文章目录
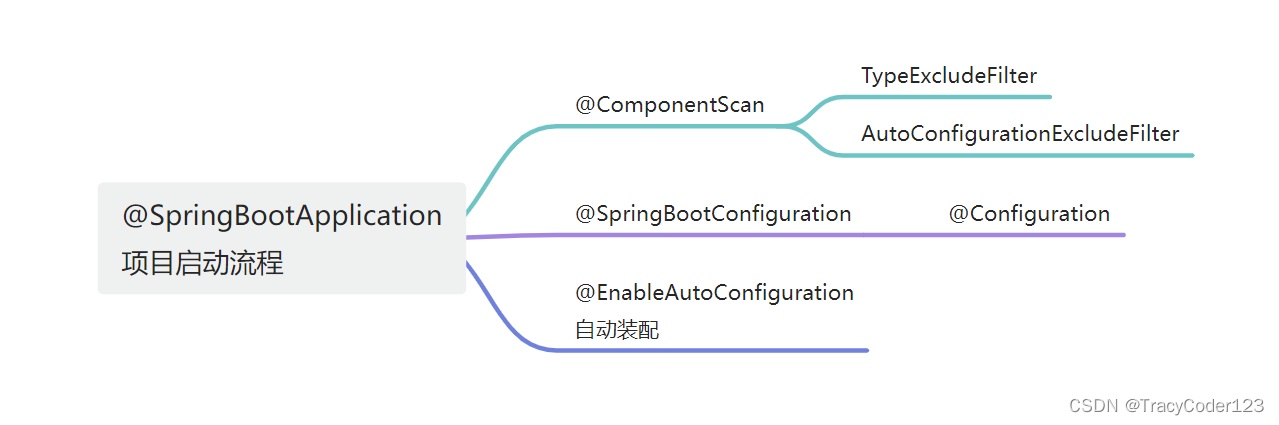
- 1、CPU和GPU的架构
- 2、CPUs: 延迟导向设计和GPUs: 吞吐导向设计
- 2.1 CPUs: 延迟导向设计
- 2.2 GPUs: 吞吐导向设计
- 2.3 GPU&CPU特点
- 2.4 GPU编程:什么样的问题适合GPU
- 3、GPU编程与CUDA
- 3.1 CUDA编程并行计算整体流程
- 3.2 CUDA编程术语
- 3.2.1 硬件
- 3.2.2 内存模型
- 3.2.3 软件
- 3.2.4 线程块:可扩展的集合体
- 3.2.5 网格(grid):并行线程块组合
- 3.2.6 线程块id&线程id:定位独立线程的门牌号
