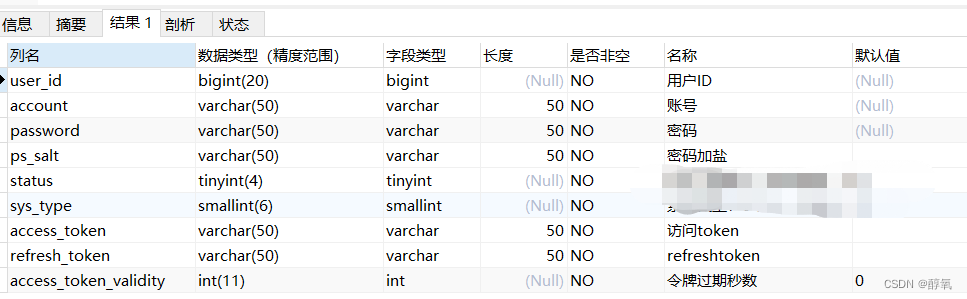
本文将介绍基于 MovieLens 数据集创建一个电影推荐系统的方法。具体而言,包括探索电影数据,训练矩阵分解模型,检查嵌入,矩阵分解中的正则化,Softmax 模型训练等内容。
目录
1.准备工作
1.1 导入依赖模块
1.2 加载数据
1.3 探索电影镜头数据
1.3.1 User 数据
1.3.2 电影
2.评分矩阵表示和误差计算
2.1 评分矩阵的稀疏表示
2.2 计算误差
3.训练矩阵分解模型
3.1 CFModel 定义
3.2 建立矩阵分解模型并对其进行训练
3.3 训练模型
4.检查嵌入件
4.1 编写一个计算候选电影评分的函数
4.2 用户推荐和最近的邻居(相似 Item 和 User)
5.矩阵分解中的正则化
5.1 建立正则化矩阵分解模型并对其进行训练
6.Softmax模型
6.1 损失函数
6.2 为softmax模型编写一个损失函数
6.3 建立一个softmax模型,对其进行训练,并检查其嵌入
6.4 训练Softmax模型
7.参考文献
1.准备工作
关于环境搭建,请前往《机器学习6:使用 TensorFlow 的训练线性回归模型》,本文不再赘述。
1.1 导入依赖模块
from __future__ import print_function
import numpy as np
import pandas as pd
import collections
from mpl_toolkits.mplot3d import Axes3D
from IPython import display
from matplotlib import pyplot as plt
import sklearn
import sklearn.manifold
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
tf.logging.set_verbosity(tf.logging.ERROR)
import altair as alt
from google.colab import auth
import gspread
from oauth2client.client import GoogleCredentials
from urllib.request import urlretrieve
import zipfile
# Add some convenience functions to Pandas DataFrame.
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.3f}'.format
def mask(df, key, function):
"""Returns a filtered dataframe, by applying function to key"""
return df[function(df[key])]
def flatten_cols(df):
df.columns = [' '.join(col).strip() for col in df.columns.values]
return df
pd.DataFrame.mask = mask
pd.DataFrame.flatten_cols = flatten_cols
# Install Altair and activate its colab renderer.
print("Installing Altair...")
alt.data_transformers.enable('default', max_rows=None)
alt.renderers.enable('colab')
print("Done installing Altair.")
USER_RATINGS = False1.2 加载数据
# 加载电影数据
print("Downloading movielens data...")
urlretrieve("/Users/shulan/Downloads/ml-100k.zip", "movielens.zip")
zip_ref = zipfile.ZipFile('movielens.zip', "r")
zip_ref.extractall()
print("Done. Dataset contains:")
print(zip_ref.read('ml-100k/u.info'))
# Load each data set (users, movies, and ratings).
users_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv(
'ml-100k/u.user', sep='|', names=users_cols, encoding='latin-1')
ratings_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings = pd.read_csv(
'ml-100k/u.data', sep='\t', names=ratings_cols, encoding='latin-1')
# 电影文件包含每种电影题材(类型)的二进制特征
genre_cols = [
"genre_unknown", "Action", "Adventure", "Animation", "Children", "Comedy",
"Crime", "Documentary", "Drama", "Fantasy", "Film-Noir", "Horror",
"Musical", "Mystery", "Romance", "Sci-Fi", "Thriller", "War", "Western"
]
movies_cols = [
'movie_id', 'title', 'release_date', "video_release_date", "imdb_url"
] + genre_cols
movies = pd.read_csv(
'ml-100k/u.item', sep='|', names=movies_cols, encoding='latin-1')
