模拟日志数据。。
日志模拟器主要模拟站点的用户信息和用户行为日志数据 使用shell调用java类实现数据的生产 !
所需文件如下:
datagen.jar
genlog.sh
注意: 存储数据的文件夹要预先创建好
| Bash
mkdir -p /tmp/doit/user_data
mkdir -p /tmp/doit/log_data |
| 将用来模拟生成数据的jar包和脚本下载后上传到Linux到指定位置,我当前是放到了/tmp/doit目录下,也可以放到任意目录下 |
执行sh脚本文件 ,内部调用datagen.jar中的java类生成特定格式的数据!
| Shell
#!/bin/bash
# $1 生成数据的种类:user | log
# 如果生成user
# $2 如果生成user,则是user数据的用户量
# $3 如果生成user,则是user数据的输出路径(到文件名)
# ===================================================
# 如果生成log
# $2, 在线人数
# $3, 要生成的日期
# $4, 1:流式生成 0:批量生成
# $5, user数据的路径
# $6, 日志数据的输出路径(到目录)
# $7, 是否日志模式(每行flush)
# =====================================================
# 注意脚本中的java环境变量 修改成自己对应的位置
export JAVA_HOME=/opt/apps/jdk1.8.0_191/
if [ $1 = user ];then
echo "generating user data ..."
$JAVA_HOME/bin/java -cp datagen.jar cn.doitedu.datagen.beans.GenUsers $2 $3 &
fi
# 生成日志数据
if [ $1 = log ];then
echo "generating log data ..."
$JAVA_HOME/bin/java -jar datagen.jar ${2} ${3} ${4} ${5} ${6} ${7} &
fi |
首先准备虚拟机环境 , 必须有java开发环境 ! 将所需的脚本文件和Jar包上传到指定的虚拟机中!
1.1 模拟用户数据
生成用户数据
| Shell
# 初始化用户数据(10000000代表公司的用户总量级别)
sh genlog.sh user 100000 /tmp/doit/user_data/user.json |
扩展:
- 用户数据信息是存储在MySQL这样的关系型数据库中 ,
- 可以修改日志生成脚本,在生成用户的时候 将数据存储到MySQL中
1.2 模拟日志数据
为公司生成1000W用户 , 日志可以滚动生成也可以批量生成
| Bash
