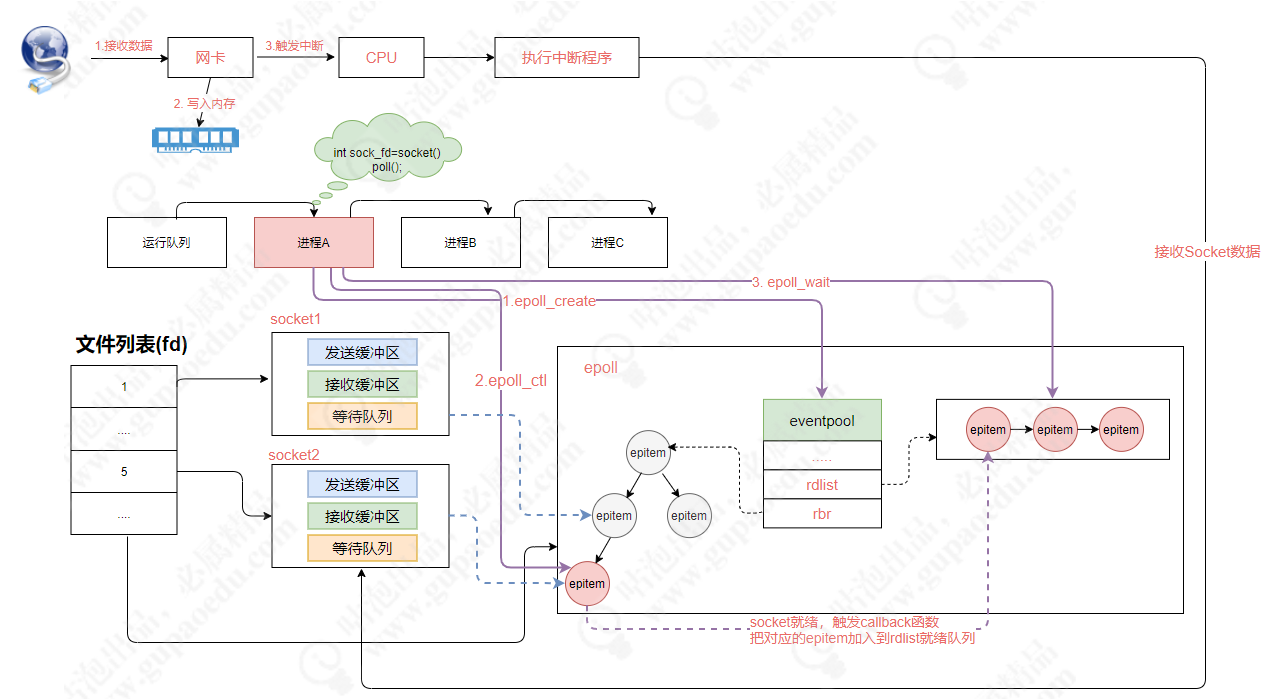
lua vm共享proto
场景
在skynet中,对于每一个lua服务,实际上就是在snlua上启动了一个lua虚拟机去完成lua逻辑,所以skynet的服务是相互隔离的。
这样就会产生一个问题,多个服务都require同一个lua库,每个服务内都会有一份这个lua库的拷贝,这样就会造成极大的内存浪费。云风因此对lua进行了一次patch,优化了这个问题。
由于云风的文档较老,代码又进行了新的变更,所以我重新阅读了一遍patch的源码以探究节省内存原理的真谛。
前置知识
closure
lua中,函数通常被表示为一个LClosure即使他没有upvalue,闭包是由函数原型的引用和该函数所需访问的外部局部变量 upvalue 组成。其中函数原型部分是可以被共享的。
//闭包
typedef struct LClosure {
ClosureHeader; //公共头部,用于gc
struct Proto *p; //函数原型
UpVal *upvals[1]; //upvalue链表
} LClosure;
//函数原型
typedef struct Proto {
CommonHeader;
lu_byte numparams; /* number of fixed (named) parameters 非可变参数数量*/
lu_byte is_vararg;
lu_byte maxstacksize; /* number of registers needed by this function 最大栈空间*/
int sizeupvalues; /* size of 'upvalues' upvalue数*/
int sizek; /* size of 'k' 常量表长度*/
int sizecode;
int sizelineinfo;
int sizep; /* size of 'p' 内嵌proto数*/
int sizelocvars;
int sizeabslineinfo; /* size of 'abslineinfo' */
int linedefined; /* debug information */
int lastlinedefined; /* debug information */
TValue *k; /* constants used by the function 常量表*/
Instruction *code; /* opcodes 操作码链表*/
struct Proto **p; /* functions defined inside the function 内嵌proto*/
Upvaldesc *upvalues; /* upvalue information upvalue描述(是否close等)*/
ls_byte *lineinfo; /* information about source lines (debug information) */
AbsLineInfo *abslineinfo; /* idem */
LocVar *locvars; /* information about local variables (debug information) */
TString *source; /* used for debug information */
GCObject *gclist;
} Proto;
require
实际上require大致分为两个过程,一是load过程,另一个是执行过程。load过程中,会通过文件流或者标准输入去读取脚本内容,并返回一个closure。执行过程中执行这个closure返回结果。而且require还有一个重要行为就是把执行结果缓存到package.loaded(modname->result)中,下次再次require,就会直接返回这个缓存。
load返回的closure执行之后,其结果中的函数原型和closure中的函数原型地址相同。因为,这个closure是lua_load中编译过的,因此其定义的函数原型会变成一个函数地址,并在执行脚本的过程中作为传入opcode中(之后我会证明这点),因此这份编译好的脚本不管执行多少次,函数原型的地址总是相同的。这也是多个虚拟机能共享同一个脚本去节省内存的关键。
//注册
static const luaL_Reg ll_funcs[] = {
{"require", ll_require},
{NULL, NULL}
};
//require流程