- 3.2.6.1 线程id计算
- 3.2.7 线程束(warp )
- 4、 并行计算实例:向量相加
1、CPU和GPU的架构
吞吐:单位时间内处理的指令条数
延迟:一条指令从发出到返回结果所需要的时间
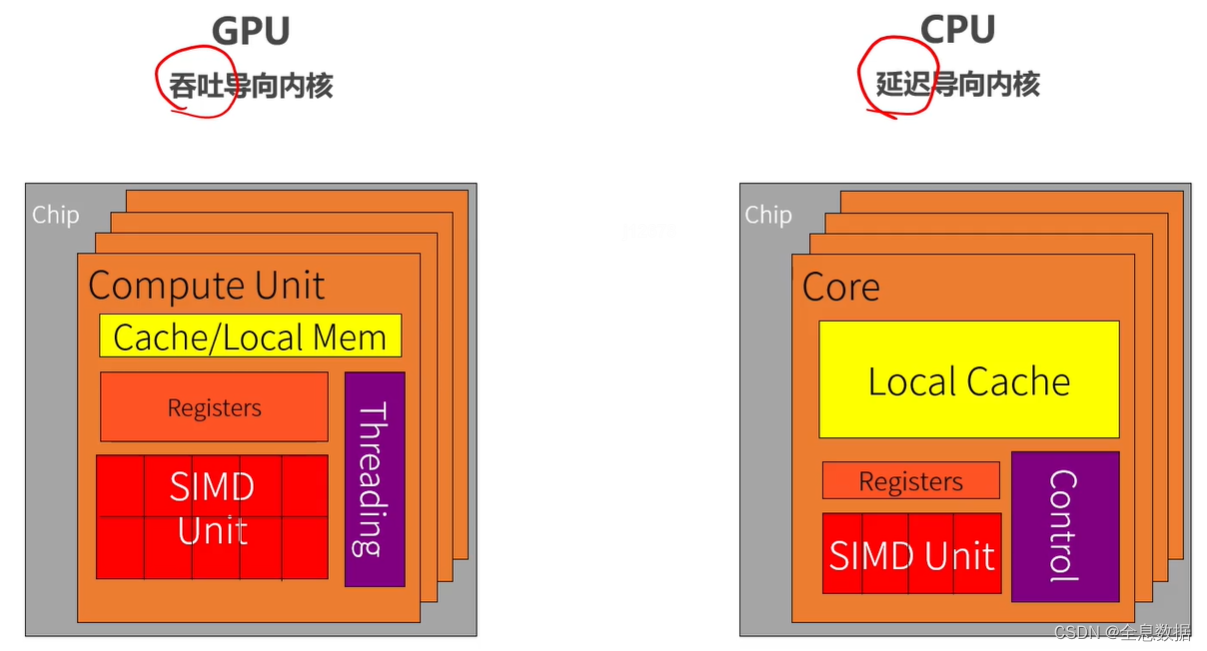
2、CPUs: 延迟导向设计和GPUs: 吞吐导向设计
2.1 CPUs: 延迟导向设计
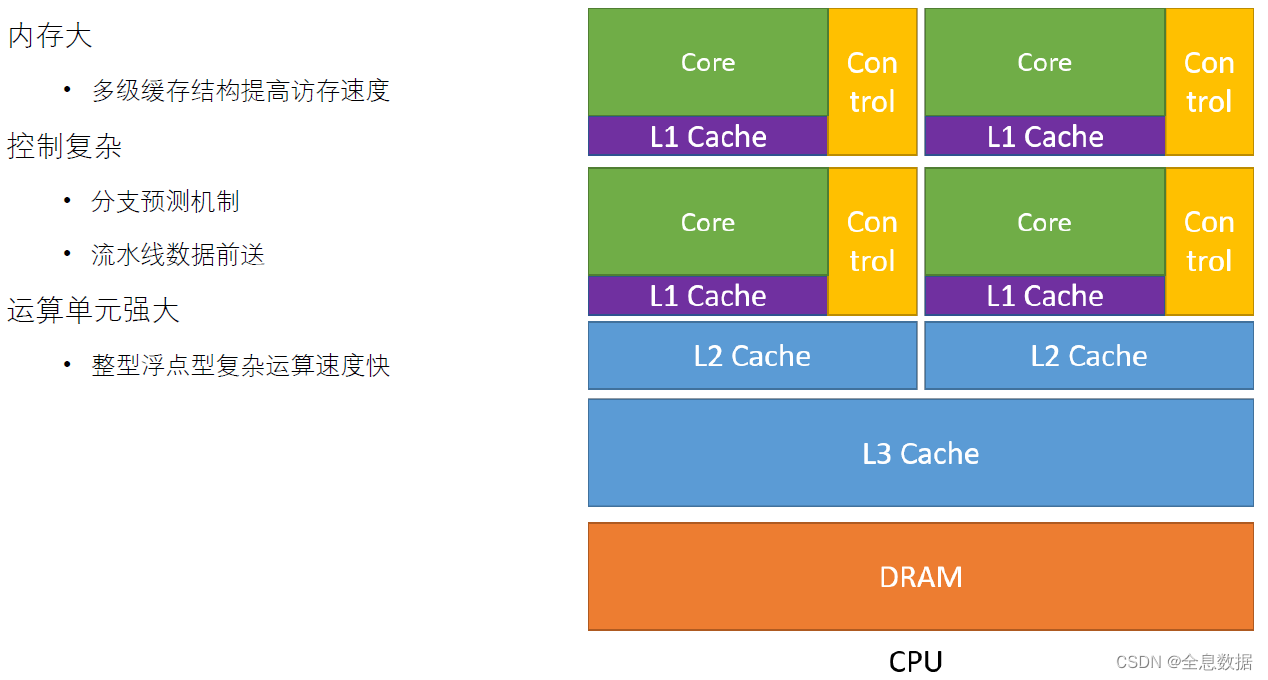
处理运算的速度远高于存储访问的速度,以空间换时间的方式,所以CPU设计了这种多级缓存的结构。
2.2 GPUs: 吞吐导向设计

2.3 GPU&CPU特点

2.4 GPU编程:什么样的问题适合GPU
计算密集:数值计算的比例要远大于内存操作,因此内存访问的延时可以被计算掩盖。
数据并行:大任务可以拆解为执行相同指令的小任务,因此对复杂流程控制的需求较低。
3、GPU编程与CUDA
CUDA(Compute Unified Device Architecture),由英伟达公司2007年开始推出,初衷是为GPU增加一个易用的编程接口,让开发者无需学习复杂的着色语言或者图形处理原语。
OpenCL(Open Computing Languge)是2008年发布的异构平台并行编程的开放标准,也是一个编程框架。OpenCL相比CUDA,支持的平台更多,除了GPU还支持CPU、DSP、FPGA等设备。
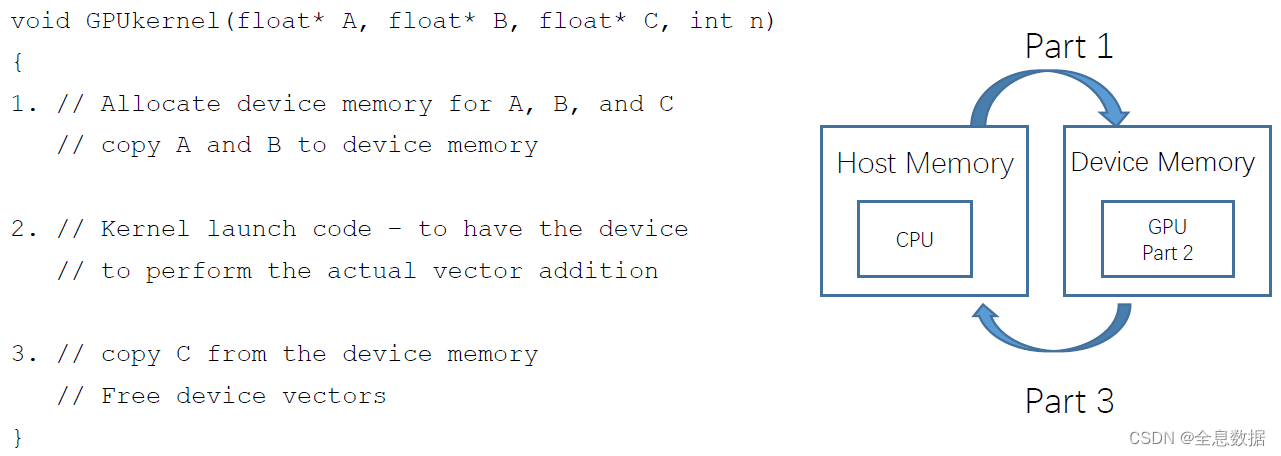
3.1 CUDA编程并行计算整体流程
1个CUDA程序可以分为3个步骤,第一个步骤是从主机端(CPU)申请内存,然后再把主机中内存的内容拷贝到设备端(GPU),第二个步骤是设备端的核函数进行计算,第三个步骤是把设备端内存的内容拷贝到主机,最后释放显存和内存。
3.2 CUDA编程术语
3.2.1 硬件
Device=GPU
Host=CPU
Kernel=GPU上运行的函数
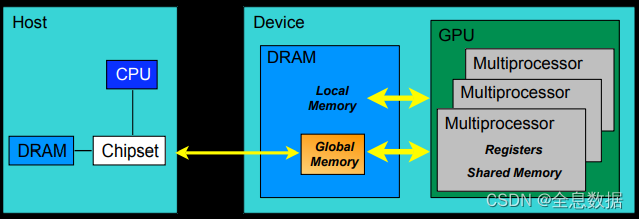
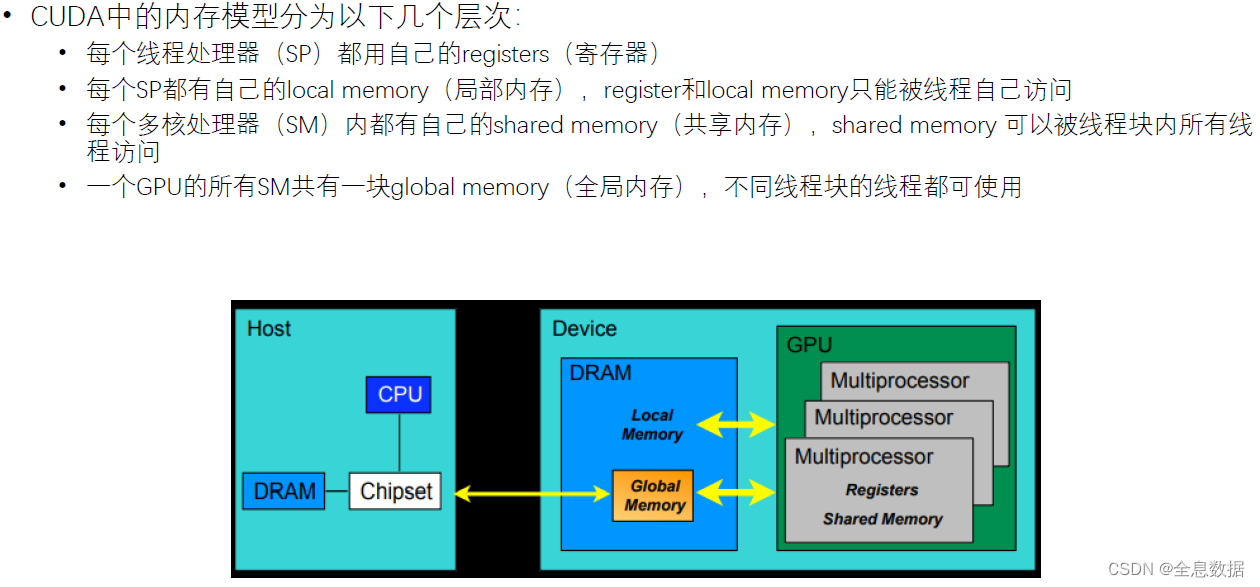
3.2.2 内存模型
CUDA模型最基本的单位是线程处理器(SP)
多个线程处理器(SP)和一个shared memory(共享内存)构成一个多核处理器(SM),多个线程处理器(SP)之间是并行运行的
多个多核处理器(SM)和一个global memory(全局内存)构成一个GPU,多个多核处理器(SM)之间是并行运行的
3.2.3 软件
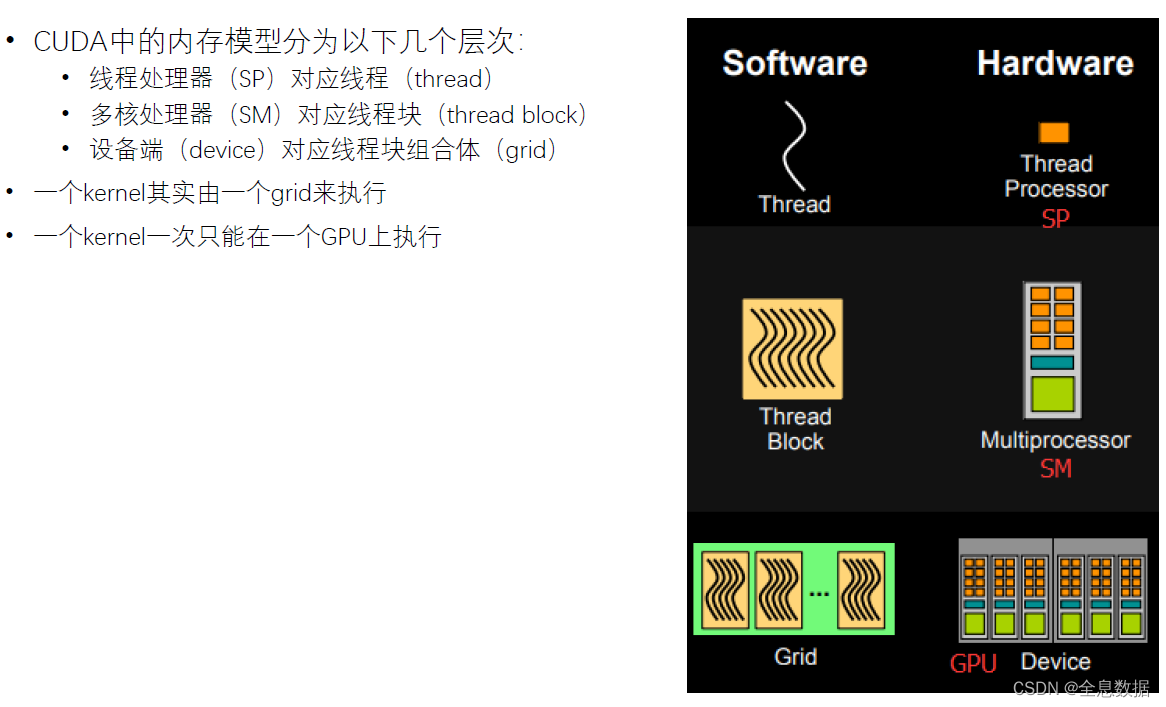
3.2.4 线程块:可扩展的集合体
线程:内存模型在软件侧最基本的执行单位
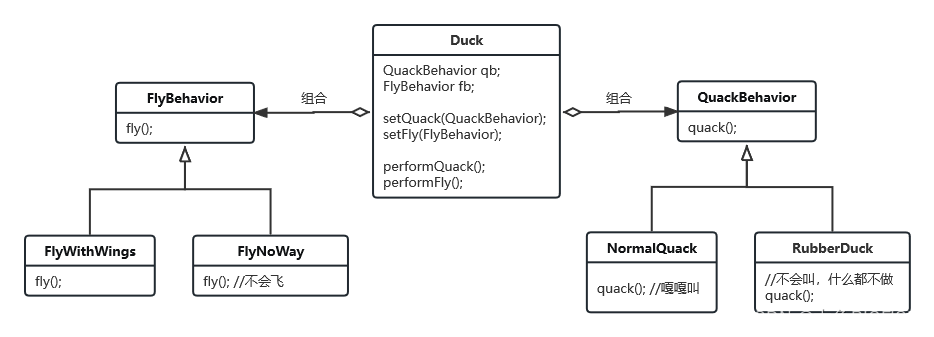
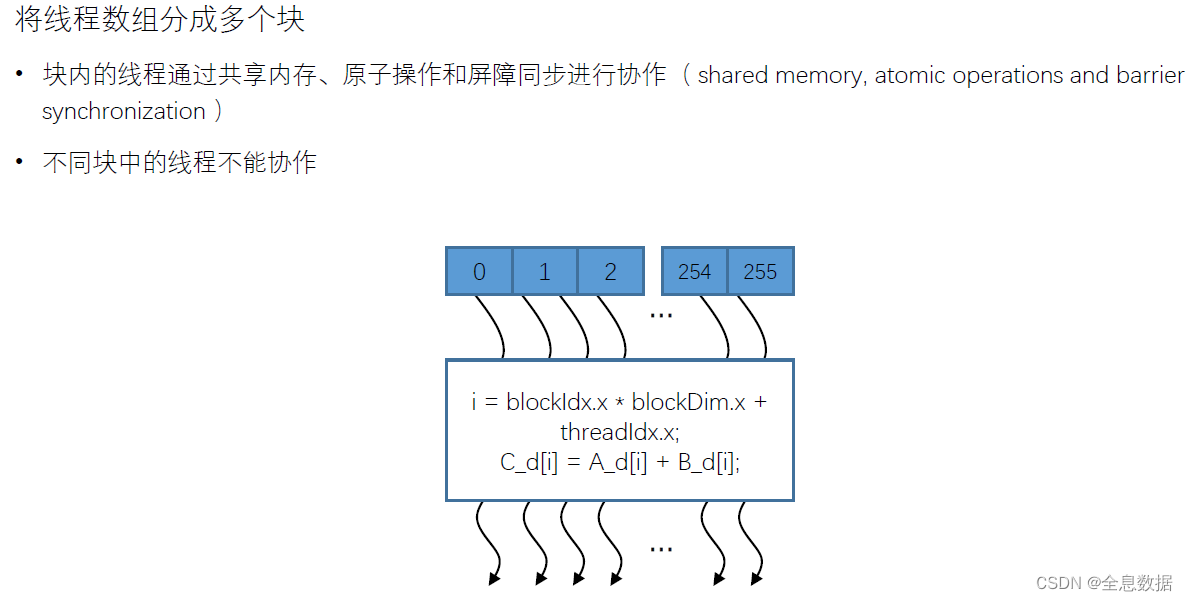
线程块:线程的组合体;有3个特点:1、线程块内的所有线程各自独立计算和访问存储,2、线程块内的共享内存可以被线程块内的所有线程所共享,3、用一个共有的时钟来去将线程块内的所有线程来进行一个同步和原子操作,进而保障线程块内所有线程的同步性。
如下图,一个线程块由256个线程所组成,各个线程独立计算,最后由一个时钟来将256个线程独立计算的结果进行同步
3.2.5 网格(grid):并行线程块组合
网格定义:线程块的组合体
网格也有3个特点:1、网格内的线程块彼此独立,互不影响,2、网格中的全局内存可以由各个线程块访问,3、可以用一个公有的时钟来同步网格内的所有线程块
3.2.6 线程块id&线程id:定位独立线程的门牌号
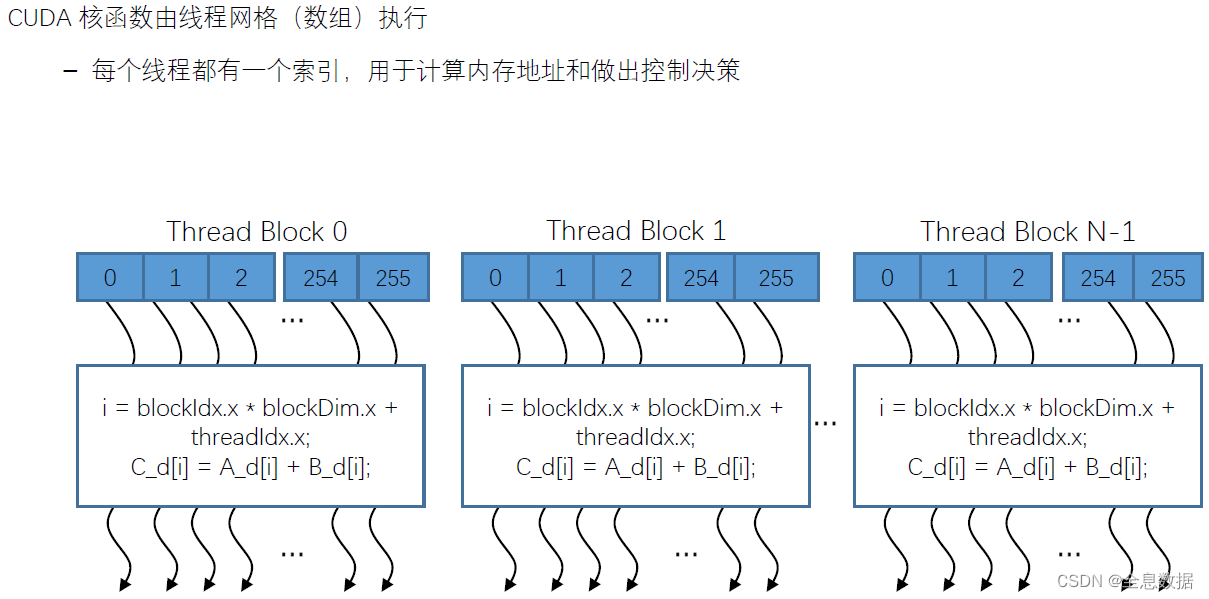