# 流式生成日志(200000代表当天在活跃用户总量)
# sh genlog.sh log 20000 2022-03-10_08:30:00 1 /tmp/doit/user_data/user.json /tmp/doit/log_data 1
# 批量生成日志
sh genlog.sh log 20000 2022-07-09_11:11:11 0 /tmp/doit/user_data/user.json /tmp/doit/log_data 0 |
user数据
| JSON
{
"account":"uqifgm", 账号信息
"appId":"cn.doitedu.yinew", appid的id
"appVersion":"2.6", app版本
"carrier":"中国电信", 网络运营商
"deviceId":"mtuh-5076", 设备ID
"deviceType":"iphone8", 设备类型
"ip":"11.20.101.60", ip地址
"latitude":24.423377357669455, 纬度
"longitude":110.3516456329476, 经度
"netType":"4G", 网络类型 5G 3G 4G wifi
"osName":"ios", 设备操作系统
"osVersion":"9.0",设备操作系统版本
"platForm":"apple", 品牌
"releaseChannel":"apple-store", 软件下载渠道
"resolution":"1366*768", 分辨率
"testGuid":70, 唯一标识 uid
"timeStamp":0 时间戳
} |
用户行为数据结构
| JSON
{
"account":"udedtx", 账号信息
"appId":"cn.doitedu.yinew", appID
"appVersion":"2.1", app版本
"carrier":"中国联通", 网路运营商
"deviceId":"nldo-3377", 设备ID
"deviceType":"iphone9", 设备类型
"eventId":"e_jf_2", 事件名 id addCar pageView shareItem Adshow submitOrder
"ip":"11.21.100.60", ip地址
"latitude":39.67027988823277, 纬度
"longitude":115.30205505724112, 经度
"netType":"4G", 网络类型
"osName":"ios", 系统名
"osVersion":"8.0", 系统版本
"platForm":"apple", 品牌
"properties":{"ad_id":"v4","p18":"v4","pageId":"page001"},用来描述事件的数据 , 比如Adshow Adshow
"releaseChannel":"apple-store", 下载渠道
"resolution":"1280*768", 分辨率
"sessionId":"LTLTNUOJBQ", 会话id
"testGuid":15, 用户的唯一标识uid
"timeStamp":1657955995935 产生数据的时间 , 事件发生的时间
} |