# 由于ID从1开始,我们将它们改为从0开始
users["user_id"] = users["user_id"].apply(lambda x: str(x - 1))
movies["movie_id"] = movies["movie_id"].apply(lambda x: str(x - 1))
movies["year"] = movies['release_date'].apply(lambda x: str(x).split('-')[-1])
ratings["movie_id"] = ratings["movie_id"].apply(lambda x: str(x - 1))
ratings["user_id"] = ratings["user_id"].apply(lambda x: str(x - 1))
ratings["rating"] = ratings["rating"].apply(lambda x: float(x))
# 计算指定类型的电影数量
genre_occurences = movies[genre_cols].sum().to_dict()
# 由于有些电影可以属于不止一种类型,我们创造了不同的“流派”列如下:
# all_genres:电影中所有活跃的类型。
# genre:从活跃的流派中随机抽取。
def mark_genres(movies, genres):
def get_random_genre(gs):
active = [genre for genre, g in zip(genres, gs) if g == 1]
if len(active) == 0:
return 'Other'
return np.random.choice(active)
def get_all_genres(gs):
active = [genre for genre, g in zip(genres, gs) if g == 1]
if len(active) == 0:
return 'Other'
return '-'.join(active)
movies['genre'] = [
get_random_genre(gs) for gs in zip(*[movies[genre] for genre in genres])]
movies['all_genres'] = [
get_all_genres(gs) for gs in zip(*[movies[genre] for genre in genres])]
mark_genres(movies, genre_cols)
# 创建一个包含所有 movielens 数据的合并 DataFrame
movielens = ratings.merge(movies, on='movie_id').merge(users, on='user_id')
# 将数据拆分为训练集和测试集
def split_dataframe(df, holdout_fraction=0.1):
test = df.sample(frac=holdout_fraction, replace=False)
train = df[~df.index.isin(test.index)]
return train, test
1.3 探索电影镜头数据
在我们深入模型构建之前,让我们检查一下 MovieLens 的数据集。了解数据集的统计数据通常是有帮助的。
1.3.1 User 数据
首先打印一些描述用户特征的基本统计数据。在 Python Console 中执行"users.describe()",结果如下:可以看出,User 数据共计 943 条。
>>> users.describe()
age
count 943.000
mean 34.052
std 12.193
min 7.000
25% 25.000
50% 31.000
75% 43.000
max 73.000此外,我们还可以打印一些描述用户特征的基本统计数据,如下所示:
>>> users.describe(include=[np.object])
user_id sex occupation zip_code
count 943 943 943 943
unique 943 2 21 795
top 0 M student 55414
freq 1 670 196 9我们还可以创建直方图来进一步了解用户的分布情况。我们使用 Altair 创建一个交互式图表。
# 创建用于对数据进行切片的过滤器
occupation_filter = alt.selection_multi(fields=["occupation"])
occupation_chart = alt.Chart().mark_bar().encode(
x="count()",
y=alt.Y("occupation:N"),
color=alt.condition(
occupation_filter,
alt.Color("occupation:N", scale=alt.Scale(scheme='category20')),
alt.value("lightgray")),
).properties(width=300, height=300, selection=occupation_filter)
# 定义生成直方图的函数.
def filtered_hist(field, label, filter):
"""第一层(浅灰色)包含完整数据的直方图,第二层包含过滤数据的直方图。
Args:
field: 生成直方图的属性
label: 直方图标签.
filter: 过滤器
"""
base = alt.Chart().mark_bar().encode(
x=alt.X(field, bin=alt.Bin(maxbins=10), title=label),
y="count()",
).properties(
width=300,
)
return alt.layer(
base.transform_filter(filter),
base.encode(color=alt.value('lightgray'), opacity=alt.value(.7)),
