目录
一、算术运算
二、比较运算
三、汇总运算
1、count非空值计数
2、sum求和
3、mean求均值
4、max求最大值
5、min求最小值
6、median求中位数
7、mode求众数
8、var求方差
9、std求标准差
10、quantile求分位数
四、相关性运算
一、算术运算
算术运算就是基本的加减乘除,在Excel或Python中数值类型的任意两列可以直接进行加、减、乘、除运算,而且是对应元素进行加、减、乘、除运算,Excel中的运算比较简单,主要介绍Python中的算术运算。
两列相加的具体实现如下所示:
>>>df
C1 C2 C3
S1 1 2 3
S2 4 5 6
>>>df["C1"]+df["C2"]
S1 3
S2 9
DTPYE:INT64相减、相乘、相除类似。
任意一列加/减一个常数值,这一列中额所有值都加/减这个常数值。
二、比较运算
比较运算和Python基础知识中讲到的比较运算一致,也是常规的大于、等于、小于之类的,只不过这里的比较是在列与列之间进行的。
在Excel中列与列之间的比较运算和Python中的方法一致,例子如下图所示:

下面是一些Python中列与列之间比较的例子
>>>df ["C1"]>df["C2"]
S1 false
S2 false
dtype:bool
三、汇总运算
上面讲到的算术运算和比较运算都是在列与列之间进行的吗,运算结果有多少行的值,就会返回多少个结果,而汇总运算是将数据进行汇总返回一个汇总以后的结果值。
1、count非空值计数
非空值计数就是计算某一个区域中非空(单元格)数值的个数。
在Excel中counta()函数用于计算某个区域中非空单元格的个数。与counta()函数类似count()函数,它用于计算某个区域中含有数字的单元格的个数。
在Python中,直接在整个数据表上调用count()函数,返回的结果为该数据表中每列的非空值的个数,具体时间如下所示:
>>>df.count()
C1 2
C2 2
C3 3
dtype:int64count()函数默认是求取每一列的非空数值的个数,可以通过修改axis参数让其等于1,来求取每一行的非空数值的个数。
>>>df.count(axis=1)
S1 3
S2 3
dtype:int64也可以把某一列或者某一行索引出来,单独查看这一列或这一行的非空值个数。
>>>df["C1"].count()
22、sum求和
求和就是对某一区域中的所有数值进行加和操作。
在Excel中要求取某一区域的和,直接在sum()函数后面的括号中指明要求和的区域,即要对哪些值进行求和操作即可。
sum(D2:D6)#表示对D2:D6范围的数值进行求和操作在Python中,直接在整个数据表上调用sum()函数,返回的是该含数据表每一列的求和结果,具体例子如下:
>>>df.sum()
C1 5
C2 7
C3 9
dtype:int64sum()函数默认对每一列进行求和,可通过修改axis参数,让其等于1,来对每一行的数值进行求和操作。
>>>df.sum(axis=1)
S1 6
S2 15
DTYPE:INT64也可以把某一列或者某一行索引出来,单独对这一列或这一行数据进行求和操作。
>>>df["C1"].sum()3、mean求均值
求均值是针对某一区域中的所有值进行求算术平均值运算。均值是用来衡量数据一般情况的指标,容易受到极大值、极小值的影响。
在Excel中对某个区域内的值进行求平均值运算,用的是average()函数,只要在average()函数中指明要求均值运算的区域即可,比如:
average(D2:D6)#表示对D2:D6范围内的值进行求均值运算
在Python中的求均值利用的是mean()函数吗,如果对整个表直接调用mean()函数,返回的是该表中每一列的均值。
>>>df.mean()
C1 2.5
C2 3.5
C3 4.5
dtpye:float64mean()函数默认是对数据表中的每一列进行求均值运算,可通过修改axis参数,让其等于1,来对每一行进行求均值运算。
>>>df.mean(axis=1)
S1 2.0
S2 5.0
dtpye : float64
也可以把某一列或者某一行通过索引的方式取出来,然后在这一行或这一列上调用mean()函数,单独求取这一行或这一列的均值。
>>>df["C1"].mean()#对C1列求均值
2.54、max求最大值
求最大就是比较一组数据中所有数值的大小,然后返回最大的一个值。
在Excel和Python中,求最大值使用的都是max()函数,在Excel中同样只需要在max()函数中指明要求最大值的区域即可:在Python中,和其他函数一样,如果对整个表直接调用max()函数,则返回该数据表中每一列的最大值。max()函数也可以对每一行求最大值,还可以单独对某一行或某一列求最大值。
>>>df.max()
C1 4
C2 5
C3 6
dtype:int64
#对每一行求最大值
>>>df.max(axis = 1)
S1 3
S2 6
dtpye:int64
>>>df["C1"].max()#对C1求最大值
45、min求最小值
求最小值与求最大值是相对应的,通过比较一组数据中所有数值的大小,然后返回最小的那个值。
在Excel和Python中都使用min()函数来求最小值,它的使用方法与求最大值的类似。
6、median求中位数
中位数就是将一组含有N个数据的序列X按从小到大排列,位于中间位置的那个数。
中位数是以中间位置的数来反映数据的一般情况,不容易受到极大值、极小值的影响,因而在反映数据分布情况上要比平均值更有代表性。
现有序列为X:{X1、X2、X3、.......、Xn}。
如果n为奇数,则中位数: 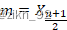
如果n为偶数,则中位数: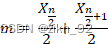
在Excel和Python中求一组数据的中位数,都是使用median()函数来实现的。下面为在Excel中求中位数的示例:
median(D2:D6)#表示求D2:D6区域内的中位数在Python中,median()函数的使用原则和其他函数的一致。
#对整个表调用median()h函数
>>>df.median()
C1 4.0
C2 5.0
C3 6.0
dtpye:float 64
#求取每一行的中位数
>>>df.median(axis = 1)
S1 2.0
S2 5.0
S3 8.0
dtpye:float 64
#求取C1列的中位数
>>>df["C1"].median()
4.07、mode求众数
顾名思义,众数就是一组数据中出现次数最多的数,求众数就是返回这组数据中出现次数最多的那个数。
在Excel和Python中求众数都使用mode()函数,使用原则与其他函数完全一致。
在Excel中求众数的示例如下:
mode(D2:D6)#返回D2:D6之间出现次数最多的值在Python中求众数的示例如下:
#对整个表调用mode()函数
>>>df
C1 C2 C3
S1 1 1 3
S2 4 4 6
S3 1 1 3
>>>df.mode()
C1 C2 C3
0 1 1 3
#求取每一行的众数
>>>df.mode(axis = 1)
0
S1 1
S2 4
S3 1
#求取C1列的众数
>>>df["C1"].mode()
0 1
dtype:int64 8、var求方差
方差是用来衡量一组数据的离散程度(即数据波动幅度)的。
在Excel和Python中求一组数据中的方差都使用var()函数。
9、std求标准差
标准差是方差的平方根,二者都是用来表示数据的离散程度的。
在Excel中计算标准差使用的是stdevp()函数。
在Python中计算标准差使用的是std()函数,std()函数的使用原则与其他函数的一致。
10、quantile求分位数
分位数是比中位数更加详细的基于位置的指标,分位数主要有四分之一分位数、四分之二分位数、四分之三分位数,而四分之二分位数就是中位数。
在Excel中求分位数用的是percentile()函数,示例如下:
percentile(D2:D6,0.5)#表示求D2:D6区域内的二分之一分位数
percentile(D2:D6,0.25)#表示求D2:D6区域内的四分之一分位数
percentile(D2:D6,0.75)#表示求D2:D6区域内的四分之三分位数在Python中求分位数用的是quantile()函数,要在quantile后的括号中指明要求取的分位数值,quantile()函数与其他函数的使用规则相同。
四、相关性运算
相关性常用来衡量两个实物之间的相关程度,我们一般用相关系数来衡量两者的相关程度,所以相关性计算其实就是计算相关系数,比较常用的是皮尔逊相关系数。
在Excel中求取相关系数用的是correl()函数,示例如下:
correl(A1:A10,B1:B10)#求取A列指标与B列指标的相关系数
在Python中求取相关系数用的是corr()函数,示例如下:
>>>df
co11 co12
0 1 2
1 3 4
2 5 6
3 7 8
4 9 10
>>>df["co11"].corr(df["co12"])
#求取co11列与co12列的相关系数
0.9999999999还可以利用corr()函数求取整个DATAFRame表中各字段两两之间的相关性。
>>>df.corr()









![[pyqt5]designer设计界面设计工具栏上图标和文字同时显示](https://img-blog.csdnimg.cn/d14bc2d1a5f44cbda66c57fde2451c55.jpeg)