1、微服务下现存的各种问题
服务调用问题
当两个服务调用时,可以通过传统的HTTP方式,让服务A直接去调用服务B的接口,但是这种方式是同步的方式,虽然可以采用SpringBoot提供的@Async注解实现异步调用,但是这种方式无法确保请求一定回访问到服务B的接口。那如何保证服务A的请求信息一定能送达到服务B去完成一些业务操作呢?
海量请求问题
在做一些秒杀业务时,可能会在某个时间点突然出现大量的并发请求,这可能已经远远超过服务器的并发瓶颈,这时就需要做一些削峰的操作。也就是将大量的请求缓冲到一个队列中,然后慢慢的消费掉。如何提供一个可以存储千万级别请求的队列呢?
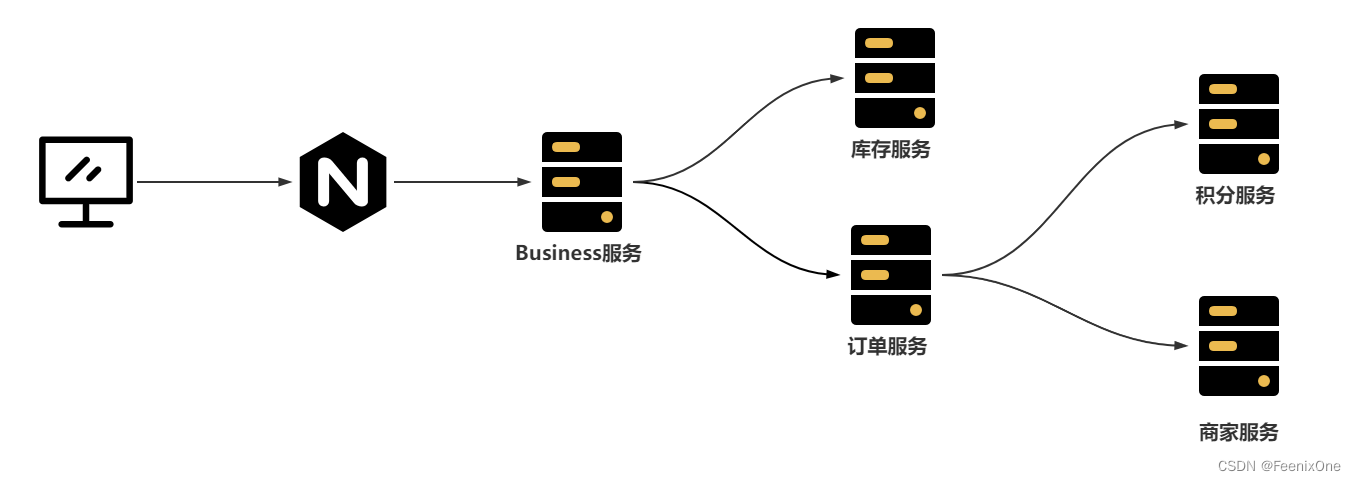
服务解耦问题
在微服务架构下,可能一个业务会出现同时调用多个其他服务的场景,而且这些服务之间一般会用到Feign的方式进行轻量级的通讯。如果存在一个业务,用户创建订单成功后,还需要去给用户添加积分、通知商家、通知物流系统、扣减商品库存,而在执行这个操作时,如果任意一个服务出现了问题,都会导致整体的下单业务失败,并且会导致给用户反馈的时间延长。这时就造成了服务之间存在一个较高的耦合性的问题。如何可以降低服务之间的耦合性呢?
消息中间件的引入
RabbitMQ就可以解决上述的全部问题:
对于服务调用问题来说,服务之间想实现可靠的异步调用,可以通过RabbitMQ的方式实现,服务A只需要保证可以把消息发送到RabbitMQ的队列中,服务B就一定会消费到队列中的消息,只不过会存在一定的延时。

对于海量请求问题来说,忽然的海量请求可以存储在RabbitMQ的队列中,然后由消费者慢慢消费掉,RabbitMQ的队列本身就可以存储上千万条消息。
对于服务解耦问题来说,在调用其它服务时,如果允许延迟效果的出现,可以将消息发送到RabbitMQ中,再由消费者慢慢消费。

那么问题来了,
2、RabbitMQ是什么
Rabbit科技有限公司开发了RabbitMQ,并提供对其的支持。起初,Rabbit科技是LSHIFT和CohesiveFT在2007年成立的合资企业,2010年4月被VMware旗下的SpringSource收购,RabbitMQ在2013年5月成为GoPivotal的一部分。RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件),RabbitMQ服务是用以高性能、健壮以及可伸缩性出名的Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的,所有主要的编程语言均有与代理接口通讯的客户端库。
AMQP协议,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
RabbitMQ官网对AMQP协议做了非常细致的描述:消息被发布到交换中心,这通常被比作邮局或邮箱。交易所然后使用称为绑定的规则将消息副本分配给队列。然后,经纪人或者将消息传递给订阅队列的消费者,或者消费者按要求从队列中获取/拉取消息。
在发布消息时,发布者可以指定各种消息属性(消息元数据)。这些元数据中的一部分可能会被代理者使用,然而,其余的部分对代理者来说是完全不透明的,只被接收消息的应用程序使用。
网络是不可靠的,应用程序可能无法处理消息,因此AMQP模型有一个消息确认的概念:当一个消息被交付给消费者时,消费者会通知经纪人,可以是自动的,也可以是应用程序开发人员选择的尽快通知。当消息确认被使用时,经纪人只有在收到该消息(或一组消息)的通知时,才会从队列中完全删除该消息。
在某些情况下,例如,当消息不能被路由时,消息可能被退回给发布者,被丢弃,或者,如果经纪人实现了一个扩展,则被放入所谓的 "死信队列"。发布者通过使用某些参数发布消息来选择如何处理这样的情况。队列、交换和绑定被统称为AMQP实体。
而从语言角度来说,Erlang在1991年由爱立信公司向用户推出了第一个版本,经过不断的改进完善和发展,在1996年爱立信又为所有的Erlang用户提供了一个非常实用且稳定的OTP软件库并在1998年发布了第一个开源版本。Erlang同时支持的操作系统有linux,windows,unix等,可以说适用于主流的操作系统上,尤其是它支持多核的特性非常适合多核CPU,而分布式特性也可以很好融合各种分布式集群。
说人话就是Erlang很适合去深度的挖掘CPU性能,从性能角度来说远远高于Java语言,可以简单的认为,在众多的消息中间件之中,RabbitMQ的延迟是最低的,可以达到微秒级别。而像Kafka、RocketMQ只能做到毫秒级别(当然,它们的优势在其它方面),延迟极低。
RabbitMQ支持的语言也特别多,主流的Java、Python等都提供对应的API,支持海量的插件去实现一些特殊功能,甚至还自带了图形化管理界面,即便用户不会编程都没关系,可以直接通过图形管理界面去发送消息,操作异常简单。
3、RabbitMQ架构
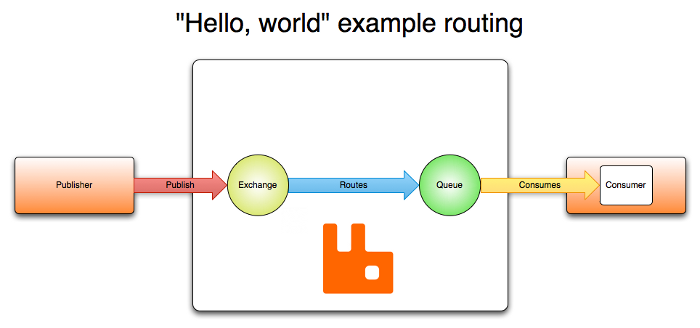
正如上面所说,RabbitMQ本质上就是AMQP协议的开源实现,那么通过上面从官网粘贴的AMQP架构图可以看出RabbitMQ中主要分为三个角色:
- Publisher:消息的发布者,将消息发布到RabbitMQ中的Exchange;
- RabbitMQ服务:Exchange接收Publisher的消息,并且根据Routes策略将消息转发到Queue中;
- Consumer:消息的消费者,监听Queue中的消息并进行消费;
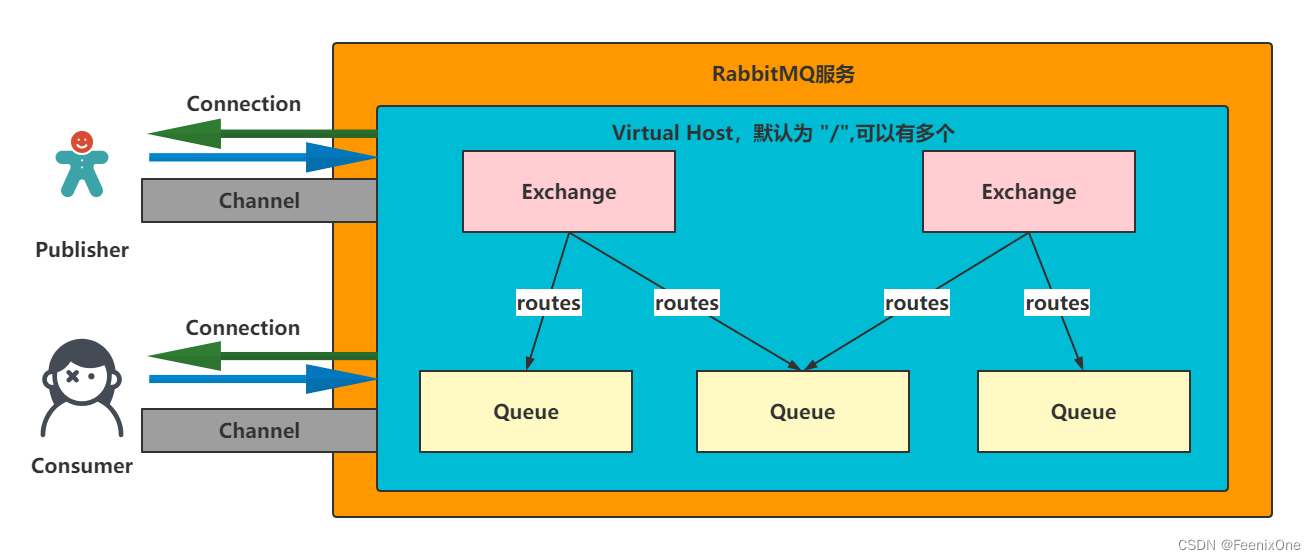
可以看出Publisher和Consumer都是单独和RabbitMQ服务中某一个Virtual Host建立Connection的客户端,后续通过Connection可以构建Channel通道,用来发布、接收消息。一个Virtual Host中可以有多个Exchange和Queue,Exchange可以同时绑定多个Queue。
基于上面的架构图了解后,再来看RabbitMQ的图形化管理界面(图形化界面的查看需要先安装好RabbitMQ服务,关于RabbitMQ服务的安装、启动和相关配置等,可以参考我写的这一篇:https://blog.csdn.net/FeenixOne/article/details/128124004),就会更加清晰:
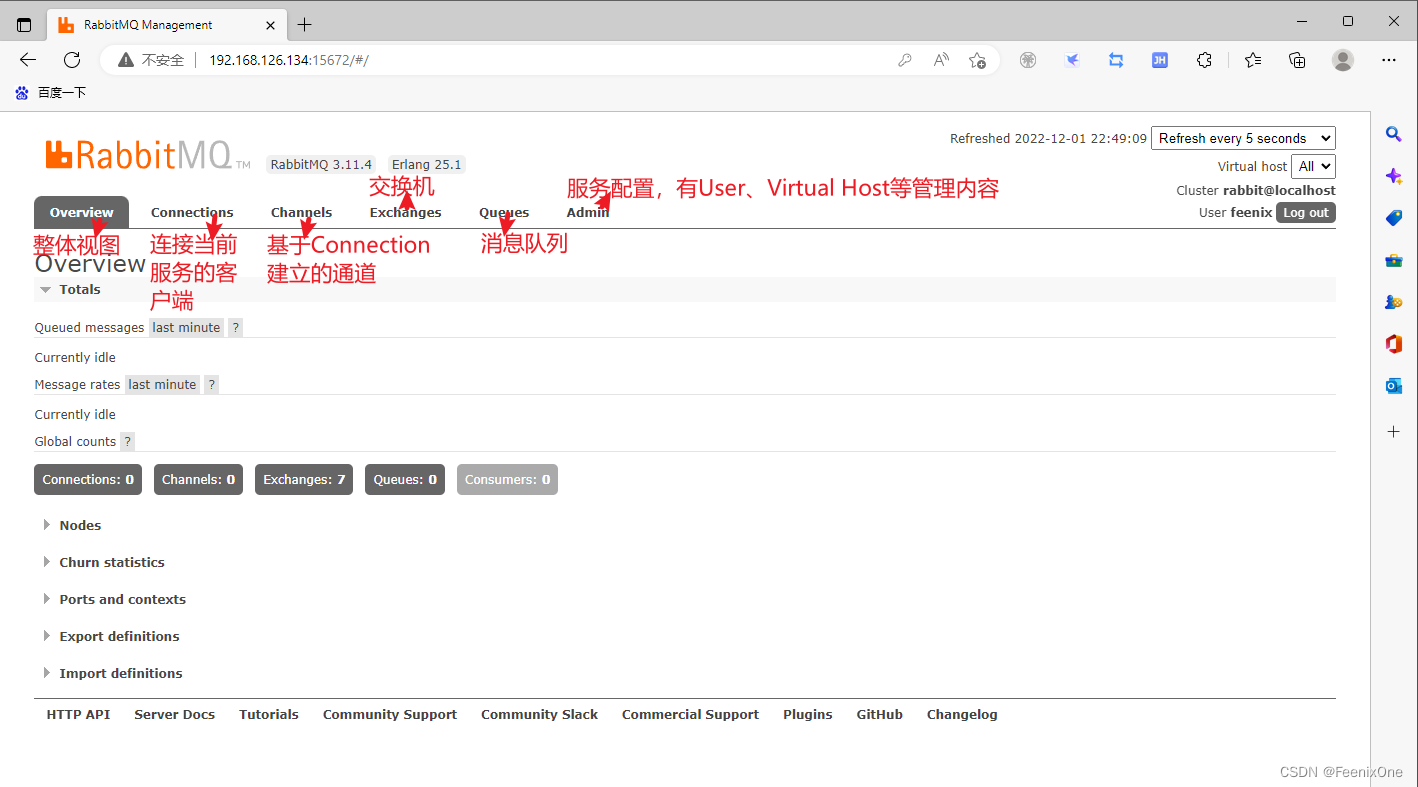
可以看到目前还没有任何的客户端连接到RabbitMQ服务
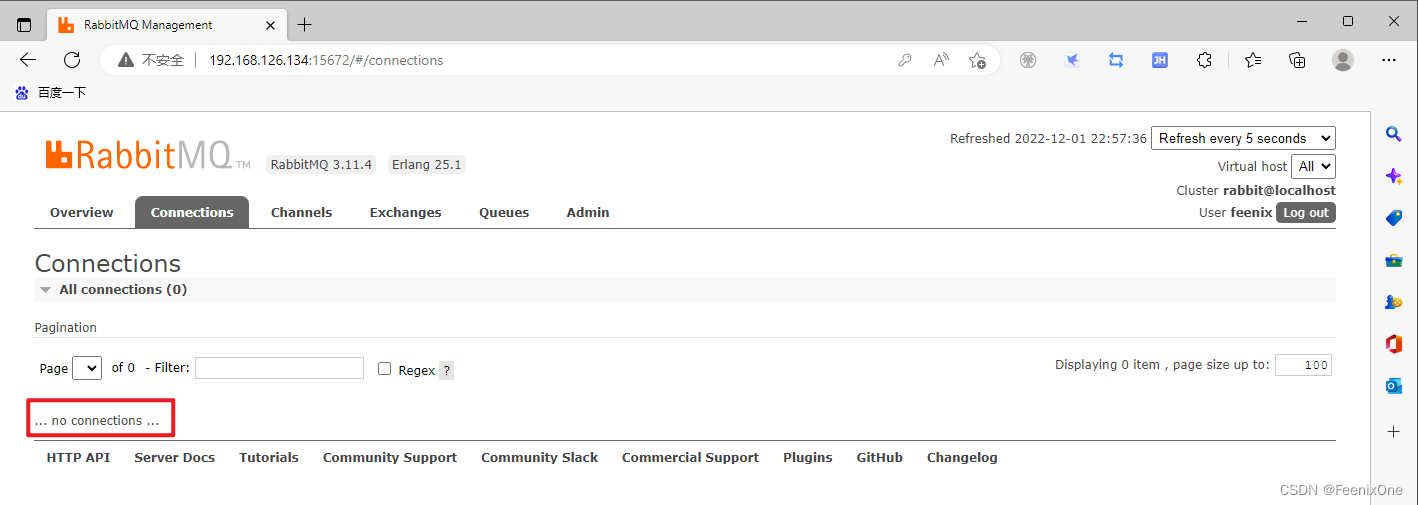
那么没有Connection,自然也不会有Channel,因为Channel是基于Connection创建的

而即便是全新安装好的RabbitMQ服务,还没有任何使用,也会提供默认的exchange交换机

消息队列也是空的,还没有产生任何的消息在队列中

这里用户有两个,一个是RabbitMQ服务自带的guest用户,一个是自己创建的feenix用户,二者都是管理员角色,不过自带的guest用户不支持远程登录。
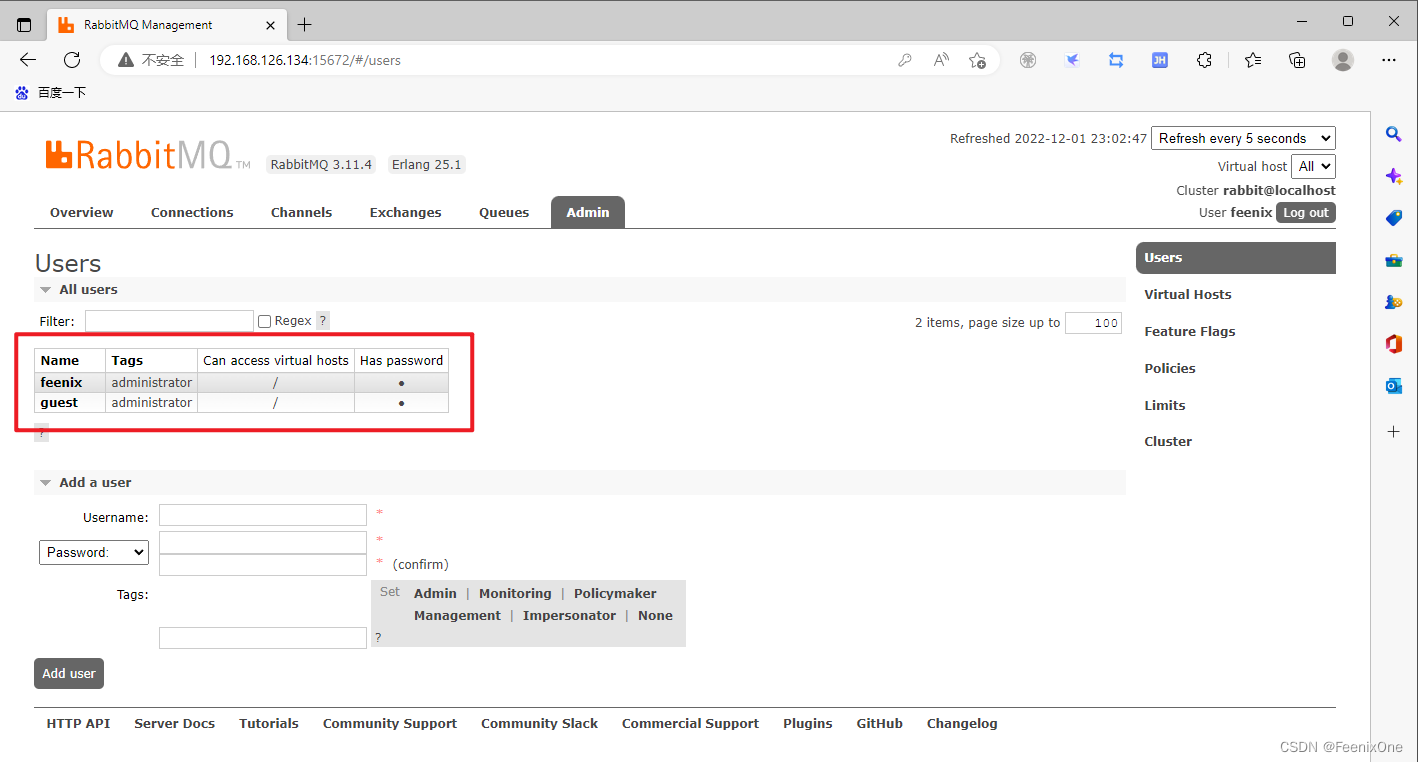
两个用户都属于 "/" Virtual Host,如果说想让两个服务之间通过MQ进行通信,就需要在同一个Virtual Host下。比如企业中经常会创建test用于测试,dev用于开发。
4、RabbitMQ通讯方式
在RabbitMQ的官网文档中,一共提供了7种通讯方式:https://rabbitmq.com/getstarted.html
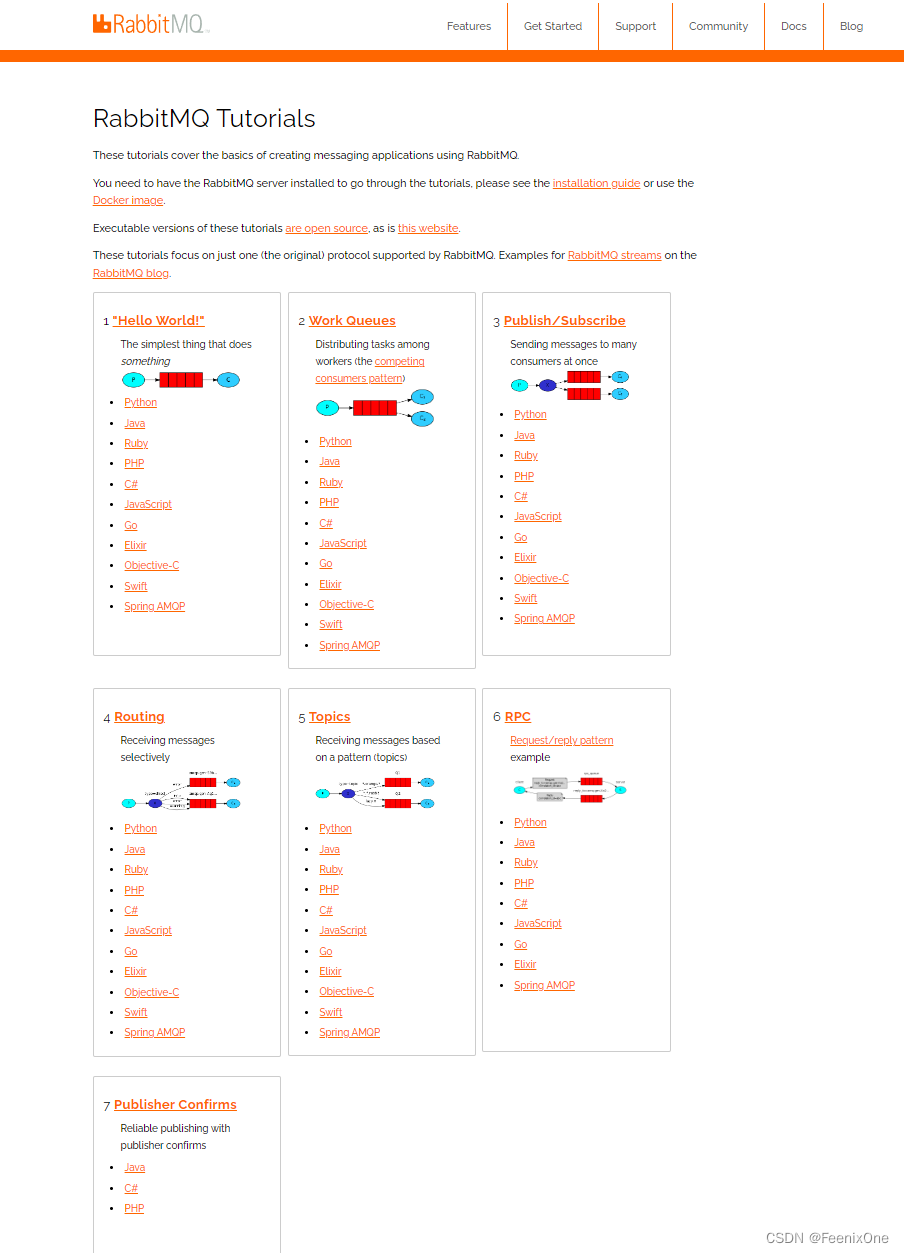
先来创建一个简单的maven工程,引入相关依赖

