transformer的细节到底是怎么样的?Transformer 连环18问!
4.1 从功能角度,Transformer Encoder的核心作用是提取特征,也有使用Transformer Decoder来提取特征。例如,一个人学习跳舞,Encoder是看别人是如何跳舞的,Decoder是将学习到的经验和记忆,展现出来
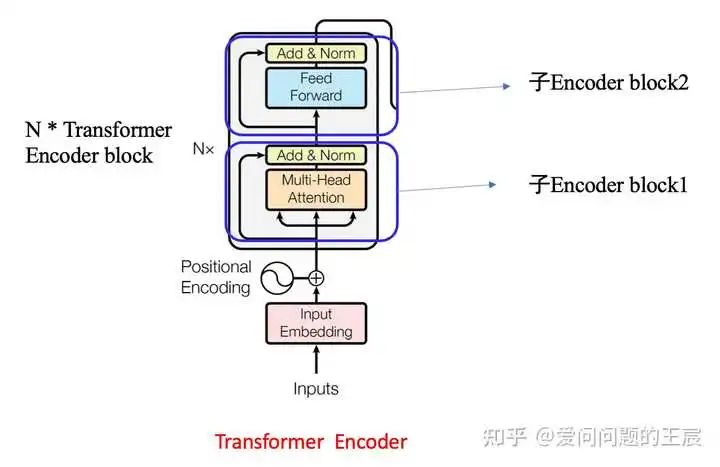
4.2 从结构角度,如图5所示,Transformer Encoder = Embedding + Positional Embedding + N*(子Encoder block1 + 子Encoder block2);
子Encoder block1 = Multi head attention + ADD + Norm;
子Encoder block2 = Feed Forward + ADD + Norm;
4.3 从输入输出角度,N个Transformer Encoder block中的第一个Encoder block的输入为一组向量 X = (Embedding + Positional Embedding),向量维度通常为512*512,其他N个TransformerEncoder block的输入为上一个 Transformer Encoder block的输出,输出向量的维度也为512*512(输入输出大小相同)。
4.4 为什么是512*512?前者是指token的个数,如“我爱学习”是4个token,这里设置为512是为了囊括不同的序列长度,不够时padding。后者是指每一个token生成的向量维度,也就是每一个token使用一个序列长度为512的向量表示。人们常说,Transformer不能超过512,否则硬件很难支撑;其实512是指前者,也就是token的个数,因为每一个token要做self attention操作;但是后者的512不宜过大,否则计算起来也很慢。

5.1 从功能角度,相比于Transformer Encoder,Transformer Decoder更擅长做生成式任务,尤其对于自然语言处理问题。
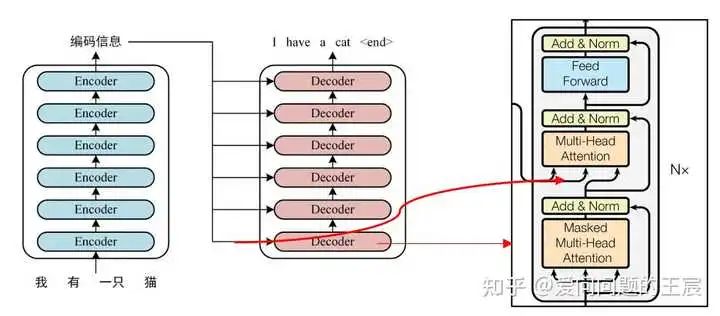
5.2 从结构角度,如图6所示,Transformer Decoder = Embedding + Positional Embedding + N*(子Decoder block1 + 子Decoder block2 + 子Decoder block3)+ Linear + Softmax;
子Decoder block1 = Mask Multi head attention + ADD + Norm;
子Decoder block2 = Multi head attention + ADD + Norm;
子Decoder block3 = Feed Forward + ADD + Norm;
5.3 从(Embedding+Positional Embedding)(N个Decoder block)(Linear + softmax) 这三个每一个单独作用角度:
Embedding + Positional Embedding :以机器翻译为例,输入“Machine Learning”,输出“机器学习”;这里的Embedding是把“机器学习”也转化成向量的形式。
N个Decoder block:特征处理和传递过程。
Linear + softmax:softmax是预测下一个词出现的概率,如图7所示,前面的Linear层类似于分类网络(ResNet18)最后分类层前接的MLP层。
6. Transformer Encoder和Transformer
Decoder有哪些不同?
6.1 作用上,Transformer Encoder常用来提取特征,Transformer Decoder常用于生成式任务。Transformer Encoder和Transformer Decoder是两条不同的技术路线,Bert采用的前者,GPT系列模型采用的是后者。
6.2 结构上,Transformer Decoder block包括了3个子Decoder block,而Transformer Encoder block 包括2个子Encoder block,且Transformer Decoder中使用了Mask multi-head Attention。
6.3 从二者的输入输出角度,N个Transformer Encoder运算完成之后,它的输出才正式输入进Transformer Decoder,作为QKV中的K和V,给Transformer Decoder使用。那么TransformerEncoder最后层的输出是如何送给Decoder呢?
7. 什么是Embedding?
7.1 Embedding在Transformer架构中的位置如图13所示。
7.2 提出背景: 计算机无法直接处理一个单词或者一个汉字,需要把一个token转化成计算机可以识别的向量,这也就是embedding过程。
7.3 实现方式: 最简单的embedding操作就是one hot vector,但one hot vector有一个弊端就是没有考虑词语前后之间的关系,后来也就产生了WordEmbedding,如图13。