渠道归因(三)基于Shapley Value的渠道归因
通过Shapley Value可以计算每个渠道的贡献权重,而且沙普利值的计算只需要参加的渠道总数,不考虑顺序,因此计算成本也较低。
传统的shapeley value
import itertools
from pathlib import Path
from collections import defaultdict
from itertools import combinations, permutations
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
本文所有数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-渠道归因】自动获取~
# 读取数据
df_mark=pd.read_excel('./shapley/marketing.xlsx')
df_mark.head() # 渠道流转路径,该流转路径下成功转化的次数
数据格式要求:
marketing_channel_subset:渠道流转路径,英文逗号分隔
converted:成功转化次数
| marketing_channel_subset | converted | |
|---|---|---|
| 0 | 110 | |
| 1 | Email,Facebook | 11 |
| 2 | Email,Facebook,House Ads | 8 |
| 3 | Email,Facebook,House Ads,Instagram | 0 |
| 4 | Email,House Ads | 40 |
def power_set(List):
PS = [list(j) for i in range(len(List)) for j in itertools.combinations(List, i+1)]
return PS
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
def v_function(A,C_values):
'''
This function computes the worth of each coalition.
inputs:
- A : a coalition of channels.
- C_values : A dictionnary containing the number of conversions that each subset of channels has yielded.
'''
subsets_of_A = subsets(A)
worth_of_A=0
for subset in subsets_of_A:
if subset in C_values:
worth_of_A += C_values[subset]
return worth_of_A
def subsets(s):
'''
This function returns all the possible subsets of a set of channels.
input :
- s: a set of channels.
'''
if len(s)==1:
return s
else:
sub_channels=[]
for i in range(1,len(s)+1):
sub_channels.extend(map(list,itertools.combinations(s, i)))
return list(map(",".join,map(sorted,sub_channels)))
def calculate_shapley(df, channel_name, conv_name):
'''
This function returns the shapley values
- df: A dataframe with the two columns: ['channel_subset', 'count'].
The channel_subset column is the channel(s) associated with the conversion and the count is the sum of the conversions.
- channel_name: A string that is the name of the channel column
- conv_name: A string that is the name of the column with conversions
**Make sure that that each value in channel_subset is in alphabetical order. Email,PPC and PPC,Email are the same
in regards to this analysis and should be combined under Email,PPC.
'''
# casting the subset into dict, and getting the unique channels
c_values = df.set_index(channel_name).to_dict()[conv_name]
df['channels'] = df[channel_name].apply(lambda x: x if len(x.split(",")) == 1 else np.nan)
channels = list(df['channels'].dropna().unique())
v_values = {}
for A in power_set(channels): #generate all possible channel combination
v_values[','.join(sorted(A))] = v_function(A,c_values)
n=len(channels) #no. of channels
shapley_values = defaultdict(int)
for channel in channels:
for A in v_values.keys():
if channel not in A.split(","):
cardinal_A=len(A.split(","))
A_with_channel = A.split(",")
A_with_channel.append(channel)
A_with_channel=",".join(sorted(A_with_channel))
weight = (factorial(cardinal_A)*factorial(n-cardinal_A-1)/factorial(n)) # Weight = |S|!(n-|S|-1)!/n!
contrib = (v_values[A_with_channel]-v_values[A]) # Marginal contribution = v(S U {i})-v(S)
shapley_values[channel] += weight * contrib
# Add the term corresponding to the empty set
shapley_values[channel]+= v_values[channel]/n
return shapley_values