| session 理解(会话) session会话: 在JavaEE中用来记录用户一次访问(产生的数据)信息 利用sessionID会话 统计用户的访问次数 , 访问时长 关键维度 |
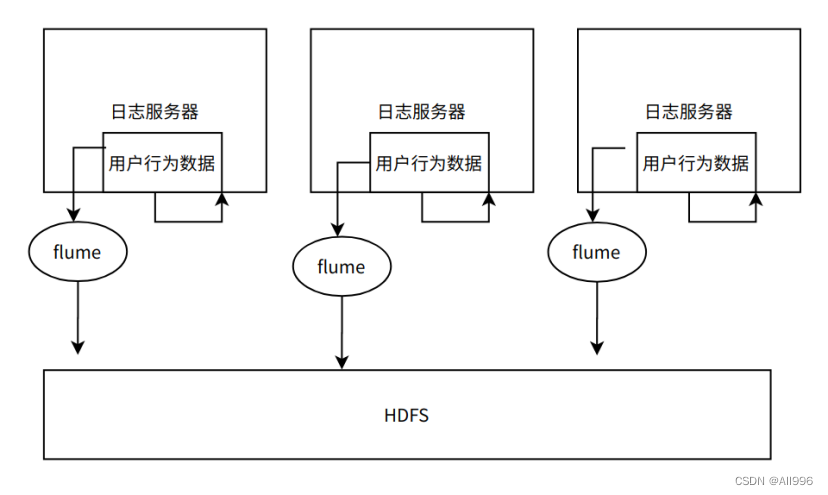
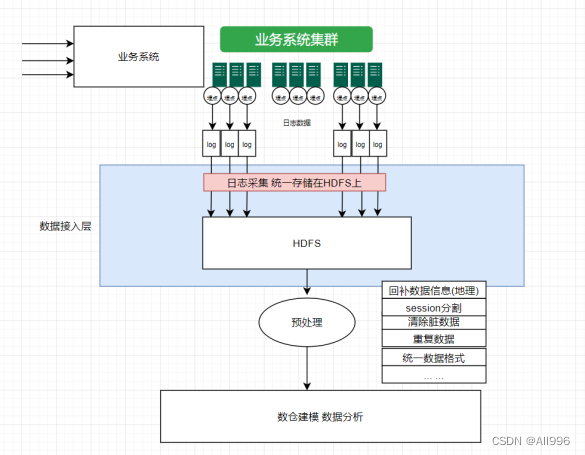
接下来我们对数据接入层进行开发:
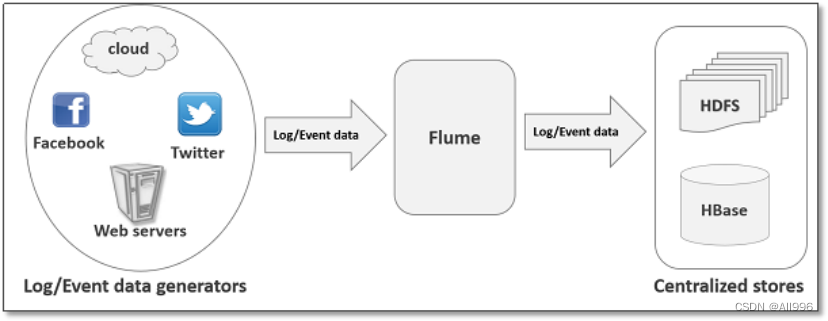
2 flume快速入门
2.1 简介
2.1.1 什么是flume
flume是由cloudera软件公司产出的可分布式日志收集系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng; 同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一. 补充:cloudera公司的主打产品是CDH(hadoop的一个企业级商业发行版)
可以从各种各样的数据源(服务器)上采集数据传输(汇聚)到大数据生态的各种存储系统中(Hdfs、hbase、hive、kafka); 开箱即用!(安装部署、修改配置文件)
2.1.2 flume的特性
Flume是一个分布式、可靠、 高可用的海量日志采集、汇聚和传输的系统。 Flume可以采集文件,socket数据包(网络端口)、文件夹、kafka、mysql数据库等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中 一般的采集、传输需求,通过对flume的简单配置即可实现;不用开发一行代码! Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景 。
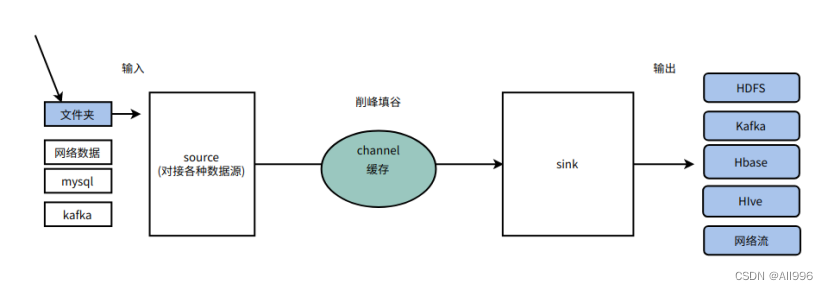
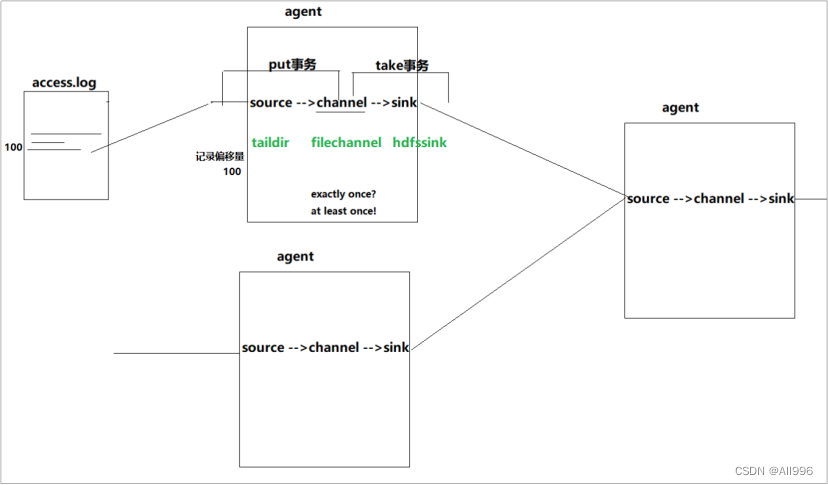
2.2 agent基本认识
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。 对于每一个Agent来说 ,它就是一个独立的守护进程(JVM) ,它负责从数据源接收数据,并发往下一个目的地,如下图所示:
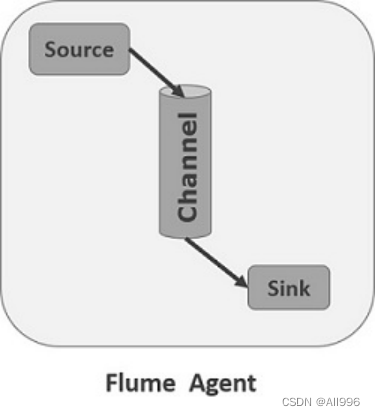
| 每一个agent相当于一条数据(被封装成Event对象)传递员,内部有3个核心组件: |
- Source:数据源组件,用于跟数据源对接,以获取数据;它有各种各样的内置实现;
- Sink:下沉组件,用于往下一级agent传递数据或者向最终存储系统传递数据
- Channel:传输通道组件(缓冲区),用于协调和解耦source & sink
source和sink之间解耦合,以及异步操作; (channel可以让source组件和sink组件解耦合,并对数据源产生数据的速度波动起到削峰填谷的作用)
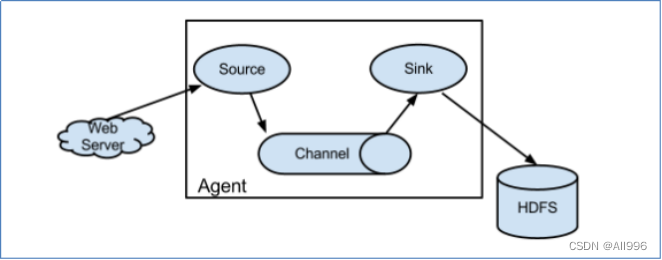