static int ll_require (lua_State *L) { //一个参数mod的名字
const char *name = luaL_checkstring(L, 1);
lua_settop(L, 1); //设置栈顶,就留一个元素
lua_getfield(L, LUA_REGISTRYINDEX, LUA_LOADED_TABLE); //获取registry["_LOADED"]也就是package.loaded表
lua_getfield(L, 2, name); //loaded[name]
if (lua_toboolean(L, -1)) //已经有了?
return 1; //直接返回模块
lua_pop(L, 1); //pop掉loaded[name]
findloader(L, name); //找到load脚本文件产生的closure
lua_rotate(L, -2, 1); //交换一下closure和data的顺序
lua_pushvalue(L, 1); /* name is 1st argument to module loader */
lua_pushvalue(L, -3); /* loader data is 2nd argument */
/* stack: ...; loader data; loader function; mod. name; loader data 栈中的元素顺序*/
lua_call(L, 2, 1); //运行这个closure
/* stack: ...; loader data; result from loader */
if (!lua_isnil(L, -1)) //非空
lua_setfield(L, 2, name); /* LOADED[name] = returned value */
else
lua_pop(L, 1); /* pop nil */
if (lua_getfield(L, 2, name) == LUA_TNIL) { //loaded[name]为空
lua_pushboolean(L, 1); //使用脚本执行结果
lua_copy(L, -1, -2); /* replace loader result */
lua_setfield(L, 2, name); /* LOADED[name] = true */
}
lua_rotate(L, -2, 1); /* loader data <-> module result */
return 2; /* return module result and loader data */
}
static void findloader (lua_State *L, const char *name) {
int i;
luaL_Buffer msg; /* to build error message */
/* push 'package.searchers' to index 3 in the stack */
if (l_unlikely(lua_getfield(L, lua_upvalueindex(1), "searchers")
!= LUA_TTABLE))
luaL_error(L, "'package.searchers' must be a table");
luaL_buffinit(L, &msg);
/* iterate over available searchers to find a loader 遍历serchers*/
for (i = 1; ; i++) {
luaL_addstring(&msg, "\n\t"); /* error-message prefix */
if (l_unlikely(lua_rawgeti(L, 3, i) == LUA_TNIL)) { //没有sercher了
lua_pop(L, 1); /* remove nil */
luaL_buffsub(&msg, 2); /* remove prefix */
luaL_pushresult(&msg); /* create error message */
luaL_error(L, "module '%s' not found:%s", name, lua_tostring(L, -1));
}
lua_pushstring(L, name); //找到了sercher
lua_call(L, 1, 2); //运行sercher,参数为name
if (lua_isfunction(L, -2)) //返回了closure?