# 计算渠道shapley value--不考虑顺序
shapley_dict = calculate_shapley(df_mark, 'marketing_channel_subset', 'converted')
shapley_result = pd.DataFrame(list(shapley_dict.items()), columns=['channel', 'shapley_value'])
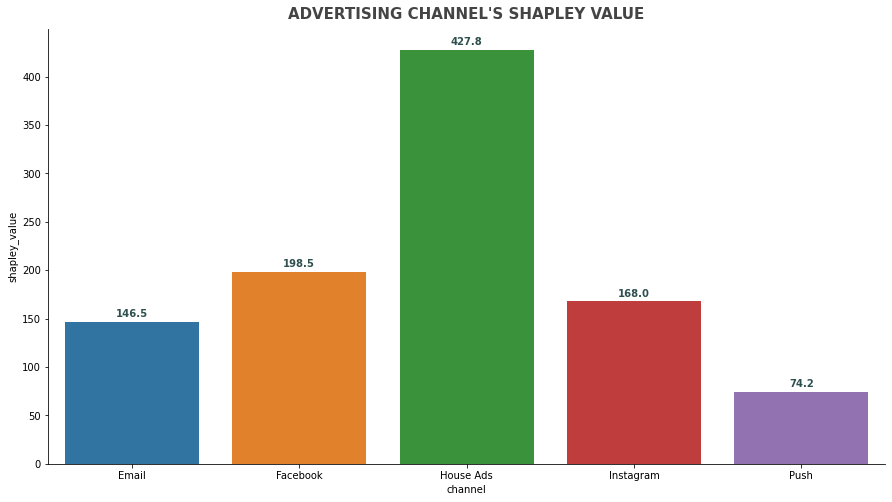
# 绘制条形图
plt.subplots(figsize=(15,8))
s = sns.barplot(x='channel', y='shapley_value', data=shapley_result)
sns.despine(top=True, right=True)
for idx, row in shapley_result.iterrows():
s.text(row.name, row.shapley_value +5, round(row.shapley_value,1), ha='center', color='darkslategray', fontweight='semibold')
plt.title("ADVERTISING CHANNEL'S SHAPLEY VALUE",
fontdict={'fontsize': 15, 'fontweight': 'semibold', 'color':'#444444'},
loc='center', pad=10)
plt.show()
升级版的shapeley value
import json
import os
# 加载自定义模块
import sys
sys.path.append("./shapley/")
from ordered_shapley_attribution_model import OrderedShapleyAttributionModel
from simplified_shapley_attribution_model import SimplifiedShapleyAttributionModel
# 读取数据
with open("./shapley/user_journeys.json", "r") as f:
journeys = json.load(f)
journeys[:5] # 用户各渠道流转日志,数字表示渠道代号
数据格式要求:json数据,每一行为成功转化的流转路径,数字为渠道ID
[[16, 4, 3, 5, 10, 8, 6, 8, 13, 20],
[2, 1, 9, 10, 1, 4, 3],
[9, 13, 20, 16, 15],
[8, 15, 20],
[16, 9, 13, 20]]
- 简单模式-不考虑顺序
# 简单模式计算shapley value--不考虑顺序
sab = SimplifiedShapleyAttributionModel()
result = sab.attribute(journeys)
# 输出渠道shapley value
print(f"Total value: {len(journeys)}")
total = 0
for k, v in result.items():
print(f"Channel {k}: {v:.2f}")
total += v
print(f"Total of attributed values: {total:.2f}")
Total value: 2392
Channel 1: 73.73
Channel 2: 92.38
Channel 3: 118.34
Channel 4: 248.21
Channel 5: 75.04
Channel 6: 55.02
Channel 7: 33.14
Channel 8: 52.95
Channel 9: 189.29
Channel 10: 209.82
Channel 11: 106.80
Channel 12: 77.08
Channel 13: 201.28
Channel 14: 55.02
Channel 15: 64.87
Channel 16: 154.71
Channel 17: 76.80
Channel 18: 5.06
Channel 19: 12.55
Channel 20: 489.91
Total of attributed values: 2392.00
- 有序模式-考虑顺序
# 有序模式计算shapley value--考虑顺序
# 计算时间过长,非必要可不执行
oab = OrderedShapleyAttributionModel()
result = oab.attribute(journeys)

# 输出渠道shapley value
print(f"Total value: {len(journeys)}")
total = 0
for k, v in result.items():
vsum = sum(v)
print(f"Channel {k}: {vsum}")
total += vsum
print(f"Total of attributed values: {total:.2f}")
Total value: 2392
Channel 1: 73.7267357642357
Channel 2: 92.37534687534699
Channel 3: 118.34282245532259
Channel 4: 248.20742174492216
Channel 5: 75.04331640581641
Channel 6: 55.01952491952489
Channel 7: 33.14323315573315
Channel 8: 52.95273476523473
Channel 9: 189.29054972804988
Channel 10: 209.8151168276172
Channel 11: 106.80050643800645
Channel 12: 77.07776806526806
Channel 13: 201.28108696858718
Channel 14: 55.01896853146851
Channel 15: 64.87037268287267
Channel 16: 154.71344627594635
Channel 17: 76.80483127983123
Channel 18: 5.057539682539683
Channel 19: 12.55146103896104
Channel 20: 489.9072163947167
Total of attributed values: 2392.00
可能是数据原因,两者的结果差异不大。
总结
日常业务中,可以结合多个方法看一下归因的差异。
共勉~
参考
python实现Shapley Value
Multi-Touch-Attribution_ShapleyValue官方示例
Shapley Value Methods for Attribution Modeling官方示例





![[已解决]Running setup.py install for MinkowskiEngine ... error](https://img-blog.csdnimg.cn/6030787cf4f54dcd810ae5ea3fd00827.png)