链Rapid Diffusion。它是面向中文特定领域的文图生成模型,采用与Stable Diffusion一样的模型结构,在给定中文文本的情况下可以实现快速的文图生成工作,此外,我们提供了一键式部署功能,用户可以在个人数据上一键式的进行模型的Finetune与推理。
论文:
Bingyan Liu*, Weifeng Lin*, Zhongjie Duan, Chengyu Wang, Ziheng Wu, Zipeng Zhang, Kui Jia, Lianwen Jin, Cen Chen, Jun Huang. Rapid Diffusion: Building Domain-Specific Text-to-Image Synthesizers with Fast Inference Speed. ACL 2023 (Industry Track)
背景
Text-to-Image Synthesis(TIS)是指根据文本输入生成图像的技术,给定一段文本指令,使用计算机程序生成符合文本内容描述的图像。近年来,随着预训练大模型和扩散模型相关研究的高速发展,使用预训练文本编码器和基于扩散的图像生成器的文图生成模型已经能够生成媲美人类画师的精美图像。然而,由于预训练语言模型缺乏特定领域的实体知识且受限于扩散模型的推理速度,目前开源社区的流行文图生成模型难以支持特定工业领域的应用。主要问题在于,基于扩散的方法需要使用预训练文本编码器对输入文本进行编码,然后作为扩散模型的UNet模型的条件输入。但是目前使用网上收集的文本图像对预训练的文本编码器模型缺乏特定实体概念的理解能力,难以捕获特定实体知识,这对于生成逼真的实体对象图片至关重要。同时,扩散模型的推理速度和计算成本也是需要考虑的重要因素,而迭代逆扩散去噪过程的繁琐计算一直是扩散模型推理速度的瓶颈。
为了解决上述问题,研究具备特定实体对象理解能力的扩散模型以生成具有符合文本内容描述的高分辨率图像,并开发支持快速在线推理的优化文图生成模型的框架是必要的。
算法概述
我们提出了一个新框架:Rapid Diffusion,用于训练和部署文图生成扩散模型,模型架构图1所示。Rapid Diffusion在stable diffusion模型的基础上进行了改进。为了提升对特定实体的理解能力,我们在CLIP的文本编码器中注入了丰富的实体知识,使用知识图谱进行知识增强。文图生成模模型隐空间的噪声预测器与stable diffusion,是一个带交叉注意力机制的U-Net网络。与开源Stable Diffusion直接利用大规模分层扩散模型不同,我们在图像扩散模块之后集成了一个基于ESRGAN的网络,以提高生成图像的分辨率的同时有效解决了参数量爆炸和耗时长的问题。对于在线部署,我们基于FlashAttention优化的神经架构设计了一个高效的推理流程。生成模型计算图的Intermediate Representation(IR)经过端到端人工智能编译器BladeDISC进一步处理,以提高生成模型的推理速度。
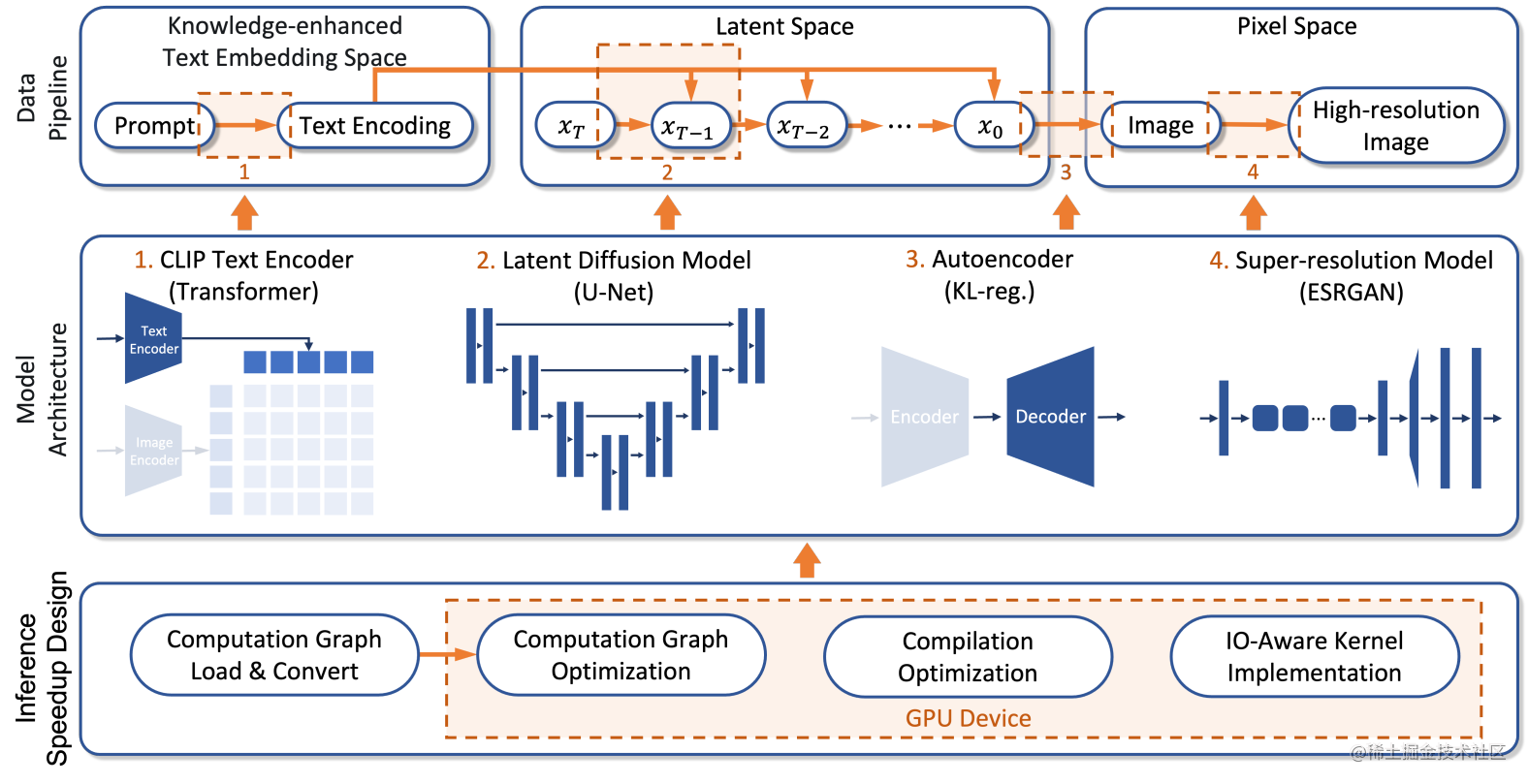
知识增强的文本编码器