return; /* module loader found */
else if (lua_isstring(L, -2)) { /* searcher returned error message? */
lua_pop(L, 1); /* remove extra return */
luaL_addvalue(&msg); /* concatenate error message */
}
else { /* no error message */
lua_pop(L, 2); /* remove both returns */
luaL_buffsub(&msg, 2); /* remove prefix */
}
}
}
//serchers有以下这些
static const lua_CFunction searchers[] = {
searcher_preload,
searcher_Lua,
searcher_C,
searcher_Croot,
NULL
};
//serchers在个函数里注册
static const luaL_Reg loadedlibs[] = {
...
{LUA_LOADLIBNAME, luaopen_package},
...
{NULL, NULL}
};
#define LUA_LOADLIBNAME "package" //调用package模块自动注册
字节码指令
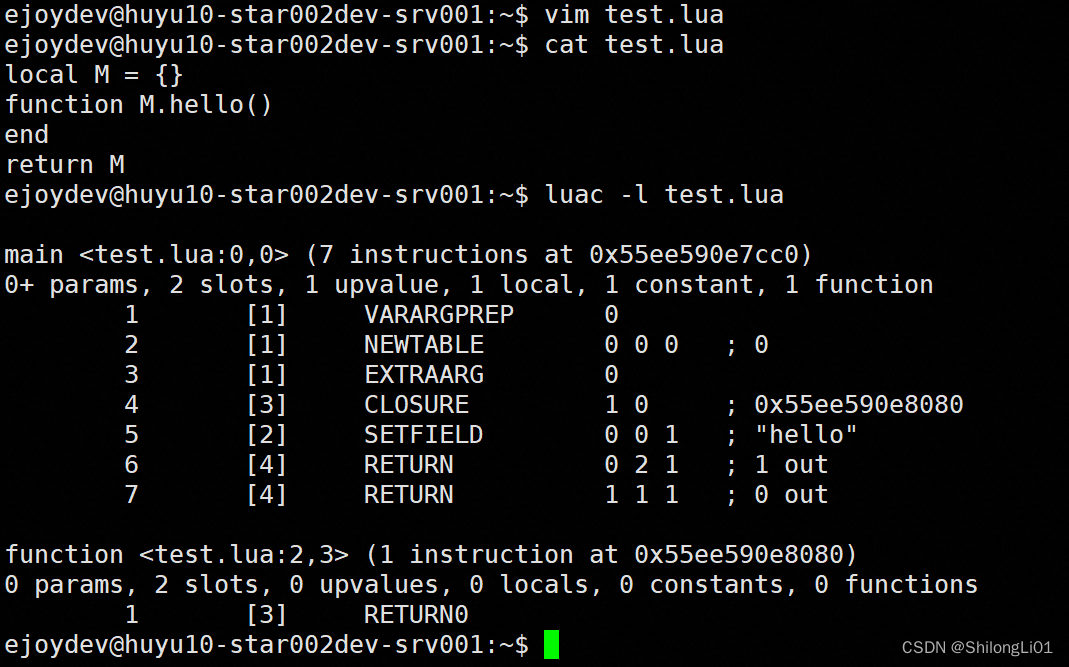
通过luac -l来查看lua文件编译出的字节码,load的编译结果也是这样。
其中CLOSURE为指定的函数prototype创建一个closure,而这个0x55ee590e8080就是函数原型的地址。可以看到下边创建出来的闭包中的函数原型地址就是脚本中编译后的地址。***这就是一个proto能共享的最重要的原因,同一份编译好的脚本运行后产生的闭包的函数原型的地址是相同的,因为函数原型加载到内存中的地址是编译中就被确定的。***所以最主要原因就是多个luastate各自load,编译过程中重复加载代码段到内存中导致内存浪费。
解决
因此,我们就明确了,那就是要防止一个模块多次load。首先我们要做一个cache缓存所有load过的模块。其次取缓存模块时,记得clone,把非共享部分单独创建,共享部分沿用。我们对每个load过的脚本用一个虚拟机进行存储,然后在cache中保存指向这个虚拟机内closure的指针,之后只要向cache查询就可以了,之所以要为每个文件分配一个虚拟机,主要原因是热更时未更新服务仍可引用旧模块且只有这个虚拟机才有权对这个模块进行gc,但是目前是永不gc的。这里引用云风的一句话,保留所有用过的函数在内存中这种做法是广泛存在的,如果你对比看 C 层次的函数,即使 C 函数存在于动态库中,我们也不能轻易卸载动态库,这有让其它模块保留过动态库中函数指针变得无效。
cache
我们的目标是创造一个共享的cache,所有的虚拟机都可以访问到这个cache,并且我们要保证这个cache是线程安全的。
接下来让我们看看实现:
- 缓存结构
struct codecache {
struct spinlock lock;
lua_State *L; //可以看到缓存在虚拟机中进行映射
};
static struct codecache CC;
static void
init(void) { //初始化
CC.L = luaL_newstate(); //创建虚拟机
}
- 更改cache模式
cache总共分为三个模式,OFF代表不进行任何缓存,重复load,ON代表进行缓存,EXIST代表复用缓存但不进行新的缓存。默认为ON。
//接收一个参数,设置相应模式,参数为空代表获取当前模式
static int cache_mode(lua_State *L) {