构建Connection工具类,RabbitMQ提供了一个工厂模式去协助创建Connection对象

Hello World - 操作入门

生产者


执行publish方法,消息发送成功之后,来到RabbitMQ的图形界面,可以看到此时有一个Connection连接正在连接着
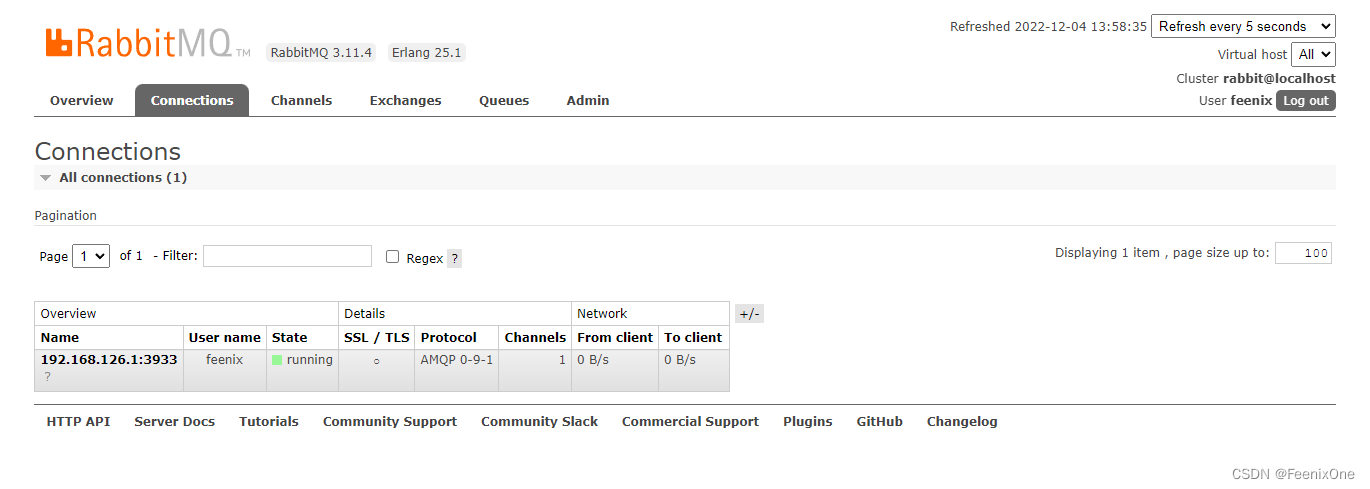
其次,基于Connection也创建了一个通道

此时这条消息也由默认的Exchange路由到了对应的队列中,现在就有了一个"hello"的队列,并且队列中有一个消息已经准备好了,等待着被消费
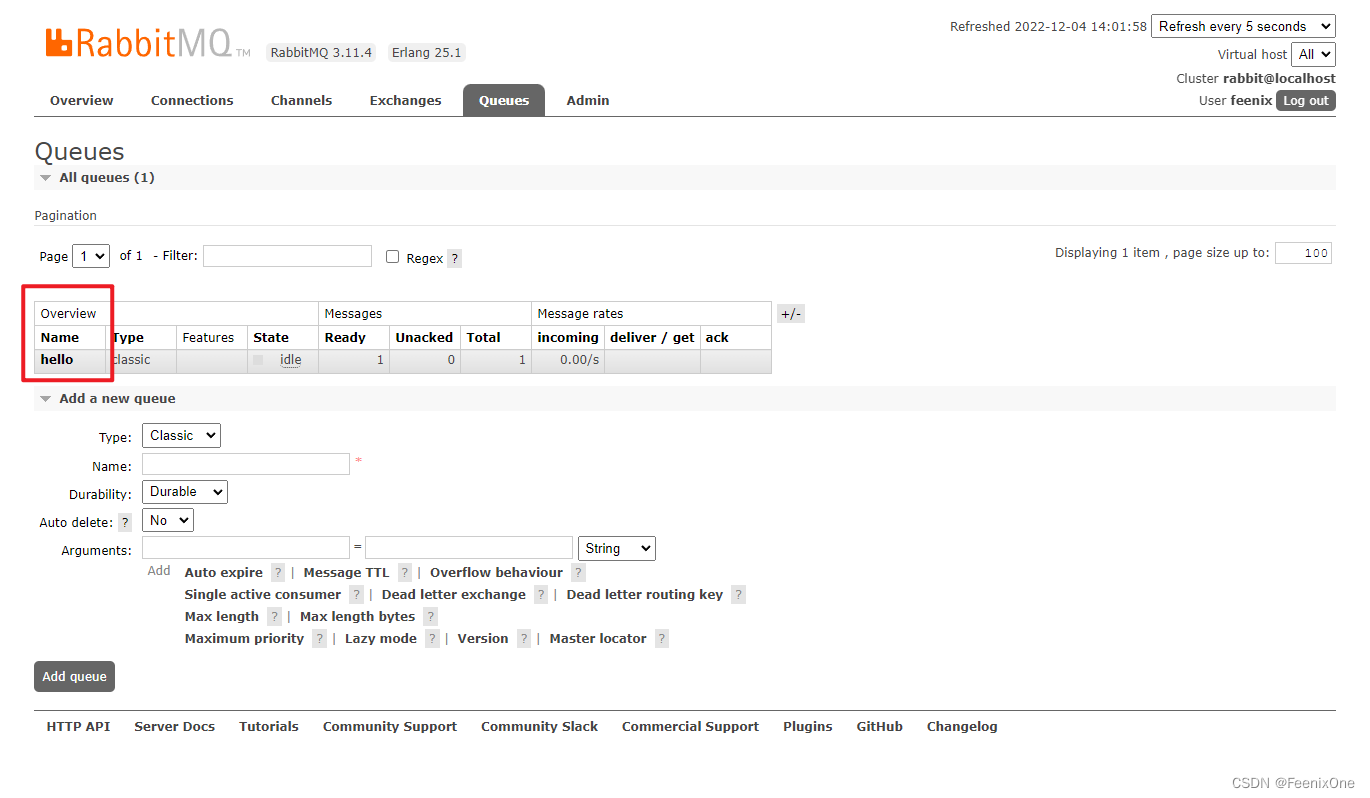
消费者
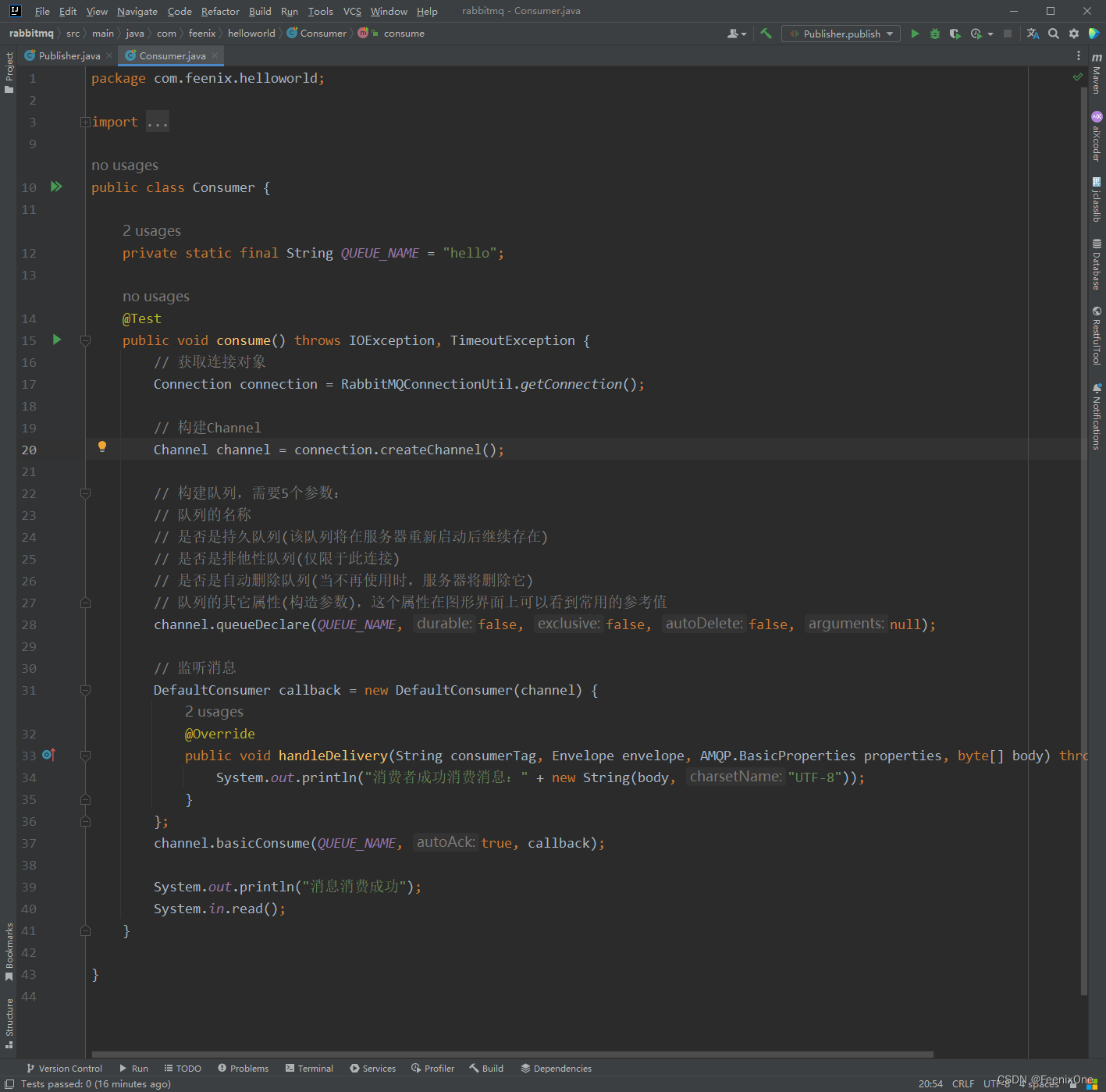
无论是生产者还是消费者,都建议将队列的构建显示声明出来。因为消息只要到了队列中才不会丢,对于生产者来说,要确保消息到了队列中;对于消费者来说,要监听这个队列,没有这个队列就报错。所以无论生产者还是消费者都要去声明队列,即便这个队列在双方声明了两次。
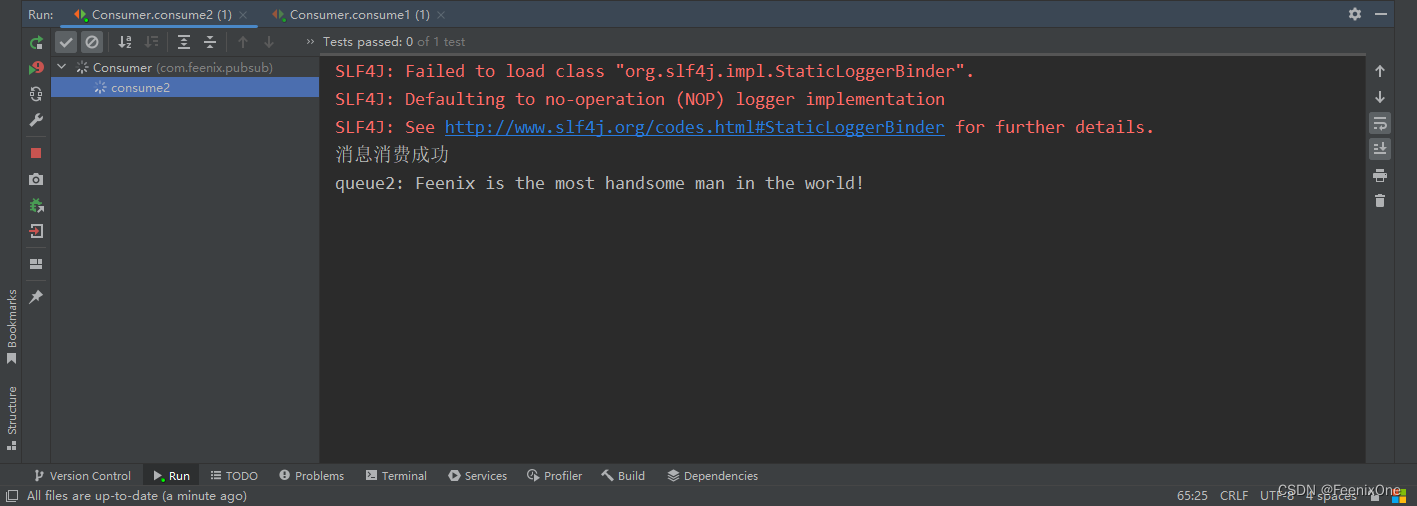
执行consume方法,在控制台直接输出监听到的消息内容
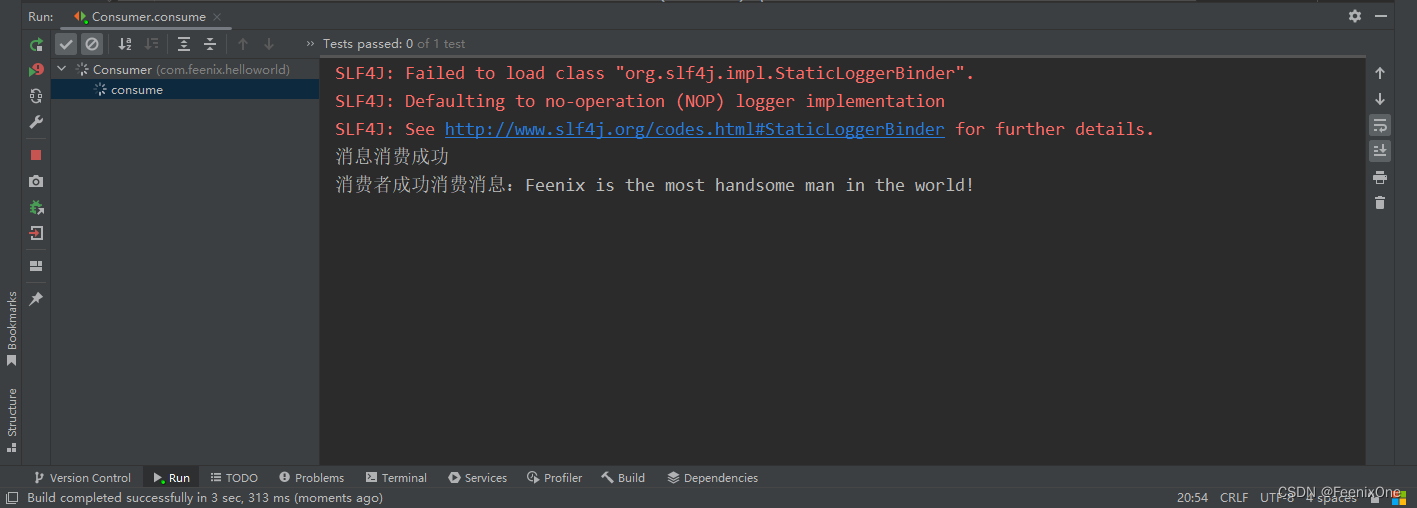
来到RabbitMQ的图形界面,可以看到之前队列中的消息已经被消费
Work Queues - 一个队列被多个消费者消费
生产者
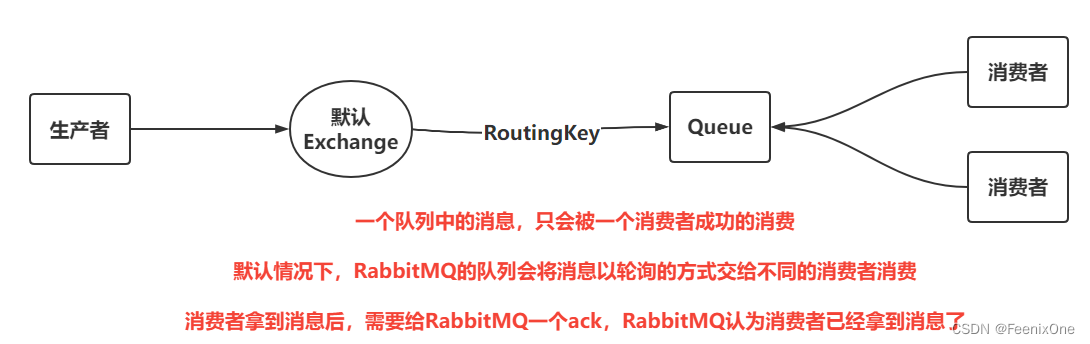
生产者和 Hello World 方式一致,都是将消息推送到默认交换机。执行生产者中的方法,连续生产10条消息,然后在消费者这边开两个监听同时对生产者进行消费
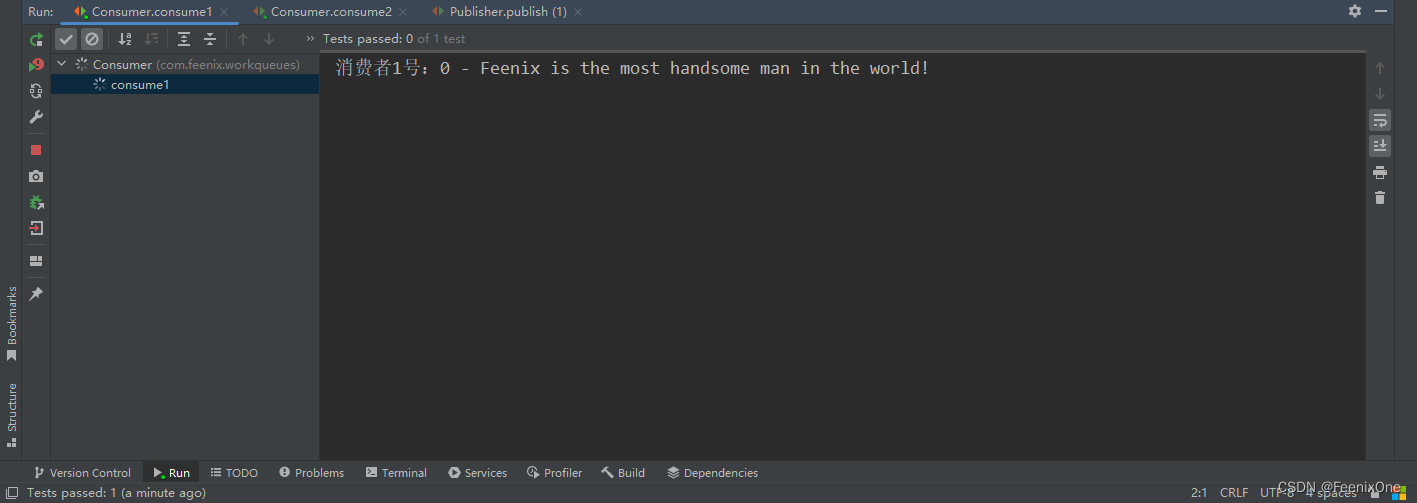
可以看到,在默认情况下以轮询的方式在不同的消费者之间进行消费
消费者
但是实际环境中,不容服务的对于业务的处理效率必然不一致,有的时间较长,有的时间较短。这就导致在轮询的时候,不能将更多的消息交给处理效率高的服务去更多消费。如果想要消费者也做到能者多劳的话,就得将消费中的autoAck参数设置为false,并进行相关的设置:

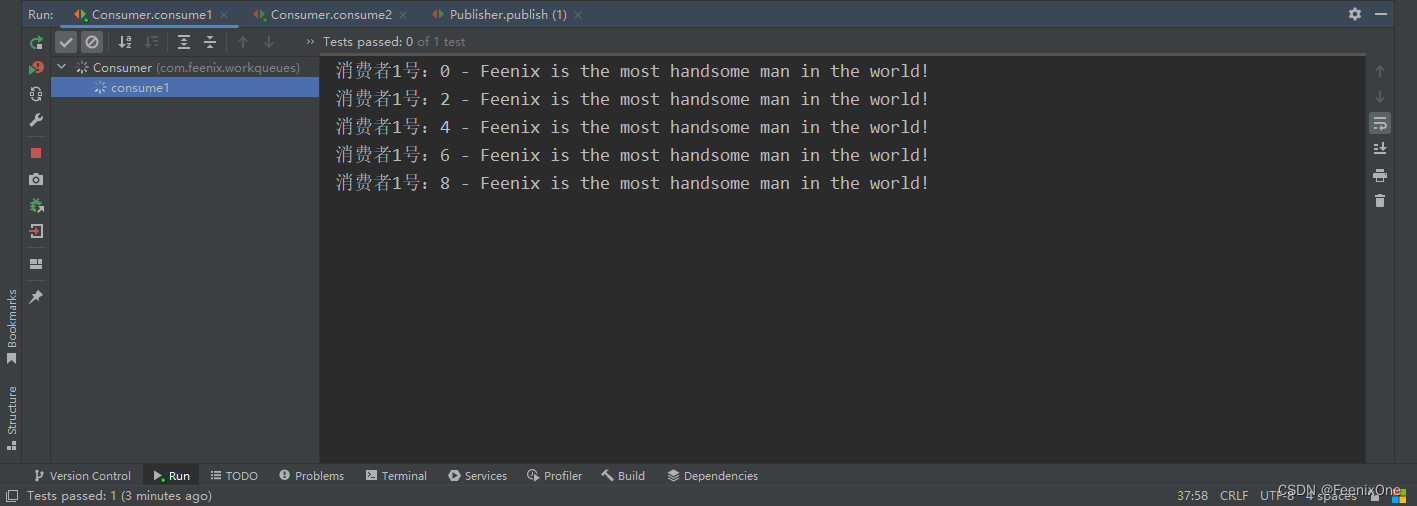
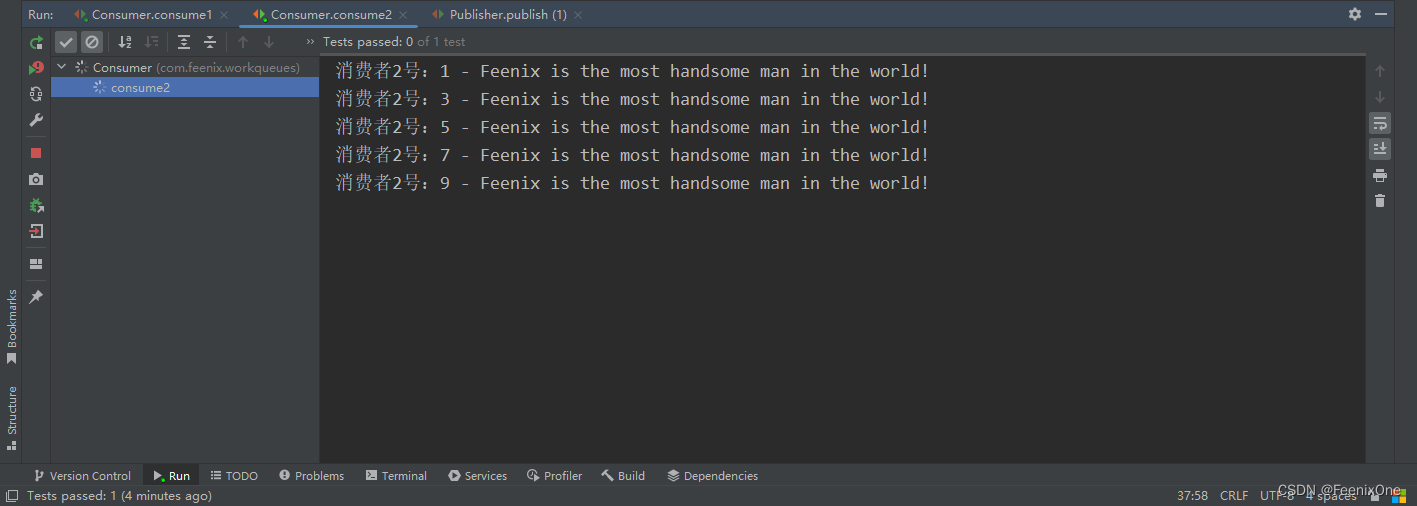
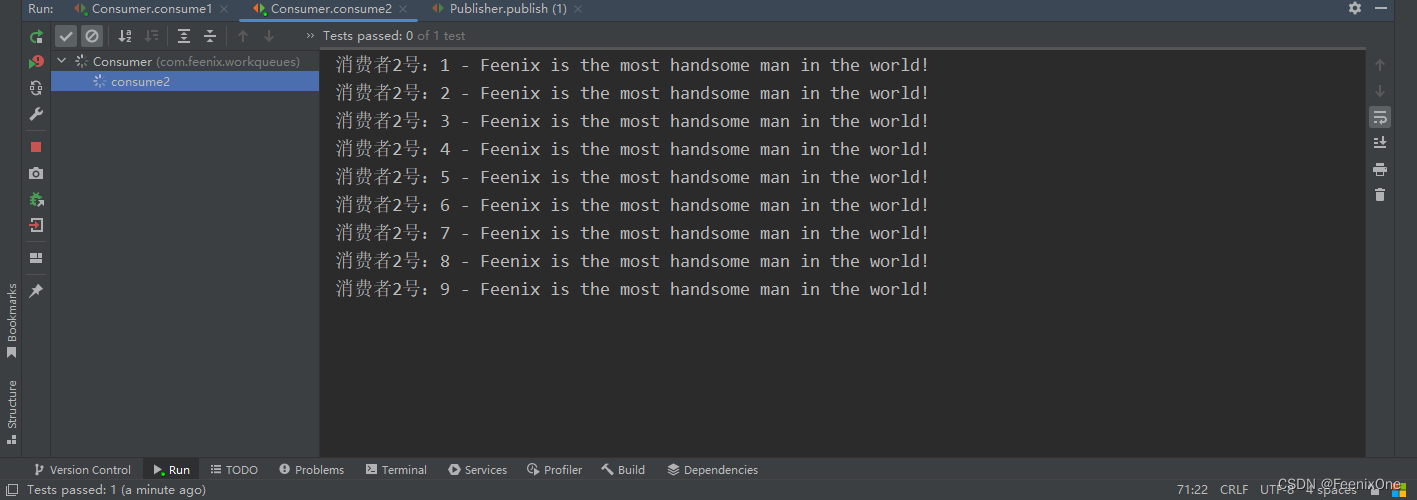
消费者2号的流程和消费者1号完全一致,只是模拟的时间稍久一些
可以看到,消费者1号只是消费了1条消息,其余的消息都别消费者2号消费
Publish/Subsribe - 手动创建Exchange(FANOUT)