| 通过agent的级联,可以组建出复杂的数据传输网络 |
- 单个agent采集数据
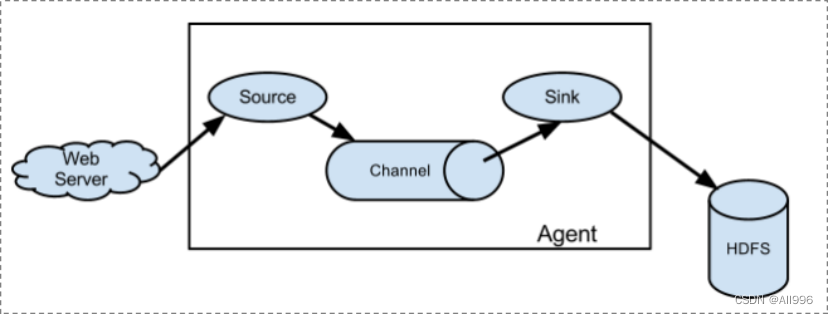

2.3 agent内部组件详解
2.4 agent内部组件架构图
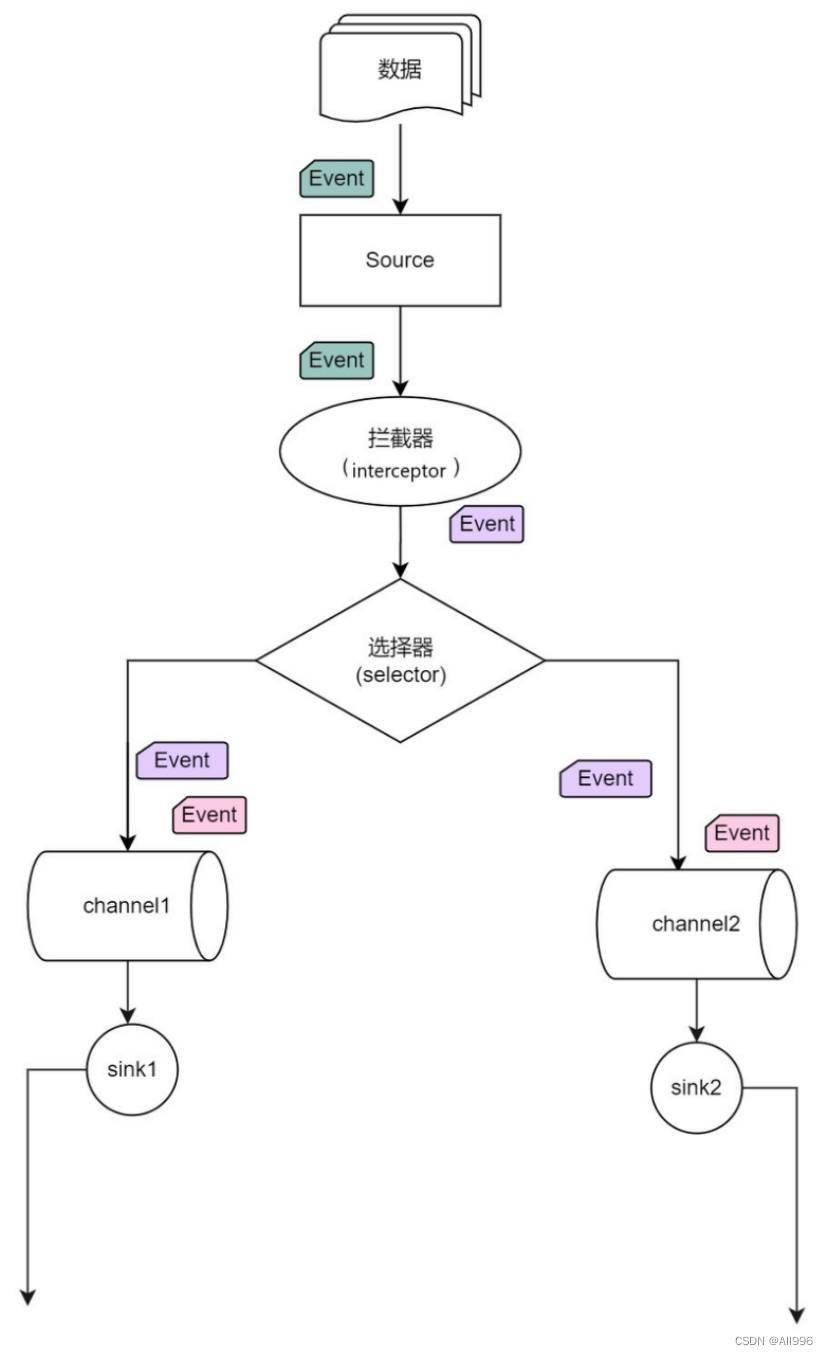
2.4.1 Event
数据agent内部数据流转的封装形式;
Source组件在获取到原始数据后,需要封装成Event放入channel; Sink组件从channel中取出Event后,需要根据目标存储的需求,转成其他形式的数据输出。
Event封装对象主要有两部分组成: Headers和 Body header是一个集合 Map[String,String],用于携带一些KV形式的元数据(标志、描述等) body: 就是一个字节数组byte[];装载具体的数据内容
| Shell
Event: {
headers:HashMap<String,String> ==> {host=doitedu01,timestamp=17623745832457} 元数据
body:byte[] ==> 61 20 61 20 61 61 61 20 61 20 0D 字节数据
} |
2.4.2 interceptor拦截器
拦截器,就是为用户提供添加数据处理逻辑的可能性
拦截器工作在source组件之后,source产生的event会被传入拦截器根据需要进行拦截处理 而且,拦截器可以组成拦截器链! 拦截器在flume中有一些内置的功能比较常用的拦截器 用户也可以根据自己的数据处理需求,自己开发自定义拦截器! 这也是flume的一个可以用来自定义扩展的接口!
2.4.3 channel selector
一个source可以对接多个channel,则event在这n个channel之间传递的策略,由配置的channel selector决定;
channel selector有2中实现: replicating(复制),multiplexing(多路复用)
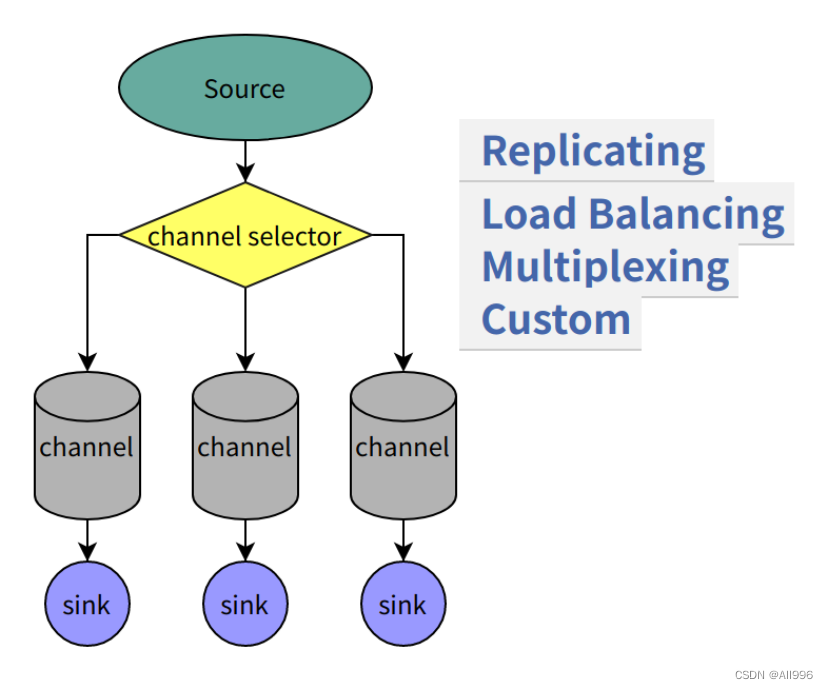
2.4.4 sink processor
如果sink和channel是一对一关系,则不需要专门的sink processor;
如果一个channel配置多个sink,则可以将这多个sink配置成一个sink group(sink组);
event在一个组中的多个sink间如何传递,则由所配置的sink processor来决定;
sink processor有2种: load balance (round robing)和 fail over
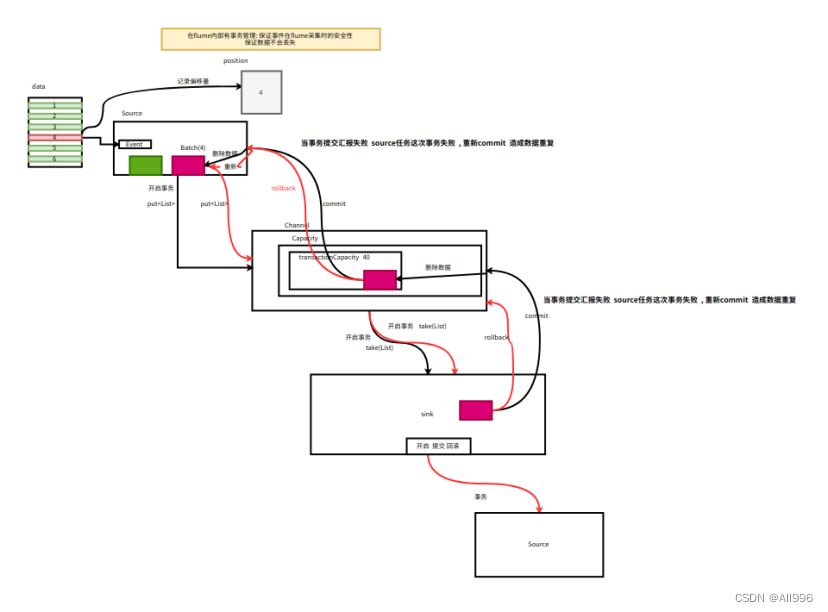
2.5 Transaction:事务机制 (数据传递语义)
数据传递的三个语义:
Flume并没有实现Exactly once!
Flume使用两个独立的事务:
- put操作:source读取数据源并写入event到channel