static const char * lst[] = {
"OFF",
"EXIST",
"ON",
NULL,
};
int t,r;
if (lua_isnoneornil(L,1)) { //参数为空
t = lua_rawgetp(L, LUA_REGISTRYINDEX, &cache_key); //获得registry[cache_key]的类型并压栈registry[*(int*)cache_key]
r = lua_tointeger(L, -1); //registry[cache_key]
if (t == LUA_TNUMBER) { //类型为数字?
if (r < 0 || r >= CACHE_ON) { //非法全部默认为ON
r = CACHE_ON;
}
} else {
r = CACHE_ON;
}
lua_pushstring(L, lst[r]); //返回模式名
return 1;
}
t = luaL_checkoption(L, 1, "OFF" , lst); //"OFF"所在索引
lua_pushinteger(L, t); //索引压栈
lua_rawsetp(L, LUA_REGISTRYINDEX, &cache_key); //registry[*(int*)cache_key]=t
return 0;
}
- 清除缓存
static int
cache_clear(lua_State *L) {
(void)(L);
clearcache(); //清除缓存
return 0;
}
static void
clearcache(void) {
if (CC.L == NULL)
return;
SPIN_LOCK(&CC)
lua_close(CC.L); //关闭虚拟机
CC.L = luaL_newstate(); //新建虚拟机
SPIN_UNLOCK(&CC)
}
//注意清除缓存后,虚拟机不再映射任何缓存,所以之前的缓存永远不会释放,内存泄漏。
//引用云风的话
//为了 skynet 服务器可以热更新 lua 脚本,还增加了 clear cache 的方法(skynet.cache.clear),可以将 cache 重置。当然,之前加载过的代码其实是没有从内存中清理掉的,这一定程度上会带来一些内存泄露。但考虑到这个 patch 可以给系统节约的内存,不是过于频繁的热更新是可以接受的。
- 加载脚本
LUALIB_API int luaL_loadfilex (lua_State *L, const char *filename,
const char *mode) {
int level = cache_level(L); //获得当前的cache模式
const void * proto;
lua_State * eL; //新的模块的虚拟机指针
int err;
const void * oldv;
if (level == CACHE_OFF) { //cache关
return luaL_loadfilex_(L, filename, mode); //load
}
proto = load_proto(filename); //查缓存
if (proto) {
lua_clonefunction(L, proto); //有就clone一份返回
return LUA_OK;
}
if (level == CACHE_EXIST) { //CACHE_EXIST模式
return luaL_loadfilex_(L, filename, mode); //直接加载不进行下边的缓存
}
eL = luaL_newstate(); //为新文件创建虚拟机
if (eL == NULL) {
lua_pushliteral(L, "New state failed");
return LUA_ERRMEM;
}