生产者

生产者消息成功发送之后,可以看到Exchange列表多了一个对应的FANOUT类型的交换机(Exchange和Queue之间是直接绑定的关系,所以routingKey没啥用,随便写)
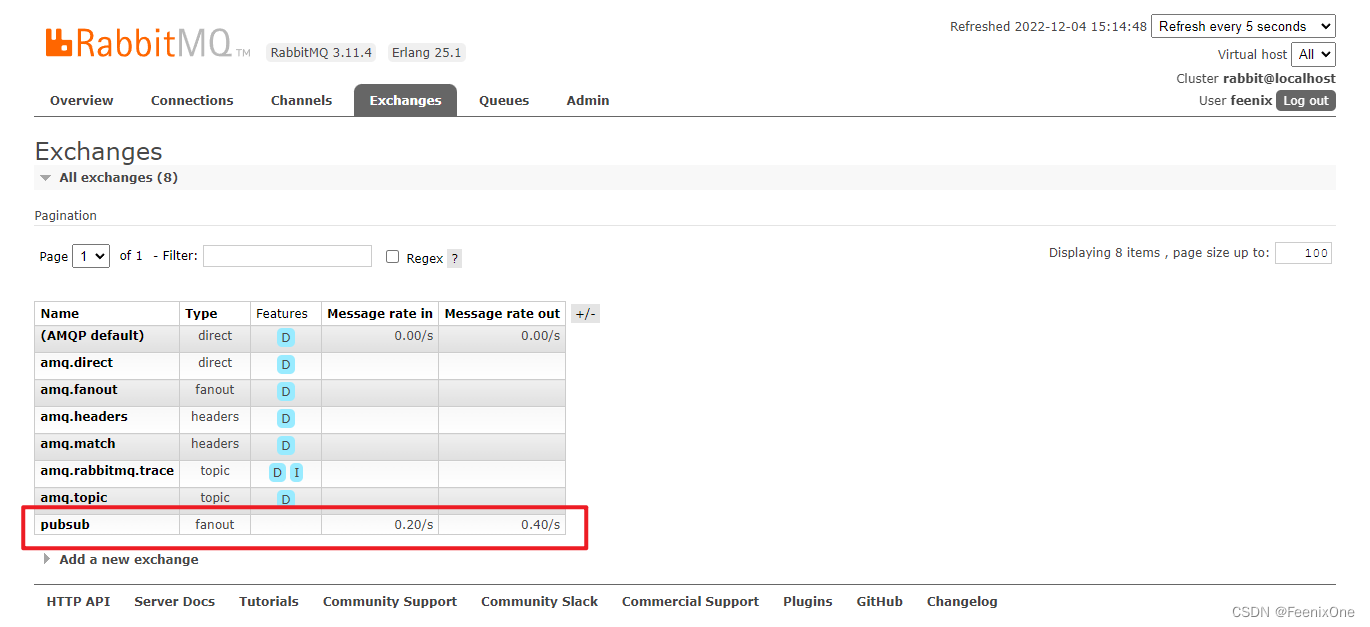
并且对绑定上的两个队列,都分别推送了一条消息等待消费
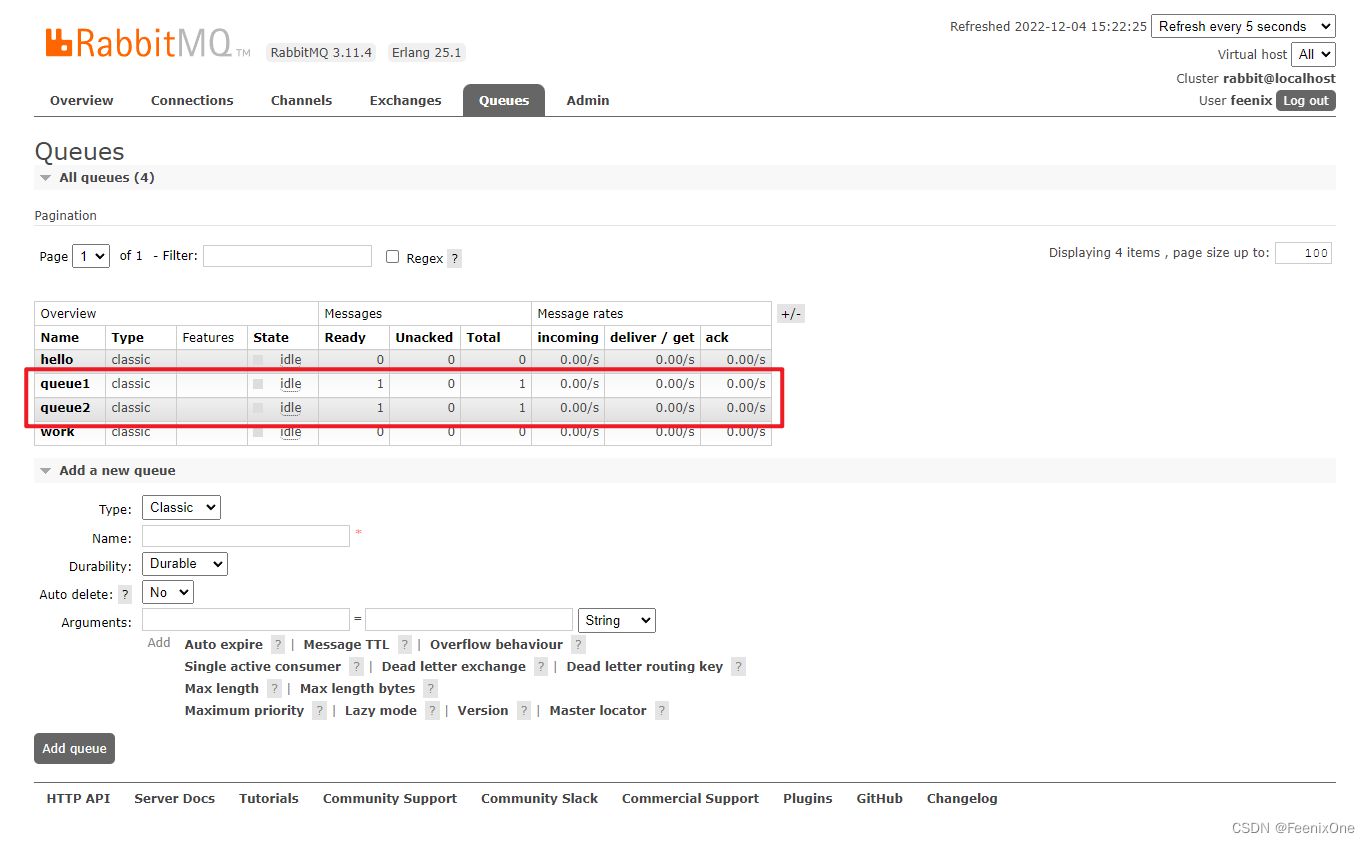
两个队列中的消费者分别消费成功消息

Routing - 手动创建Exchange(DIRECT)
生产者
在绑定Exchange和Queue时,需要指定好routingKey;同时在发送消息时,也需指定routingKey,只有routingKey一致时,才会把指定的消息路由到指定的Queue。
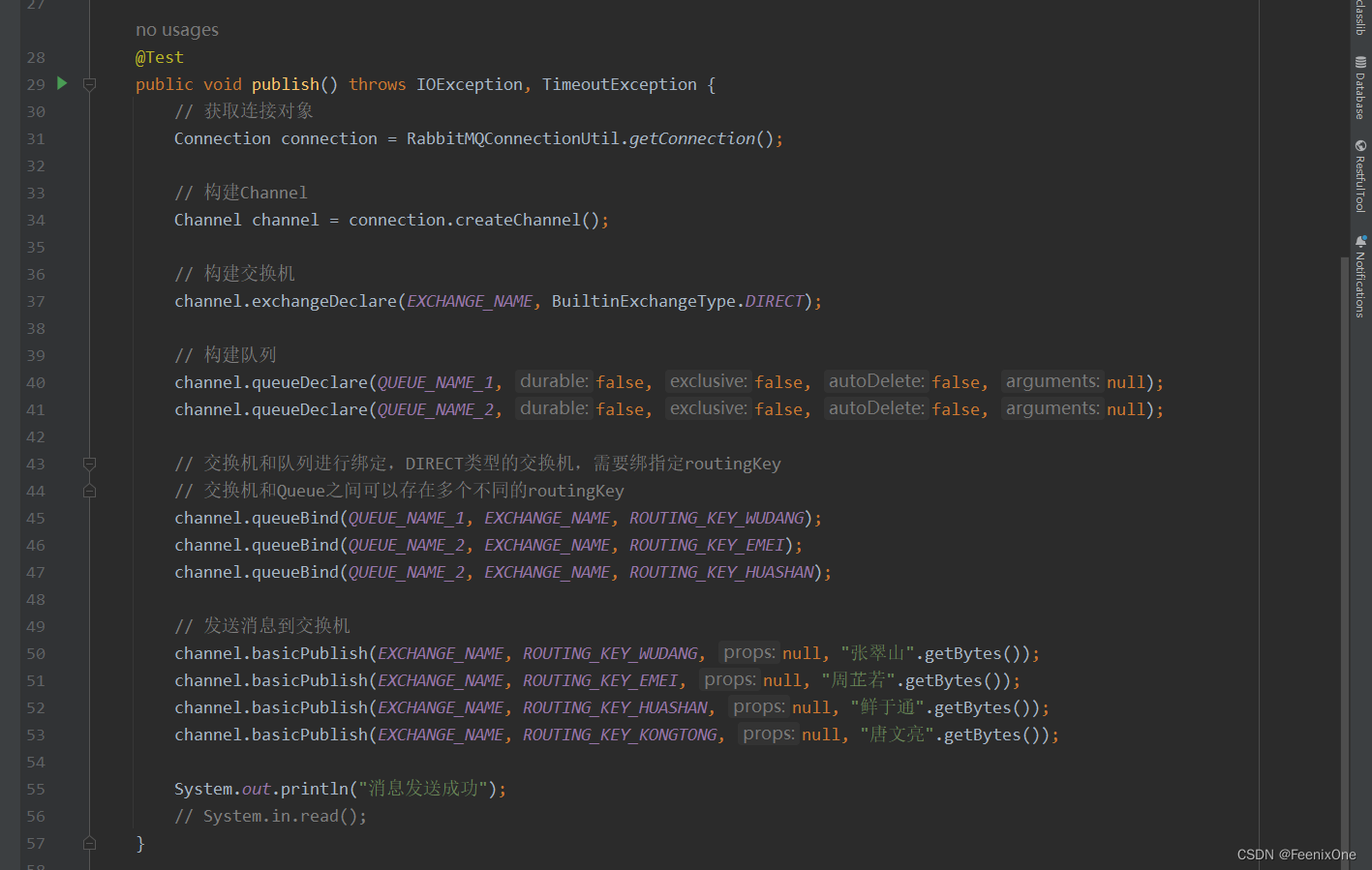
Exchange和Queue之间绑定了三种routingKey,但是消息推送到交换机后指定了四种routingKey,所以未绑定routingKey的消息必然是进不了Queue中的。
生产者消息发送成功之后,Exchange列表新增一个direct类型的交换机
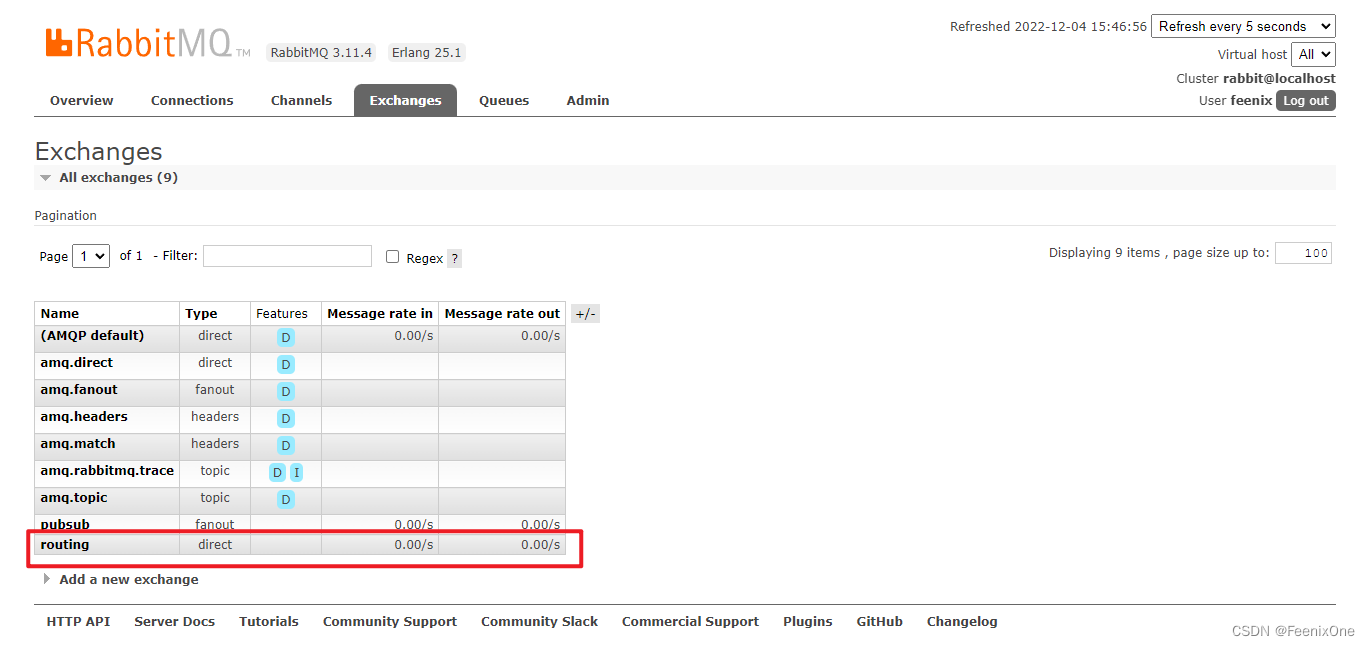
Queues列表新增两个队列
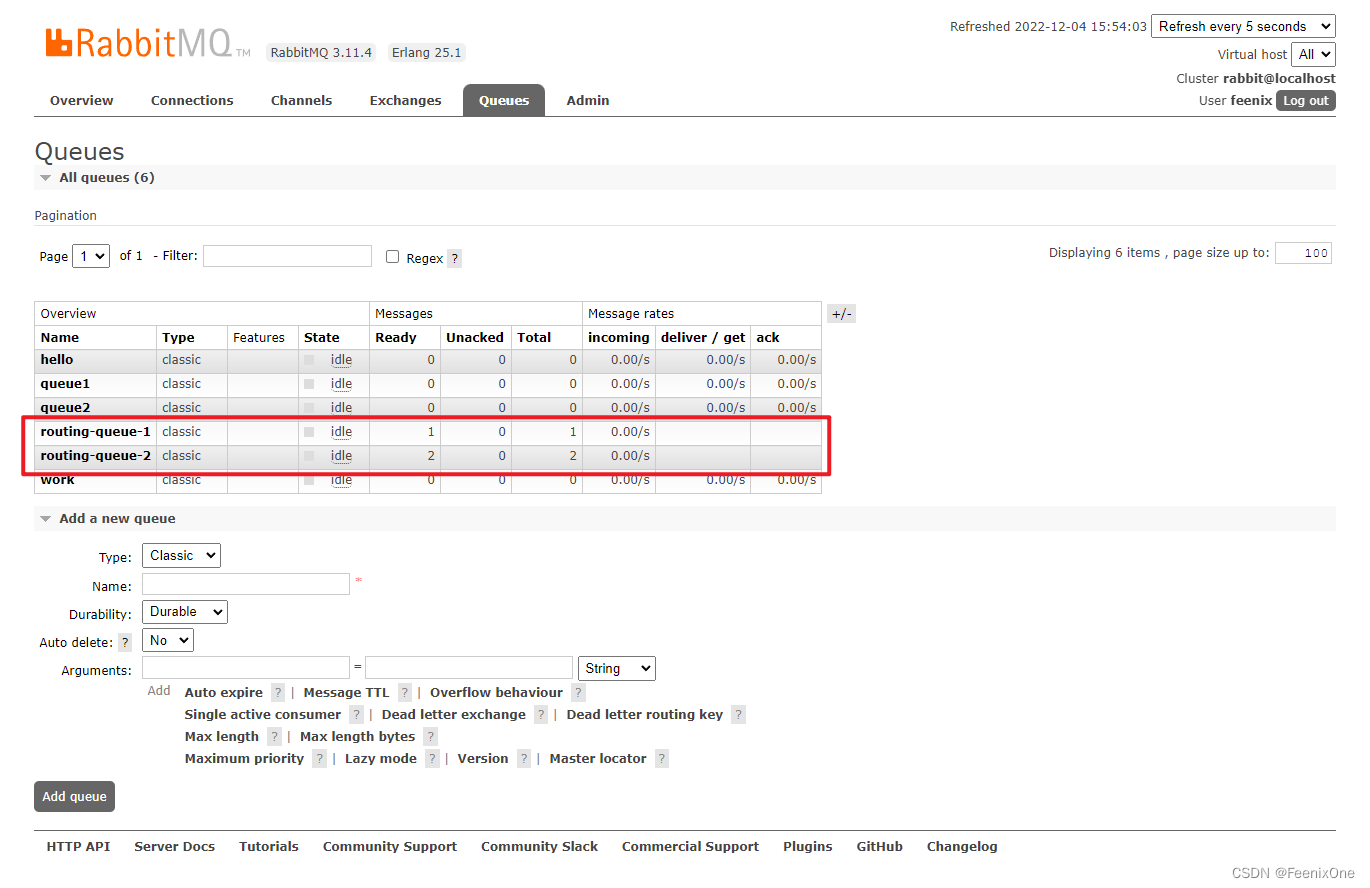
两个队列中的消费者分别消费成功消息