对于知识增强的文本编码器,我们聚焦在中文场景下的文图生成问题,为了得到对中文文本以及中文实体知识更具理解能力的文本编码器,我们使用了1亿的悟空图文对数据集作为我们的文本编码器预训练数据。此外,对于实体知识,我们使用了最新的中文知识图谱OpenKG数据集,包含了1600万的实体和1.4亿个三元关系对,来训练我们的中文CLIP模型。在中文CLIP预训练阶段,悟空语料库句子中的实体token会被增强为 e ˉ = e ˉ t x t + e ˉ k g \bar{e}=\bar{e}_{txt}+\bar{e}_{kg} eˉ=eˉtxt+eˉkg,其中 e ˉ t x t \bar{e}_{txt} eˉtxt是实体的文本embedding, e ˉ k g \bar{e}_{kg} eˉkg是通过TransE算法得到的知识图谱embedding。虽然我们是在中文场景下对CLIP模型进行知识增强,但是我们的增强方法同样适用于其他的语言场景。在训练特定领域的文图生成模型时,为了领域知识的对齐,我们将中文CLIP模型的文本编码器设置为可训练。
隐空间噪声预测器
在得到文本embedding e ˉ \bar{e} eˉ 后,我们在隐空间下使用latent diffusion模型生成图像的潜在编码,latent diffusion是一个带有可以捕捉文本条件信息的交叉注意力机制的Unet模型,训练时图像重建的损失函数为:
图像生成的过程是扩散的逆过程,从随机采样的高斯噪声中基于条件文本信息生成图像,同样的,为了增强生成图像与文本信息之间的相关性,我们在训练时使用classifier-free guidance的训练方法。为了减少太大的采样步数带来的时间开销,我们使用了PNDM算法来减少采样步数。在我们框架中,我们使用了悟空数据集预训练了latent diffusion模型,然后再在领域场景数据下进行微调。
超分辨率网络
我们的latent diffusion模型生成的图像的分辨率为256*256, 为了得到更高分辨率的图像,与stable diffusion用另外一个扩散模型不同,我们直接使用了训练好的ESRGAN模型来提高图像的分辨率,大大提升了图像生成的速度。
推理加速设计
在推理加速设计这块,我们分析了原始 PyTorch 模型的推理速度,并观察到模型推理瓶颈主要在U-Net 模型,其中U-Net中的交叉注意力计算在推理时间中占主导地位。分析结果见图2。为了解决这个问题,我们结合自动切片和编译优化技术来优化整个技术流水线,并引入 IO 感知注意力实现以进一步提高推理性能。
我们的推理加速算法通过增强一组中间标识来创建一个完整的动态图表示来实现的。对于内存访问密集的操作,我们充分利用共享内存设计了更大粒度的内核融合策略,有效减少了CPU/GPU之间的切换。执行最佳图分区和内核实现选择以获得最佳推理速度。
在自动编译优化的基础上,我们进一步利用 FlashAttention 技术作为U-Net的交叉注意力算子,这是网络推理瓶颈的核心。该技术基于注意力IO特性,对注意力计算进行tiling操作,减少内存读写计算量。我们为计算设备和硬件架构以及动态输入的各种组合引入了不同的 FlashAttention内核实现。通过加速交叉注意力计算,为 U-Net 模块带来 1.9倍的加速。
算法精度评测
为了评测Rapid Diffusion模型,我们在三个中文图文对数据集(电商,国画,美食)上进行测试,结果如表一所示:
表1 Rapid Diffusion 与基线模型的性能对比 (FID 分数)。
结果可以证明,Rapid Diffusion在这些数据集上获得不错的效果。从表1可以看出,Rapid Diffusion 在三个数据集上的表现优于所有交易对手,平均 FID 得分为 21.90。 结果表明,我们针对特定领域场景的知识增强模型可以更好地理解领域知识,并且可以生成更逼真和多样化的图像。
表2 文本图像检索知识增强 CLIP 的性能。