).resolve_scale(y='independent')
接下来,我们看一下每个用户的评分分布。
users_ratings = (
ratings
.groupby('user_id', as_index=False)
.agg({'rating': ['count', 'mean']})
.flatten_cols()
.merge(users, on='user_id')
)
# Create a chart for the count, and one for the mean.
alt.hconcat(
filtered_hist('rating count', '# ratings / user', occupation_filter),
filtered_hist('rating mean', 'mean user rating', occupation_filter),
occupation_chart,
data=users_ratings)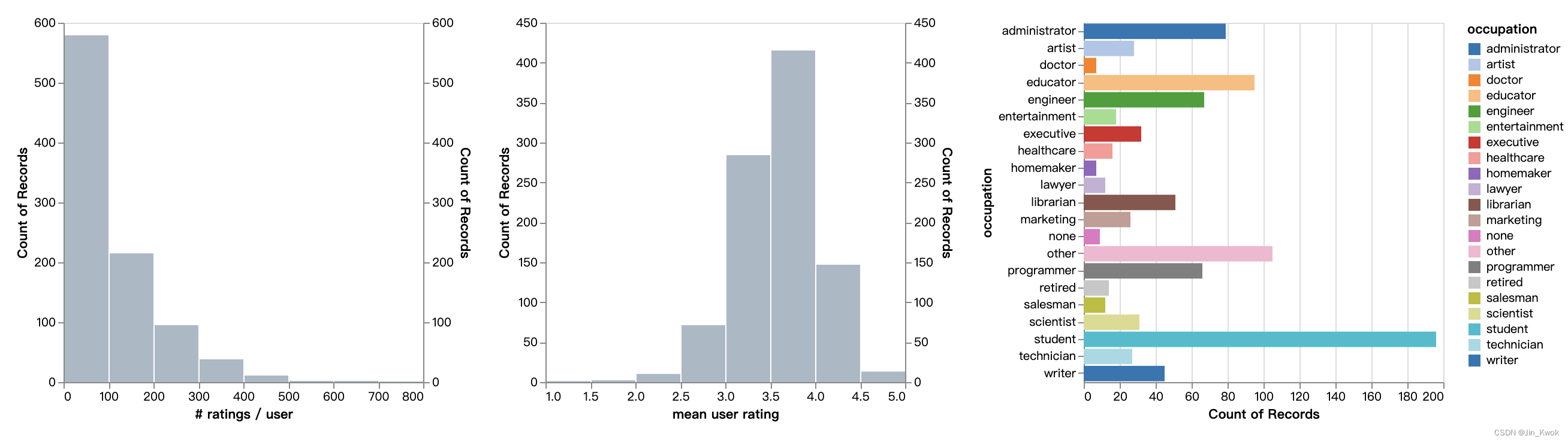
1.3.2 电影
用类似的方法,我们可以查看有关电影的数据。
movies_ratings = movies.merge(
ratings
.groupby('movie_id', as_index=False)
.agg({'rating': ['count', 'mean']})
.flatten_cols(),
on='movie_id')
genre_filter = alt.selection_multi(fields=['genre'])
genre_chart = alt.Chart().mark_bar().encode(
x="count()",
y=alt.Y('genre'),
color=alt.condition(
genre_filter,
alt.Color("genre:N"),
alt.value('lightgray'))
).properties(height=300, selection=genre_filter)
(movies_ratings[['title', 'rating count', 'rating mean']]
.sort_values('rating count', ascending=False)
.head(10))输出结果如下:
title rating count rating mean
49 Star Wars (1977) 583 4.358
257 Contact (1997) 509 3.804
99 Fargo (1996) 508 4.156
180 Return of the Jedi (1983) 507 4.008
293 Liar Liar (1997) 485 3.157
285 English Patient, The (1996) 481 3.657
287 Scream (1996) 478 3.441
0 Toy Story (1995) 452 3.878
299 Air Force One (1997) 431 3.631
120 Independence Day (ID4) (1996) 429 3.438当然,我们也可以绘制更加直观的直方图,如下所示:
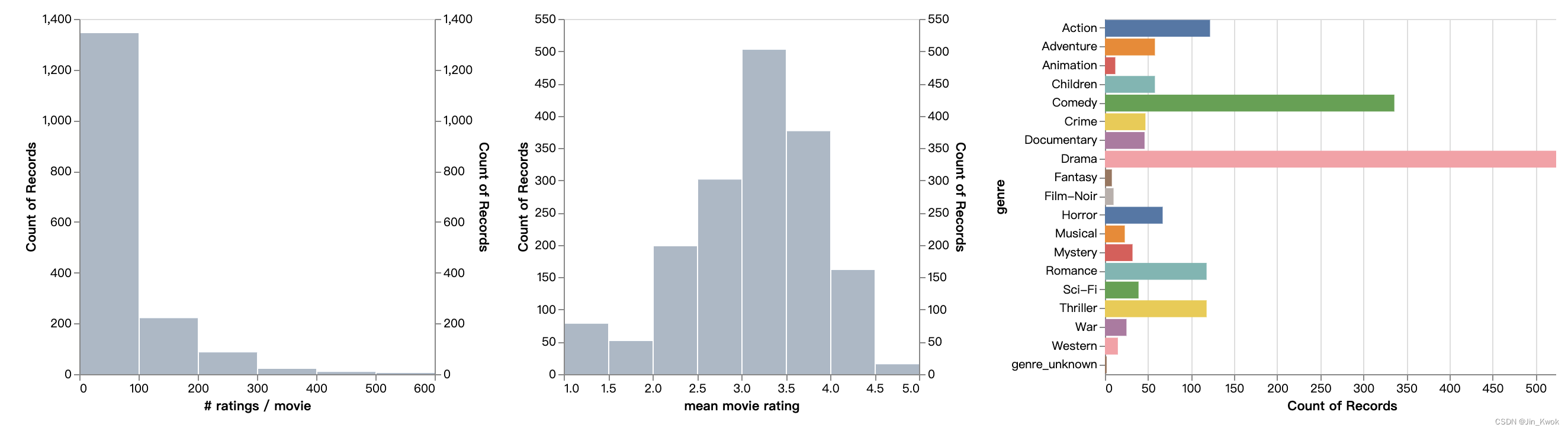
2.评分矩阵表示和误差计算
我们的目标是将评级矩阵 𝐴 分解转化为用户嵌入矩阵 𝑈 和电影嵌入矩阵 𝑉 的乘积, 使得
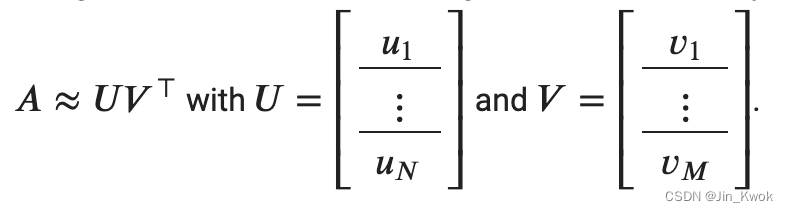
其中,
𝑁 是用户的数量,
𝑀 是电影的数量,
𝐴𝑖𝑗 是第 i 个用户对第 j 部电影的评分,
每一行𝑈𝑖 是一个𝑑-维用户的维向量(嵌入)𝑖,
每一行𝑉𝑗 是一个𝑑-维电影的维向量(嵌入)𝑗,
模型的预测是 (𝑖,𝑗) 对的点积〈𝑈𝑖,𝑉𝑗〉.
2.1 评分矩阵的稀疏表示
评分矩阵可能非常大,而且通常情况下,大多数条目(本案例中是电影评分)都没有被观察到,因为给定的用户只会对电影的一小部分进行评分。为了有效地表示,我们将使用 tf.SparseTensor。稀疏张量使用三个张量来表示矩阵:tf.SparseTensor(index,values,dense_shape) 表示张量,其中值 𝐴𝑖𝑗=𝑎 通过设置 indices[k]=[i,j] 和 values[k]=a 来编码。最后一个张量 dense_shape 用于指定整个底层矩阵的形状。
举个例子,假设我们有 2 个用户和 4 部电影,这 2 个用户对 4 部电影打了 3 个评分,如下所示:
user_id movie_id rating
0 0 5.0
0 1 3.0
1 3 1.0那么,相应的矩阵如下所示:

接下来,我们来构建评分矩阵的 tf.SparseTensor 表示。通过编写一个函数,将评级 DataFrame 映射到 tf.SparseTensor。提示:可以使用 df['column_name].values 来选择数据帧 df 的给定列的值。代码如下:
def build_rating_sparse_tensor(ratings_df):
"""
Args:
ratings_df: a pd.DataFrame with `user_id`, `movie_id` and `rating` columns.
Returns:
a tf.SparseTensor representing the ratings matrix.
"""
indices = ratings_df[['user_id', 'movie_id']].values
values = ratings_df['rating'].values
return tf.SparseTensor(
indices=indices,
values=values,
dense_shape=[users.shape[0], movies.shape[0]])2.2 计算误差
我们需要一种测量近似误差的方法。我们将从仅使用观测条目的均方误差开始(稍后我们将重新讨论)。它被定义为:
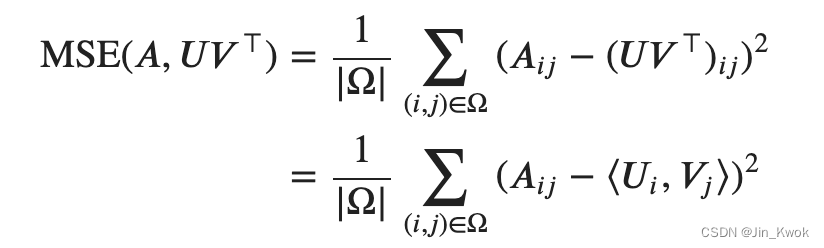
其中,Ω 是观测评分的集合; |Ω| 是 Ω 的基数.