err = luaL_loadfilex_(eL, filename, mode); //加载到这个创建的虚拟机中
if (err != LUA_OK) { //失败
size_t sz = 0;
const char * msg = lua_tolstring(eL, -1, &sz);
lua_pushlstring(L, msg, sz);
lua_close(eL);
return err;
}
lua_sharefunction(eL, -1); //设置加载的脚本为share(不被gc)
proto = lua_topointer(eL, -1); //获取脚本指针
oldv = save_proto(filename, proto); //在cache虚拟机中保存存映射<filename,proto>
if (oldv) { //如果原有这个文件,说明重新加载了
lua_close(eL);
lua_clonefunction(L, oldv);
} else {
lua_clonefunction(L, proto); //clone一个返回
/* Never close it. notice: memory leak */
}
return LUA_OK;
}
- 查缓存
static const void *
load_proto(const char *key) {
lua_State *L;
const void * result;
if (CC.L == NULL)
return NULL;
SPIN_LOCK(&CC) //上锁多线程安全
L = CC.L; //获得cache虚拟机
lua_pushstring(L, key); //push文件名
lua_rawget(L, LUA_REGISTRYINDEX); //registry[filename]
result = lua_touserdata(L, -1); //结果
lua_pop(L, 1);
SPIN_UNLOCK(&CC)
return result; //返回registry[filename]
}
- 进行缓存
static const void *
save_proto(const char *key, const void * proto) {
lua_State *L;
const void * result = NULL;
SPIN_LOCK(&CC)
if (CC.L == NULL) {
init();
}
L = CC.L;
lua_pushstring(L, key);
lua_pushvalue(L, -1);
lua_rawget(L, LUA_REGISTRYINDEX); //registry[filename]
result = lua_touserdata(L, -1); /* stack: key oldvalue */
if (result == NULL) { //没有就缓存进去
lua_pop(L,1);
lua_pushlightuserdata(L, (void *)proto);
lua_rawset(L, LUA_REGISTRYINDEX); //registry[filename] = (void *)proto
} else {
lua_pop(L,2);
}
SPIN_UNLOCK(&CC)
return result;
}
- clone脚本
LUA_API void lua_clonefunction (lua_State *L, const void * fp) {
LClosure *cl;
LClosure *f = cast(LClosure *, fp); //fp 指向缓存的closure
api_check(L, isshared(f->p), "Not a shared proto");
lua_lock(L);