由于 CLIP 模型旨在学习跨模态表示,我们首先通过文本图像检索从本质上评估我们的模型。 我们使用相同的预训练文本图像语料库比较中文 CLIP 模型和我们的Chinese Knowledge-enhanced CLIP (CKCLIP) 模型。表 2报告了测试集上的文本到图像和文本到图像检索结果。 我们的 CKCLIP 模型显着提高了检索性能(尤其是对于 R@1 指标,显示了其学习跨模态表示的能力。
表3 Rapid Diffusion 的推理加速结果。
在推理速度上,我们使用了端到端人工智能编译器BladeDISC以及FlashAttention 技术来提高模型的推理速度,同样的,实验结果表3所示,我们的方法可以提高1.73倍的推理速度。虽然我们是在Rapid Diffusion上进行实验,但是我们提出的加速方法具有普适性,同样也适用于其他的diffusion模型,譬如 Stable Diffusion 和太乙 Diffusion模型。我们还将Rapid Diffusion与阿里云机器学习平台PAI进行集成,以展示其在实际应用中的实用价值。在阿里云机器学习平台PAI上,用户可以在自己的任务(数据)上一键式的进行训练,微调以及推理自己的模型。
在未来,我们将扩展 Rapid Diffusion 的功能,并通过先进的编译优化技术进一步提高推理速度。为了更好地服务开源社区,我们模型和源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High- resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695.
- Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840– 6851.
- Jiaming Song, Chenlin Meng, and Stefano Ermon. 2021. Denoising diffusion implicit models. In International Conference on Learning Representations.
- Kai Zhu, WY Zhao, Zhen Zheng, TY Guo, PZ Zhao, JJ Bai, Jun Yang, XY Liu, LS Diao, and Wei Lin. 2021. Disc: A dynamic shape compiler for machine learning workloads. In Proceedings of the 1st Workshop on Machine Learning and Systems, pages 89– 95.
- Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. CoRR, abs/2205.14135.
论文信息
论文标题:Rapid Diffusion: Building Domain-Specific Text-to-Image Synthesizers with Fast Inference Speed
论文作者:刘冰雁、林炜丰、段忠杰、汪诚愚、吴梓恒、张子鹏、贾奎、金连文、陈岑、黄俊
论文PDF链接:https://aclanthology.org/2023.acl-industry.28.pdf
免费领取 交互式建模PAI-DSW、模型训练PAI-DLC 5000CU*H计算资源包,以及价值500元模型在线服务 PAI-EAS 抵扣包。