- take操作:sink从channel中获取event并写出到目标存储
事务的实现程度,取决于运行时所选择的具体的组件实现类;
再好的组件的组合,也只实现到了at least once!(不会丢失数据,但可能产生重复传输)
事务实现的核心点,是记录状态(比如source,记录自己完成的数据的偏移量)
比如spooling directory source 为文件的每一个event batch创建一个事务,来记录状态,一旦事务中所有的事件全部传递到channel且提交成功,那么soucrce就将event batch标记为完成。
同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚,且所有的事件都会保持到channel中,等待重新传递。
事务机制涉及到如下重要参数:
- a1.sources.s1.batchSize =100
- a1.sinks.k1.batchSize = 200
- a1.channels.c1.transactionCapacity = 300 (应该大于source或者sink的batchSize)
< transactionCapacity 是说,channel中保存的事务的个数>
跟channel的数据缓存空间容量区别开来: a1.channels.c1.capacity = 10000

那么事务是如何保证数据的端到端完整性的呢?看下面有两个agent的情况:

数据流程:
- source 1产生Event,通过“put”、“commit”操作将Event放到Channel 1中
- sink 1通过“take”操作从Channel 1中取出Event,并把它发送到Source 2中
- source 2通过“put”、“commit”操作将Event放到Channel 2中
- source 2向sink 1发送成功信号,sink 1“commit”步骤2中的“take”操作(其实就是删除Channel 1中的Event)
说明:在任何时刻,Event至少在一个Channel中是完整有效的
| 事务原理基本流程 事务能保证数据在采集的过程中 在agent内部和agent之间不会丢失数据 但是如果事务提交汇报失败 , 成功处理的事务会被再次提交 出现数据重复问题 处理的数据语义是 : 至少处理一次! 重复的数据 后续的可以通过去重 |
2.6 安装部署
2.6.1 参数设置
Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
1、上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.8.0-bin.tar.gz
配置环境变量
修改参数 vi flume-env.sh
| Shell
export JAVA_HOME=/opt/apps/jdk1.8.0_191/
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
export JAVA_OPTS="-Xms1000m -Xmx2000m -Dcom.sun.management.jmxremote" |
