subprocess模块是Python标准库中的一个模块,用于创建和控制子进程。它提供了一种在Python程序中调用其他外部命令、执行系统命令和与系统进程进行交互的方法。常用的有两种方法:subprocess.run(),subprocess.Popen()
1. subprocess.run()方法
subprocess.run()是subprocess模块中一个常用的函数,也是官方推荐的方法,它用于运行命令并等待其完成。
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False, encoding=None, errors=None, text=None, cwd=None, env=None, universal_newlines=None)
常用参数说明:
- args:要执行的命令及其参数组成的列表或字符串。
- stdin:标准输入流(默认为None)。
- input:作为子进程的输入发送的数据(默认为None)。
- stdout:标准输出流(默认为None,表示将输出传递给父进程)。
- stderr:标准错误流(默认为None,表示将错误信息传递给父进程)。
- shell:是否通过系统shell执行命令(默认为False,即不使用shell执行)。
- timeout:超时时间,指定子进程允许执行的最长时间(默认为None)。
- check:如果子进程返回非零状态码,则抛出CalledProcessError异常(默认为False)。
- cwd:子进程的当前工作目录(默认为None,表示使用父进程的当前工作目录)。
subprocess.run()的详细用法介绍
- 示例1:运行命令并等待其完成
import subprocess
subprocess.run(['ls', '-l'])
执行结果:

- 示例2:通过shell执行命令
import subprocess
subprocess.run('echo Hello, World!', shell=True)
执行结果:

- 示例3:传递输入给子进程
import subprocess
subprocess.run(['grep', 'hello'], input=b'Hello, world!\nHello, Python!')
打印结果:

- 示例4:设置超时时间
import subprocess
try:
subprocess.run(['sleep', '10'], timeout=5)
except subprocess.TimeoutExpired:
print("Timeout reached")
打印结果:

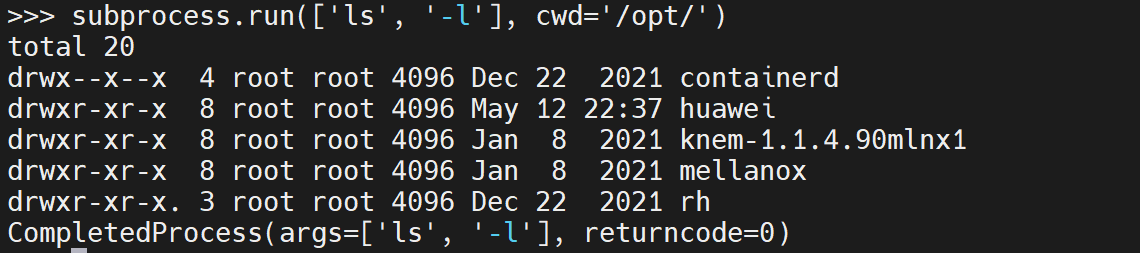
- 示例5:指定工作目录
import subprocess
subprocess.run(['ls', '-l'], cwd='/opt/')
打印结果:
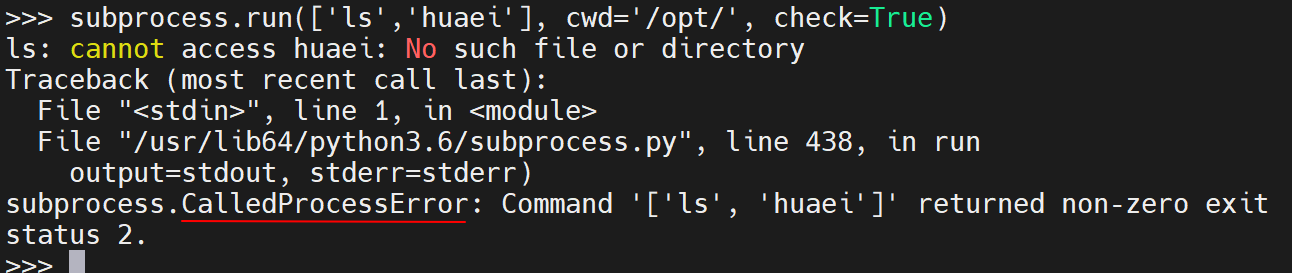
- 示例6:check
import subprocess
subprocess.run(['ls','huaei'], cwd='/opt/', check=True)
打印结果:
- 示例7:捕获脚本的输出
# 使用管道捕获输出
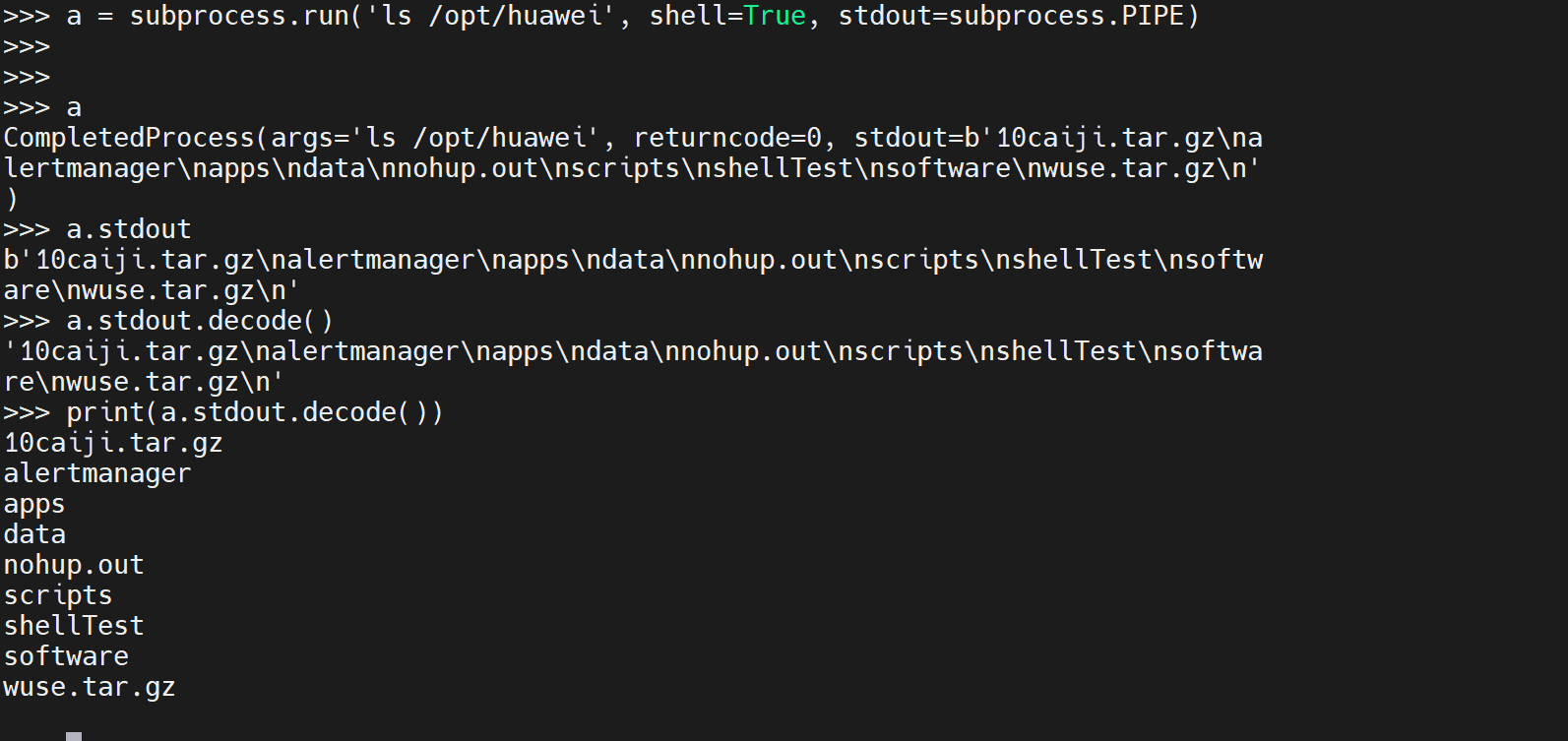
a = subprocess.run('ls /opt/huawei', shell=True, stdout=subprocess.PIPE)
打印结果:
2. subprocess.Popen()方法
subprocess.Popen()是subprocess模块中用于创建子进程的函数之一。它提供了更灵活的控制和处理子进程的能力。
subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=(), *, encoding=None, errors=None)
常用参数说明:
- args:要执行的命令及其参数组成的列表或字符串。
- executable:可执行文件路径或命令名称(默认为None)。
- stdin:标准输入流(默认为None)。
- stdout:标准输出流(默认为None)。
- stderr:标准错误流(默认为None)。
- preexec_fn:子进程创建前要调用的可调用对象(默认为None)。
- close_fds:在子进程中关闭不必要的文件描述符(默认为True)。
- shell:是否通过系统shell执行命令(默认为False)。
- cwd:子进程的当前工作目录(默认为None,表示使用父进程的当前工作目录)。
- env:子进程的环境变量(默认为None,表示使用父进程的环境变量)。
- universal_newlines:各种换行符统一成’\n’。
subprocess.Popen()的详细用法介绍
- 示例1:运行命令并捕获输出
import subprocess
process = subprocess.Popen(['ls', '-l'], stdout=subprocess.PIPE)
output, error = process.communicate()
print(output.decode())
打印结果:

- 示例2:传递输入给子进程并获取输出
process = subprocess.Popen(['grep', 'hello'], stdin=subprocess.PIPE, stdout=subprocess.PIPE)
# communicate:参数是标准输入,返回标准输出和标准出错
output, error = process.communicate(input=b'hello, world!')
print(output)
打印结果:

- 示例3:后台执行命令
subprocess.Popen(['sleep', '10'])
打印结果:

- 示例4:通过shell执行命令
subprocess.Popen('echo Hello, World!', shell=True)
打印结果:

- 示例5:指定工作目录和环境变量
subprocess.Popen(['ls', '-l'], cwd='/path/to/directory', env={'VAR': 'value'})
poll()方法
poll(): 该方法用于检查子进程是否已经结束,并返回子进程的返回码。如果子进程尚未结束,poll()会立即返回None;如果子进程已经结束,poll()会返回子进程的返回码。这个方法通常在你需要非阻塞地检查子进程状态时使用。
import subprocess
# 启动一个子进程
process = subprocess.Popen(['echo', 'Hello, world!'], stdout=subprocess.PIPE)
# 检查子进程是否结束
return_code = process.poll()
if return_code is None:
print("子进程尚未结束")
else:
print(f"子进程已结束,返回码: {return_code}")
打印结果:

wait()方法
wait(): 该方法用于等待子进程的结束,并返回子进程的返回码。如果子进程尚未结束,wait()方法会阻塞当前进程直到子进程结束。这个方法通常在你需要等待子进程执行完毕并获取其返回码时使用。
import subprocess
# 启动一个子进程
process = subprocess.Popen(['sleep', '5'])
# 等待子进程结束并获取返回码
return_code = process.wait()
print(f"子进程已结束,返回码: {return_code}")
打印结果:
等待5秒钟程序执行完成,才打印返回码