相应地,实现代码如下:
# 定义计算均方根误差的函数
def sparse_mean_square_error(sparse_ratings, user_embeddings, movie_embeddings):
"""
Args:
sparse_ratings: 密度为[N,M]的稀疏张量评分矩阵
user_embeddings: 形状为[N,k]的稠密张量U,其中k是嵌入维度,使得U_i是用户i的嵌入。
movie_embeddings: 形状为[M,k]的稠密张量V,其中k是嵌入维度,使得V_j是电影j的嵌入。
Returns:标量张量,表示真实评级和模型预测之间的 MSE。
"""
predictions = tf.gather_nd(
tf.matmul(user_embeddings, movie_embeddings, transpose_b=True),
sparse_ratings.indices)
loss = tf.losses.mean_squared_error(sparse_ratings.values, predictions)
return loss3.训练矩阵分解模型
我们需要用到 CFModel(协作过滤模型)帮助类(helper class),它是一个使用随机梯度下降训练矩阵分解模型的简单类。类构造函数参数如下:
- 用户嵌入U(一个 tf.Variable)
- 电影嵌入 V(一个 tf.Variable)
- 要优化的损失(tf.Tensor)
- 度量字典的可选列表,每个字典将一个字符串(度量的名称)映射到一个张量。这些都是在训练过程中评估和绘制的(例如训练误差和测试误差)。
经过训练后,可以使用 model.embeddings 字典访问经过训练的嵌入。示例用法如下:
U_var = ...
V_var = ...
loss = ...
model = CFModel(U_var, V_var, loss)
model.train(iterations=100, learning_rate=1.0)
user_embeddings = model.embeddings['user_id']
movie_embeddings = model.embeddings['movie_id']3.1 CFModel 定义
# CFModel 帮助类
class CFModel(object):
"""简单定义一个协同过滤模型"""
def __init__(self, embedding_vars, loss, metrics=None):
"""初始化 CFModel.
Args:
embedding_vars: tf.Variables 字典.
loss: 一个浮动张量,代表要优化的损失。
metrics: 张量词典的可选列表。在训练过程中,每个字典中的指标将绘制在一个单独的图中。
"""
self._embedding_vars = embedding_vars
self._loss = loss
self._metrics = metrics
self._embeddings = {k: None for k in embedding_vars}
self._session = None
@property
def embeddings(self):
"""The embeddings dictionary."""
return self._embeddings
def train(self, num_iterations=100, learning_rate=1.0, plot_results=True,
optimizer=tf.train.GradientDescentOptimizer):
"""训练模型.
Args:
iterations: 迭代次数.
learning_rate: 学习率
plot_results: 是否打印训练结果
optimizer: 使用的优化器,默认为GradientDescentOptimizer。
Returns:
上次迭代时评估所用的度量字典
"""
with self._loss.graph.as_default():
opt = optimizer(learning_rate)
train_op = opt.minimize(self._loss)
local_init_op = tf.group(
tf.variables_initializer(opt.variables()),
tf.local_variables_initializer())
if self._session is None:
self._session = tf.Session()
with self._session.as_default():
self._session.run(tf.global_variables_initializer())
self._session.run(tf.tables_initializer())
tf.train.start_queue_runners()
with self._session.as_default():
local_init_op.run()
iterations = []
metrics = self._metrics or ({},)
metrics_vals = [collections.defaultdict(list) for _ in self._metrics]
# Train and append results.
for i in range(num_iterations + 1):
_, results = self._session.run((train_op, metrics))
if (i % 10 == 0) or i == num_iterations:
print("\r iteration %d: " % i + ", ".join(
["%s=%f" % (k, v) for r in results for k, v in r.items()]),
end='')
iterations.append(i)
for metric_val, result in zip(metrics_vals, results):
for k, v in result.items():
metric_val[k].append(v)
for k, v in self._embedding_vars.items():
self._embeddings[k] = v.eval()
if plot_results:
# Plot the metrics.
num_subplots = len(metrics)+1
fig = plt.figure()
fig.set_size_inches(num_subplots*10, 8)
for i, metric_vals in enumerate(metrics_vals):
ax = fig.add_subplot(1, num_subplots, i+1)
for k, v in metric_vals.items():
ax.plot(iterations, v, label=k)
ax.set_xlim([1, num_iterations])
ax.legend()
return results3.2 建立矩阵分解模型并对其进行训练
使用 spare_mean_square_error 函数,编写一个函数,通过创建嵌入变量以及训练和测试损失来构建 CFModel。代码如下:
# 定义模型函数
def build_model(ratings, embedding_dim=3, init_stddev=1.):
"""
Args:
ratings: 评分 DataFrame
embedding_dim: 嵌入向量的维数
init_stddev: float,随机初始化嵌入的标准偏差
Returns:
model: a CFModel.