2、根据数据采集的需求配置采集方案(用什么类型的source,channel,sink),描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
4 创建日志采集配置文件目录
| Plain Text
[root@doitedu01 flume-1.9.0]# mkdir props
[root@doitedu01 flume-1.9.0]# ll
total 168
drwxr-xr-x. 2 dolphinscheduler dolphinscheduler 62 Jul 16 17:22 bin
-rw-rw-r--. 1 dolphinscheduler dolphinscheduler 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x. 2 dolphinscheduler dolphinscheduler 118 Jul 16 17:26 conf
-rw-r--r--. 1 dolphinscheduler dolphinscheduler 5681 Nov 16 2017 DEVNOTES
-rw-r--r--. 1 dolphinscheduler dolphinscheduler 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x. 12 dolphinscheduler dolphinscheduler 4096 Dec 18 2018 docs
drwxr-xr-x. 2 root root 8192 Jul 16 17:22 lib
-rw-rw-r--. 1 dolphinscheduler dolphinscheduler 43405 Dec 10 2018 LICENSE
-rw-r--r--. 1 dolphinscheduler dolphinscheduler 249 Nov 29 2018 NOTICE
-- flume工作时通过加载配置文件进行采集数据的 , 以后的采集数的方案配置在当前props目录下
drwxr-xr-x. 2 root root 6 Jul 16 17:28 props
-rw-r--r--. 1 dolphinscheduler dolphinscheduler 2483 Nov 16 2017 README.md
-rw-rw-r--. 1 dolphinscheduler dolphinscheduler 1958 Dec 10 2018 RELEASE-NOTES
drwxr-xr-x. 2 root root 68 Jul 16 17:22 tools |
以后要是想采集数据 只需要配置一个日志采集的配置文件即可 local_file_2_hdfs.conf
local_file_2_hdfs.conf: source channel sink
bin/flume-ng agent -f local_file_2_hdfs.conf 自动的加载配置文件 采集数据
