文章目录
- 日志的概念
- 日志门面
- JUL日志框架
- JUL架构
- 入门案例
- 日志的级别
- Logger之间的父子关系
- 日志的配置文件
- 日志原理解析
- LOG4J日志框架
- Log4j入门
- Log4j组件
- Loggers
- Appenders
- Layouts
- Layout的格式
- Appender的输出
- 自定义Logger
- JCL日志门面
- JCL入门
- JCL原理
- SLF4J日志门面
- SLF4J入门
- 绑定日志的实现(Binding)
- 桥接旧的日志框架(Bridging)
- SLF4J原理解析
- Logback日志框架
- logback入门
- logback组件
- logback配置
- logback-access的使用
- Log4J2日志框架
- Log4j2入门
- Log4j2配置
- Log4j2异步日志
- 无垃圾记录
- SpringBoot中的日志使用
- SpringBoot中的日志设计
- SpringBoot日志使用
日志的概念
日志是记录应用程序运行时所产生的事件信息的工具。使用日志的主要目的是:
- 排错:通过日志可以排查应用程序运行过程中的问题。可以根据日志定位到错误产生的位置,找出错误原因。
- 分析:日志可以用来分析应用程序的运行情况,比如流量、访问量等,以便于对系统进行优化。
- 监控:可以通过日志监控应用程序的运行状态,以及捕捉运行时的安全事件或故障。
- 审计:日志提供了应用程序运行历史的审计线索,可以用于溯源或 forensic 分析。
- 理解:日志可以让开发者理解应用程序代码的执行流程。
-
日志实现:主要的日志实现包括:log4j、logback、log4j2、java.util.logging(JUL)等。每种日志都有自己的配置方式。
-
日志门面:日志门面提供了标准、统一的日志接口,常用的日志门面有SLF4J和JCL。
那么日志门面又是什么呢?
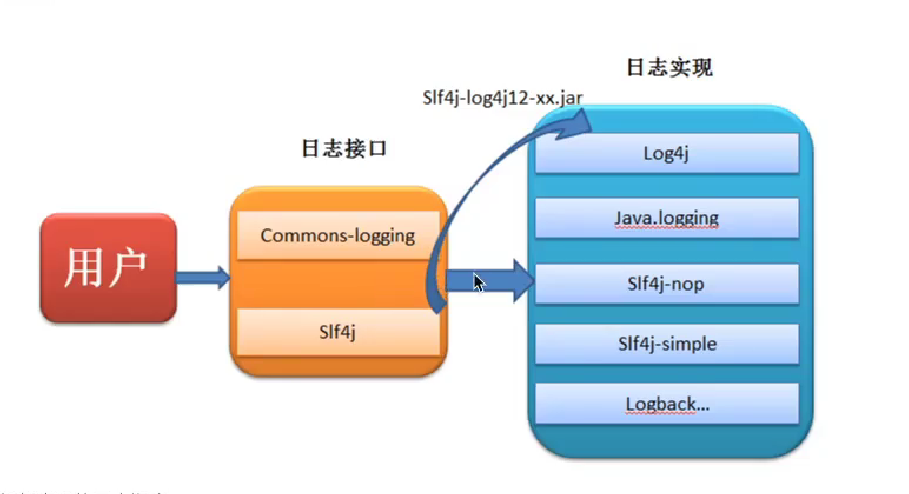
日志门面
当我们的系统变的更加复杂的时候,我们的日志就容易发生混乱。随着系统开发的进行,可能会更新不同的日志框架,造成当前系统中存在不同的日志依赖,让我们难以统一的管理和控制。就算我们强制要求所有的模块使用相同的日志框架,系统中也难以避免使用其他类似spring,mybatis等其他的第三方框架,它们依赖于我们规定不同的日志框架,而且他们自身的日志系统就有着不一致性,依然会出来日志体系的混乱。
所以我们需要借鉴JDBC的思想,为日志系统也提供一套门面,那么我们就可以面向这些接口规范来开发,避免了直接依赖具体的日志框架。这样我们的系统在日志中,就存在了日志的门面和日志的实现。
常见的日志门面 :
JCL、slf4j
日志门面和日志实现的关系:
日志框架出现的历史顺序:
log4j -->JUL–>JCL–> slf4j --> logback --> log4j2
JUL日志框架
JUL全称Java util Logging是java原生的日志框架,使用时不需要另外引用第三方类库,相对其他日志框架使用方便,能够在小型应用中灵活使用。
JUL架构
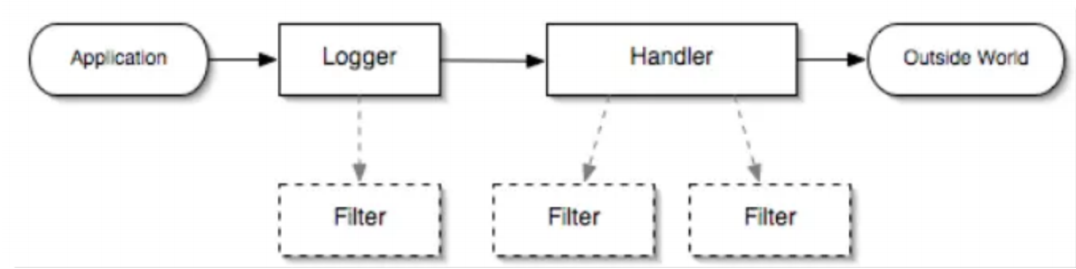
- Loggers:被称为记录器,应用程序通过获取Logger对象,调用其API来发布日志信息。Logger通常是应用程序访问日志系统的入口程序。
- Appenders:也被称为Handlers,每个Logger都会关联一组Handlers,Logger会将日志交给关联Handlers处理,由Handlers负责将日志做记录。Handlers在此是一个抽象,其具体的实现决定了日志记录的位置可以是控制台、文件、网络上的其他日志服务或操作系统日志等。
- Layouts:也被称为Formatters,它负责对日志事件中的数据进行转换和格式化。Layouts决定了数据在一条日志记录中的最终形式。
- Level:每条日志消息都有一个关联的日志级别。该级别粗略指导了日志消息的重要性和紧迫,我可以将Level和Loggers,Appenders做关联以便于我们过滤消息。
- Filters:过滤器,根据需要定制哪些信息会被记录,哪些信息会被放过。
总结一下就是:
用户使用Logger来进行日志记录,Logger持有若干个Handler,日志的输出操作是由Handler完成的。在Handler输出日志前,会经过Filter的过滤,判断哪些日志级别过滤放行哪些拦截,Handler会将日志内容输出到指定位置(日志文件、控制台等)。Handler在输出日志时会使用Layout,将输出内容进行排版。
入门案例
@Test
public void testLogger(){
//获取日志记录器
//一般每一个日志记录器都有一个唯一的标识,我们一般拿当前类的全限定名来充当这个角色
Logger logger = Logger.getLogger("com.zyb.LoggerTest");
logger.info("hello");
logger.log(Level.INFO,"this is info");
//如果只有一个{}可以不用标序号,多个一定要标
logger.log(Level.WARNING, "{0}发生了错误{1}", new Object[]{"Application","!"});
}

日志的级别
java.util.logging.Level中定义了日志的级别:
- SEVERE(最高值)
- WARNING
- INFO (默认级别)
- CONFIG
- FINE
- FINER
- FINEST(最低值)
还有两个特殊的级别:
- OFF,可用来关闭日志记录。
- ALL,启用所有消息的日志记录。
虽然我们测试了7个日志级别但是默认只实现info及以上的级别:
@Test
public void testLogLevel() throws Exception {
// 1.获取日志对象
Logger logger = Logger.getLogger("com.zyb.LoggerTest");
// 2.日志记录输出
logger.severe("severe");
logger.warning("warning");
logger.info("info");
logger.config("cofnig");
logger.fine("fine");
logger.finer("finer");
logger.finest("finest");
}

自定义日志级别配置
@Test
public void testLogConfig() throws Exception {
//创建logger
Logger logger = Logger.getLogger("com.zyb.LoggerTest");
//关闭默认配置
logger.setUseParentHandlers(false);
//设置日志级别
logger.setLevel(Level.ALL);
//设置控制台的Handler
ConsoleHandler consoleHandler = new ConsoleHandler();
//设置Handler的日志级别
consoleHandler.setLevel(Level.ALL);
//绑定Handler
logger.addHandler(consoleHandler);
//再绑定一个文件Handler
FileHandler fileHandler = new FileHandler("F:\\资料-Java日志\\日志.txt");
//进行绑定
logger.addHandler(fileHandler);
//重新测试几个日志级别
logger.severe("severe");
logger.warning("warning");
logger.info("info");
logger.config("config");
logger.fine("fine");
logger.finer("finer");
logger.finest("finest");
}
注意:
- Logger和Handler都可以设置日志级别:Logger控制日志类本身的级别,Handler控制输出到目的地的级别。Logger和Handler的级别互相制约,日志只有同时满足两个级别要求才会输出。Logger级别一般作为默认设置,Handler级别可覆盖Logger的设置。
- ConsoleHandler默认日志级别是INFO
- FileHandler的日志级别是从其父Logger继承的级别
Logger之间的父子关系
JUL 中 Logger 记录器之间是存在 “父子” 关系的,这种父子关系不是我们普遍认为的类之间的继承关系,关系是通过树状结构存储的。
JUL 在初始化时会创建一个顶层 RootLogger 作为所有 Logger 的父 Logger,RootLogger 是 LogManager 的内部类,默认的名称为空串。
以上的 RootLogger 对象作为树状结构的根节点存在的,将来自定义的父子关系通过路径来进行关联,父子关系同时也是节点之间的挂载关系。
RootLogger有默认的Handler和Formatters,默认级别是DEBUG。
子Logger会从其父Logger继承日志级别、Handler、过滤器、格式化器等,根据父子关系,查找的顺序为:当前Logger --> 父Logger --> Root Logger。
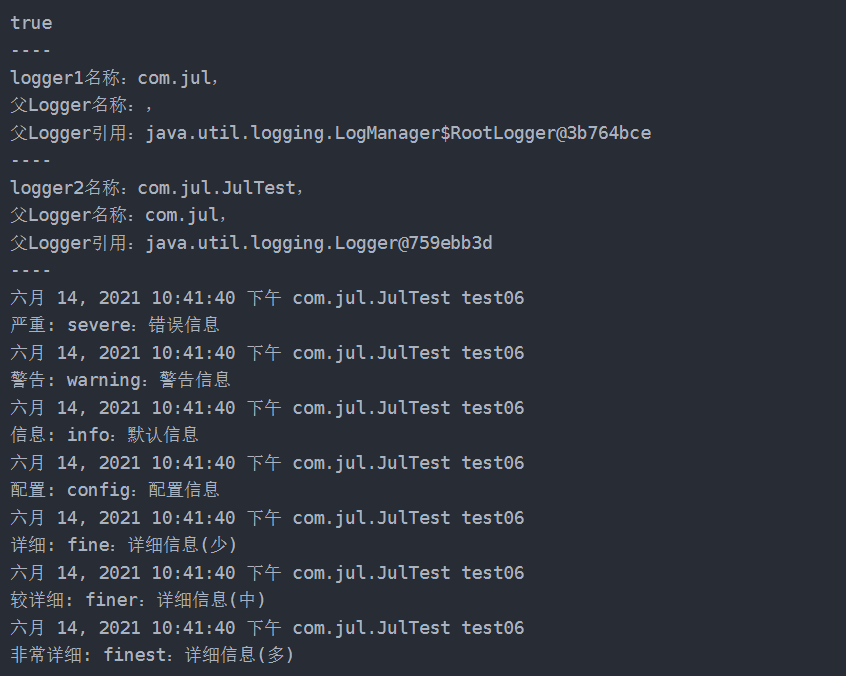
@Test
public void test06() {
// 创建两个 logger 对象,可以认为 logger1 是 logger2 的父亲
// RootLogger 是所有 logger 对象的顶层 logger,名称默认是一个空的字符串
Logger logger1 = Logger.getLogger("com.jul");
Logger logger2 = Logger.getLogger("com.jul.JulTest");
System.out.println(logger2.getParent() == logger1);
System.out.println("----");
System.out.println("logger1名称:" + logger1.getName() +
",\n父Logger名称:" + logger1.getParent().getName() +
",\n父Logger引用:" + logger1.getParent());
System.out.println("----");
System.out.println("logger2名称:" + logger2.getName() +
",\n父Logger名称:" + logger2.getParent().getName() +
",\n父Logger引用:" + logger2.getParent());
System.out.println("----");
// 父亲所做的设置,也能够同时作用于儿子
// 对 logger1 做日志打印相关的设置,然后我们使用 logger2 进行日志的打印
logger1.setUseParentHandlers(false);
ConsoleHandler handler = new ConsoleHandler();
SimpleFormatter formatter = new SimpleFormatter();
handler.setFormatter(formatter);
logger1.addHandler(handler);
handler.setLevel(Level.ALL);
logger1.setLevel(Level.ALL);
//儿子做打印
logger2.severe("severe:错误信息");
logger2.warning("warning:警告信息");
logger2.info("info:默认信息");
logger2.config("config:配置信息");
logger2.fine("fine:详细信息(少)");
logger2.finer("finer:详细信息(中)");
logger2.finest("finest:详细信息(多)");
}
结果:
日志的配置文件
我们上面都是使用硬编码的方式进行配置,这样肯定是不太好的,所以接下来我们尝试使用配置文件。
默认配置文件路径$JAVAHOME\jre\lib\logging.properties
默认配置:
############################################################
# 默认日志记录配置文件
#
# 您可以通过使用java.util.logging.config.file系统属性指定文件名来使用不同的文件
# 例如 java -Djava.util.logging.config.file=myfile
############################################################
############################################################
# 全局性质
############################################################
# RootLogger使用的处理器,在获取RootLogger对象时进行的设置
# 可在当前处理器类后,通过指定的英文逗号分隔,添加多个日志处理器
# 这些处理程序将在VM启动期间安装,请注意:这些类必须位于系统类路径上
# 默认情况下,只配置控制台处理程序,默认打印INFO和高于INFO级别消息
handlers = java.util.logging.ConsoleHandler
# 要添加文件处理程序,请使用以下行(多个日志处理器)
#handlers= java.util.logging.FileHandler, java.util.logging.ConsoleHandler
# RootLogger 默认的全局日志记录级别
# 对于这种全局层面的任何特定配置,可以通过配置特定的水平来覆盖
# 如果不手动配置其它的日志级别,则默认输出下述配置的级别以及更高的级别
.level = INFO
############################################################
# 处理器指定属性,描述处理程序的特定配置信息
############################################################
# 文件处理器属性设置
# 默认输出的日志文件路径,位于用户的主目录中
# %h:当前用户系统的默认根路径,C:\用户\用户名\java0.log
# %u:指向默认输出的日志文件数量count,count=1,则:java0.log;count=2,则:java0.log,java1.log...
java.util.logging.FileHandler.pattern = %h/java%u.log
# 默认输出的日志文件大小(单位字节)
java.util.logging.FileHandler.limit = 50000
# 默认输出的日志文件数量
java.util.logging.FileHandler.count = 1
# 默认输出的日志文件格式(XML)
java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter
# 控制台处理器属性设置
# 默认输出的日志级别
java.util.logging.ConsoleHandler.level = INFO
# 默认输出的日志格式(Simple)
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
# 示例以自定义简单的格式化器输出格式,以打印这样的单行日志消息:
# <level>: <log message> [<date/time>]
#
# java.util.logging.SimpleFormatter.format=%4$s: %5$s [%1$tc]%n
############################################################
# 配置特定属性,为每个记录器提供额外的控制
############################################################
# 例如:将日志级别设定到具体的某个包下
com.xyz.foo.level = SEVERE
我们自定义一个:
############################################################
# 默认日志记录配置文件
############################################################
# 全局性质
############################################################
# 默认配置控制台处理程序,默认打印INFO和高于INFO级别信息
handlers=java.util.logging.ConsoleHandler
# 如果不手动配置其它的日志级别,则默认输出下述配置的级别以及更高的级别
.level = ALL
############################################################
# 处理器指定属性,描述处理程序的特定配置信息
############################################################
# 文件处理器属性设置
# 默认输出的日志文件路径,位于用户的主目录中
java.util.logging.FileHandler.pattern = %h/java%u.log
# 默认输出的日志文件大小(单位字节)
java.util.logging.FileHandler.limit = 50000
# 默认输出的日志文件数量
java.util.logging.FileHandler.count = 1
# 默认输出的日志文件格式(XML)
java.util.logging.FileHandler.formatter = java.util.logging.XMLFormatter
# 控制台处理器属性设置
# 默认输出的日志级别
java.util.logging.ConsoleHandler.level = ALL
# 默认输出的日志格式(Simple)
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
############################################################
# 配置特定属性,为每个记录器提供额外的控制
############################################################
# 例如:将日志级别设定到具体的某个包下
com.xyz.foo.level = SEVERE
代码如下:
@Test
public void testLogLevel() throws Exception {
//创建Manager
LogManager logManager = LogManager.getLogManager();
//设置配置文件
logManager.readConfiguration(LoggerTest.class.getClassLoader().getResourceAsStream("logging.properties"));
// 1.获取日志对象
Logger logger = Logger.getLogger("com.zyb.LoggerTest");
// 2.日志记录输出
logger.severe("severe");
logger.warning("warning");
logger.info("info");
logger.config("cofnig");
logger.fine("fine");
logger.finer("finer");
logger.finest("finest");
}
结果:
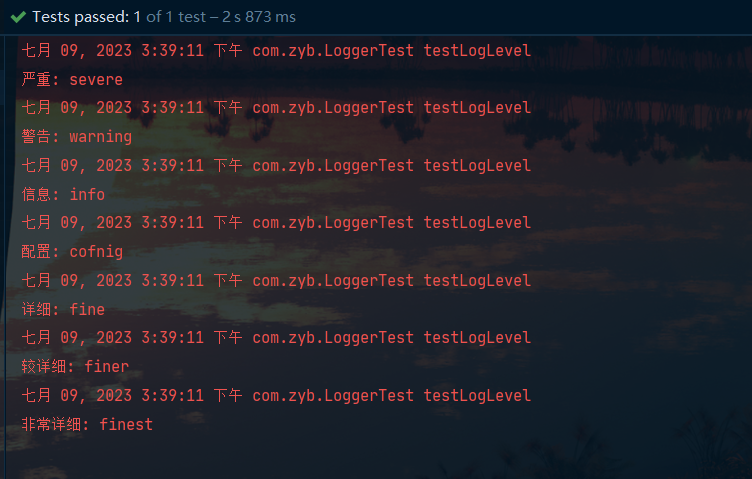
日志原理解析
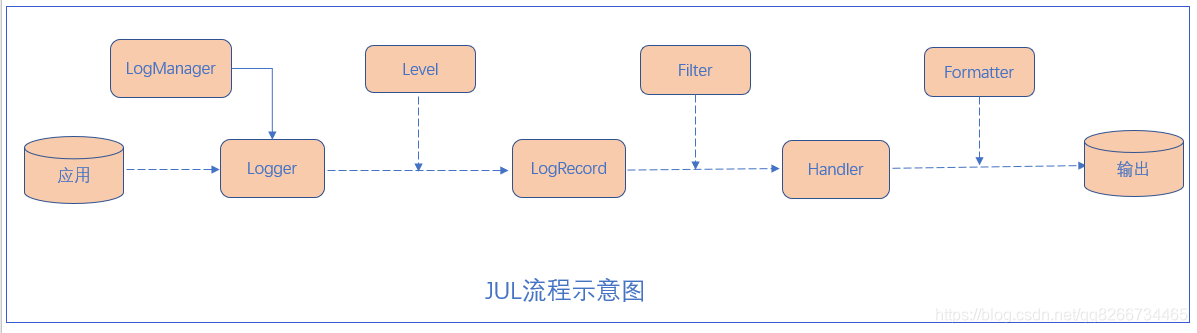
- 初始化LogManager
- LogManager加载logging.properties配置
- 添加Logger到LogManager
- 从单例LogManager获取Logger
- 设置级别Level,并指定日志记录LogRecord
- Filter提供了日志级别之外更细粒度的控制
- Handler是用来处理日志输出位置
- Formatter是用来格式化LogRecord的
LOG4J日志框架
Log4j是Apache下的一款开源的日志框架,通过在项目中使用 Log4J,我们可以控制日志信息输出到控制台、文件、甚至是数据库中。我们可以控制每一条日志的输出格式,通过定义日志的输出级别,可以更灵活的控制日志的输出过程。方便项目的调试。
官方网站: http://logging.apache.org/log4j/1.2/
Log4j入门
依赖:
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
public class Log4jTest {
@Test
public void testQuick() throws Exception {
// 初始化系统配置,不需要配置文件
BasicConfigurator.configure();
// 创建日志记录器对象
Logger logger = Logger.getLogger(Log4jTest.class);
// 日志记录输出
logger.info("hello log4j");
// 日志级别
logger.fatal("fatal"); // 严重错误,一般会造成系统崩溃和终止运行
logger.error("error"); // 错误信息,但不会影响系统运行
logger.warn("warn"); // 警告信息,可能会发生问题
logger.info("info"); // 程序运行信息,数据库的连接、网络、IO操作等
logger.debug("debug"); // 调试信息,一般在开发阶段使用,记录程序的变量、参数等
logger.trace("trace"); // 追踪信息,记录程序的所有流程信息
}
}
日志级别
每个Logger都被了一个日志级别(log level),用来控制日志信息的输出。日志级别从高到低分为:
- fatal 指出每个严重的错误事件将会导致应用程序的退出。
- error 指出虽然发生错误事件,但仍然不影响系统的继续运行。
- warn 表明会出现潜在的错误情形。
- info 一般和在粗粒度级别上,强调应用程序的运行全程。
- debug 一般用于细粒度级别上,对调试应用程序非常有帮助。
- trace 是程序追踪,可以用于输出程序运行中的变量,显示执行的流程。
还有两个特殊的级别:
- OFF,可用来关闭日志记录。
- ALL,启用所有消息的日志记录。
注:一般只使用4个级别,优先级从高到低为 ERROR > WARN > INFO > DEBUG
Log4j组件
Log4J 主要由 Loggers (日志记录器)、Appenders(输出端)和 Layout(日志格式化器)组成。其中Loggers 控制日志的输出级别与日志是否输出;Appenders 指定日志的输出方式(输出到控制台、文件等);Layout 控制日志信息的输出格式。
Loggers
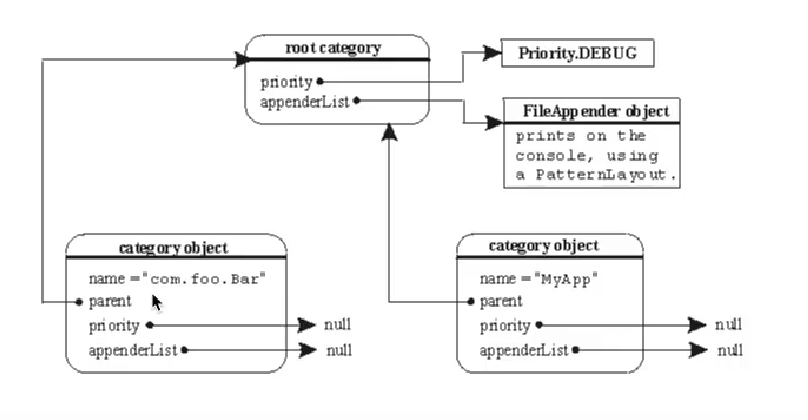
日志记录器,负责收集处理日志记录,实例的命名就是类“XX”的full quailied name(类的全限定名),Logger的名字大小写敏感,其命名有继承机制:例如:name为org.apache.commons的logger会继承name为org.apache的logger。
Log4J中有一个特殊的logger叫做“root”,他是所有logger的根,也就意味着其他所有的logger都会直接或者间接地继承自root。root logger可以用Logger.getRootLogger()方法获取。
但是,自log4j 1.2版以来, Logger 类已经取代了 Category 类。对于熟悉早期版本的log4j的人来说,Logger 类可以被视为 Category 类的别名
Appenders
Appender 用来指定日志输出到哪个地方,可以同时指定日志的输出目的地。Log4j 常用的输出目的地有以下几种:

Layouts
布局器 Layouts用于控制日志输出内容的格式,让我们可以使用各种需要的格式输出日志。Log4j常用的Layouts:
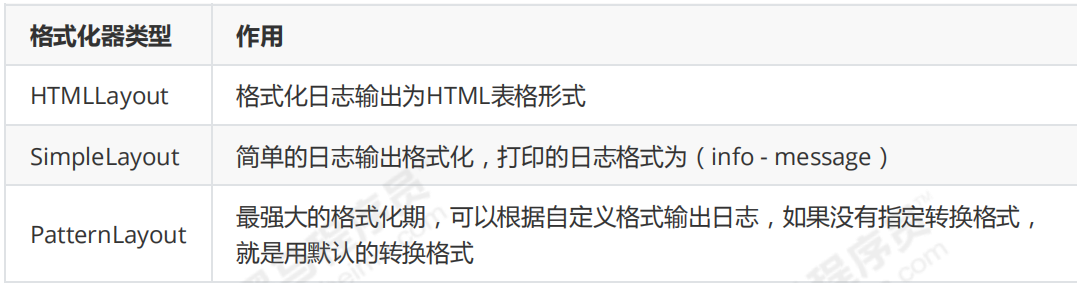
Layout的格式
在 log4j.properties 配置文件中,我们定义了日志输出级别与输出端,在输出端中分别配置日志的输出格式。
log4j 采用类似 C 语言的 printf 函数的打印格式格式化日志信息,具体的占位符及其含义如下:
- %m 输出代码中指定的日志信息
- %p 输出优先级,及 DEBUG、INFO 等
- %n 换行符(Windows平台的换行符为 “\n”,Unix 平台为 “\n”)
- %r 输出自应用启动到输出该 log 信息耗费的毫秒数
- %c 输出打印语句所属的类的全名
- %t 输出产生该日志的线程全名
- %d 输出服务器当前时间,默认为 ISO8601,也可以指定格式,如:%d{yyyy年MM月dd日HH:mm:ss}
- %l 输出日志时间发生的位置,包括类名、线程、及在代码中的行数。如:Test.main(Test.java:10)
- %F 输出日志消息产生时所在的文件名称
- %L 输出代码中的行号
- %% 输出一个 “%” 字符
可以在 % 与字符之间加上修饰符来控制最小宽度、最大宽度和文本的对其方式。如:
- %5c 输出category名称,最小宽度是5,category<5,默认的情况下右对齐
- %-5c 输出category名称,最小宽度是5,category<5,"-"号指定左对齐,会有空格
- %.5c 输出category名称,最大宽度是5,category>5,就会将左边多出的字符截掉,<5不会有空格
- %20.30c category名称<20补空格,并且右对齐,>30字符,就从左边交远销出的字符截掉
Appender的输出
控制台,文件,数据库
#指定日志的输出级别与输出端
log4j.rootLogger=INFO,Console
# 控制台输出配置
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
# 文件输出配置
log4j.appender.A = org.apache.log4j.DailyRollingFileAppender
#指定日志的输出路径
log4j.appender.A.File = D:/log.txt
log4j.appender.A.Append = true
#使用自定义日志格式化器
log4j.appender.A.layout = org.apache.log4j.PatternLayout
#指定日志的输出格式
log4j.appender.A.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [%t:%r] -
[%p] %m%n
#指定日志的文件编码
log4j.appender.A.encoding=UTF-8
#mysql
log4j.appender.logDB=org.apache.log4j.jdbc.JDBCAppender
log4j.appender.logDB.layout=org.apache.log4j.PatternLayout
log4j.appender.logDB.Driver=com.mysql.jdbc.Driver
log4j.appender.logDB.URL=jdbc:mysql://localhost:3306/test
log4j.appender.logDB.User=root
log4j.appender.logDB.Password=root
log4j.appender.logDB.Sql=INSERT INTO
log(project_name,create_date,level,category,file_name,thread_name,line,all_categ
ory,message) values('itcast','%d{yyyy-MM-dd
HH:mm:ss}','%p','%c','%F','%t','%L','%l','%m')
CREATE TABLE `log` (
`log_id` int(11) NOT NULL AUTO_INCREMENT,
`project_name` varchar(255) DEFAULT NULL COMMENT '目项名',
`create_date` varchar(255) DEFAULT NULL COMMENT '创建时间',
`level` varchar(255) DEFAULT NULL COMMENT '优先级',
`category` varchar(255) DEFAULT NULL COMMENT '所在类的全名',
`file_name` varchar(255) DEFAULT NULL COMMENT '输出日志消息产生时所在的文件名称 ',
`thread_name` varchar(255) DEFAULT NULL COMMENT '日志事件的线程名',
`line` varchar(255) DEFAULT NULL COMMENT '号行',
`all_category` varchar(255) DEFAULT NULL COMMENT '日志事件的发生位置',
`message` varchar(4000) DEFAULT NULL COMMENT '输出代码中指定的消息',
PRIMARY KEY (`log_id`)
);
自定义Logger
# RootLogger配置
log4j.rootLogger = trace,console
# 自定义Logger
log4j.logger.com.itheima = info,file
log4j.logger.org.apache = error
@Test
public void testCustomLogger() throws Exception {
// 自定义 com.itheima
Logger logger1 = Logger.getLogger(Log4jTest.class);
logger1.fatal("fatal"); // 严重错误,一般会造成系统崩溃和终止运行
logger1.error("error"); // 错误信息,但不会影响系统运行
logger1.warn("warn"); // 警告信息,可能会发生问题
logger1.info("info"); // 程序运行信息,数据库的连接、网络、IO操作等
logger1.debug("debug"); // 调试信息,一般在开发阶段使用,记录程序的变量、参数等
logger1.trace("trace"); // 追踪信息,记录程序的所有流程信息
// 自定义 org.apache
Logger logger2 = Logger.getLogger(Logger.class);
logger2.fatal("fatal logger2"); // 严重错误,一般会造成系统崩溃和终止运行
logger2.error("error logger2"); // 错误信息,但不会影响系统运行
logger2.warn("warn logger2"); // 警告信息,可能会发生问题
logger2.info("info logger2"); // 程序运行信息,数据库的连接、网络、IO操作等
logger2.debug("debug logger2"); // 调试信息,一般在开发阶段使用,记录程序的变量、参数等
logger2.trace("trace logger2"); // 追踪信息,记录程序的所有流程信息
}
JCL日志门面
了解即可,已被淘汰
全称为Jakarta Commons Logging,是Apache提供的一个通用日志API。
它是为 "所有的Java日志实现"提供一个统一的接口,它自身也提供一个日志的实现,但是功能非常常弱(SimpleLog)。所以一般不会单独使用它。他允许开发人员使用不同的具体日志实现工具: Log4j, Jdk
自带的日志(JUL)
JCL 有两个基本的抽象类:Log(基本记录器)和LogFactory(负责创建Log实例)。
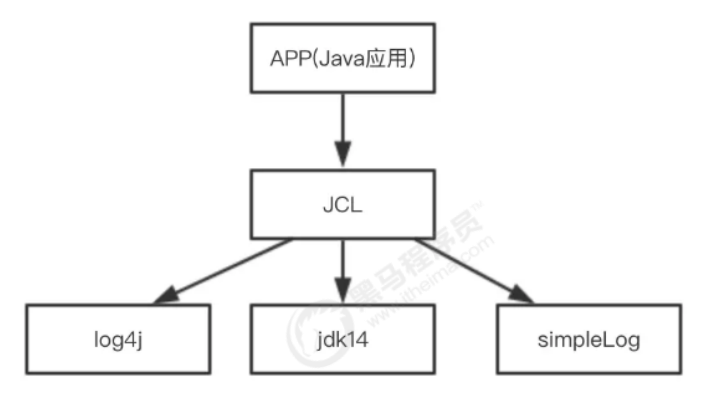
JCL入门
依赖:
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
入门代码:
public class JULTest {
@Test
public void testQuick() throws Exception {
// 创建日志对象
Log log = LogFactory.getLog(JULTest.class);
// 日志记录输出
log.fatal("fatal");
log.error("error");
log.warn("warn");
log.info("info");
log.debug("debug");
}
}
我们为什么要使用日志门面:
- 面向接口开发,不再依赖具体的实现类。减少代码的耦合
- 项目通过导入不同的日志实现类,可以灵活的切换日志框架
- 统一API,方便开发者学习和使用
- 统一配置便于项目日志的管理
JCL原理
①通过LogFactory动态加载Log实现类

②日志门面支持的日志实现数组
private static final String[] classesToDiscover =
new String[]{"org.apache.commons.logging.impl.Log4JLogger",
"org.apache.commons.logging.impl.Jdk14Logger",
"org.apache.commons.logging.impl.Jdk13LumberjackLogger",
"org.apache.commons.logging.impl.SimpleLog"};
③获取具体的日志实现
for(int i = 0; i < classesToDiscover.length && result == null; ++i) {
result = this.createLogFromClass(classesToDiscover[i], logCategory,true);
}
我们可以发现JCL的可拓展性相当的差,假如你要添加一个实现,先要添加数组元素,还要添加相应的依赖。所以这个日志门面已经在2014年被阿帕奇淘汰了。
SLF4J日志门面
简单日志门面(Simple Logging Facade For Java) SLF4J主要是为了给Java日志访问提供一套标准、规范的API框架,其主要意义在于提供接口,具体的实现可以交由其他日志框架,例如log4j和logback等。
当然slf4j自己也提供了功能较为简单的实现,但是一般很少用到。对于一般的Java项目而言,日志框架会选择slf4j-api作为门面,配上具体的实现框架(log4j、logback等),中间使用桥接器完成桥接。
官方网站: https://www.slf4j.org/
SLF4J是目前市面上最流行的日志门面。现在的项目中,基本上都是使用SLF4J作为我们的日志系统。
SLF4J日志门面主要提供两大功能:
- 日志框架的绑定
- 日志框架的桥接
为什么要使用SLF4J作为日志门面?
- 使用SLF4J框架,可以在部署时迁移到所需的日志记录框架。
- SLF4J提供了对所有流行的日志框架的绑定,例如log4j,JUL,Simple logging和NOP。因此可以在部署时切换到任何这些流行的框架。
- 无论使用哪种绑定,SLF4J都支持参数化日志记录消息。由于SLF4J将应用程序和日志记录框架分离,因此可以轻松编写独立于日志记录框架的应用程序。而无需担心用于编写应用程序的日志记录框架。
- SLF4J提供了一个简单的Java工具,称为迁移器。使用此工具,可以迁移现有项目,这些项目使用日志框架(如Jakarta Commons Logging(JCL)或log4j或Java.util.logging(JUL))到SLF4J。
SLF4J入门
首先添加依赖
<!--slf4j core 使用slf4j必須添加-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.27</version>
</dependency>
<!--slf4j 自带的简单日志实现(可选) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.27</version>
</dependency>
入门代码:
public class Slf4jTest {
// 声明日志对象
public final static Logger LOGGER = LoggerFactory.getLogger(Slf4jTest.class);
@Test
public void testQuick() throws Exception {
//打印日志信息
LOGGER.error("error");
LOGGER.warn("warn");
LOGGER.info("info");
LOGGER.debug("debug");
LOGGER.trace("trace");
// 使用占位符输出日志信息
String name = "jack";
Integer age = 18;
LOGGER.info("用户:{},{}", name, age);
// 将系统异常信息写入日志
try {
int i = 1 / 0;
} catch (Exception e) {
// e.printStackTrace();
LOGGER.info("出现异常:", e);
}
}
}
绑定日志的实现(Binding)
如前所述,SLF4J支持各种日志框架。SLF4J发行版附带了几个称为“SLF4J绑定”的jar文件,每个绑定对应一个受支持的框架。
使用slf4j的日志绑定流程:
- 添加slf4j-api的依赖
- 使用slf4j的API在项目中进行统一的日志记录
- 绑定具体的日志实现框架
- 绑定已经实现了slf4j的日志框架,直接添加对应依赖
- 绑定没有实现slf4j的日志框架,先添加日志的适配器,再添加实现类的依赖
- slf4j有且仅有一个日志实现框架的绑定(如果出现多个默认使用第一个依赖日志实现)
通过maven引入常见的日志实现框架:
<!--slf4j core 使用slf4j必須添加-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.27</version>
</dependency>
<!-- log4j-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.27</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- jul -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<version>1.7.27</version>
</dependency>
<!--jcl -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jcl</artifactId>
<version>1.7.27</version>
</dependency>
<!-- nop 日志开关-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.27</version>
</dependency>
要切换日志框架,只需替换类路径上的slf4j绑定。例如,要从java.util.logging切换到log4j,只需将slf4j-jdk14-1.7.27.jar替换为slf4j-log4j12-1.7.27.jar即可。
SLF4J不依赖于任何特殊的类装载。实际上,每个SLF4J绑定在编译时都是硬连线的, 以使用一个且只有一个特定的日志记录框架。例如,slf4j-log4j12-1.7.27.jar绑定在编译时绑定以使用log4j。在您的代码中,除了slf4j-api-1.7.27.jar之外,您只需将您选择的一个且只有一个绑定放到相应的类路径位置。不要在类路径上放置多个绑定。以下是一般概念的图解说明。
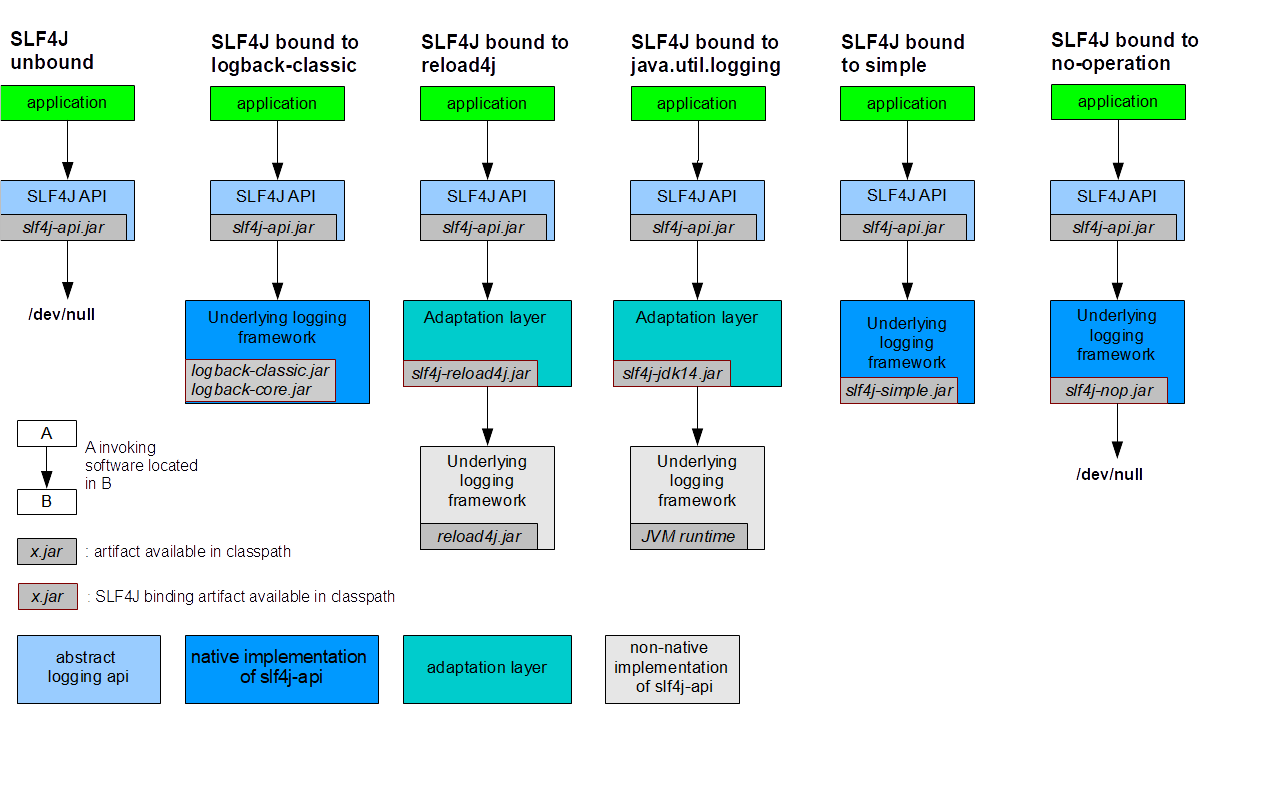
这里我们可以看到reload4j和JUL开发的比较早没有遵循slf4j的规范,没有办法直接绑定,所以中间加了一个适配层来间接的遵循slf4j的API规范。
桥接旧的日志框架(Bridging)
使用场景:比如我们项目一开始使用的是log4j,随着项目的迭代,我们现在想升级为slf4j+logback,但是我们不想修改原本log4j的代码。这个时候桥接器就可以帮我们实现底层的转化,
通常,您依赖的某些组件依赖于SLF4J以外的日志记录API。您也可以假设这些组件在不久的将来不会切换到SLF4J。为了解决这种情况,SLF4J附带了几个桥接模块,这些模块将对log4j,JCL和java.util.logging API的调用重定向,就好像它们是对SLF4J API一样。
桥接解决的是项目中日志的遗留问题,当系统中存在之前的日志API,可以通过桥接转换到slf4j的实现
- 先去除之前老的日志框架的依赖
- 添加SLF4J提供的桥接组件
- 为项目添加SLF4J的具体实现
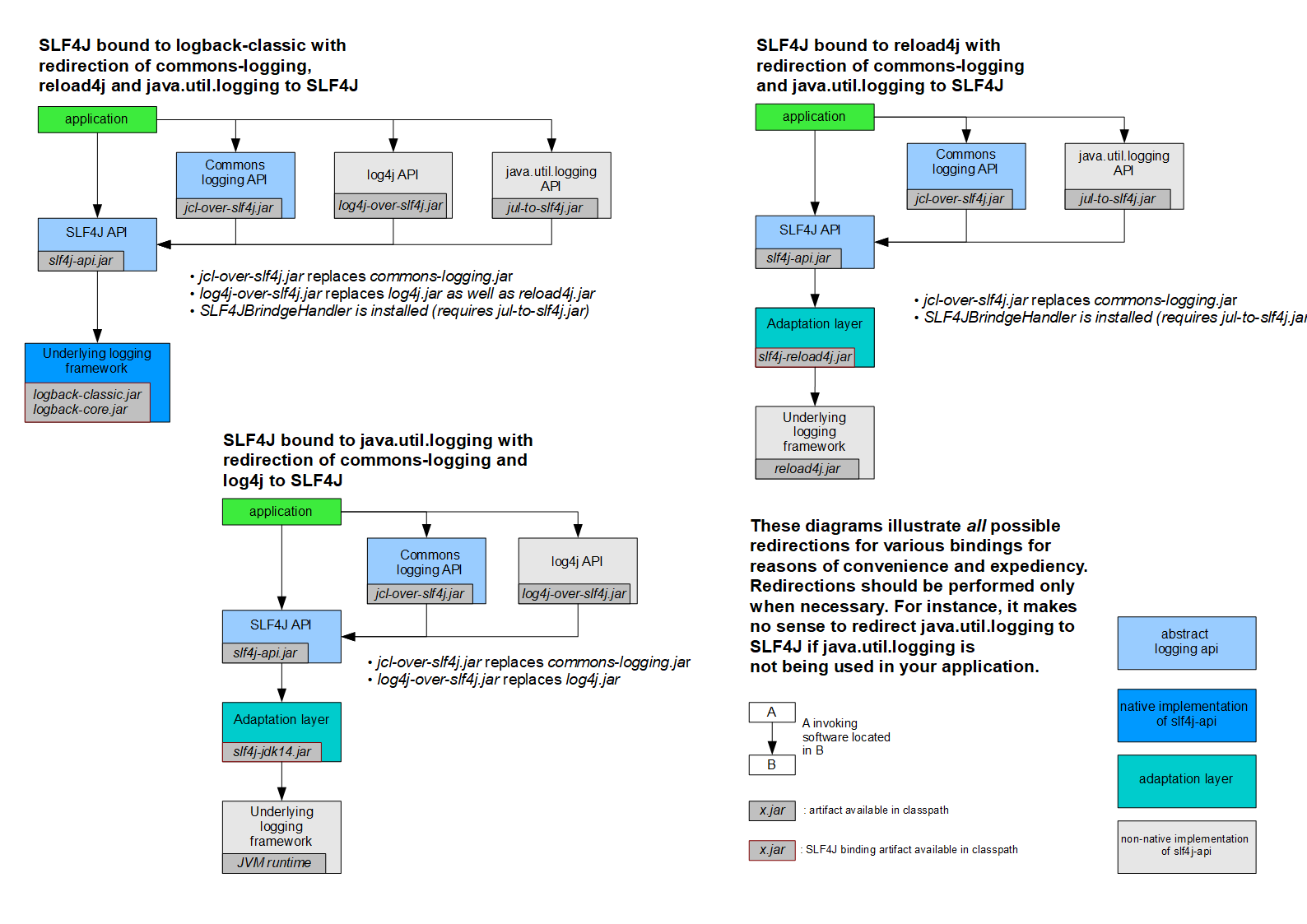
迁移的方式:
如果我们要使用SLF4J的桥接器,替换原有的日志框架,那么我们需要做的第一件事情,就是删除掉原有项目中的日志框架的依赖。然后替换成SLF4J提供的桥接器。
<!-- log4j-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>1.7.27</version>
</dependency>
<!-- jul -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>1.7.27</version>
</dependency>
<!--jcl -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.7.27</version>
</dependency>
注意:
- jcl-over-slf4j.jar和 slf4j-jcl.jar不能同时部署。前一个jar文件将导致JCL将日志系统的选择委托给SLF4J,后一个jar文件将导致SLF4J将日志系统的选择委托给JCL,从而导致无限循环。
- log4j-over-slf4j.jar和slf4j-log4j12.jar不能同时出现(桥接器和适配器不能同时出现)
- jul-to-slf4j.jar和slf4j-jdk14.jar不能同时出现
- 所有的桥接都只对Logger日志记录器对象有效,如果程序中调用了内部的配置类或者是Appender,Filter等对象,将无法产生效果。
SLF4J原理解析
- SLF4J通过LoggerFactory加载日志具体的实现对象。
- LoggerFactory在初始化的过程中,会通过performInitialization()方法绑定具体的日志实现。
- 在绑定具体实现的时候,通过类加载器,加载org/slf4j/impl/StaticLoggerBinder.class
- 所以,只要是一个日志实现框架,在org.slf4j.impl包中提供一个自己的StaticLoggerBinder类,在其中提供具体日志实现的LoggerFactory就可以被SLF4J所加载
Logback日志框架
Logback是由log4j创始人设计的另一个开源日志组件,性能比log4j要好。
官方网站:https://logback.qos.ch/index.html
Logback主要分为三个模块:
- logback-core:其它两个模块的基础模块
- logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API
- logback-access:访问模块与Servlet容器集成,提供通过Http来访问日志的功能
后续的日志代码都是通过SLF4J日志门面搭建日志系统,所以在代码是没有区别,主要是通过修改配置文件和pom.xml依赖
logback入门
依赖:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
入门代码:
//定义日志对象
public final static Logger LOGGER =LoggerFactory.getLogger(LogBackTest.class);
@Test
public void testSlf4j(){
//打印日志信息
LOGGER.error("error");
LOGGER.warn("warn");
LOGGER.info("info");
LOGGER.debug("debug"); // 默认级别
LOGGER.trace("trace");
}
logback组件
- Logger:日志的记录器,把它关联到应用的对应的context上后,主要用于存放日志对象,也可以定义日志类型、级别。 Logger 可以被分配级别。级别包括:TRACE、DEBUG、INFO、WARN 和 ERROR,定义于ch.qos.logback.classic.Level类。如果 logger没有被分配级别,那么它将从有被分配级别的最近的祖先那里继承级别。root logger 默认级别是 DEBUG。级别排序为: TRACE < DEBUG < INFO < WARN < ERROR
- Appender:用于指定日志输出的目的地,目的地可以是控制台、文件、数据库等等。
- Layout:负责把事件转换成字符串,格式化日志信息的输出。在logback中Layout对象被封装在encoder中。
各个logger 都被关联到一个 LoggerContext,LoggerContext负责制造logger,也负责以树结构排列各logger。其他所有logger也通过org.slf4j.LoggerFactory 类的静态方法getLogger取得。 getLogger方法以 logger名称为参数。用同一名字调用LoggerFactory.getLogger 方法所得到的永远都是同一个logger对象的引用。
logback配置
logback会依次读取以下类型配置文件:
- logback.groovy
- logback-test.xml
- logback.xml
- 如果都不存在,logback用BasicConfigurator自动对自己进行配置,这会导致记录输出到控制台。
接下来我们来说一下配置文件怎么编写:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
日志输出格式:
%-5level
%d{yyyy-MM-dd HH:mm:ss.SSS}日期
%c类的完整名称
%M为method
%L为行号
%thread线程名称
%m或者%msg为信息
%n换行
-->
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<property name="pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} %c [%thread] %-5level %msg%n"/>
<!--
Appender: 设置日志信息的去向,常用的有以下几个
ch.qos.logback.core.ConsoleAppender (控制台)
ch.qos.logback.core.rolling.RollingFileAppender (文件大小到达指定尺寸的时候产生一个新文件)
ch.qos.logback.core.FileAppender (文件)
-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err(也就是输出时候字体变红)-->
<target>System.err</target>
<!--日志格式配置-->
<encoder
class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${pattern}</pattern>
</encoder>
</appender>
<!--
<root>也是<logger>元素,但是它是根logger。默认debug
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF,
<root>可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个logger。
-->
<root level="ALL">
<appender-ref ref="console"/>
</root>
</configuration>
Appender标签中每一个子标签,对应的都是它的setter方法,根据这个规律可以更好的编写配置文件。
FileAppender配置
与上面重复的配置不显示
<!-- 日志文件存放目录 -->
<property name="log_dir" value="d:/logs"></property>
<!--日志文件输出appender对象-->
<appender name="file" class="ch.qos.logback.core.FileAppender">
<!--日志格式配置-->
<encoder
class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${pattern}</pattern>
</encoder>
<!--日志输出路径-->
<file>${log_dir}/logback.log</file>
</appender>
<!-- 生成html格式appender对象 -->
<appender name="htmlFile" class="ch.qos.logback.core.FileAppender">
<!--日志格式配置-->
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="ch.qos.logback.classic.html.HTMLLayout">
<pattern>%level%d{yyyy-MM-dd HH:mm:ss}%c%M%L%thread%m</pattern>
</layout>
</encoder>
<!--日志输出路径-->
<file>${log_dir}/logback.html</file>
</appender>
<!--RootLogger对象-->
<root level="all">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
<appender-ref ref="htmlFile"/>
</root>
RollingFileAppender配置
其使用场景就是:如果日志一直输出到同一个文件,随着系统的运行,日志文件越来越大,会造成难以管理和维护的情况。这个时候我们期望日志可以通过一定的规则进行拆分,如果拆分的内容还是比较大的时候,我们可以进行归档和压缩。而这些功能就可以靠RollingFileAppender来实现。
<!-- 日志文件拆分和归档的appender对象-->
<appender name="rollFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志格式配置-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${pattern}</pattern>
</encoder>
<!--日志输出路径-->
<file>${log_dir}/roll_logback.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>${log_dir}/rolling.%d{yyyy-MM-dd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--RootLogger对象-->
<root level="all">
<appender-ref ref="console"/>
<appender-ref ref="rollFile"/>
</root>
Filter配置
我们可以使用Filter对appender的细腻度进行筛选,以上面的RollingFileAppender为例:
<appender name="rollFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--日志格式配置-->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>${pattern}</pattern>
</encoder>
<!--日志输出路径-->
<file>${log_dir}/roll_logback.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>${log_dir}/rolling.%d{yyyy-MM-dd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
<!--日志级别过滤器 filter配置-->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<!--设置拦截日志级别-->
<level>error</level>
<!--超过这个级别就放行-->
<onMatch>ACCEPT</onMatch>
<!--小于这个级别就拦截-->
<onMismatch>DENY</onMismatch>
</filter>
</appender>
异步日志配置
在同步日志的情况下,只有在日志记录完毕之后代码才会往下执行,为了解决性能问题我们可以使用异步日志。
<!--异步日志-->
<appender name="async" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="rollFile"/>
</appender>
<!--RootLogger对象-->
<root level="all">
<appender-ref ref="console"/>
<appender-ref ref="async"/>
</root>
自定义Logger配置
<logger>:用来设置某一个包或具体的某一个类的日志打印级别、以及指定<appender>。<loger>仅有一个name属性,一个可选的level和一个可选的addtivity属性。
可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个loger
- name: 用来指定受此loger约束的某一个包或者具体的某一个类。
- level: 用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL和OFF,还有一个特殊值INHERITED或者同义词NULL,代表强制执行上级的级别。 如果未设置此属性,那么当前loger将会继承上级的级别。
- addtivity: 是否继承rootLogger。默认是true。
同<root>一样,可以包含零个或多个<appender-ref>元素,标识这个appender将会添加到这个loger。
<logger name="com.mmall" additivity="false" level="INFO" >
<appender-ref ref="mmall" />
<appender-ref ref="console"/>
</logger>
官方提供的log4j.properties转换成logback.xml
https://logback.qos.ch/translator/
logback-access的使用
logback-access模块与Servlet容器(如Tomcat和Jetty)集成,以提供HTTP访问的日志功能。我们可以使用logback-access模块来替换tomcat的访问日志。
步骤:
①将logback-access.jar与logback-core.jar复制到$TOMCAT_HOME/lib/目录下
②修改$TOMCAT_HOME/conf/server.xml中的Host元素中添加:
<Valve className="ch.qos.logback.access.tomcat.LogbackValve" />
③ logback默认会在$TOMCAT_HOME/conf下查找文件 logback-
access.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- always a good activate OnConsoleStatusListener -->
<statusListener class="ch.qos.logback.core.status.OnConsoleStatusListener"/>
<property name="LOG_DIR" value="${catalina.base}/logs"/>
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_DIR}/access.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>access.%d{yyyy-MM-dd}.log.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<!-- 访问日志的格式 -->
<pattern>combined</pattern>
</encoder>
</appender>
<appender-ref ref="FILE"/>
</configuration>
官方配置: https://logback.qos.ch/access.html#configuration
Log4J2日志框架
Apache Log4j 2是对Log4j的升级版,参考了logback的一些优秀的设计,并且修复了一些问题,因此带来了一些重大的提升,主要有:
- 异常处理,在logback中,Appender中的异常不会被应用感知到,但是在log4j2中,提供了一些异常处理机制。
- 性能提升, log4j2相较于log4j 和logback都具有很明显的性能提升,后面会有官方测试的数据。
- 自动重载配置,参考了logback的设计,当然会提供自动刷新参数配置,最实用的就是我们在生产上可以动态的修改日志的级别而不需要重启应用。
- 无垃圾机制,log4j2在大部分情况下,都可以使用其设计的一套无垃圾机制,避免频繁的日志收集导致的jvm gc。
官网: https://logging.apache.org/log4j/2.x/
Log4j2入门
目前市面上最主流的日志门面就是SLF4J,虽然Log4j2也是日志门面,因为它的日志实现功能非常强大,性能优越。所以大家一般还是将Log4j2看作是日志的实现,Slf4j + Log4j2应该是未来的大势所趋。
如果使用Log4j2作为门面和实现类依赖:
<!-- Log4j2 门面API-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.11.1</version>
</dependency>
<!-- Log4j2 日志实现 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
入门代码:
public class Log4j2Test {
// 定义日志记录器对象
public static final Logger LOGGER = LogManager.getLogger(Log4j2Test.class);
@Test
public void testQuick() throws Exception {
LOGGER.fatal("fatal");
LOGGER.error("error");
LOGGER.warn("warn");
LOGGER.info("info");
LOGGER.debug("debug");
LOGGER.trace("trace");
}
}
如果使用slf4j作为日志的门面,使用log4j2作为日志的实现:
这种情况加一个适配器即可
<!-- Log4j2 门面API-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.11.1</version>
</dependency>
<!-- Log4j2 日志实现 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.1</version>
</dependency>
<!--使用slf4j作为日志的门面,使用log4j2来记录日志 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<!--为slf4j绑定日志实现 log4j2的适配器 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.10.0</version>
</dependency>
如果是SpringBoot只需要一个依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
Log4j2配置
log4j2默认加载classpath下的 log4j2.xml 文件中的配置。
和logback的差不多
<?xml version="1.0" encoding="UTF-8"?>
<!-- status:日志框架本身的日志输出级别
monitorInterval="5":热更新,自动加载配置文件的间隔时间,不低于5秒 -->
<Configuration status="warn" monitorInterval="5">
<!-- 集中配置属性进行管理,使用时通过${name} -->
<properties>
<property name="LOG_HOME">D:/logs</property>
</properties>
<!-- 日志处理器 -->
<Appenders>
<!-- 控制台输出Appender,target:输出类型 -->
<Console name="Console" target="SYSTEM_OUT">
<!-- 消息格式表达式 -->
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] [%-5level] %c{36}:%L --- %m%n" />
</Console>
<!-- 日志文件输出的Appender,fileName:文件存放路径 -->
<File name="file" fileName="${LOG_HOME}/myfile.log">
<!-- 消息格式表达式 -->
<PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] %l%c{36} - %m%n" />
</File>
<!-- 使用随机读取流的日志文件输出Appender,性能更高 -->
<RandomAccessFile name="accessFile" fileName="${LOG_HOME}/myAcclog.log">
<PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] %l%c{36} - %m%n" />
</RandomAccessFile>
<!-- 按照一定的规则拆分日志文件的Appender -->
<!-- fileName:拆分前的文件命名,filePattern拆分后的文件命名 -->
<RollingFile name="rollingFile" fileName="${LOG_HOME}/myrollog.log" filePattern="D:/logs/$${date:yyyy-MM-dd}/myrollog-%d{yyyyMM-dd-HH-mm}-%i.log">
<!-- 日志级别过滤器 -->
<ThresholdFilter level="debug" onMatch="ACCEPT" onMismatch="DENY" />
<PatternLayout pattern="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%-5level] %l%c{36} - %msg%n" />
<!-- 拆分规则 -->
<Policies>
<!-- 在系统启动时,触发拆分规则,生产一个新的日志文件 -->
<OnStartupTriggeringPolicy />
<!-- 按照文件大小进行拆分 -->
<SizeBasedTriggeringPolicy size="10 MB" />
<!-- 按照时间的节点进行拆分,规则根据filePattern来定义的 -->
<TimeBasedTriggeringPolicy />
</Policies>
<!-- 在同一个目录下,文件的个数限定为30个,超过则进行覆盖 -->
<DefaultRolloverStrategy max="30" />
</RollingFile>
</Appenders>
<!-- logger的定义 -->
<Loggers>
<Root level="trace">
<AppenderRef ref="Console" />
</Root>
</Loggers>
</Configuration>
Log4j2异步日志
log4j2最大的特点就是异步日志,其性能的提升主要也是从异步日志中受益。
首先我们来看看同步日志:
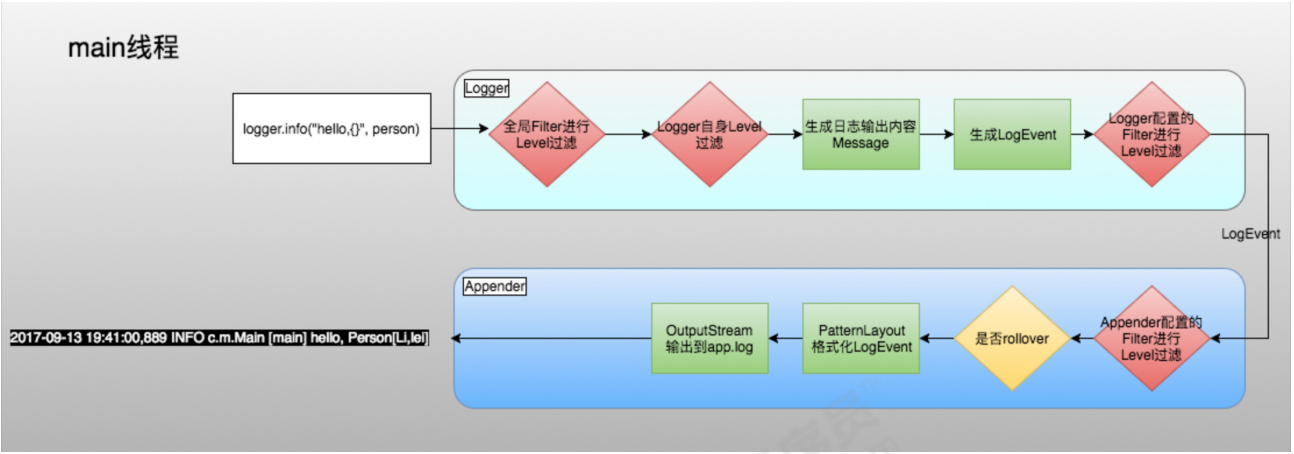
异步日志:

Log4j2提供了两种实现日志的方式,一个是通过AsyncAppender,一个是通过AsyncLogger,分别对应前面我们说的Appender组件和Logger组件。
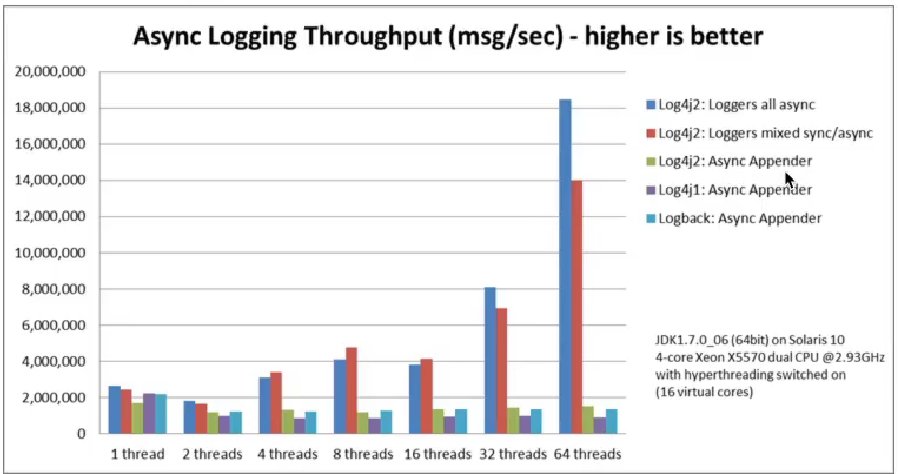
Log4j2最牛的地方在于异步输出日志时的性能表现,Log4j2在多线程的环境下吞吐量与Log4j和Logback的比较如下图。下图比较中Log4j2有三种模式:1)全局使用异步模式;2)部分Logger采用异步模式;3)异步Appender。可以看出在前两种模式下,Log4j2的性能较之Log4j和Logback有很大的优势。
注意:配置异步日志需要添加依赖
<!--异步日志依赖-->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.4</version>
</dependency>
AsyncAppender方式
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="warn">
<properties>
<property name="LOG_HOME">D:/logs</property>
</properties>
<Appenders>
<File name="file" fileName="${LOG_HOME}/myfile.log">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m%n</Pattern>
</PatternLayout>
</File>
<Async name="Async">
<AppenderRef ref="file"/>
</Async>
</Appenders>
<Loggers>
<Root level="error">
<AppenderRef ref="Async"/>
</Root>
</Loggers>
</Configuration
AsyncLogger方式
AsyncLogger才是log4j2 的重头戏,也是官方推荐的异步方式。它可以使得调用Logger.log返回的更快(从上面的图中可以看出来)。你可以有两种选择:全局异步和混合异步。
全局异步就是,所有的日志都异步的记录,在配置文件上不用做任何改动,只需要在类路径添加一个log4j2.component.properties 配置文件;
Log4jContextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
混合异步就是,你可以在应用中同时使用同步日志和异步日志,这使得日志的配置方式更加灵活。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<properties>
<property name="LOG_HOME">D:/logs</property>
</properties>
<Appenders>
<File name="file" fileName="${LOG_HOME}/myfile.log">
<PatternLayout>
<Pattern>%d %p %c{1.} [%t] %m%n</Pattern>
</PatternLayout>
</File>
</Appenders>
<Loggers>
<!-- includeLocation="false" 表示关闭日志记录的行号信息,一般为false,打开会影响异步效率 -->
<!-- additivity="false" 不再继承rootLogger对象 -->
<AsyncLogger name="com.zyb" level="trace" includeLocation="false" additivity="false">
<AppenderRef ref="file"/>
</AsyncLogger>
<Root level="info" includeLocation="true">
<AppenderRef ref="file"/>
</Root>
</Loggers>
</Configuration>
如上配置: com.zyb日志是异步的,root日志是同步的。
使用异步日志需要注意的问题:
- 如果使用异步日志,AsyncAppender、AsyncLogger和全局日志,不要同时出现。性能会和AsyncAppender一致,降至最低。
- 设置includeLocation=false ,打印位置信息会急剧降低异步日志的性能,比同步日志还要慢。
无垃圾记录
垃圾收集暂停是延迟峰值的常见原因,并且对于许多系统而言,花费大量精力来控制这些暂停。
许多日志库(包括以前版本的Log4j)在稳态日志记录期间分配临时对象,如日志事件对象,字符串,字符数组,字节数组等。这会对垃圾收集器造成压力并增加GC暂停发生的频率。
从版本2.6开始,默认情况下Log4j以“无垃圾”模式运行,其中重用对象和缓冲区,并且尽可能不分配临时对象。还有一个“低垃圾”模式,它不是完全无垃圾,但不使用ThreadLocal字段。
Log4j 2.6中的无垃圾日志记录部分通过重用ThreadLocal字段中的对象来实现,部分通过在将文本转换为字节时重用缓冲区来实现。
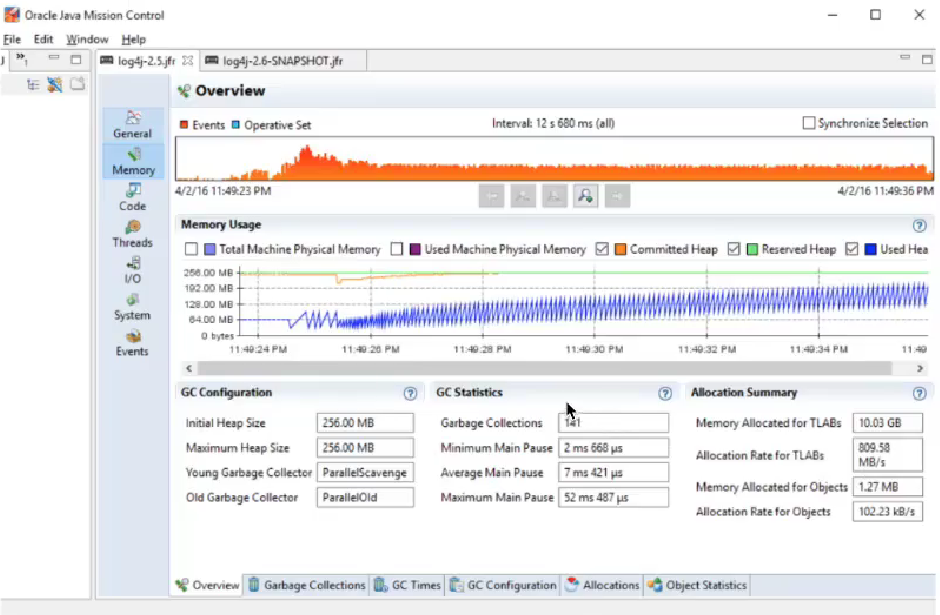
- 使用Log4j 2.5:内存分配速率809 MB /秒,141个无效集合。
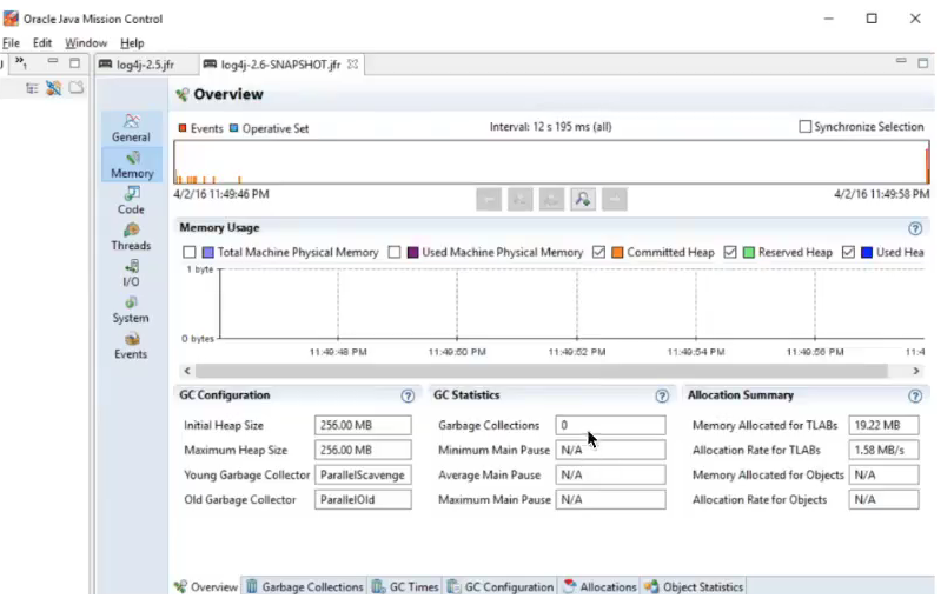
- Log4j 2.6没有分配临时对象:0(零)垃圾回收。
有两个单独的系统属性可用于手动控制Log4j用于避免创建临时对象的机制:
- log4j2.enableThreadlocals - 如果“true”(非Web应用程序的默认值)对象存储在ThreadLocal字段中并重新使用,否则将为每个日志事件创建新对象。
- log4j2.enableDirectEncoders - 如果将“true”(默认)日志事件转换为文本,则将此文本转换为字节而不创建临时对象。注意: 由于共享缓冲区上的同步,在此模式下多线程应用程序的同步日志记录性能可能更差。如果您的应用程序是多线程的并且日志记录性能很重要,请考虑使用异步记录器。
SpringBoot中的日志使用
springboot框架在企业中的使用越来越普遍,springboot日志也是开发中常用的日志系统。springboot默认就是使用SLF4J作为日志门面,logback作为日志实现来记录日志。
SpringBoot中的日志设计
springboot中的日志
<dependency>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</dependency>
依赖关系图:
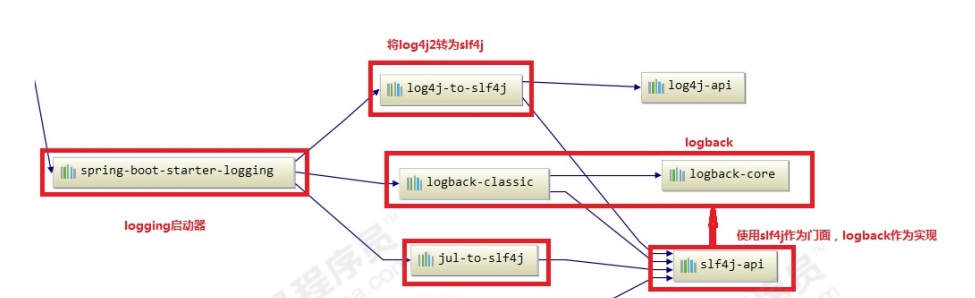
总结:
- springboot 底层默认使用logback作为日志实现。
- 使用了SLF4J作为日志门面
- 将JUL也转换成slf4j
- 也可以使用log4j2作为日志门面,但是最终也是通过slf4j调用logback
SpringBoot日志使用
在springboot中测试打印日志
@SpringBootTest
class SpringbootLogApplicationTests {
//记录器
public static final Logger LOGGER = LoggerFactory.getLogger(SpringbootLogApplicationTests.class);
@Test
public void contextLoads() {
// 打印日志信息
LOGGER.error("error");
LOGGER.warn("warn");
LOGGER.info("info"); // 默认日志级别
LOGGER.debug("debug");
LOGGER.trace("trace");
}
}
修改默认日志配置
logging.level.com.zyb=trace
# 在控制台输出的日志的格式 同logback
logging.pattern.console=%d{yyyy-MM-dd} [%thread] [%-5level] %logger{50} - %msg%n
# 指定文件中日志输出的格式
logging.file=D:/logs/springboot.log
logging.pattern.file=%d{yyyy-MM-dd} [%thread] %-5level %logger{50} - %msg%n
指定配置
给类路径下放上每个日志框架自己的配置文件;SpringBoot就不使用默认配置的了:
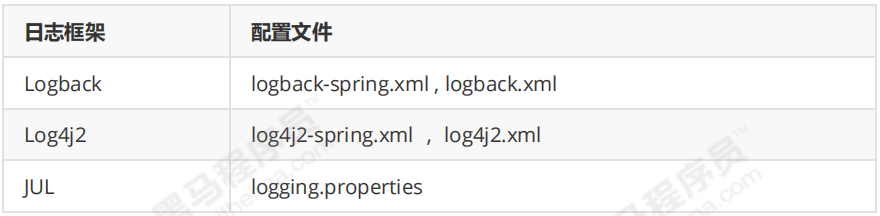
使用SpringBoot解析日志配置
logback-spring.xml:由SpringBoot解析日志配置
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<springProfile name="dev">
<pattern>${pattern}</pattern>
</springProfile>
<springProfile name="pro">
<pattern>%d{yyyyMMdd:HH:mm:ss.SSS} [%thread] %-5level %msg%n</pattern>
</springProfile>
</encoder>
application.properties
spring.profiles.active=dev
将日志切换为log4j2
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<!--排除logback-->
<exclusion>
<artifactId>spring-boot-starter-logging</artifactId>
<groupId>org.springframework.boot</groupId>
</exclusion>
</exclusions>
</dependency>
<!-- 添加log4j2 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>