"""
# 将评分 DataFrame 切分为训练集和测试集.
train_ratings, test_ratings = split_dataframe(ratings)
# 训练和测试数据集的稀疏张量表示
A_train = build_rating_sparse_tensor(train_ratings)
A_test = build_rating_sparse_tensor(test_ratings)
# 使用正态分布初始化嵌入
U = tf.Variable(tf.random_normal(
[A_train.dense_shape[0], embedding_dim], stddev=init_stddev))
V = tf.Variable(tf.random_normal(
[A_train.dense_shape[1], embedding_dim], stddev=init_stddev))
train_loss = sparse_mean_square_error(A_train, U, V)
test_loss = sparse_mean_square_error(A_test, U, V)
metrics = {
'train_error': train_loss,
'test_error': test_loss
}
embeddings = {
"user_id": U,
"movie_id": V
}
return CFModel(embeddings, train_loss, [metrics])3.3 训练模型
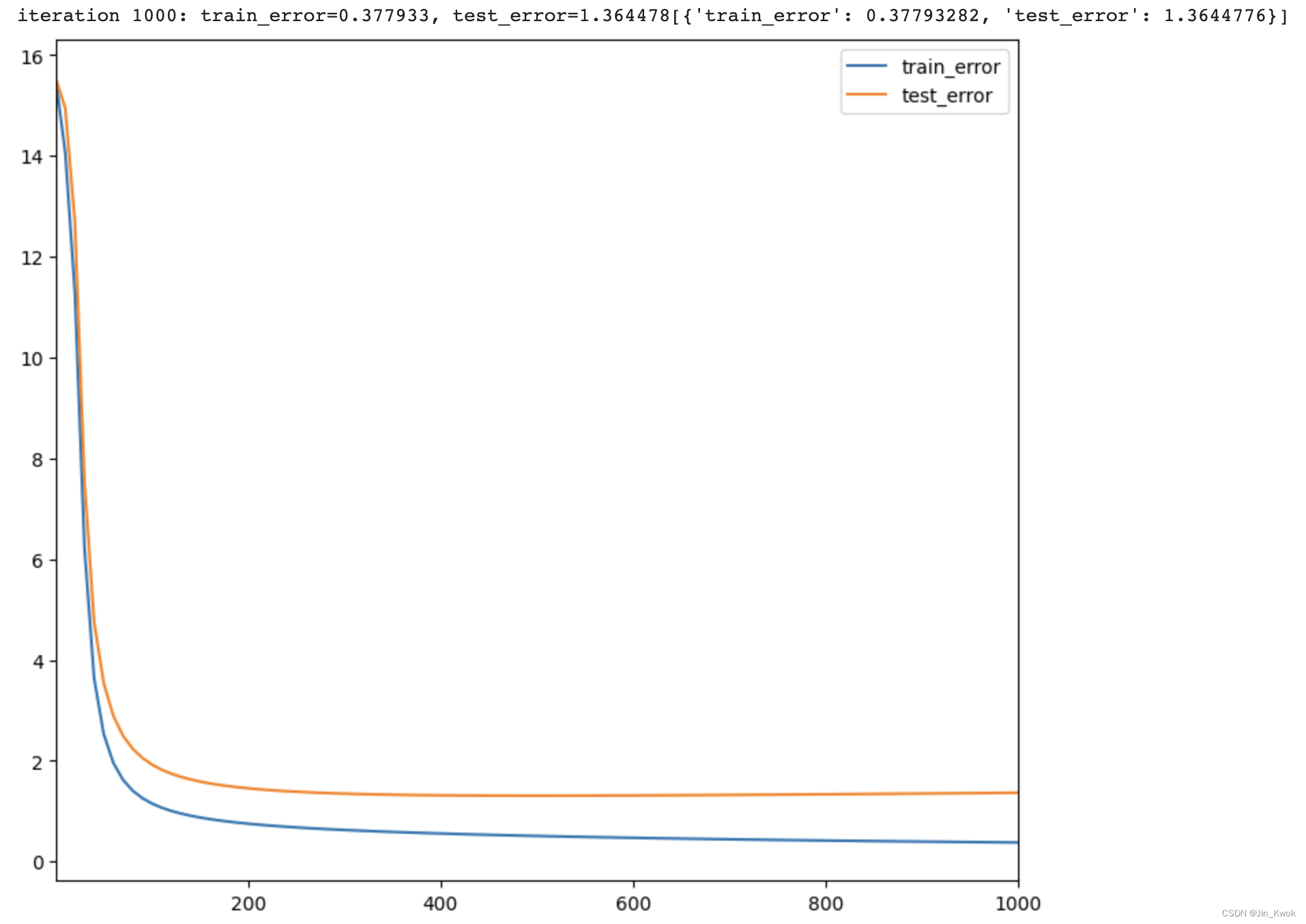
执行如下代码,尝试不同的参数(嵌入维度、学习率、迭代)。训练和测试误差在训练结束时绘制。同时,我们可以检查这些值以验证超参数。
# 创建 CF model 并执行训练
model = build_model(ratings, embedding_dim=30, init_stddev=0.5)
model.train(num_iterations=1000, learning_rate=10.)运行结果如下:
4.检查嵌入件
在本节中,我们会检查嵌入,具体而言,包括:
- 计算你的推荐
- 查看一些电影最近的邻居(相似的电影)
4.1 编写一个计算候选电影评分的函数
我们首先编写一个函数,在给定查询嵌入 和 Item嵌入
的情况下, 计算 Item 得分。正如之前文章所介绍的,我们可以使用不同的相似性度量,这些度量可以产生不同的结果。在此,我们将比较以下内容:
- 点积: Item j 的评分为
- 余弦: Item j 的评分为
相关代码如下所示:
DOT = 'dot'
COSINE = 'cosine'
def compute_scores(query_embedding, item_embeddings, measure=DOT):
"""Computes the scores of the candidates given a query.
Args:
query_embedding: a vector of shape [k], representing the query embedding.
item_embeddings: a matrix of shape [N, k], such that row i is the embedding
of item i.
measure: a string specifying the similarity measure to be used. Can be
either DOT or COSINE.
Returns:
scores: a vector of shape [N], such that scores[i] is the score of item i.