cl = luaF_newLclosure(L,f->nupvalues); //创建nupvalues的新闭包
setclLvalue2s(L,L->top,cl); //设置栈顶为cl
api_incr_top(L); //栈顶加一
cl->p = f->p; //cl的proto设置为fp的proto
luaF_initupvals(L, cl); //初始化upvalue
set_env(L,cl); //设置_ENV
lua_unlock(L);
}
//由此可见,clone全面复制了fp的proto
- lua 加载文件
LUALIB_API int luaL_loadfilex_ (lua_State *L, const char *filename,
const char *mode) {
LoadF lf; //文件加载结构
int status, readstatus;
int c;
int fnameindex = lua_gettop(L) + 1; /* index of filename on the stack */
if (filename == NULL) {
lua_pushliteral(L, "=stdin");
lf.f = stdin;
}
else {
lua_pushfstring(L, "@%s", filename);
lf.f = fopen(filename, "r"); //打开文件
if (lf.f == NULL) return errfile(L, "open", fnameindex);
}
lf.n = 0;
if (skipcomment(lf.f, &c)) //读文件头
lf.buff[lf.n++] = '\n'; /* add newline to correct line numbers */
if (c == LUA_SIGNATURE[0]) { //二进制文件
lf.n = 0; /* remove possible newline */
if (filename) { /* "real" file? */
lf.f = freopen(filename, "rb", lf.f); /* reopen in binary mode */
if (lf.f == NULL) return errfile(L, "reopen", fnameindex);
skipcomment(lf.f, &c); /* re-read initial portion */
}
}
if (c != EOF)
lf.buff[lf.n++] = c; /* 'c' is the first character of the stream */
status = lua_load(L, getF, &lf, lua_tostring(L, -1), mode); //lua_load加载文件(被压入栈)
readstatus = ferror(lf.f);
if (filename) fclose(lf.f); //关闭文件
if (readstatus) {
lua_settop(L, fnameindex); /* ignore results from 'lua_load' */
return errfile(L, "read", fnameindex);
}
lua_remove(L, fnameindex);
return status;
}
总结
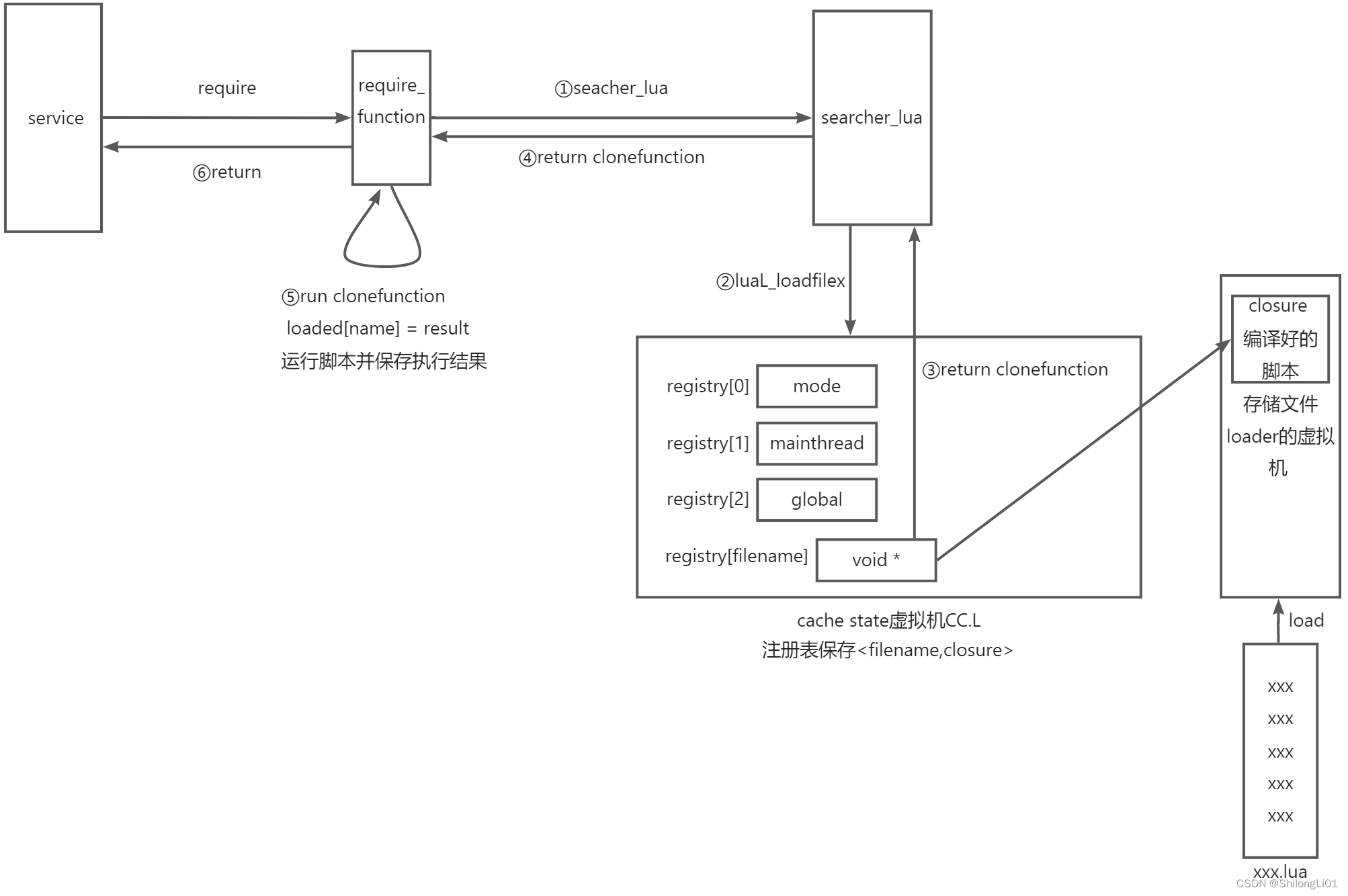
我们require的时候会先查package缓存,然后查load缓存。如果package缓存不存在,那么运行一遍load的缓存,然后把结果缓存在package.loaded中。这样多个服务运行同一个load缓存时,由于load编译时已经把代码载入内存,所以产生的结果的proto都指向同一个函数地址,这样内存浪费的问题就解决了。
下面是原理图: