深蓝学院C++基础与深度解析笔记 第 11 章 类
1. 结构体与对象聚合
**● 结构体:**对基本数据结构进行扩展,将多个对象放置在一起视为一个整体
– 结构体的声明与定义(注意定义后面要跟分号来表示结束)
– 仅有声明的结构体是不完全类型( incomplete type )
– 结构体(以及类)的一处定义原则:翻译单元级别
● 数据成员(数据域)的声明与初始化
– ( C++11 )数据成员可以使用 decltype 来声明其类型,但不能使用 auto(除静态)
– 数据成员声明时可以引入 const 、引用等限定
– 数据成员会在构造类对象时定义
– ( C++11 )类内成员初始化
– 聚合初始化:从初始化列表到指派初始化器
#include <iostream>
struct Str
{
int x;
int y;
}
int main()
{
Str m_str;
m str.x = 3;
std::cout < m str.x < std::endl;
}
有声明即可定义指针,结构体内可以使用decltype(),不可以使用auto;
● mutable 限定符,只能在结构体内限定定义
● 静态数据成员 多个对象之间共享的数据成员
– 定义方式的衍化
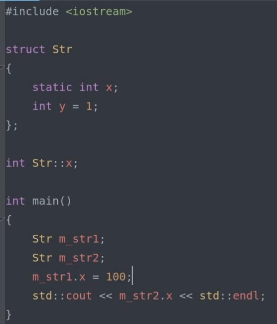
● C++98 :类外定义, const 静态成员的类内初始化
● C++17 :内联静态成员的初始化
– 可以使用 auto 推导类型
● 静态数据成员的访问
– “.” 与“ ->” 操作符
– “::” 操作符
● 在类的内部声明相同类型的静态数据成员
2. 成员函数(方法)
● C语言不可以在结构体中定义函数;C++可以在结构体中定义函数,作为其成员的一部分:对内操作数据成员,对外提供调用接口:
– 在结构体中将数据与相关的成员函数组合在一起将形成类,是 C++ 在 C 基础上引入的概念
– 关键字 class, struct在此类似于public:
– 类可视为一种抽象数据类型,通过相应的接口(成员函数)进行交互
– 类本身形成域,称为类域
● 成员函数的声明与定义:
– 类内定义(隐式内联)
– 类内声明 + 类外定义, 类外显示内联:inline
– 类与编译期的两遍处理:但是只能处理内置类型后置,自定义类型还是需要桉顺序使用
– 成员函数与尾随返回类型( trail returning type )
● 成员函数与 this 指针: str *const this
– 使用 this 指针引用当前对象
– 基于 const 的成员函数重载,this本身不能修改,但是this->x可以
**● 成员函数的名称查找与隐藏关系:**先找最小范围的作用域,在递归的寻找外一层的作用域
– 函数内部(包括形参名称)隐藏函数外部
– 类内部名称隐藏类外部
– 使用 this 或域操作符引入依赖型名称查找
ps: 类名::变量/函数即为该类下的变量/函数, :: 变量/函数:中省略::前的作用域范围即为全局的变量/作用域
● 静态成员函数:被所有对象共享
– 在静态成员函数中返回静态数据成员
● 成员函数基于引用限定符的重载( C++11 )
3. 访问限定符与友元
访问限定符与友元
● 使用 public/private/protected 限定类成员的访问权限
– 限定目标 : 访问权限的引入使得可以对抽象数据类型进行封装
– 类与结构体缺省访问权限的区别: C++默认:private, C 默认类似于public
● 使用友元打破访问权限限制 关键字 —— friend
– 声明某个类或某个函数是当前类的友元 慎用! —— 改变了【封装】 特性
– 在类内首次声明友元类或友元函数:可以先声明freined ,再定义;声明friend和声明函数是两个概念
● 注意使用限定名称引入友元并非友元类(友元函数)的声明: 假如使用了全局限定::则需要提前声明或定义函数
#include <iostream>
#include <vector>
class Str2;
class str
{
friend Str2; // str2可以访问str的私有和保护类型的数据和函数 ,单向的
public:
inline static int x;
private:
int y;
};
class Str2
{
void fun()
{
std::cout<<Str::x<< std::endl;
}
};
– 友元函数的类内外定义与类内定义
隐藏友元( hidden friend ):常规名称查找无法找到,在类内定义
● 好处:减轻编译器负担,防止误用
● 改变隐藏友元的缺省行为:在类外声明或定义函数
4. 构造、析构与复制成员函数
● 构造函数: 构造对象时调用的函数,无返回
– 名称与类名相同,无返回值,可以包含多个版本(可重载)
– 代理构造函数( C++11 ):使用别的函数完成构造,然后再执行本构造函数的内容
代理构造:
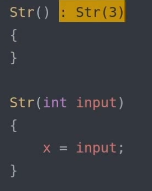
● 初始化列表: 区分数据成员的初始化与赋值,尽量和初始化顺序一致
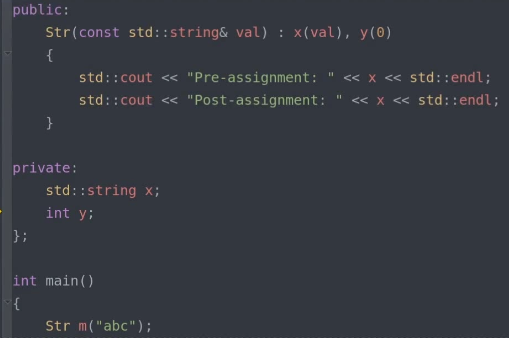
– 通常情况下可以提升系统性能
– 一些情况下必须使用初始化列表(如类中包含引用成员)
– 注意元素的初始化顺序与其声明顺序相关,与初始化列表中的顺序无关(初始化列表可能顺序不一致,但是声明顺序是固定的,为了满足先构造的后销毁的原则)
– 使用初始化列表覆盖类内成员初始化的行为
先构造的后销毁,后构造的对象先销毁!
**● 缺省构造函数:**不需要提供实际参数就可以调用的构造函数
– 如果类中没有提供任何构造函数,那么在条件允许的情况下,编译器会自动合成一个缺省构造函数
– 合成的缺省构造函数会使用缺省初始化来初始化其数据成员
– 调用缺省构造函数时避免 most vexing parse
classname m(); //会把m认为是函数而不是对象
使用 = default 关键字定义缺省构造函数,只有编译器能合成的函数它才会去合成。
● 单一参数构造函数
– 可以视为一种类型转换函数
– 可以使用 explicit 关键字避免求值过程中的隐式转换
● 拷贝构造函数: 接收一个当前类对象的构造函数
– 会在涉及到拷贝初始化的场景被调用,比如:参数传递。因此要注意拷贝构造函数的形参类型
– 如果未显式提供,那么编译器会自动合成一个,合成的版本会依次对每个数据成员调用拷贝构造
● 移动构造函数 (C++11) :
将旧的对象转移给新对象后,旧的对象自动销毁。接收一个当前类右值引用对象的构造函数,进一步提升系统性能。
– 可以从输入对象中“ 偷窃” 资源,只要确保传入对象处于合法状态即可
– 当某些特殊成员函数(如拷贝构造)未定义时,编译器可以合成一个,有移动调移动,没有移动调拷贝 (C++17)
– 通常声明为不可抛出异常的函数: noexcept,一旦抛出就会崩溃
– 注意右值引用对象用做表达式时是左值!
PS:&& 代表右值引用
语义移动:
在C++中,移动语义是一种优化技术,用于在对象之间转移资源的所有权,而不是进行复制。 当你移动一个对象时,源对象的资源所有权转移到目标对象,源对象不再拥有该资源。
移动操作通常使用移动构造函数和移动赋值运算符来实现。这些特殊的成员函数允许你有效地将资源(如堆上的内存、文件句柄等)从一个对象转移到另一个对象,而无需进行代价昂贵的复制操作。
在进行移动操作时,原始对象的内存空间仍然存在,但它的状态可能会变为有效但不确定的状态。 是因为移动操作不对原始对象进行显式的清理或重置,这意味着你不能再对原始对象进行任何有意义的操作,因为它的资源已被移动到其他对象。对于移动后的原始对象,你可以选择销毁它或重新赋值为其他有效值。(为了避免误用移动操作导致不确定状态,建议清理!)
移动操作的主要好处是避免了不必要的复制开销,特别是在涉及大型对象或资源密集型对象时。通过移动对象,可以更高效地管理资源并提高程序的性能。
需要注意的是,只有具有可移动语义的对象才能被移动。这包括具有移动构造函数和移动赋值运算符的类,或者具有可移动成员的类(如std::unique_ptr、std::vector等)。
总结起来,移动操作将资源的所有权从一个对象转移到另一个对象,原始对象进入有效但不确定的状态,而移动后的对象获得资源的所有权。移动操作的主要目的是避免不必要的复制并提高程序性能。
● 拷贝赋值与移动赋值函数( operator = )
Str m; //缺省构造函数 无参
Str m2 = m; //拷贝赋值
Str m3(m2); //移动构造函数
m3 = m; //赋值运算符,会被翻译成 m3.opreator = (m);
拷贝赋值返回值是:类名&
– 注意赋值函数不能使用初始化列表
– 通常来说返回当前类型的引用
– 注意处理给自身赋值的情况
– 在一些情况下编译器会自动合成
● 析构函数
– 函数名:“ ” ~ 加当前类型,无参数,无返回值
– 用于销毁对象以及扫尾工作,执行完最后一句才会跳出执行内存回收。
– 注意内存回收是在调用完析构函数时才进行
– 除非显式声明,否则编译器会自动合成一个,其内部逻辑为平凡的
– 析构函数通常不能抛出异常
● 通常来说,一个类:
– 如果需要定义析构函数,那么也需要定义拷贝构造与拷贝赋值函数(显式地)
– 如果需要定义拷贝构造函数,那么也需要定义拷贝赋值函数
– 如果需要定义拷贝构造(赋值)函数,那么也要考虑定义移动构造(赋值)函数
没有定义在使用时就会造成二次释放或者多次释放
ps:
1. Rule of Three (三法则):
如果需要定义析构函数、拷贝构造函数或拷贝赋值函数中的任何一个,就需要显式定义这三个函数。
这个原则确保了资源管理的正确性和一致性。
2. Rule of Five (五法则):
在C++11及更高版本中,如果需要定义拷贝构造函数或拷贝赋值函数,就需要同时定义析构函数、拷贝构造函数和拷贝赋值函数,并且还要考虑定义移动构造函数和移动赋值函数。
这个原则兼容了移动语义,提高了对象的性能和效率。
请注意,这些名称是广为接受的通用术语,用于描述C++编程中的最佳实践。
● 示例:包含指针的类:
● default 关键字
– 只对特殊成员函数有效
● delete 关键字
=delete 表示禁用该函数
– 对所有函数都有效
– 注意其与未声明的区别
– 注意不要为移动构造(移动赋值)函数引入 delete 限定符

● 如果只需要拷贝行为,那么引入拷贝构造即可
● 如果不需要拷贝行为,那么将拷贝构造声明为 delete 函数即可
● 注意 delete 移动构造(移动赋值)对 C++17 的新影响
如果一个类有用户自定义的拷贝赋值运算符或拷贝构造函数,或者有用户自定义的析构函数,那么该类的相关默认函数的隐式定义会被弃用,并且在未来的C++版本中可能会被删除,需要显式定义相关函数来替代。
5. 字面值类,成员指针与 bind 交互
● 字面值类:可以构造编译期常量的类型
– 其数据成员需要是字面值类型
– 提供 constexpr / consteval 构造函数 (小心使用 consteval )
– 平凡的析构函数(没有自定义行为的析构函数)
– 提供 constexpr / consteval 成员函数 (小心使用 consteval )
– 注意:从 C++14 起 constexpr / consteval 成员函数非 const 成员函数
constexpr和consteval区别:
constexpr和consteval是C++中的两个关键字,用于指定编译时常量表达式和编译时求值函数。
-
constexpr:constexpr是C++11引入的关键字,用于声明一个编译时常量表达式。它可以应用于变量、函数、构造函数等。- 用
constexpr声明的变量必须在编译时求值并产生常量结果,可以用于编译时常量的计算和编译时优化。 constexpr函数是在编译时进行求值的函数,它的参数和返回值必须是可编译时求值的表达式,函数体内只能包含可编译时求值的语句。- 在C++14之前,
constexpr函数只能包含一些简单的计算和控制流程,而在C++14及以后的版本中,constexpr函数可以包含更复杂的逻辑。
-
consteval:consteval是C++20引入的关键字,用于声明一个编译时求值函数,要求在编译时执行。consteval函数是在编译时强制执行的函数,它的参数和返回值必须是可编译时求值的表达式,函数体内只能包含可编译时求值的语句。- 与
constexpr函数不同,consteval函数在编译时强制要求函数的调用结果能在编译期间确定,否则会引发编译错误。 consteval函数适用于需要在编译时执行的严格要求,可以用于生成更高效的代码,但使用场景相对较少。
总结:
constexpr用于声明编译时常量表达式和函数,而consteval用于声明在编译时强制求值的函数。它们都提供了在编译期间进行求值和优化的能力,但consteval更加严格,要求函数在编译时一定能求值,否则会导致编译错误。
● 成员指针
– 数据成员指针类型示例: int A::*; 即使A中没有任何东西
– 成员函数指针类型示例: int (A::*)(double);
– 成员指针对象赋值: auto ptr = &A::x;
● 注意域操作符子表达式不能加小括号(否则 A::x 一定要有意义,例如静态)
– 成员指针的使用:
● 对象 .* 成员指针
● 对象指针 ->* 成员指针
无法加减,会被认为不是同一类型的,下式报错:
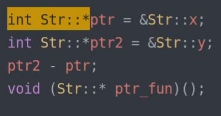
● bind 交互: 需要引入类的对象
– 使用 bind + 成员指针构造可调用对象
– 注意这种方法也可以基于数据成员指针构造可调用对象