"""
u = query_embedding
V = item_embeddings
if measure == COSINE:
V = V / np.linalg.norm(V, axis=1, keepdims=True)
u = u / np.linalg.norm(u)
scores = u.dot(V.T)
return scores4.2 用户推荐和最近的邻居(相似 Item 和 User)
# 定义推荐函数
def user_recommendations(model, measure=DOT, exclude_rated=False, k=6):
if USER_RATINGS:
scores = compute_scores(
model.embeddings["user_id"][943], model.embeddings["movie_id"], measure)
score_key = measure + ' score'
df = pd.DataFrame({
score_key: list(scores),
'movie_id': movies['movie_id'],
'titles': movies['title'],
'genres': movies['all_genres'],
})
if exclude_rated:
# remove movies that are already rated
rated_movies = ratings[ratings.user_id == "943"]["movie_id"].values
df = df[df.movie_id.apply(lambda movie_id: movie_id not in rated_movies)]
display.display(df.sort_values([score_key], ascending=False).head(k))
# 定义寻找指定电影“邻居(相似电影)”的函数
def movie_neighbors(model, title_substring, measure=DOT, k=6):
# 根据指定字符串 title_substring 搜索电影.
ids = movies[movies['title'].str.contains(title_substring)].index.values
titles = movies.iloc[ids]['title'].values
if len(titles) == 0:
raise ValueError("Found no movies with title %s" % title_substring)
print("Nearest neighbors of : %s." % titles[0])
if len(titles) > 1:
print("[Found more than one matching movie. Other candidates: {}]".format(
", ".join(titles[1:])))
movie_id = ids[0]
scores = compute_scores(
model.embeddings["movie_id"][movie_id], model.embeddings["movie_id"],
measure)
score_key = measure + ' score'
df = pd.DataFrame({
score_key: list(scores),
'titles': movies['title'],
'genres': movies['all_genres']
})
display.display(df.sort_values([score_key], ascending=False).head(k))执行以下代码,可以查看与电影《Little Princess》相似电影。替换“Little Princess”,可以查看与其他指定电影相似的电影。
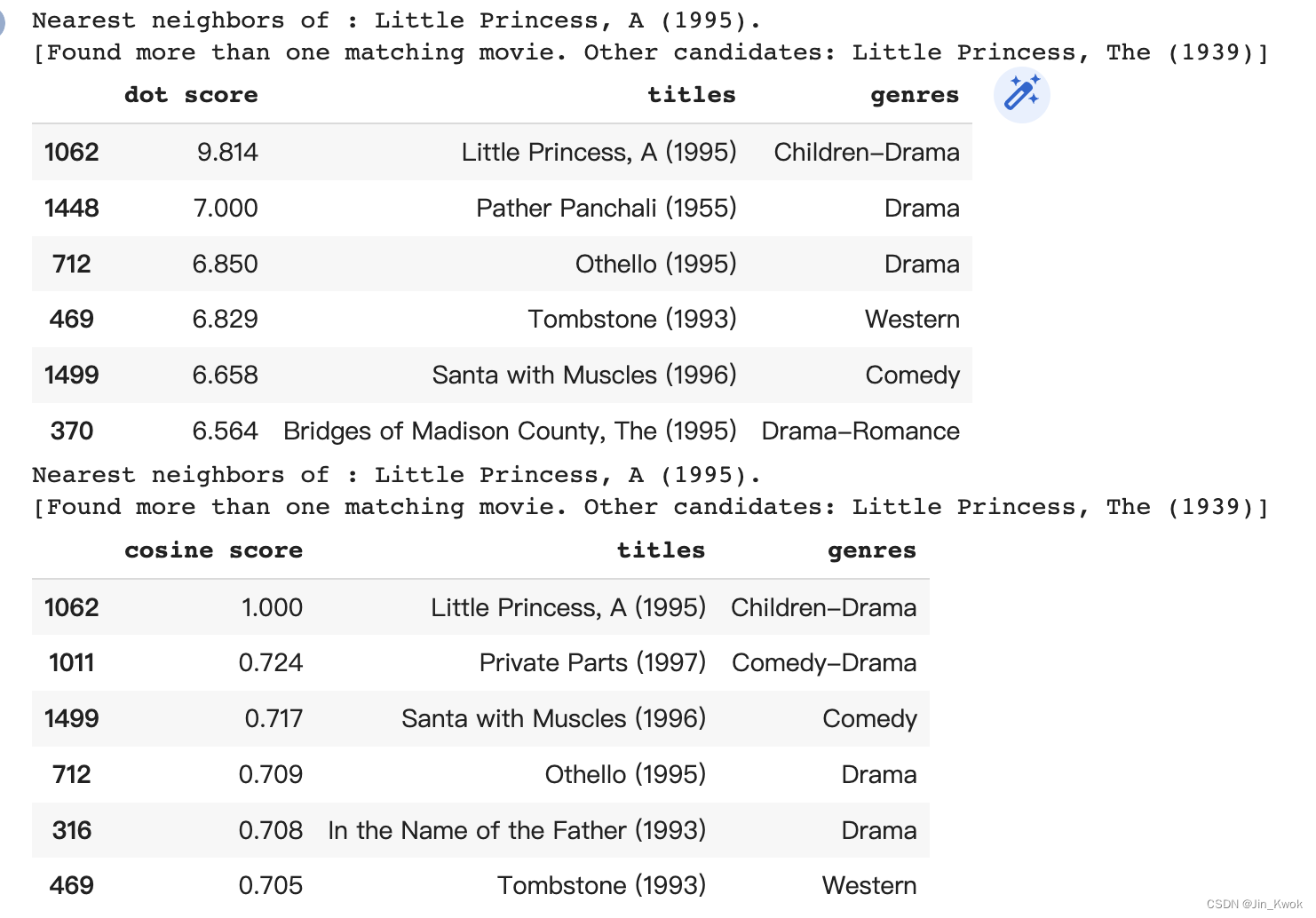
movie_neighbors(model, "Little Princess", DOT)
movie_neighbors(model, "Little Princess", COSINE)执行结果如下:
5.矩阵分解中的正则化
在上一节中,我们的损失被定义为评级矩阵中观察部分的均方误差。正如讲座中所讨论的,这可能会有问题,因为模型没有学会如何处理无关电影(没有观察到的电影)的嵌入。这种现象被称为折叠。在本节,我们将添加正则化术语来解决这个问题。我们将使用两种类型的正则化:

5.1 建立正则化矩阵分解模型并对其进行训练
编写一个函数来构建正则化(规范化)模型。给定一个函数 gravity(U,V),该函数计算给定两个嵌入矩阵的重力项 𝑈 和 𝑉 .
# 定义函数 gravity
def gravity(U, V):
"""基于给定两个嵌入矩阵,创建重力损失."""
return 1. / (U.shape[0].value*V.shape[0].value) * tf.reduce_sum(
tf.matmul(U, U, transpose_a=True) * tf.matmul(V, V, transpose_a=True))
# 定义规范化模型构建函数
def build_regularized_model(
ratings, embedding_dim=3, regularization_coeff=.1, gravity_coeff=1.,
init_stddev=0.1):
"""
Args:
ratings: the DataFrame of movie ratings.
embedding_dim: The dimension of the embedding space.
regularization_coeff: The regularization coefficient lambda.
gravity_coeff: The gravity regularization coefficient lambda_g.
Returns:
A CFModel object that uses a regularized loss.
"""
# Split the ratings DataFrame into train and test.
train_ratings, test_ratings = split_dataframe(ratings)
# SparseTensor representation of the train and test datasets.
A_train = build_rating_sparse_tensor(train_ratings)
A_test = build_rating_sparse_tensor(test_ratings)
U = tf.Variable(tf.random_normal(
[A_train.dense_shape[0], embedding_dim], stddev=init_stddev))
V = tf.Variable(tf.random_normal(
[A_train.dense_shape[1], embedding_dim], stddev=init_stddev))
error_train = sparse_mean_square_error(A_train, U, V)
error_test = sparse_mean_square_error(A_test, U, V)
gravity_loss = gravity_coeff * gravity(U, V)
regularization_loss = regularization_coeff * (
tf.reduce_sum(U*U)/U.shape[0].value + tf.reduce_sum(V*V)/V.shape[0].value)
total_loss = error_train + regularization_loss + gravity_loss
losses = {
'train_error_observed': error_train,
'test_error_observed': error_test,
}
loss_components = {
'observed_loss': error_train,
'regularization_loss': regularization_loss,
'gravity_loss': gravity_loss,
}
embeddings = {"user_id": U, "movie_id": V}
return CFModel(embeddings, total_loss, [losses, loss_components])基于上面的代码,可以训练正则化模型了!可以尝试不同的正则化系数值和不同的嵌入维度。示例代码如下:
reg_model = build_regularized_model(
ratings, regularization_coeff=0.1, gravity_coeff=1.0, embedding_dim=35,
init_stddev=.05)
reg_model.train(num_iterations=2000, learning_rate=20.)可以观察到,在训练集和测试集上,添加正则化项会导致更高的 MSE。然而,正如我们将看到的那样,模型预测的质量有所提高。这突出了拟合观测数据和最小化正则化项之间的紧张关系。拟合观察到的数据通常强调学习高相似度(在具有许多交互的 Item 之间),但良好的嵌入表示也需要学习低相似度(在很少或没有交互的 Item 间)。
进一步,我们可以查看指定电影(Item)的相似电影。这里以 “Aladdin” 为例,示例代码如下:
movie_neighbors(reg_model, "Aladdin", DOT)
movie_neighbors(reg_model, "Aladdin", COSINE)6.Softmax模型
在本节中,我们将训练一个简单的 softmax 模型,该模型预测给定用户是否对电影进行了评分。该模型将采用一个特征向量 𝑥 作为输入表示用户已经评定的电影的列表。我们从评分 DataFrame 开始,我们根据 user_id 对其进行分组。
rated_movies = (ratings[["user_id", "movie_id"]]
.groupby("user_id", as_index=False)
.aggregate(lambda x: list(x)))
rated_movies.head()然后,我们创建一个函数来生成一个示例批,这样每个示例都包含以下特征:
- movie_id:用户评分的电影 id 字符串的张量
- genre:这些电影流派的一个张量
- year:发行年份字符串的张量
years_dict = {
movie: year for movie, year in zip(movies["movie_id"], movies["year"])
}
genres_dict = {
movie: genres.split('-')
for movie, genres in zip(movies["movie_id"], movies["all_genres"])
}
def make_batch(ratings, batch_size):
"""Creates a batch of examples.
Args:
ratings: A DataFrame of ratings such that examples["movie_id"] is a list of
movies rated by a user.
batch_size: The batch size.
"""
def pad(x, fill):
return pd.DataFrame.from_dict(x).fillna(fill).values
movie = []
year = []
genre = []
label = []
for movie_ids in ratings["movie_id"].values:
movie.append(movie_ids)
genre.append([x for movie_id in movie_ids for x in genres_dict[movie_id]])
year.append([years_dict[movie_id] for movie_id in movie_ids])
label.append([int(movie_id) for movie_id in movie_ids])
features = {
"movie_id": pad(movie, ""),
"year": pad(year, ""),
"genre": pad(genre, ""),
"label": pad(label, -1)
}
batch = (
tf.data.Dataset.from_tensor_slices(features)
.shuffle(1000)
.repeat()
.batch(batch_size)
.make_one_shot_iterator()
.get_next())
return batch
def select_random(x):
"""Selectes a random elements from each row of x."""
def to_float(x):
return tf.cast(x, tf.float32)
def to_int(x):
return tf.cast(x, tf.int64)
batch_size = tf.shape(x)[0]
rn = tf.range(batch_size)
nnz = to_float(tf.count_nonzero(x >= 0, axis=1))
rnd = tf.random_uniform([batch_size])
ids = tf.stack([to_int(rn), to_int(nnz * rnd)], axis=1)
return to_int(tf.gather_nd(x, ids))
6.1 损失函数
回想一下,softmax 模型映射了输入特征 𝑥 到用户嵌入 𝜓(𝑥)∈ℝ𝑑 。其中,𝑑 是嵌入维度。然后将该向量乘以电影嵌入矩阵 𝑉∈ℝ𝑚×𝑑 (其中 𝑚 是电影的数量),模型的最终输出是产品的 softmax
给定目标标签 , 如果我们用表示
对这个目标标签进行一次热编码,则损失是之间的交叉熵
和
.