Topics - 手动创建Exchange(TOPIC)
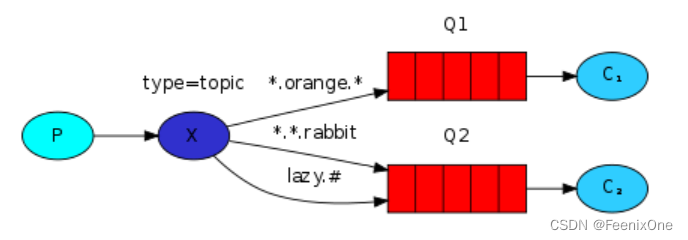
生产者
TOPIC类型可以编写带有特殊意义的routingKey的绑定方式。值得一提的是,* 是占位符,# 才是通配符。根据规则,绑定的时候使用特殊符号指代,消息推送的时候再使用具体的名称即可。
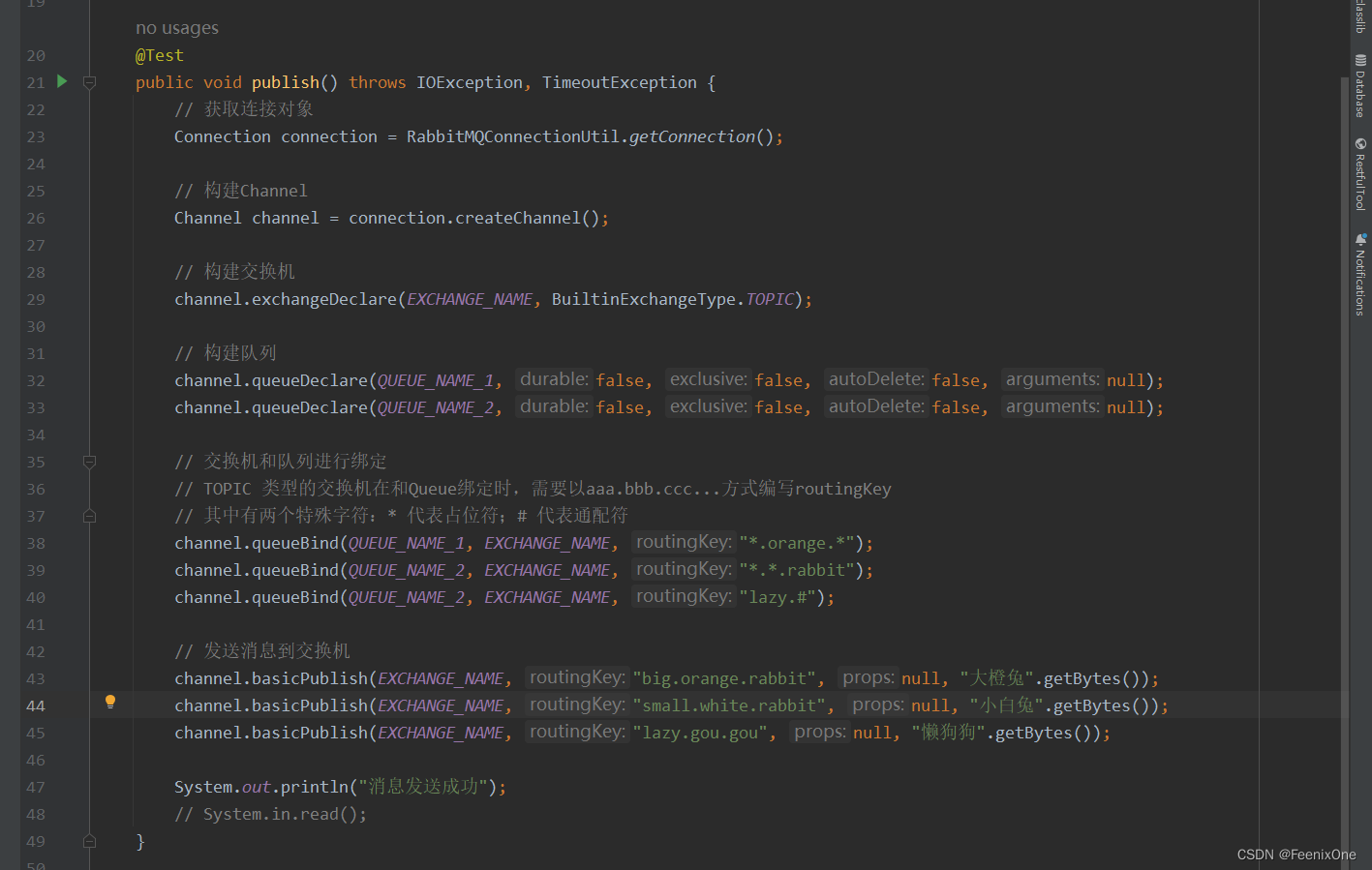
生产者消息发送成功之后,Exchange列表新增一个direct类型的交换机
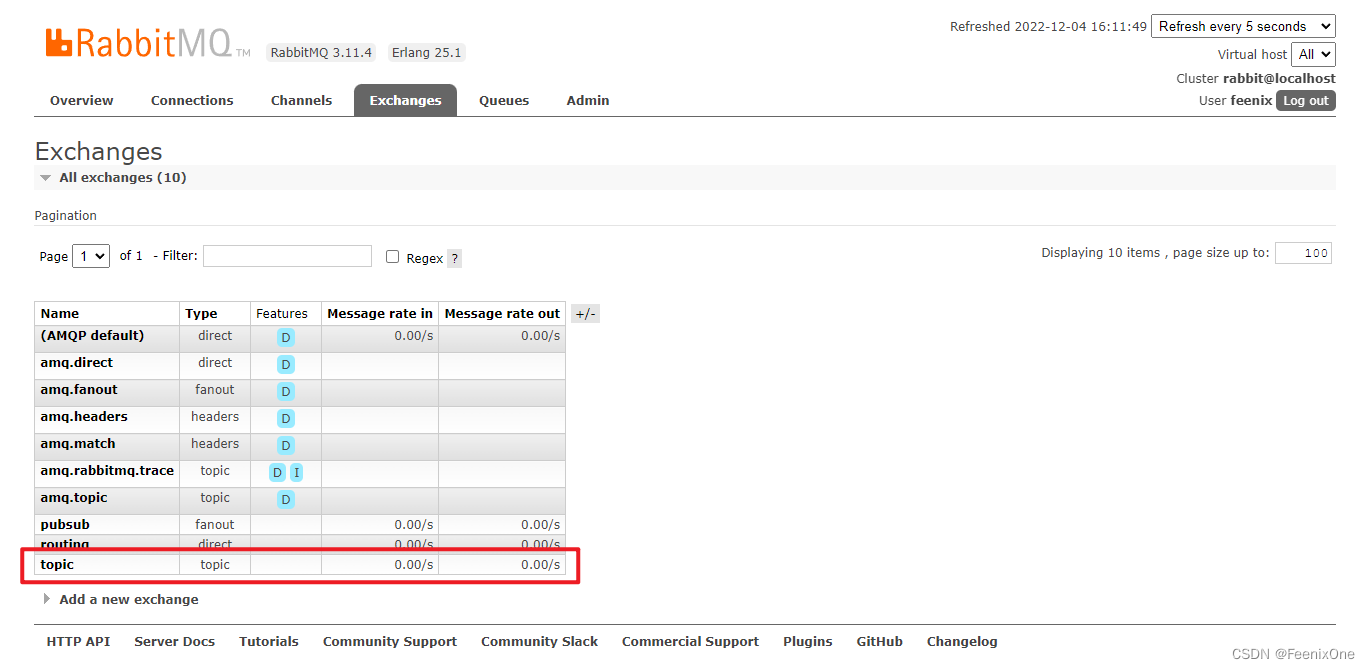
Queues列表新增两个队列,关键在于,队列1中只有1条数据,队列2中有3条数据,完全符合绑定时指定的routingKey规则
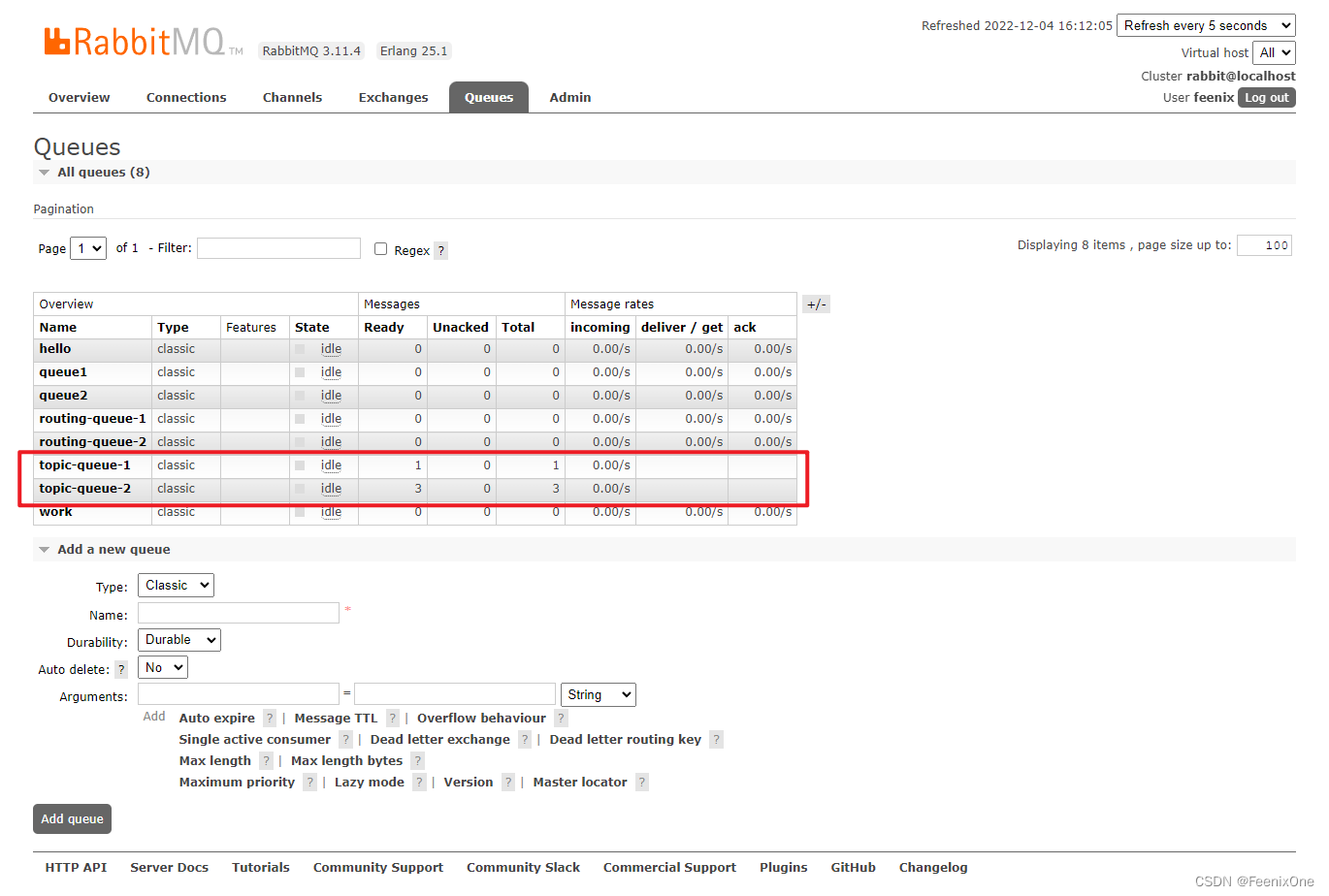
两个队列中的消费者分别消费成功消息
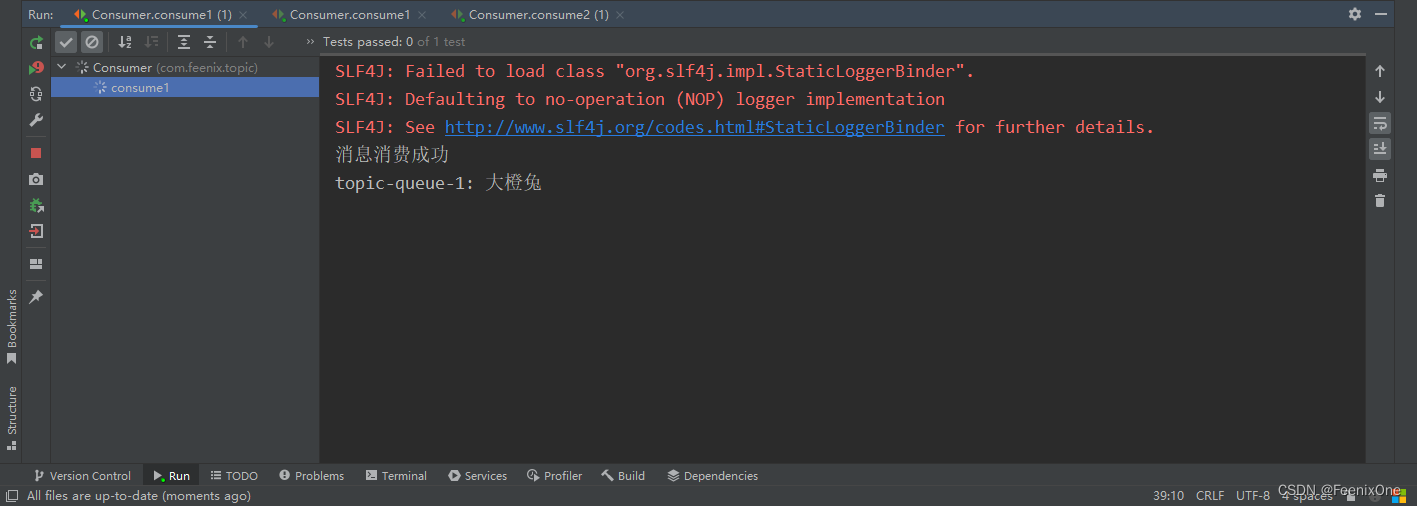
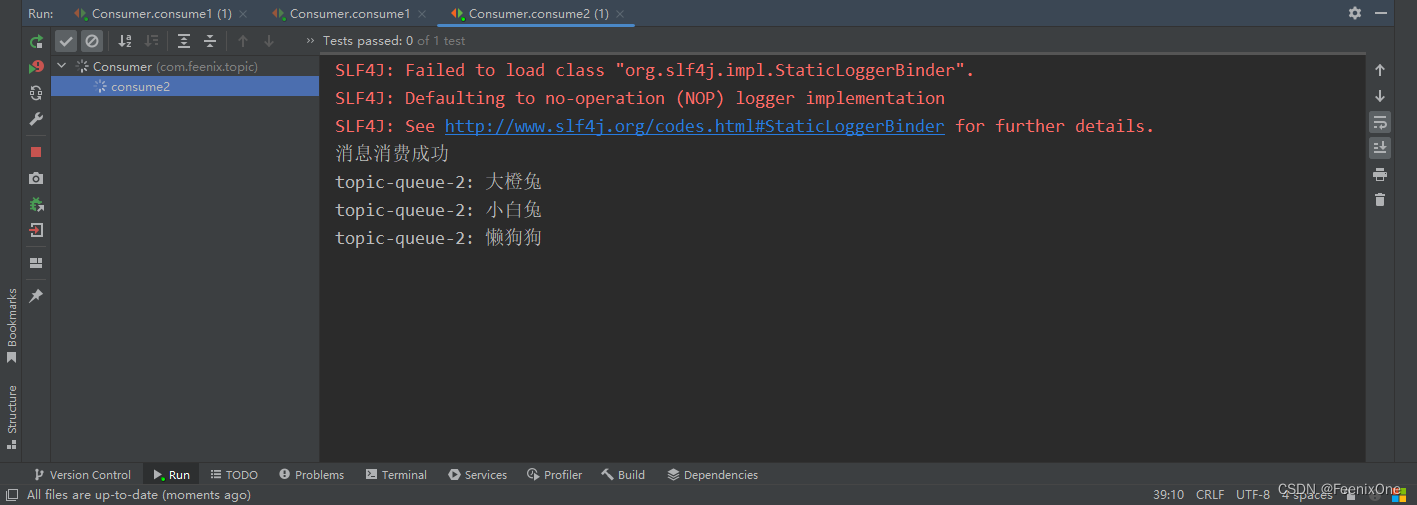
RPC - RPC方式
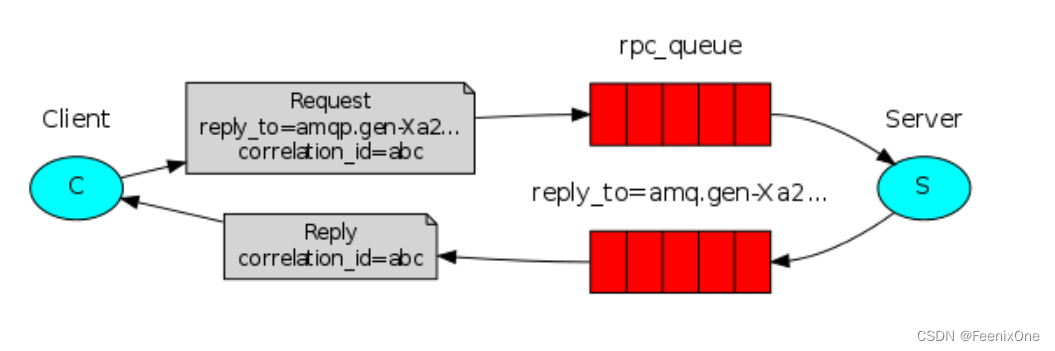
RPC这种方式平时在实际生产中使用的比较少,从结构图上可以看出,RabbitMQ对RPC方式已经不叫生产者和消费者了,而是叫做客户端和服务端,因为这种方式下主要是为了完成两个服务之间的相互调用。两个服务在交互时,可以尽量做到Client和Server的解耦,通过RabbitMQ进行解耦操作。需要让Client发送消息时,携带两个属性:
- replyTo告知Server将相应信息放到哪个队列;
- correlationId告知Server发送相应消息时,需要携带位置标示来告知Client响应的信息;
不过在这种闭环下,需要按两个消息队列的支持,对性能的影响肯定是不小的,但是无论如何,确实起到了解耦的重要作用。
客户端

服务端
为啥这种方式现在用的不多呢,因为现在的微服务基本上都是基于SpringCloud全家桶提供的注册中心组件和远程调用组件来管理,已经大幅度各个Client和Server之间的耦合问题。这样访问中心就不会穿插这么多的队列,效率是远比RPC要高很多。
那么,RabbitMQ几种基础的通讯方式就全部介绍完了,还剩下最后一种Publisher Confirms方式没有说明,关于这种方式会在下面的消息可靠性相关进行详细讲解。
HEADERS类型交换机
在上面官方文档提供的7中类型通讯方式中,好像没有对headers类型的交换机做过介绍
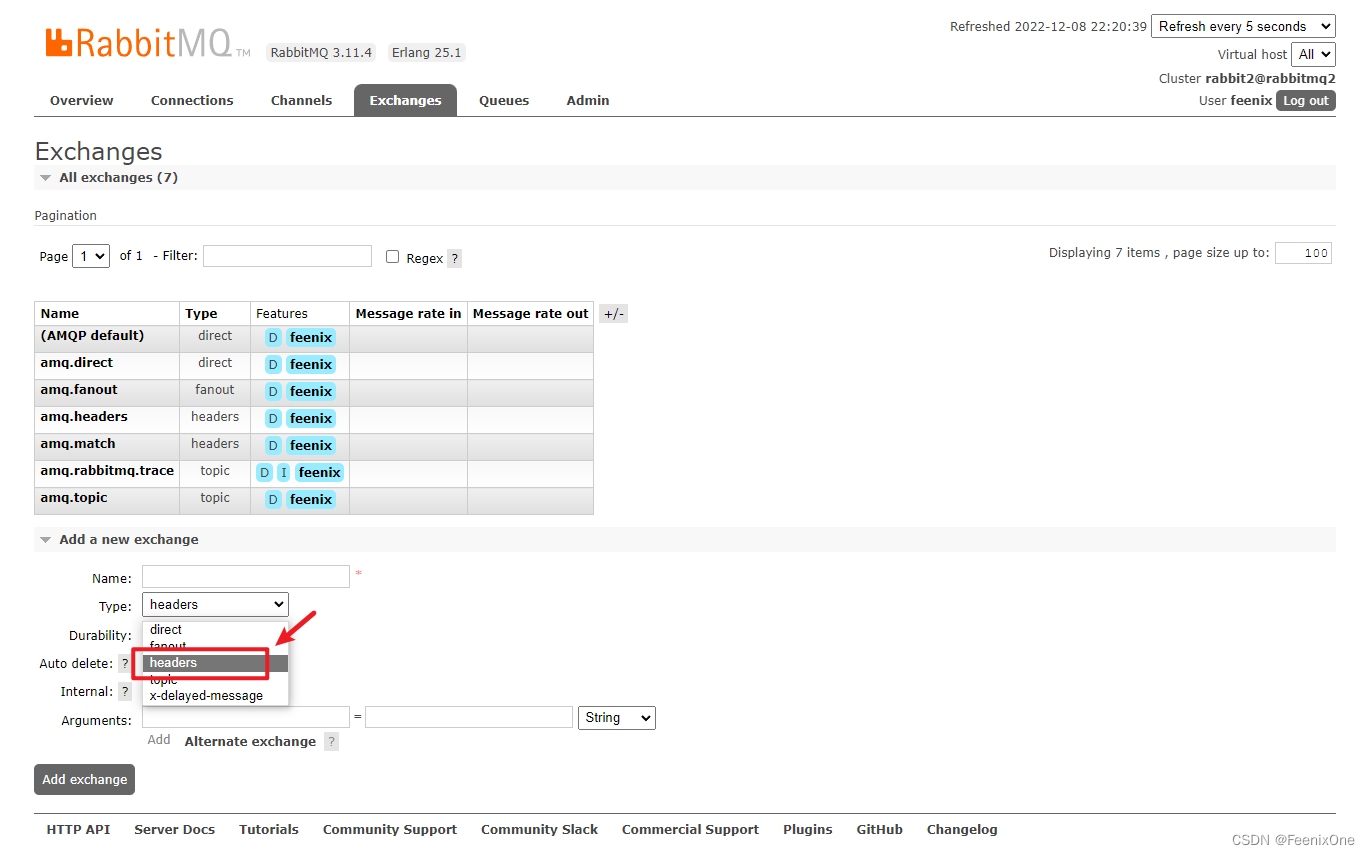
headers类型和别的通讯方式没有啥本质上的区别,都是要让Exchange交换机和Queue队列以一定的规则绑定到一起。只不过不再是通过routingKey来指定绑定规则,而是基于key-value的形式。在生产者发送消息的时候,会给消息携带一个headers的参数,其中的核心匹配参数就是x-match,值有两个:all 和 any。如果是all类型的,那么消息中携带的参数必须全部满足headers中的key-value,才可以路由到指定的队列中,类似于&&;如果是any类型的,那么消息中携带的参数只要有一个满足headers中的key-value,都可以路由到指定的队列中,类似于||。

生产者
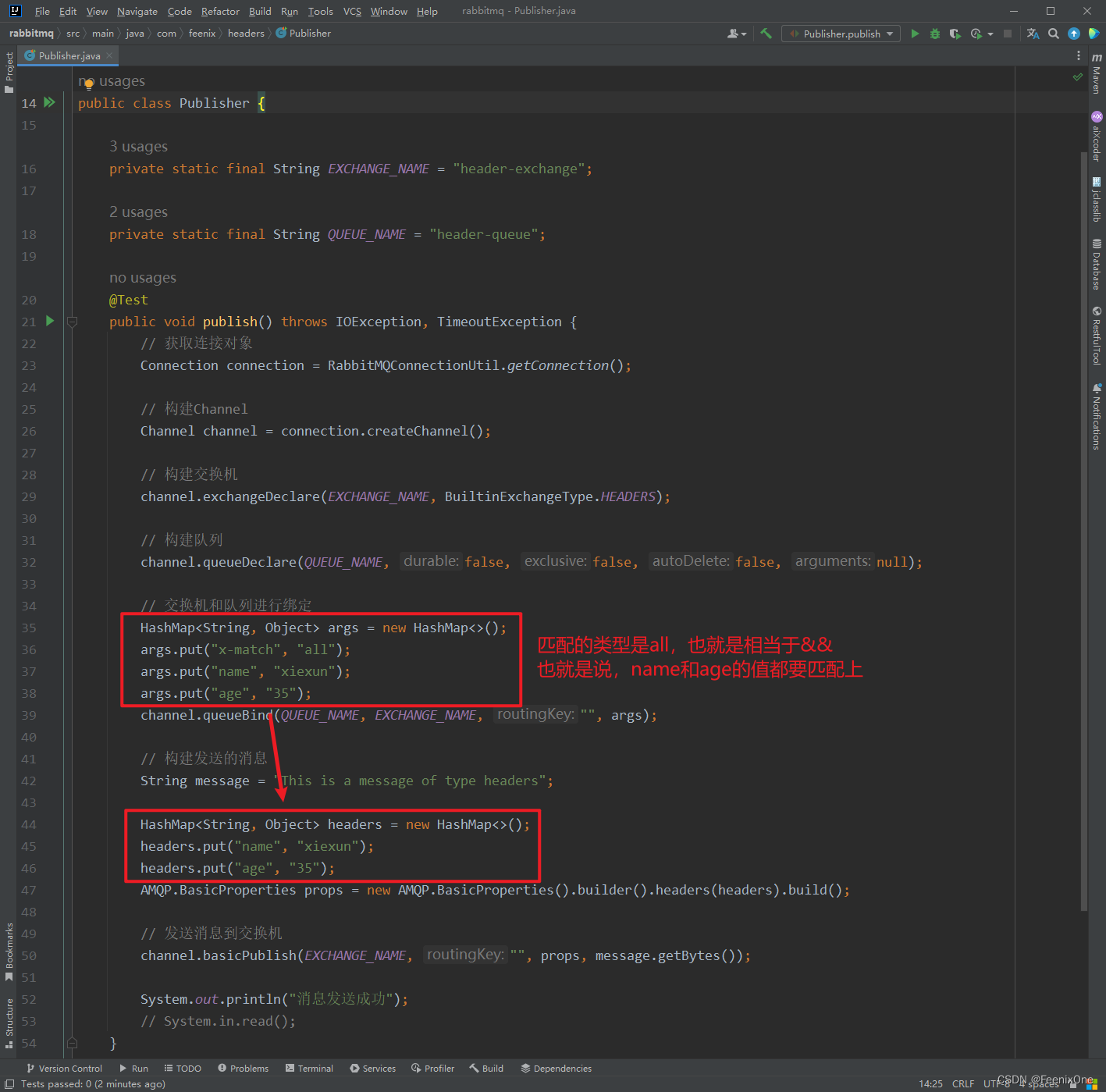
可以看到发送的消息已经路由到队列中
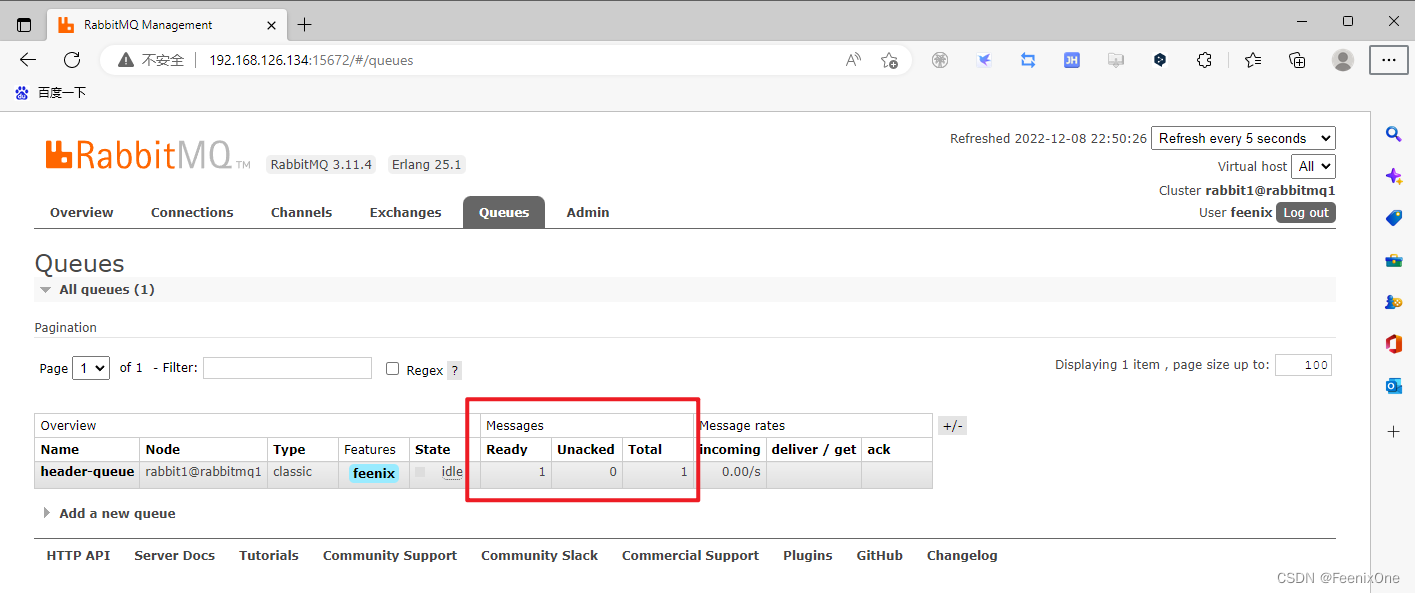
如果将消息中携带的参数值改掉,发送后就无法完全匹配,则不可路由到队列中