2.6.2 启动
指定配置目录
bin/flume-ng help 查看flume支持的指令参数
| Shell
commands:
help 显示本帮助信息
agent 启动一个agent进程 采集方案
avro-client 启动一个用于测试avro source的客户端(能够发送avro序列化流)
version 显示当前flume的版本信息
global options: 全局通用选项
--conf,-c <conf> 指定flume的系统配置文件所在目录
--classpath,-C <cp> 添加额外的jar路径
--dryrun,-d 不去真实启动flume agent,而是打印当前命令
--plugins-path <dirs> 指定插件(jar)所在路径
-Dproperty=value 传入java环境参数
-Xproperty=value 传入所需的JVM配置参数
agent options:
--name,-n <name> agent的别名(在用户采集方案配置文件中)
--conf-file,-f <file> 指定用户采集方案配置文件的路径
--zkConnString,-z <str> 指定zookeeper的连接地址
--zkBasePath,-p <path> 指定用户配置文件所在的zookeeper path,比如:/flume/config
--no-reload-conf 关闭配置文件动态加载
--help,-h display help text
avro-client options:
--rpcProps,-P <file> RPC client properties file with server connection params
--host,-H <host> avro序列化数据所要发往的目标主机(avro source所在机器)
--port,-p <port> avro序列化数据所要发往的目标主机的端口号
--dirname <dir> 需要被序列化发走的数据所在目录(提前准备好测试数据放在一个文件中)
--filename,-F <file> 需要被序列化发走的数据所在文件(default: std input)
--headerFile,-R <file> 存储header key-value的文件
--help,-h 帮助信息
Either --rpcProps or both --host and --port must be specified.
Note that if <conf> directory is specified, then it is always included first
in the classpath.
开启内置
HTTP监控功能
-Dflume.monitoring.type=http -Dflume.monitoring.port=34545
监控数据发往ganglia进行展现
-Dflume.monitoring.type=ganglia -Dflume.monitoring.port=34890 |