6.2 为softmax模型编写一个损失函数
# 定义损失函数
def softmax_loss(user_embeddings, movie_embeddings, labels):
"""Returns the cross-entropy loss of the softmax model.
Args:
user_embeddings: A tensor of shape [batch_size, embedding_dim].
movie_embeddings: A tensor of shape [num_movies, embedding_dim].
labels: A tensor of [batch_size], such that labels[i] is the target label
for example i.
Returns:
The mean cross-entropy loss.
"""
# Verify that the embddings have compatible dimensions
user_emb_dim = user_embeddings.shape[1].value
movie_emb_dim = movie_embeddings.shape[1].value
if user_emb_dim != movie_emb_dim:
raise ValueError(
"The user embedding dimension %d should match the movie embedding "
"dimension % d" % (user_emb_dim, movie_emb_dim))
logits = tf.matmul(user_embeddings, movie_embeddings, transpose_b=True)
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=logits, labels=labels))
return loss6.3 建立一个softmax模型,对其进行训练,并检查其嵌入
本节将构建一个 softmax CFModel。实现 build_softmax_model 函数。该模型的体系结构在函数create_user_embeddings 中定义,如下图所示。输入嵌入(movie_id, genre and year)被连接起来形成输入层,然后我们有隐藏层,其维度由 hidden_dims 参数指定。最后,将最后一个隐藏层乘以电影嵌入,以获得 logits 层。对于目标标签,我们将使用用户评分的电影列表中随机采样的movie_id。
# 定义softmax模型构建函数
def build_softmax_model(rated_movies, embedding_cols, hidden_dims):
"""Builds a Softmax model for MovieLens.
Args:
rated_movies: DataFrame of traing examples.
embedding_cols: A dictionary mapping feature names (string) to embedding
column objects. This will be used in tf.feature_column.input_layer() to
create the input layer.
hidden_dims: int list of the dimensions of the hidden layers.
Returns:
A CFModel object.
"""
def create_network(features):
"""Maps input features dictionary to user embeddings.
Args:
features: A dictionary of input string tensors.
Returns:
outputs: A tensor of shape [batch_size, embedding_dim].
"""
# Create a bag-of-words embedding for each sparse feature.
inputs = tf.feature_column.input_layer(features, embedding_cols)
# Hidden layers.
input_dim = inputs.shape[1].value
for i, output_dim in enumerate(hidden_dims):
w = tf.get_variable(
"hidden%d_w_" % i, shape=[input_dim, output_dim],
initializer=tf.truncated_normal_initializer(
stddev=1./np.sqrt(output_dim))) / 10.
outputs = tf.matmul(inputs, w)
input_dim = output_dim
inputs = outputs
return outputs
train_rated_movies, test_rated_movies = split_dataframe(rated_movies)
train_batch = make_batch(train_rated_movies, 200)
test_batch = make_batch(test_rated_movies, 100)
with tf.variable_scope("model", reuse=False):
# Train
train_user_embeddings = create_network(train_batch)
train_labels = select_random(train_batch["label"])
with tf.variable_scope("model", reuse=True):
# Test
test_user_embeddings = create_network(test_batch)
test_labels = select_random(test_batch["label"])
movie_embeddings = tf.get_variable(
"input_layer/movie_id_embedding/embedding_weights")
test_loss = softmax_loss(
test_user_embeddings, movie_embeddings, test_labels)
train_loss = softmax_loss(
train_user_embeddings, movie_embeddings, train_labels)
_, test_precision_at_10 = tf.metrics.precision_at_k(
labels=test_labels,
predictions=tf.matmul(test_user_embeddings, movie_embeddings, transpose_b=True),
k=10)
metrics = (
{"train_loss": train_loss, "test_loss": test_loss},
{"test_precision_at_10": test_precision_at_10}
)
embeddings = {"movie_id": movie_embeddings}
return CFModel(embeddings, train_loss, metrics)6.4 训练Softmax模型
基于前面的准备,本节开始训练softmax模型。我们可以设置以下超参数:
- 学习率
- 迭代次数
- 输入嵌入维度(input_dims 参数)
- 隐藏层的数量和每个层的大小(hidden_dims参数)
# 定义特征嵌入函数
def make_embedding_col(key, embedding_dim):
categorical_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=key, vocabulary_list=list(set(movies[key].values)), num_oov_buckets=0)
return tf.feature_column.embedding_column(
categorical_column=categorical_col, dimension=embedding_dim,
# default initializer: trancated normal with stddev=1/sqrt(dimension)
combiner='mean')
with tf.Graph().as_default():
softmax_model = build_softmax_model(
rated_movies,
embedding_cols=[
make_embedding_col("movie_id", 35),
make_embedding_col("genre", 3),
make_embedding_col("year", 2),
],
hidden_dims=[35])
# 训练模型
softmax_model.train(
learning_rate=8., num_iterations=3000, optimizer=tf.train.AdagradOptimizer)此外,我们还可以通过执行如下代码来可视化嵌入和查看与指定电影的最邻近(最相似)的电影:
movie_neighbors(softmax_model, "Aladdin", DOT)
movie_neighbors(softmax_model, "Aladdin", COSINE)
movie_embedding_norm([reg_model, softmax_model])
tsne_movie_embeddings(softmax_model)7.参考文献
链接-https://developers.google.cn/machine-learning/recommendation/labs/movie-rec-programming-exercise