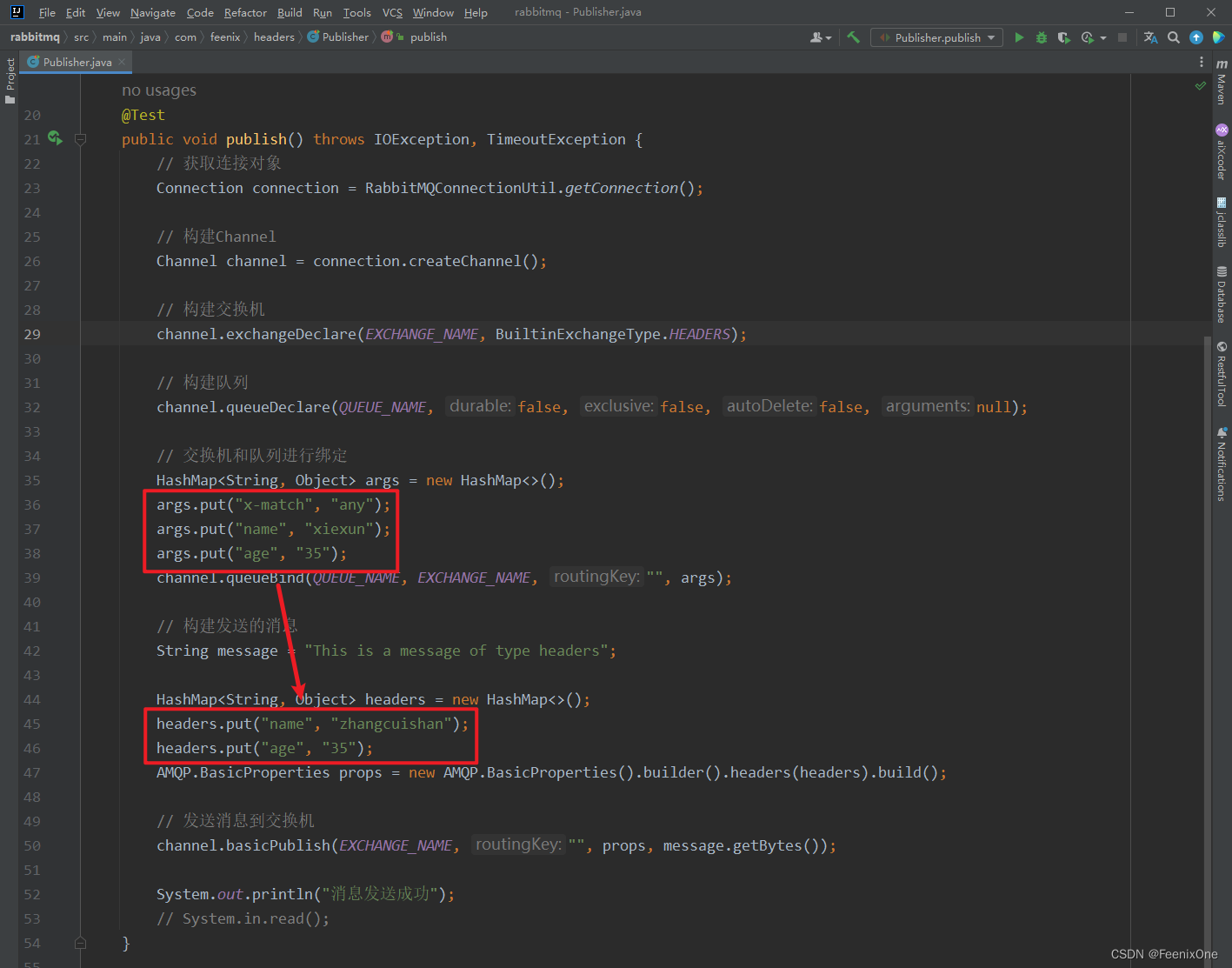
将all类型改为any类型,那就可以路由到队列中
5、SpringBoot整合RabbitMQ
引入RabbitMQ相关依赖
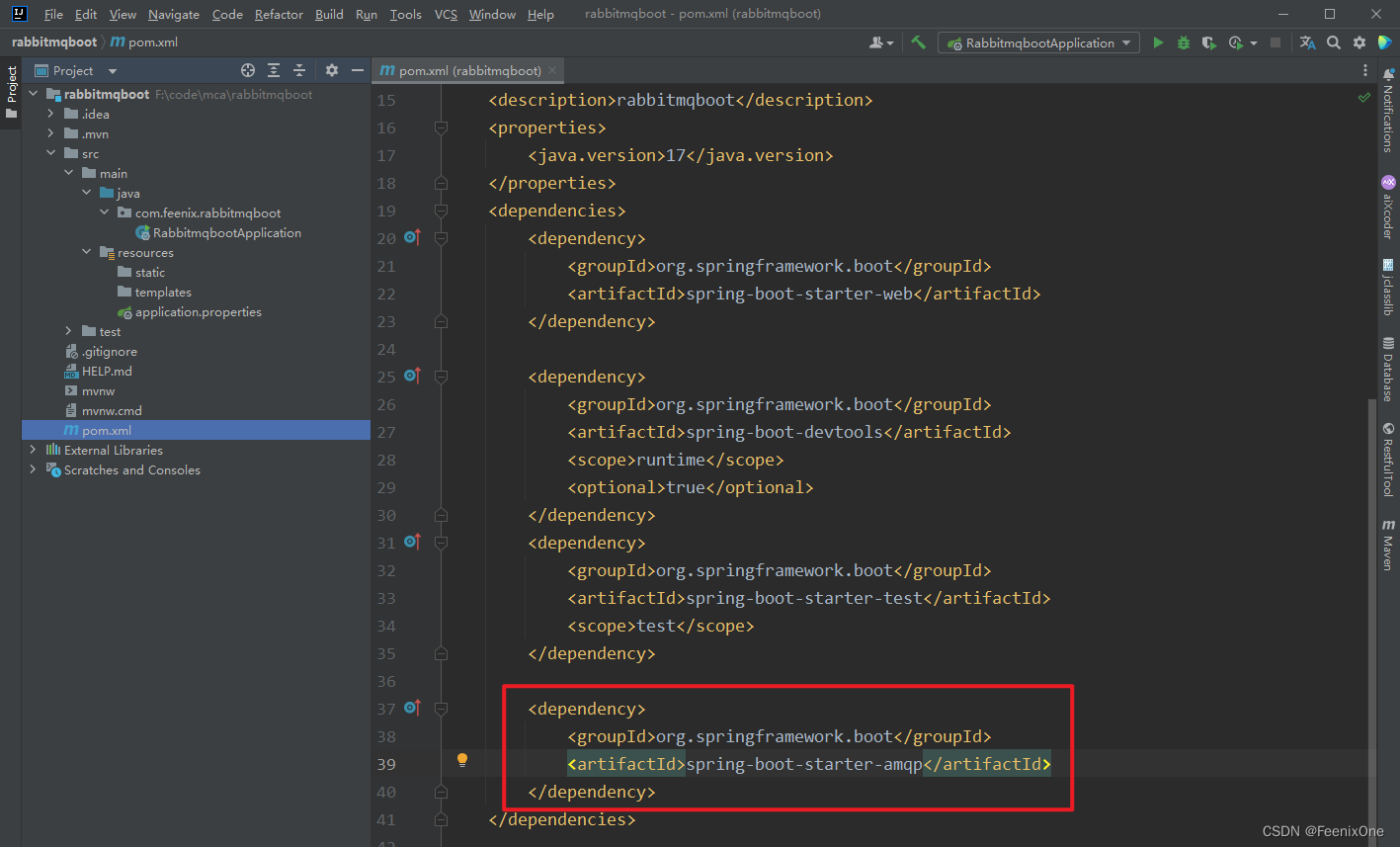
配置yml配置文件

声明交换机Exchange和队列Queue

生产者

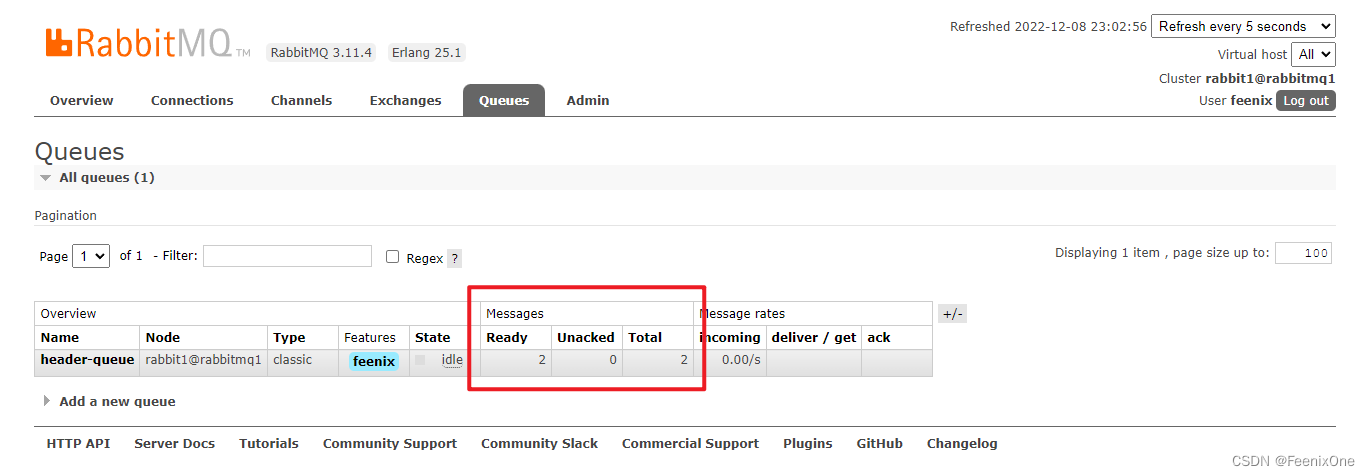
在RabbitMQ图像管理界面上,已经可以看到生成的Exchange和Queue
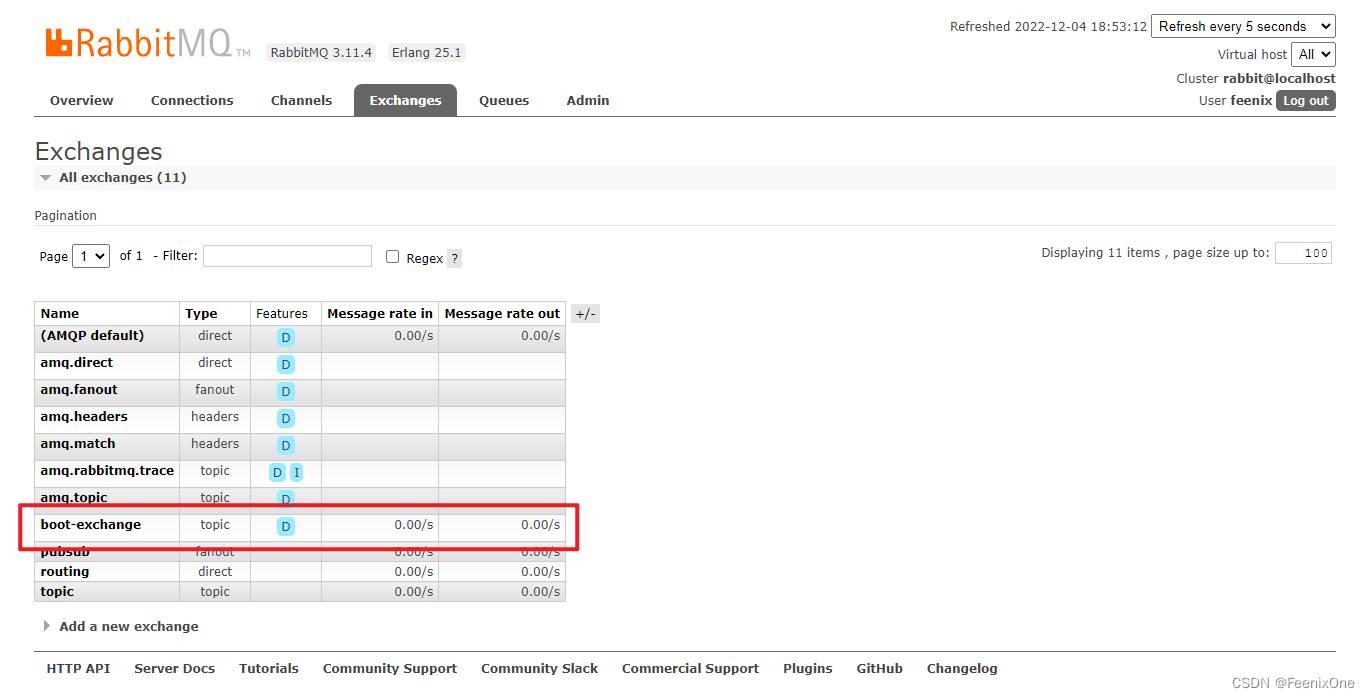
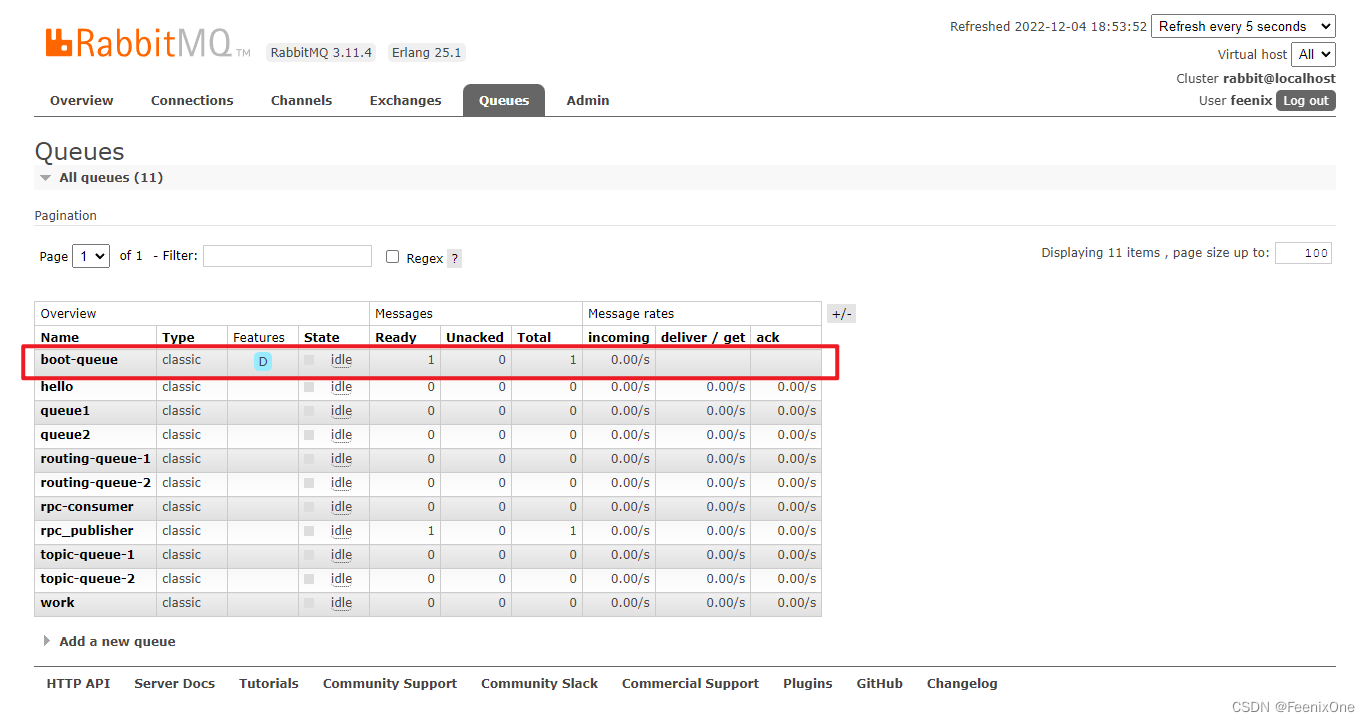
如果在发送消息的时候需要携带特殊属性的话
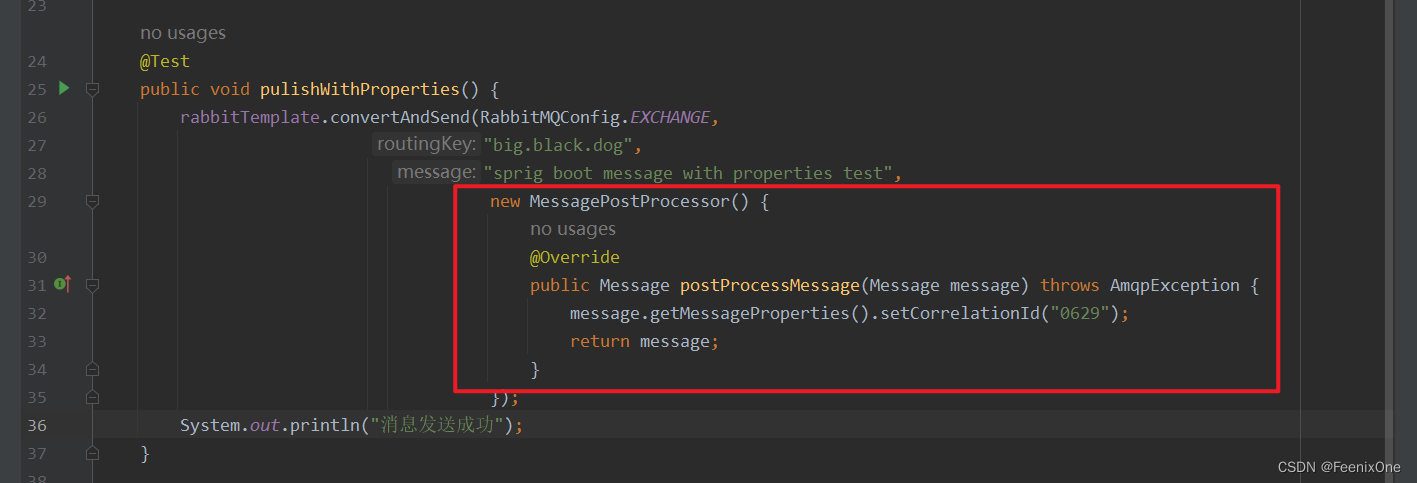
消费者

6、RabbitMQ保证消息可靠性
对于RabbitMQ来说,【生产者->Excahnge->Queue->消费者】这一整条链上每一环都会导致消息的丢失。
首先,生产者将消息发送到Exchange时,可能因为网络原因导致没有传输成功。但是对于生产者来说,消息已经发送出去,但是Exchange并没有接受到消息。所以RabbitMQ要解决的第一件事就是,如何保证消息一定送达到Exchange?
当消息送达到Exchange之后,再由Exchange根据不同的routingKey路由到不同的Queue中。假设在这个过程中,RabbitMQ服务重启或者宕机,那么没有路由到Queue中的消息就会丢失。所以RabbitMQ要解决的第二件事就是,如何保证消息一定路由到Queue中?
当消息被路由到Queue之后,RabbitMQ又是如何保证Queue可以持久化消息?
在前面介绍过RabbitMQ中的ACK机制,只有关闭自动ACK并开启手动ACK之后,才可以使用消息的流控(就是每次可以消费多少条消息)。同时手动ACK可以保证,消费者在确保业务逻辑执行完之后再告诉RabbitMQ服务消息已经消费完成,不需要再交给其它的消费者二次消费。那么RabbitMQ又是如何保证消费者可以正常消费消息?
打开RabbitMQ的官网,来到之前的介绍7中通讯方式的页面(https://www.rabbitmq.com/getstarted.html)。在上面介绍RabbitMQ通讯方式的时候,最后一个 Publisher Confirms 方式没有讲解,现在来详细看下相关的说明。
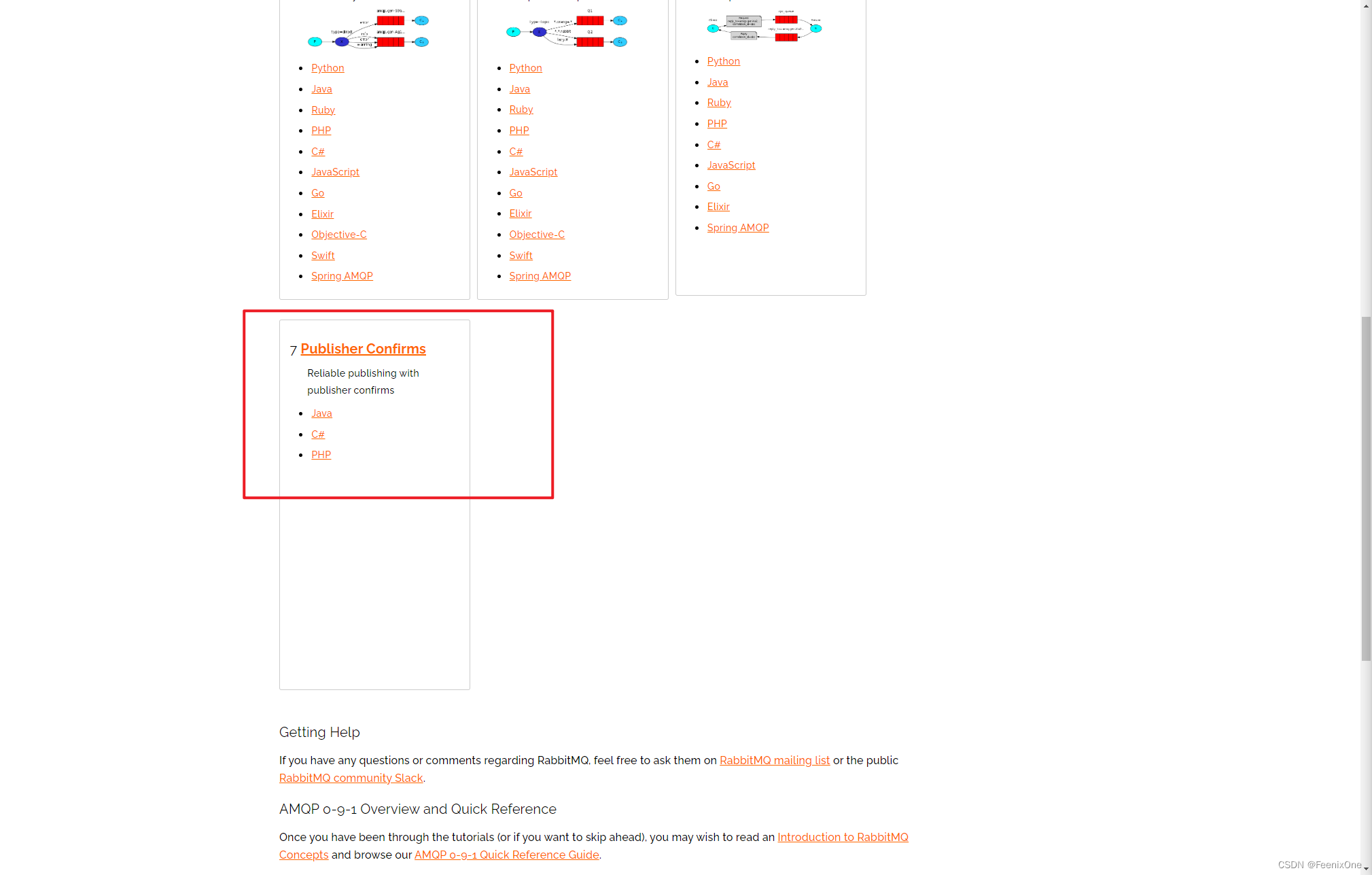
点进去可以看到,官网提供了3中方式用以保证消息可以送到到Exchange,比如confirmSelect是通过每次发送以后需要等待时间,而这种等待就会导致整个MQ服务效率大打折扣。所以这种同步的操作实际生产中几乎不会去使用,真正使用的是
Confirm机制
这种机制采用的是异步通讯当时,生产者发送完消息之后无须等待,该该什么继续干什么。当消息发送出现问题之后,RabbitMQ会异步给一个反馈,生产者根据反馈回来的信息进行一些补救操作:尝试重新发送、或者将数据存储到数据库等待后续的操作等。
在yml文件中配置开启Confirm机制
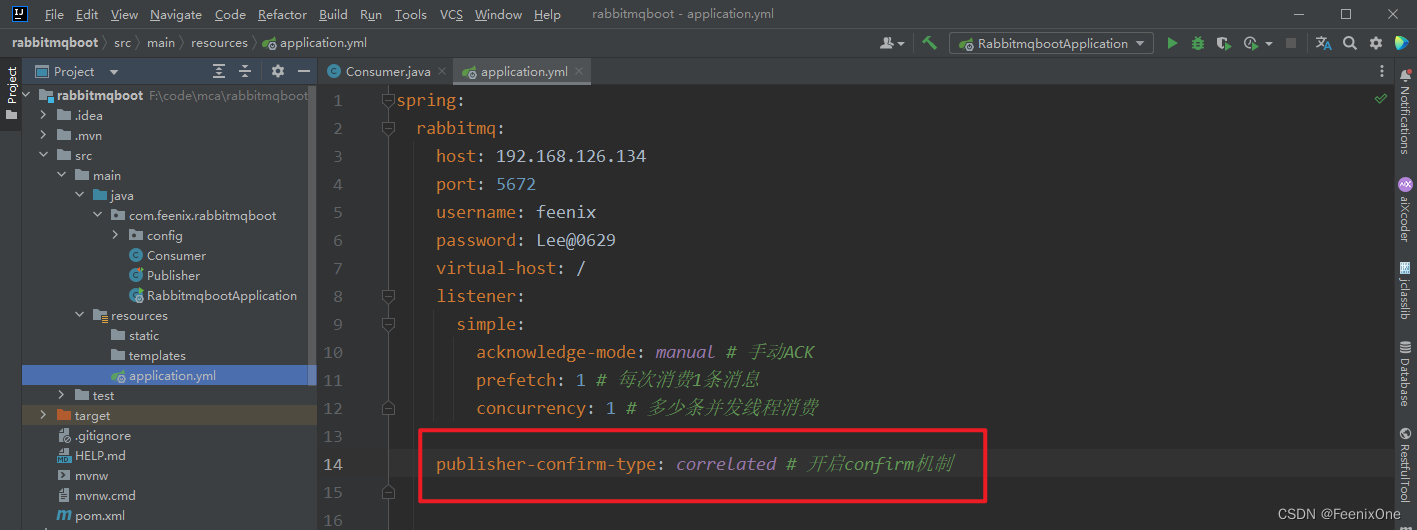
较新版本的SpringBoot+RabbitMQ对于Confirm属性的开启由老版的【publisher-confirms】变为【publisher-confirm-type】。老版的是布尔类型,给个true或false就可以;新版的属性值变成了枚举。点进去可以看到提供给了3个不同的值

而这个 SIMPLE 模式就是上面说的官网提供的三种模式中的第一种同步等待的模式,效率很低。
代码中使用Confirm机制
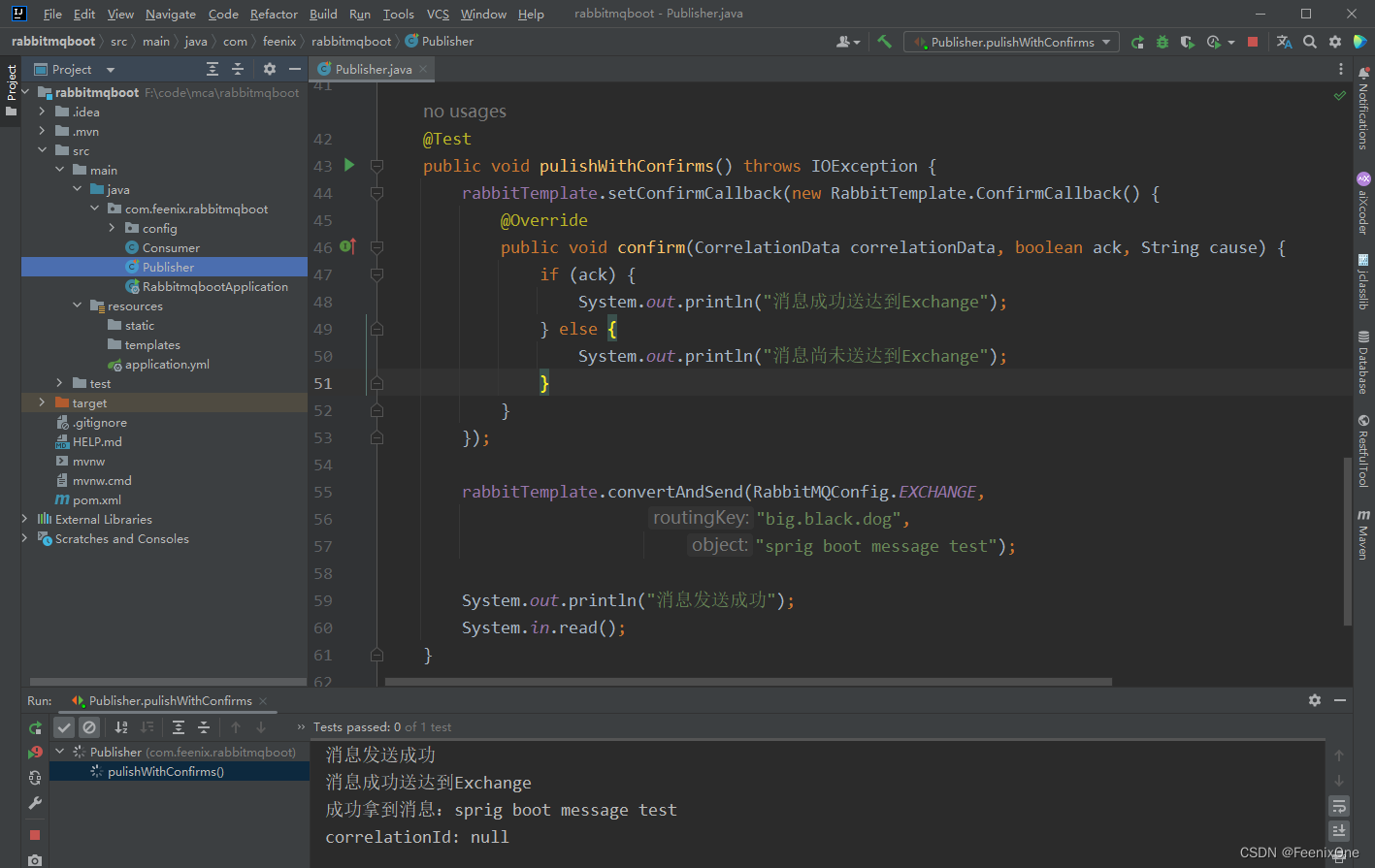
消息成功发送到Exchange之后,保证消息路由到Queue,就需要用到
Return机制
和Confirm机制一样,当消息无法被路由到某个Queue中时,就会异步给一个反馈,生产者根据反馈回来的信息再去进行一些补救操作。
在yml文件中配置开启Return机制
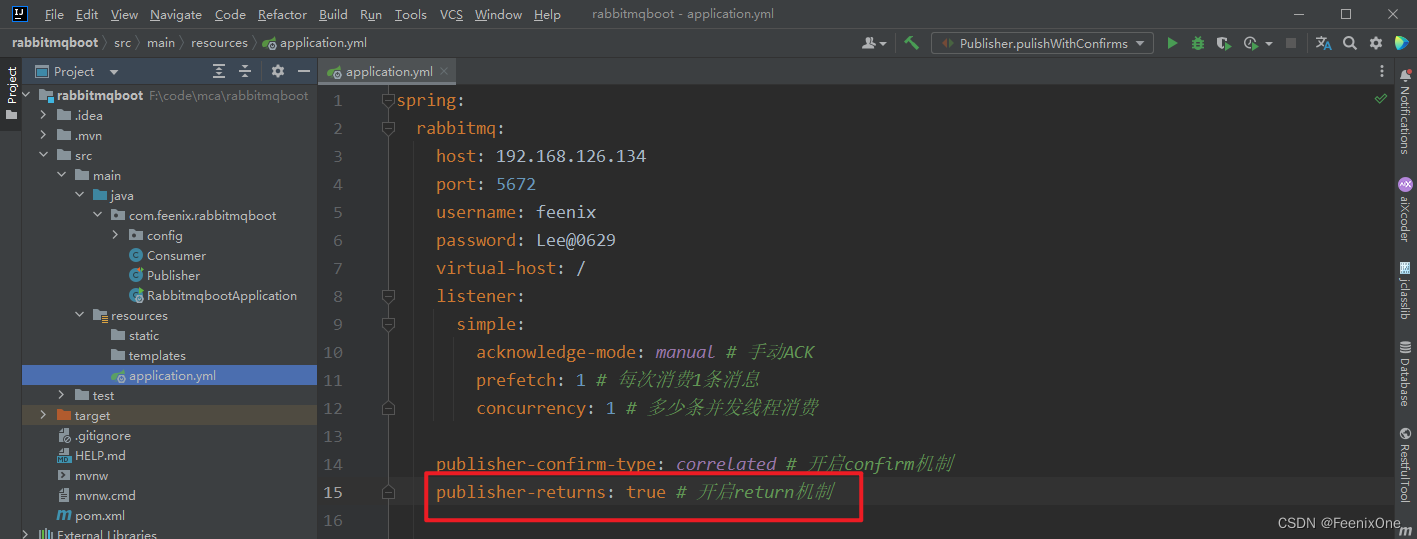
代码中使用Return机制
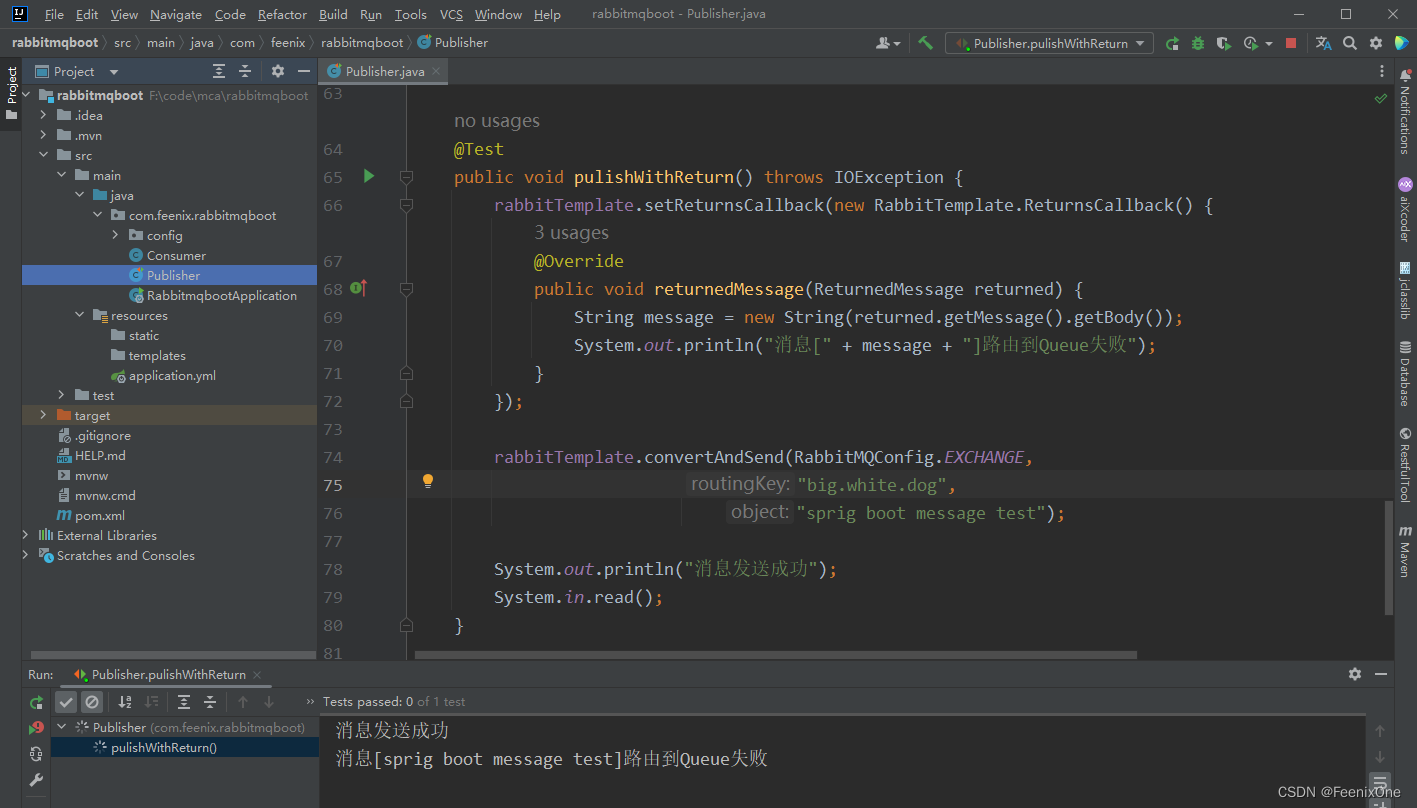
较新版本的SpringBoot+RabbitMQ对于Return属性的代码,由老版的rabbitTemplate.setReturnCallback变为了新版的rabbitTemplate.setReturnsCallback,中间多了个s
为了RabbitMQ服务重启之后,队列中的消息还在,就选对队列中的消息进行持久化操作,
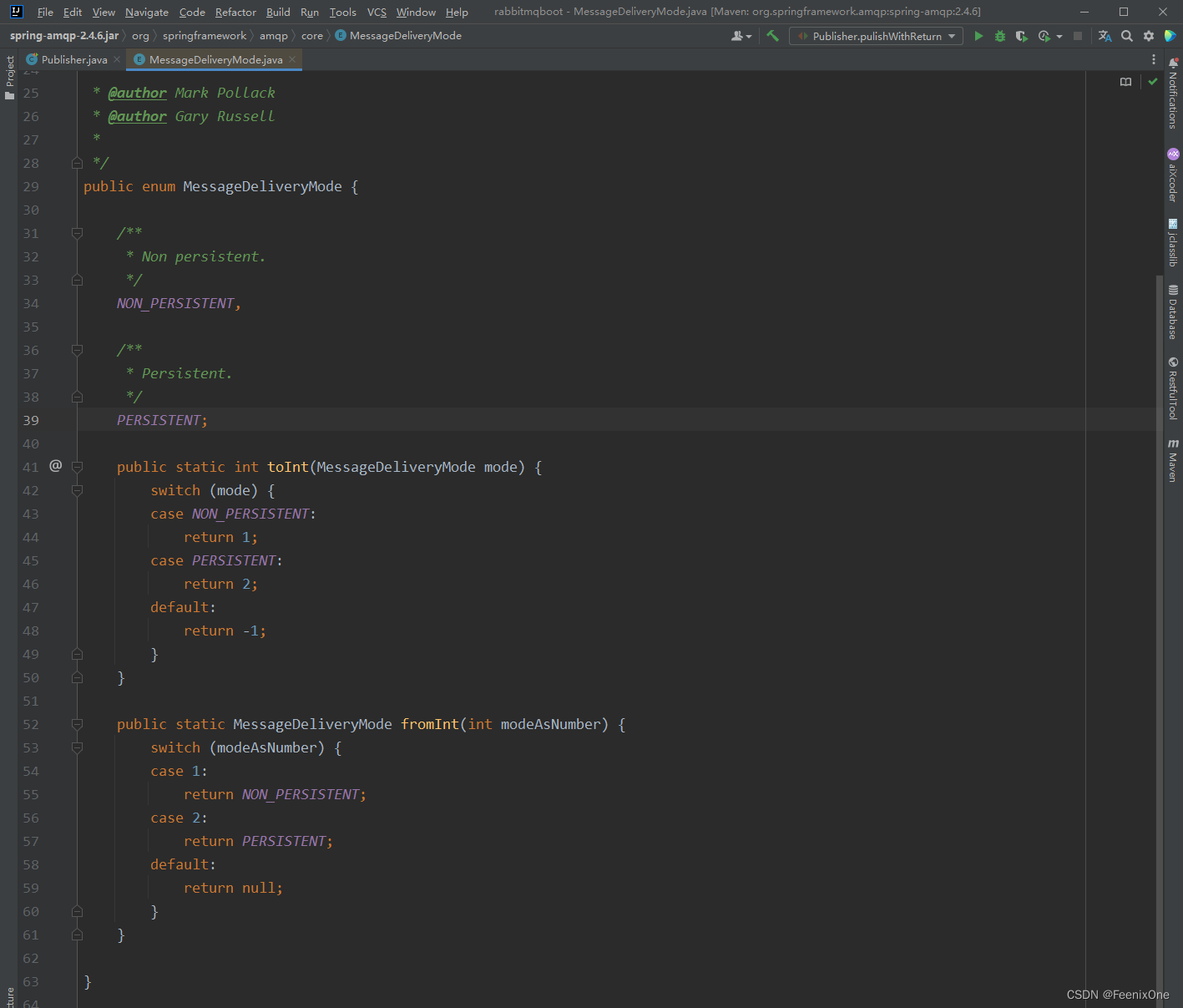
DeliveryMode设置消息持久化

消息持久化并不需要在yml配置文件中设置,直接在消息发送的时候添加一个参数即可。MessageDeliveryMode是一个枚举,一共就倆值,NON_PERSISTENT为1,代表不要持久化;PERSISTENT为2,代表需要持久化。
至于最后一个问题,RabbitMQ如何保证消费者的正常消费,在上面介绍6中通讯方式的时候,Work Queues的通讯方式就是解决保证消费者消费的问题。
7、关于死信队列和延迟交换机
其实官方给出的定义是dead letter,就被简单粗暴的直接翻译成死信。在了解死信队列之前,我们首先需要知道这个死信到底是什么意思。
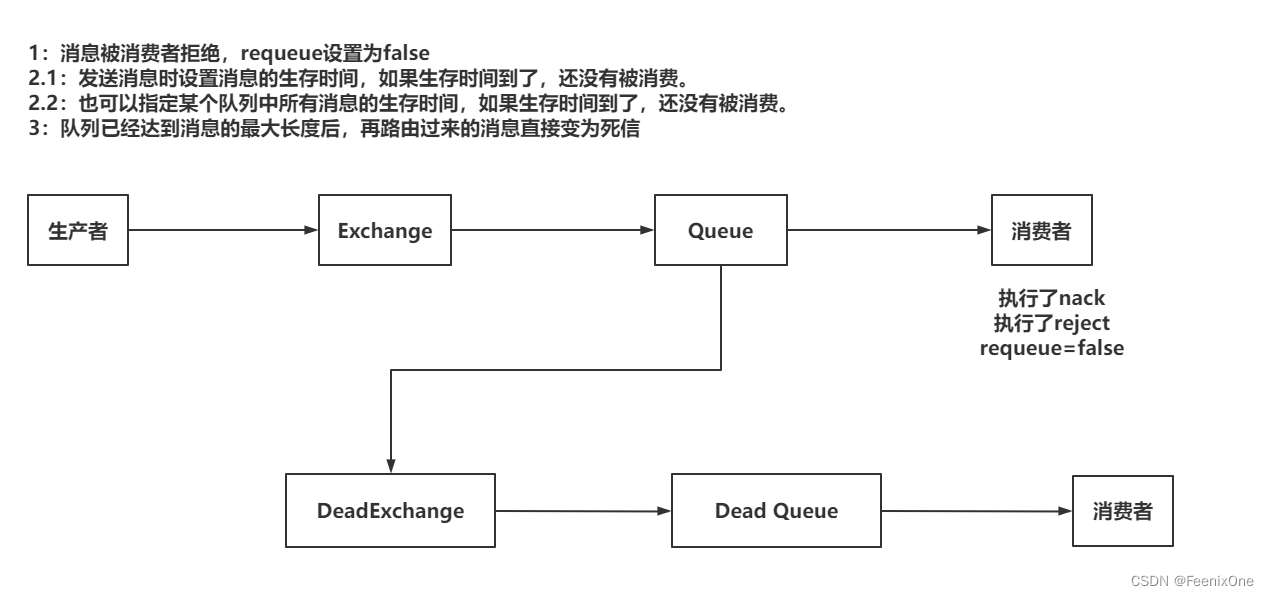
所以其实就是经过上图中的三种情况后,一个普通的消息变成了死信。由普通的Queue路由到Dead Exchange后,再被路由到一个特殊的Queue —— Dead Queue,这就是所谓的死信队列。其实死信队列和其他普通的队列没有什么区别,只不过这个队列专门用于存放死信。
死信队列的应用:
- 基于死信队列在队列消息已满的情况下,消息也不会丢失,二次保证消息可靠性;
- 实现延迟消费的效果。比如:下订单时,有15分钟的付款时间;
构建普通队列和死信队列
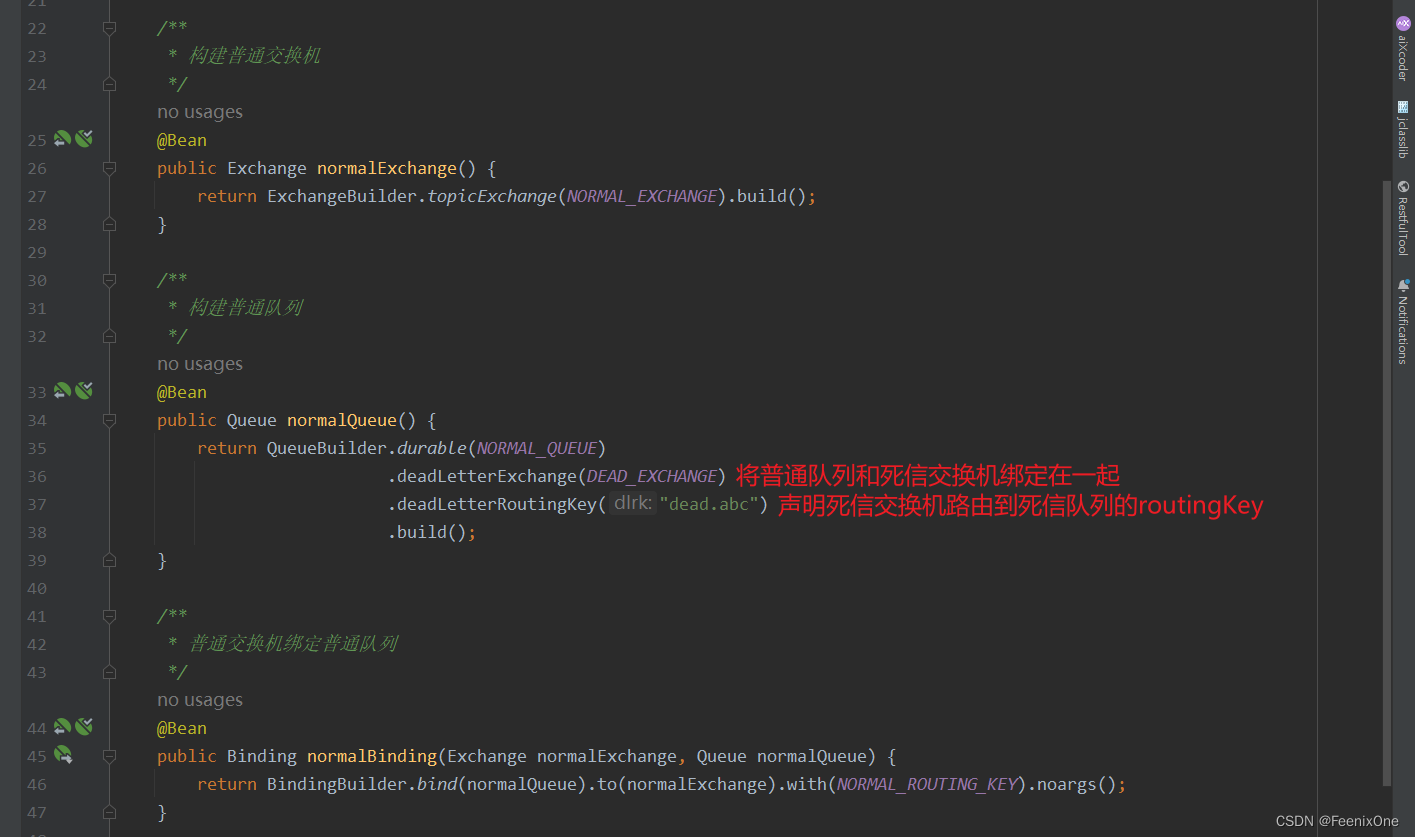

消息拒绝
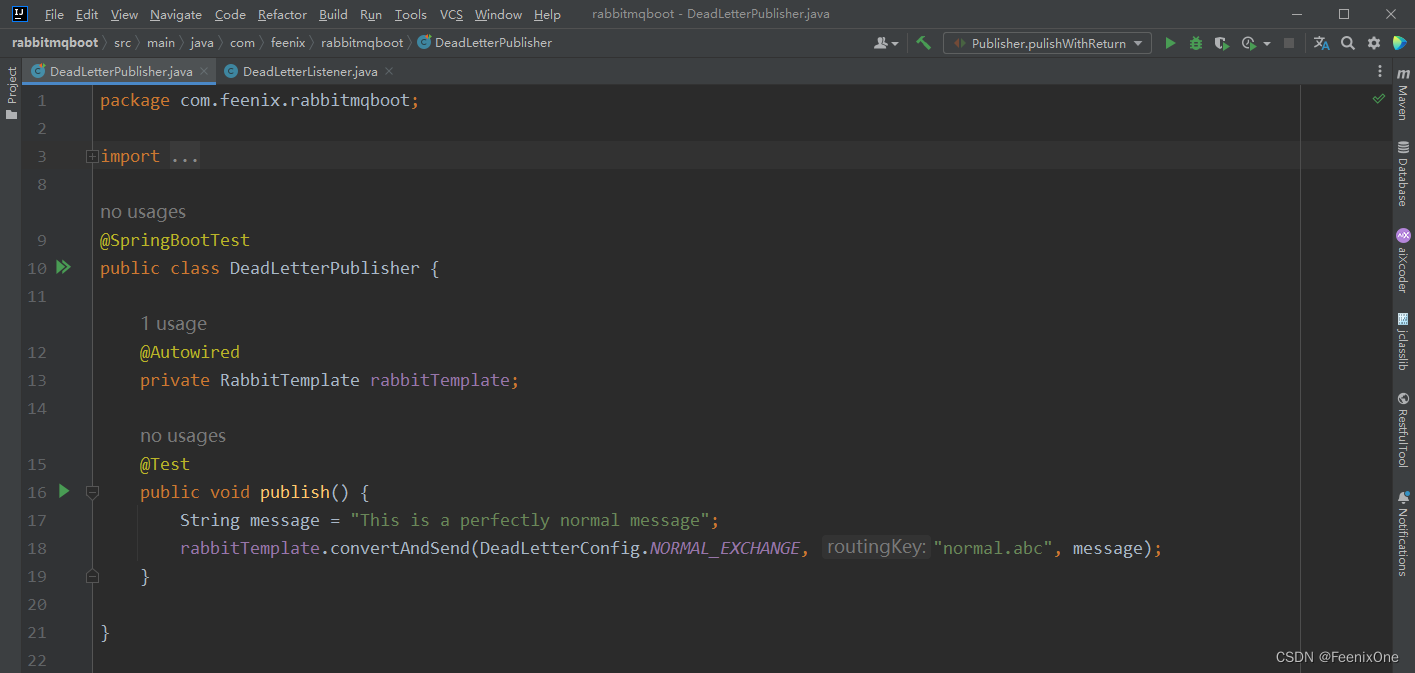
生产者
消费者
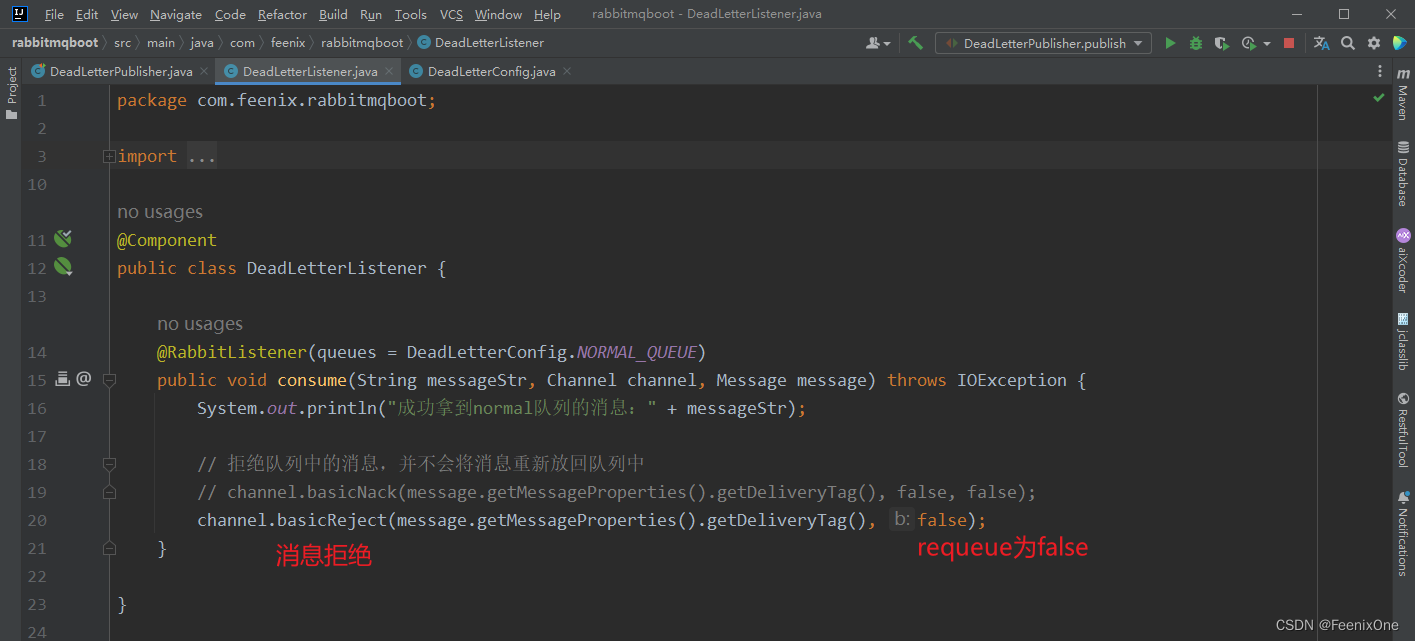
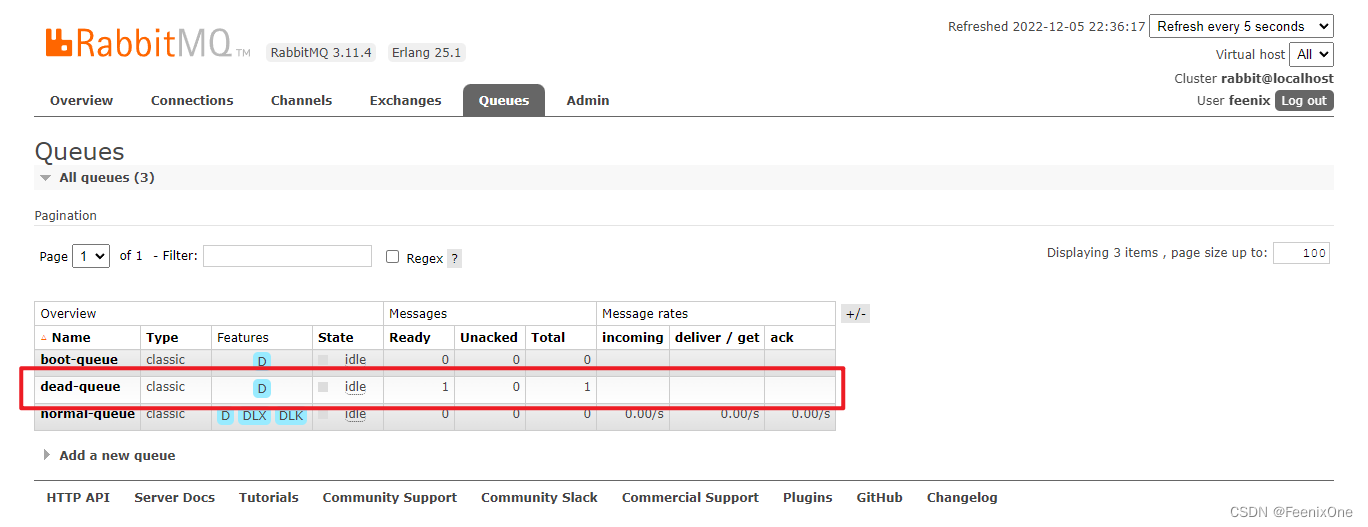
当生产者发送的消息被消费者拒绝之后,并且消息不会被requeue,就会来到死信队列中
消息生存时间
生产者
每次发送消息的时候,单独指定消息的生存时间
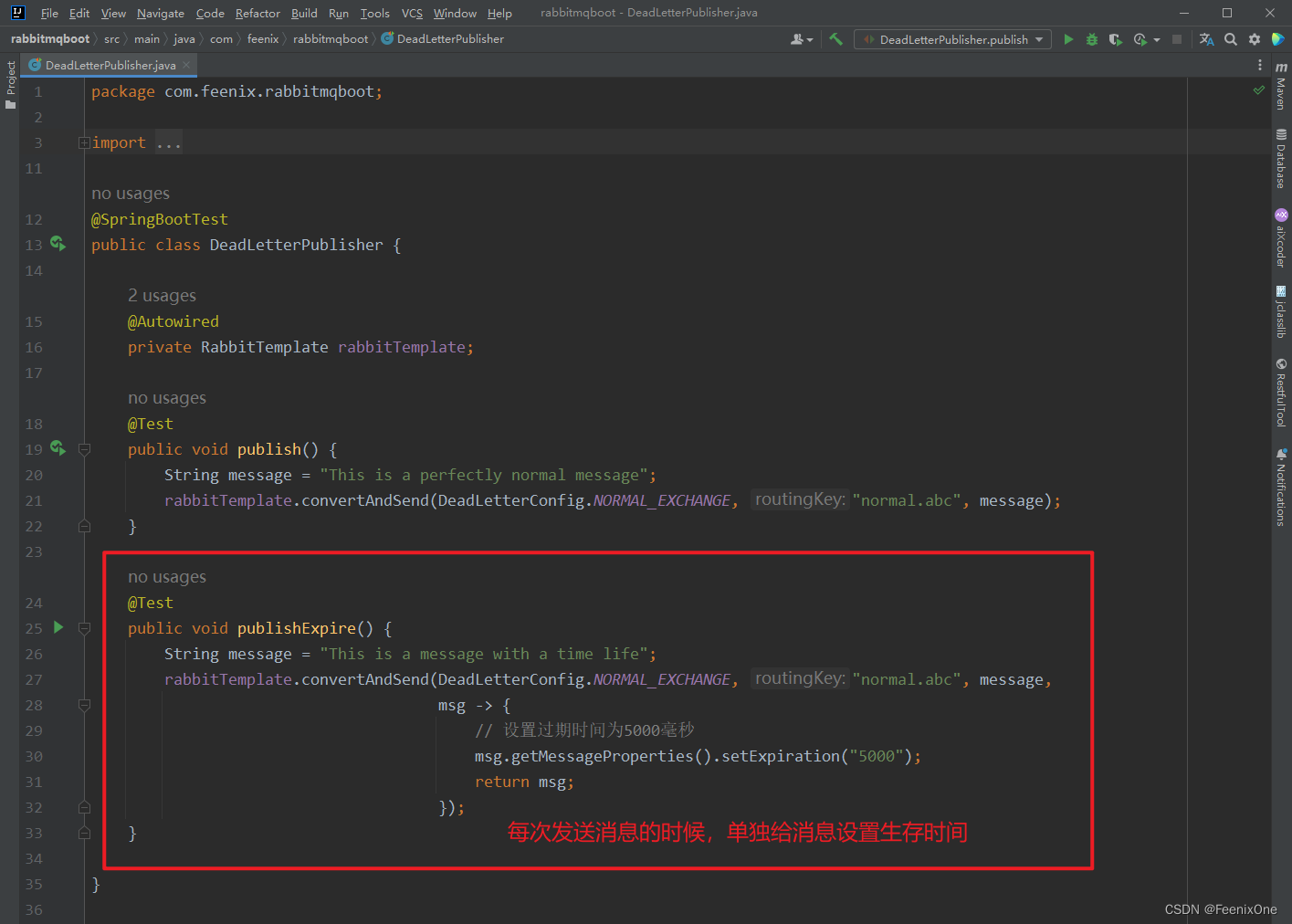
当然,也可以在构建队列的时候,直接指定队列中消息的生存时间
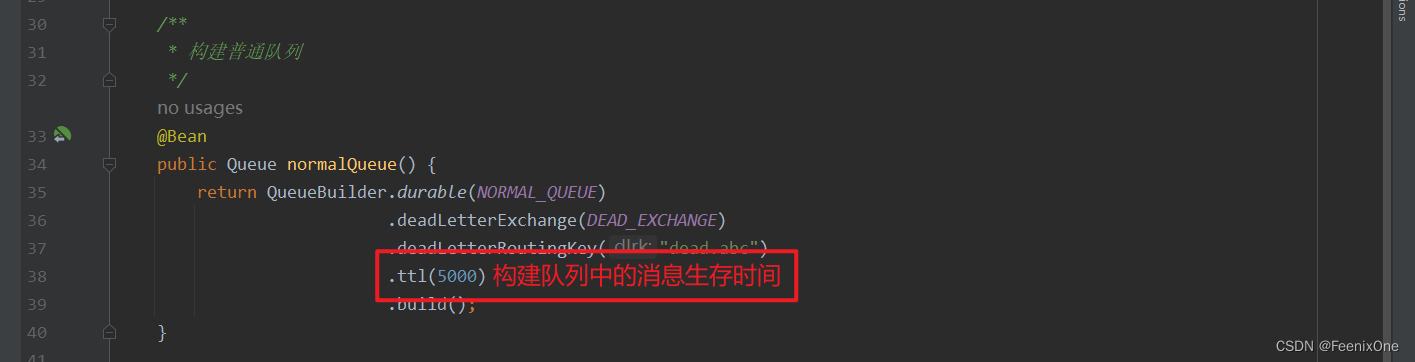
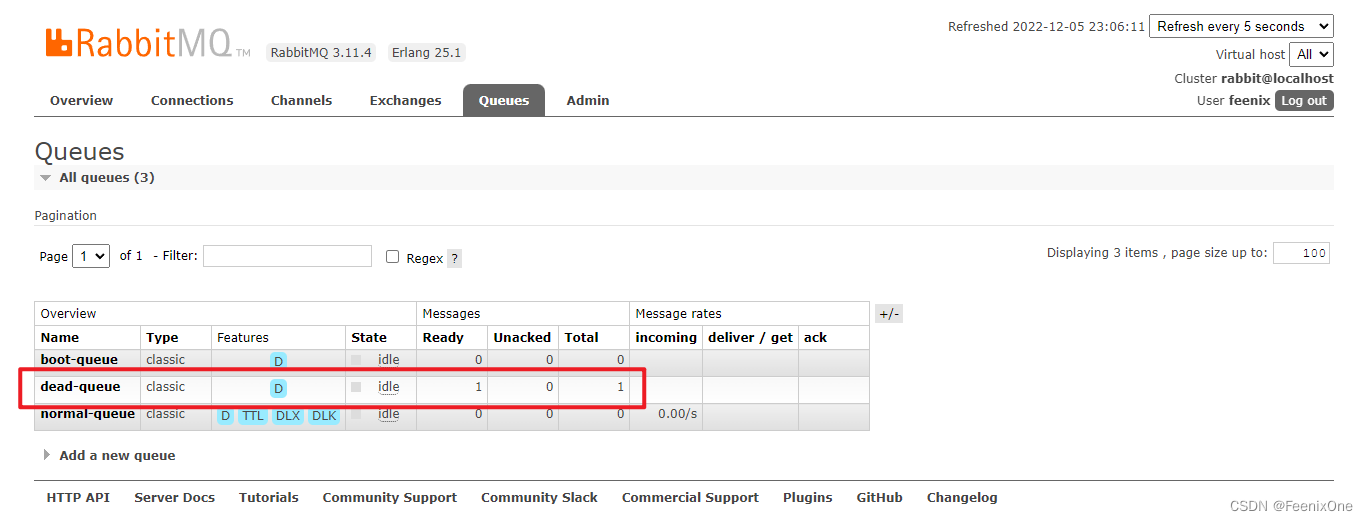
当生产者发送的消息在队列中等待的时间超过了设置的存活时间,就会自动被路由到死信队列
队列最大长度
在构建队列的时候,指定队列最大长度
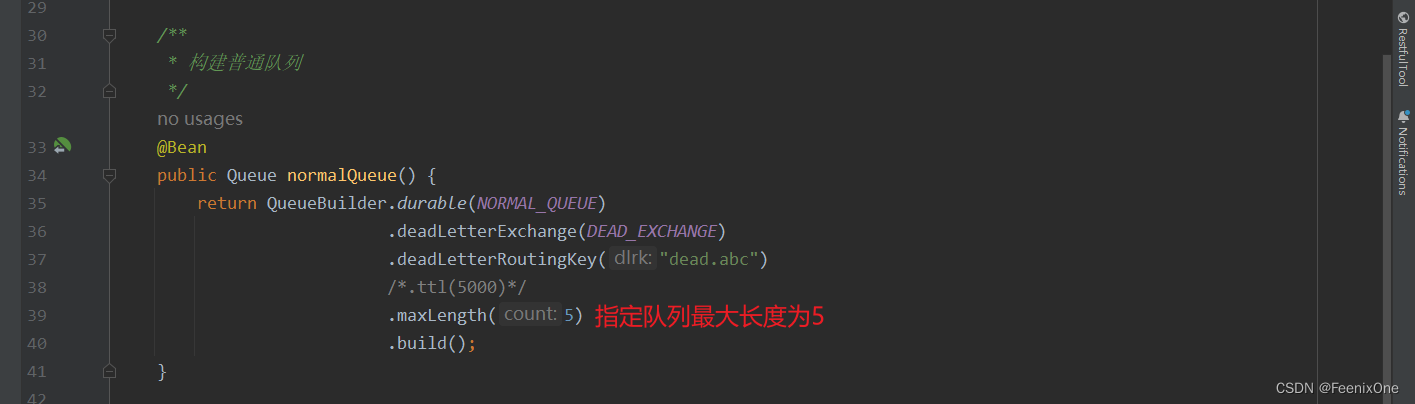
生产者发送10条消息,超过最大长度5条消息之后,其余的消息都会被路由到死信队列中
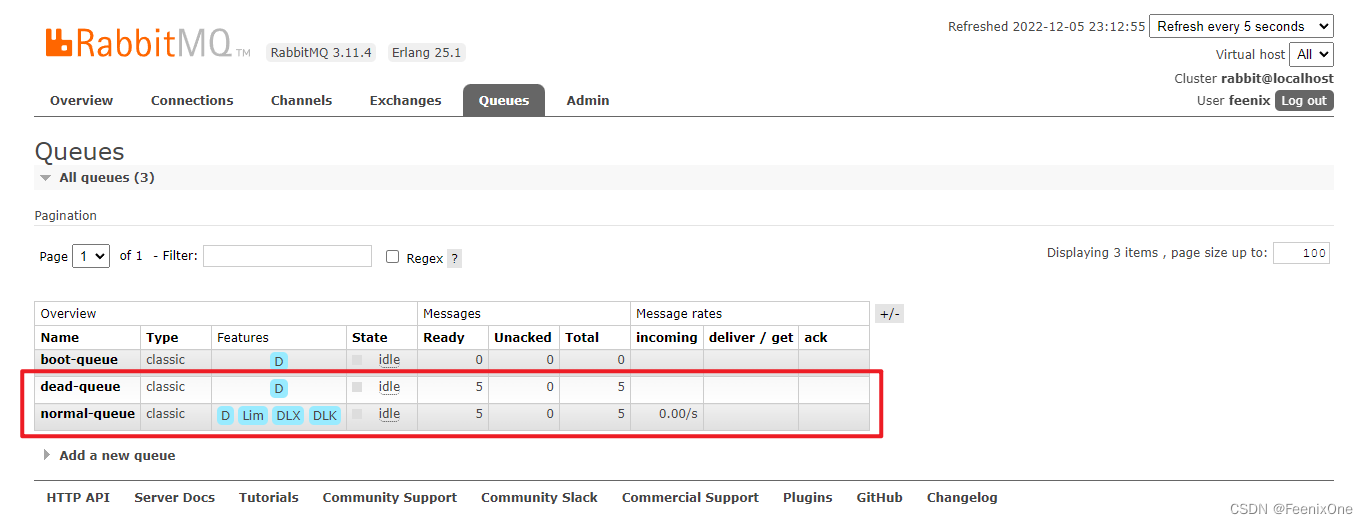
延迟交换机
死信队列实现延迟消费时,如果延迟时间比较复杂且比较多,直接使用死信队列时,需要创建大量的队列,还需要对应设置不同的时间,不仅麻烦还很耗费性能,也存在一些问题:
RabbitMQ对消息的消息的生存时间的检测是有顺序的。假设有两条生存时间不一致的消息,第一个进入队列中的消息生存时间为10s,第二个进入队列中的消息生存时间为5s,RabbitMQ先检测的是第一个消息,10s之后将第一条消息放入死信队列中,再去检测第二条消息,第二条早已在队列中存放超过了5s的时间。
为了解决这种场景下的问题,RabbitMQ官方提供了延迟交换机插件:https://rabbitmq.com/community-plugins.html


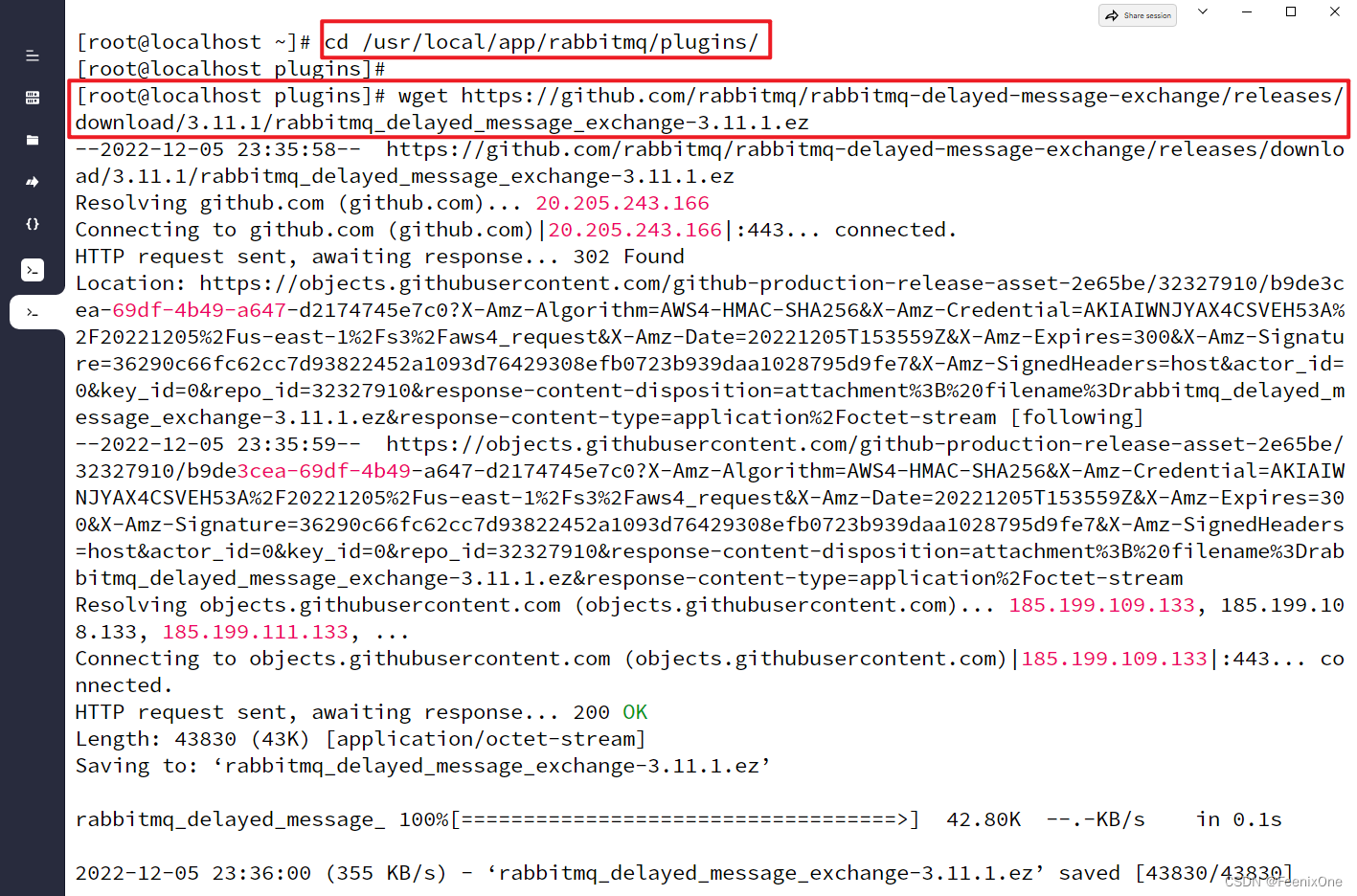
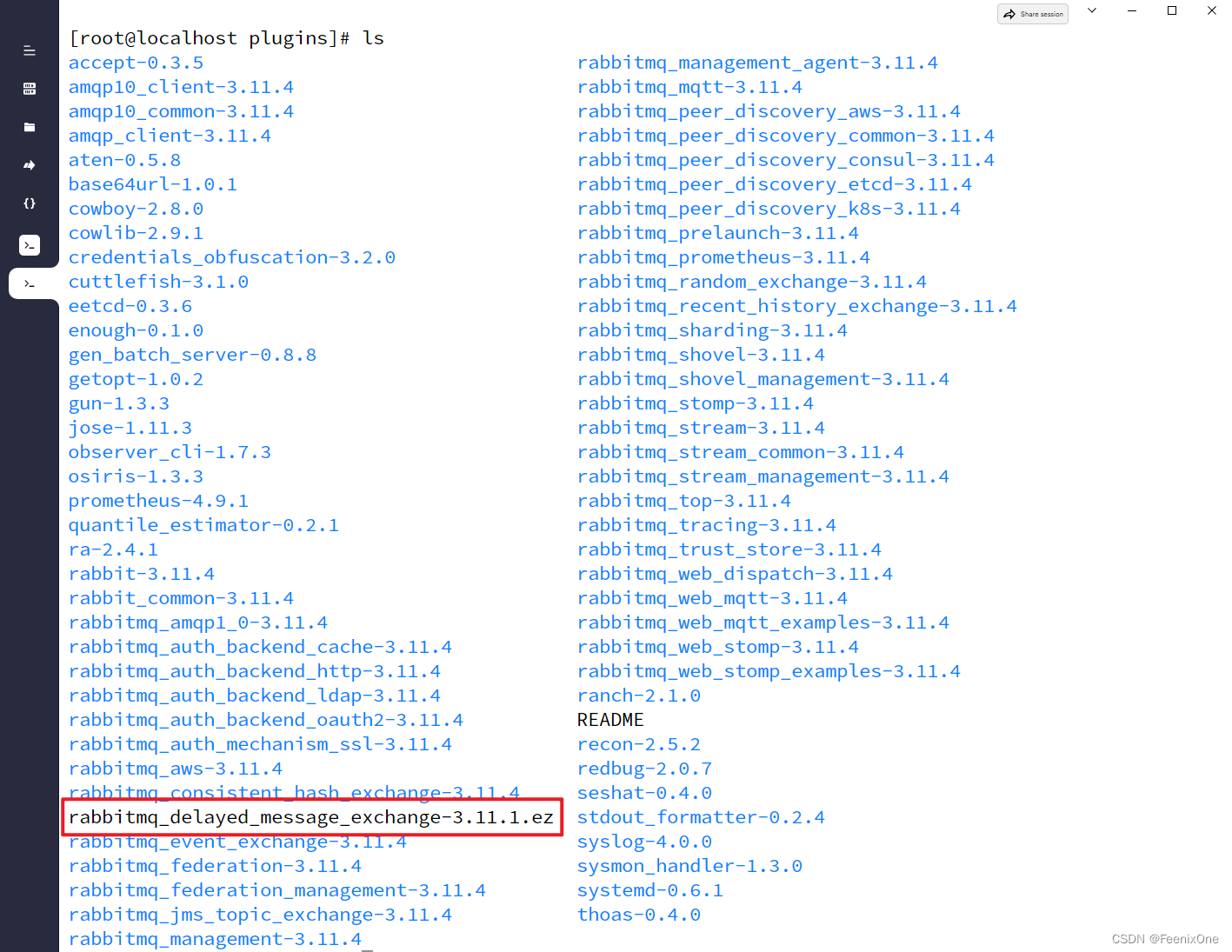
安装延迟交换机插件
进入到RabbitMQ的plugins目录下,执行:wget https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases/download/3.11.1/rabbitmq_delayed_message_exchange-3.11.1.ez
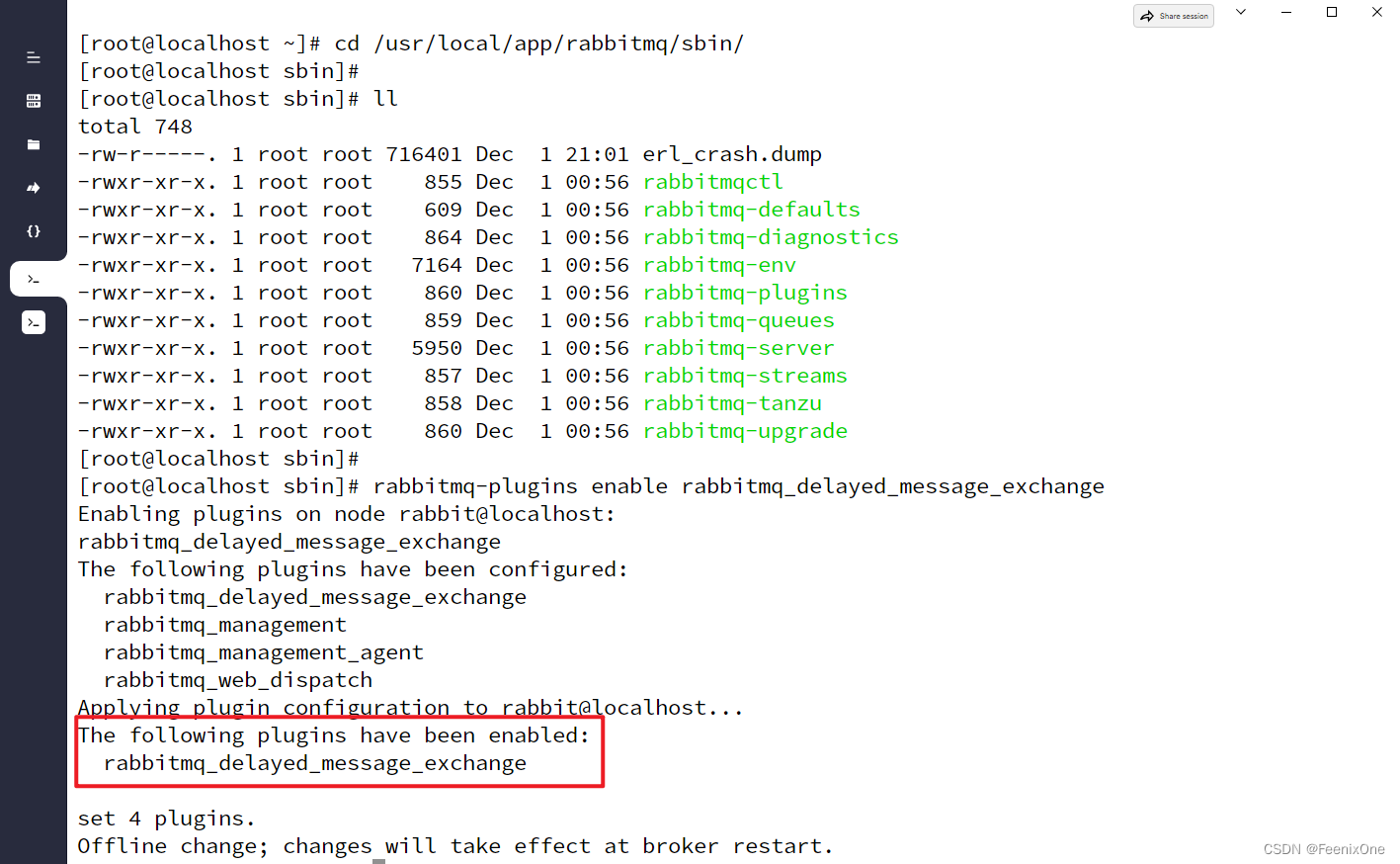
停止RabbitMQ服务,进入到RabbitMQ的sbin目录下,启动延迟交换机插件:
cd /usr/local/app/rabbitmq/sbin/
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
再次重启RabbitMQ服务,进入图形管理页面,可以看到在交换机的类型下拉选,已经有了延迟交换机的选项

构建延迟交换机
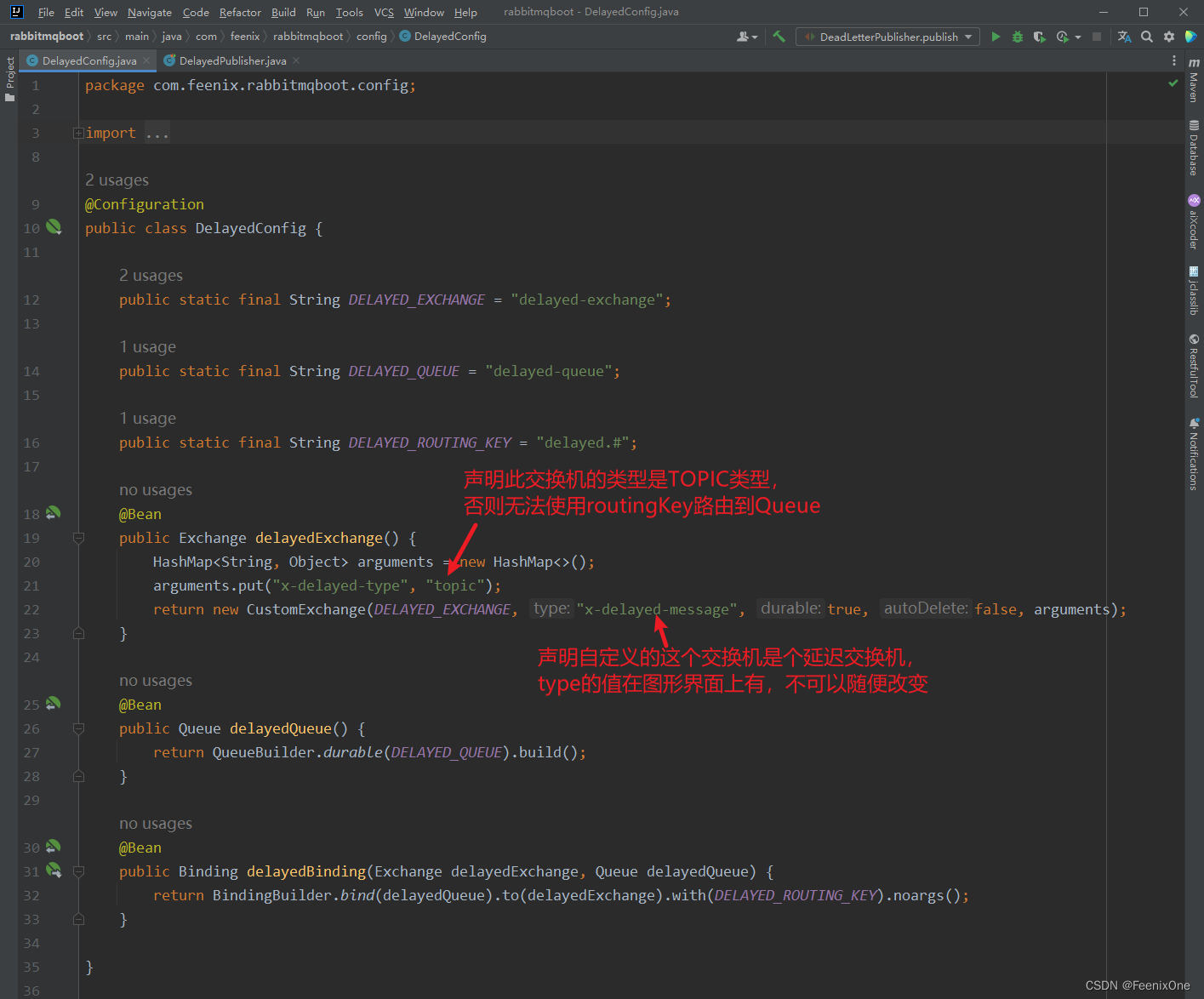
生产者

通过延迟交换机,可以很好的解决上面提到的问题。但延迟交换机也存在一定的问题,RabbitMQ重启之后,延迟交换机中的消息就会丢失。如果业务场景不允许消息丢失,还是不推荐使用。如果业务场景可以接受消息丢失,不需要保证100%的推送成功,非常推荐使用延迟交换机,效率更高,实现也更加优雅。
8、RabbitMQ集群

普通模式:默认的集群模式
RabbitMQ集群中节点包括内存节点、磁盘节点。内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘上。如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。那么内存节点的性能只能体现在资源管理上,比如增加或删除队列(queue),虚拟主机(vrtual hosts),交换机(exchange)等,发送和接受message速度同磁盘节点一样。一个集群至少要有一个磁盘节点。一个rabbitmq集群中可以共享user,vhost,exchange等,所有的数据和状态都是必须在所有节点上复制的,对于queue根据集群模式不同,应该有不同的表现。在集群模式下只要有任何一个节点能够工作,RabbitMQ集群对外就能提供服务。
默认的集群模式,queue创建之后,如果没有其它policy,则queue就会按照普通模式集群。对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq节点(A节点),当A节点宕机,你可以去其B节点查看,./rabbitmqctl list_queues发现该队列已经丢失,但声明的exchange还存在。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点,从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点,并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
为什么RabbitMQ不将队列复制到集群里每个节点呢?这与它的集群的设计本意相冲突,集群的设计目的就是增加更多节点时,能线性的增加性能(CPU、内存)和容量(内存、磁盘)。当然RabbitMQ新版本集群也支持队列复制(有个选项可以配置)。比如在有五个节点的集群里,可以指定某个队列的内容在2个节点上进行存储,从而在性能与高可用性之间取得一个平衡(应该就是指镜像模式)。
镜像模式:把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案
该模式解决了上述问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用,一个队列想做成镜像队列,需要先设置policy,然后客户端创建队列的时候,rabbitmq集群根据“队列名称”自动设置是普通集群模式或镜像队列。具体如下:
队列通过策略来使能镜像。策略能在任何时刻改变,rabbitmq队列也近可能的将队列随着策略变化而变化;非镜像队列和镜像队列之间是有区别的,前者缺乏额外的镜像基础设施,没有任何slave,因此会运行得更快。
为了使队列称为镜像队列,你将会创建一个策略来匹配队列,设置策略有两个键“ha-mode和 ha-params(可选)”。ha-params根据ha-mode设置不同的值,下面表格说明这些key的选项。
| ha-mode | ha-params | 结果 |
| all | absent | 队列镜像到集群内所有节点,当新节点加入集群时,队列将被镜像到那个节点。 |
| exactly | count | 队列镜像到集群内指定数量的节点。如果集群内节点数少于此数,则队列镜像到集群内所有节点。如果集群内节点数多于此数,而且一个包含镜像的节点停止,则新的镜像不会在另外一个节点上创建,阻止队列在集群内发生迁移。 |
| nodes | node names | 队列镜像到指定节点。如果任何指定节点不在集群中,都不产生错误。当队列声明是,如果没有任何指定的节点在线,则队列会被创建在发起声明的客户端所连接的节点上。 |
那么接下来,基于镜像模式搭建由两台RabbitMQ服务组成的集群。首先需要在两台不同的虚拟机上安装好RabbitMQ服务:


修改两台RabbitMQ服务的主机名
让 135 的RabbitMQ服务 去 join 134 的RabbitMQ服务,RabbitMQ服务在进行join的时候,是按照hosts文件中的名称去寻找的,而不是通过IP地址。所以,要现在两台虚拟上配置对应的名称
vim /etc/hosts

并且修改两台虚拟机的主机名:
134服务:hostnamectl set-hostname rabbitmq1
135服务:hostnamectl set-hostname rabbitmq2
重启RabbitMQ服务,这次在启动命令上加上RabbitMQ节点名:
134服务:RABBITMQ_NODENAME=rabbit1 ./rabbitmq-server
135服务:RABBITMQ_NODENAME=rabbit2 ./rabbitmq-server
登录RabbitMQ图形管理界面,可以看到此时的节点名称已经改变:


注意:更改节点名称后,和原来节点名称之间的账户信息不会同步。所以重启后,需要重新将新节点名称服务中的账户加回,重新授予角色和权限。因为sbin目录下的文件都是默认节点名称是rabbitmq@xxx,所以当指定节点名称重启RabbitMQ服务后,添加账户和授权也都要加上-n参数:
/usr/local/app/rabbitmq/sbin/
./rabbitmqctl -n rabbit1 add_user feenix Lee@0629
./rabbitmqctl -n rabbit1 set_user_tags feenix administrator
./rabbitmqctl -n rabbit1 set_permissions -p "/" feenix ".*" ".*" ".*"
同步集群中的.erlang.cookie文件
RabbitMQ是由Erlang语言写的,在安装Erlang环境依赖的时候,会在系统中生成一个.erlang.cookie文件,同一个集群中的.erlang.cookie文件如果不一致,启动的时候就会报错,一般来说,会将主节点的.erlang.cookie文件同步给其余从节点中:
搜索系统中.erlang.cookie的位置:locate .erlang.cookie

通过scp命令,将134服务的.erlang.cookie文件拷贝到135服务中:
scp ./.erlang.cookie root@192.168.126.135:`pwd`

RabbitMQ服务join成集群
停止135的RabbitMQ服务:./rabbitmqctl -n rabbit2 stop_app
重置135的RabbitMQ服务:./rabbitmqctl -n rabbit2 reset
将135的RabbitMQ服务作为从节点加入134服务的RabbitMQ服务:./rabbitmqctl -n rabbit2 join_cluster rabbit1@rabbitmq1
重启135的RabbitMQ服务:./rabbitmqctl -n rabbit2 start_app

此时再去访问134和135的RabbitMQ的图形界面,已经可以看到集群完成:

集群join完成之后,如果想要将某个RabbitMQ服务踢出群聊,只需将服务重置重启。比如现在想要将135的RabbitMQ服务踢出群聊,依次执行即可:
./rabbitmqctl -n rabbit2 stop_app
./rabbitmqctl -n rabbit2 reset
./rabbitmqctl -n rabbit2 start_app
设置集群镜像模式

配置好镜像模式之后,在134的RabbitMQ添加一个Queue,可以看到此队列所属的Node列后面有个+1标识,说明白不止有一个Node中含有这个队列:
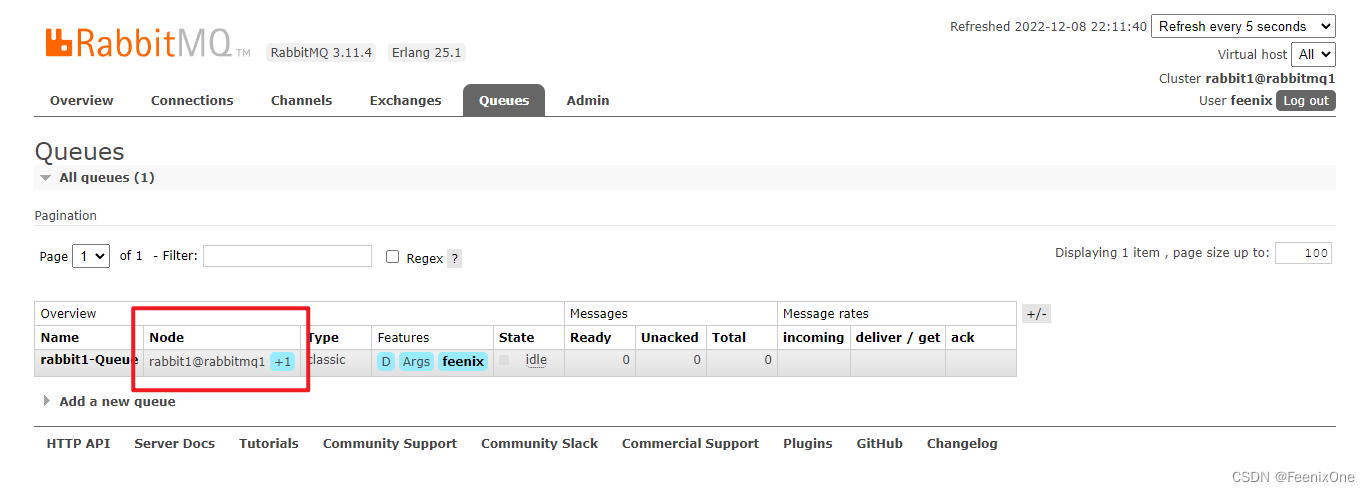
查看Queue的详情描述,此队列属于rabbit1,但在rabbit2中依然保存一份镜像:

在135的RabbitMQ服务中,确实看到对应的镜像队列:
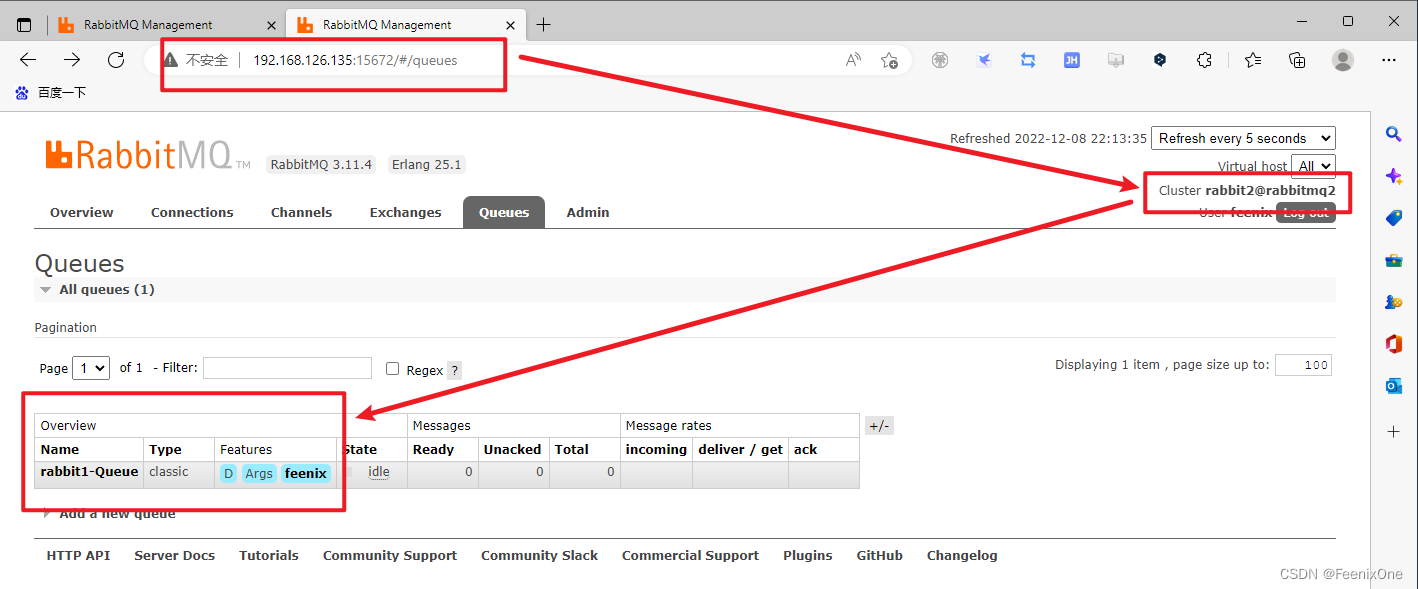
至此,RabbitMQ集群搭建完成。
![[附源码]JAVA毕业设计天津城建大学校友录管理系统(系统+LW)](https://img-blog.csdnimg.cn/76f5deff90dc46419940ff9dc5312136.png)