核函数是在设备端执行的函数,内存模型一个非常关键的一点是内存和显存之间的拷贝,当核函数调用每个线程的寄存器和局部内存的时候,需要确定线程在显存中的位置
blockIdx:线程块索引,
threadIdx:线程索引,
如下图,Grid 1是网格,是由2x2个线程块(Block)组成,每个线程块(Block)是由2x4x2个线程组成
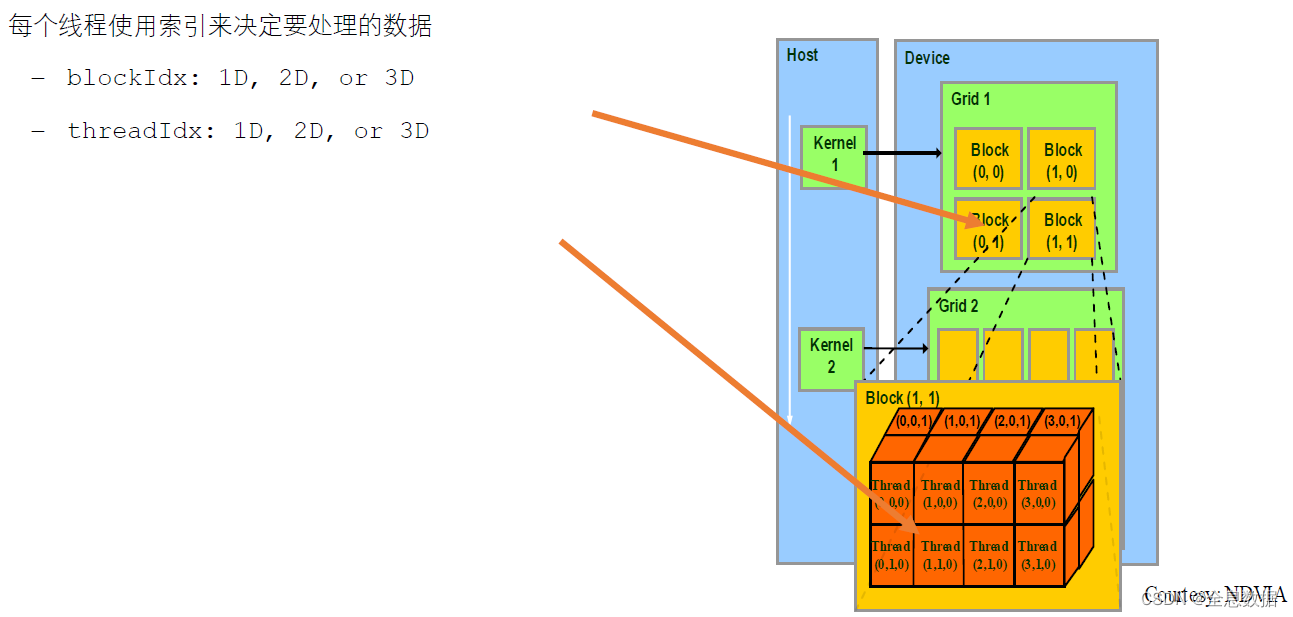
3.2.6.1 线程id计算
如下图,Grid 1是由2x2个Block组成,所以M为2,N也为2;每个Block是由4x2x2个Thread组成,所以P为4,Q为2,S为2
threadId.x:线程x的索引,它等于线程块x维度的索引乘以线程块x维度的大小,再加上线程x维度的索引; 以此类推threadId.y
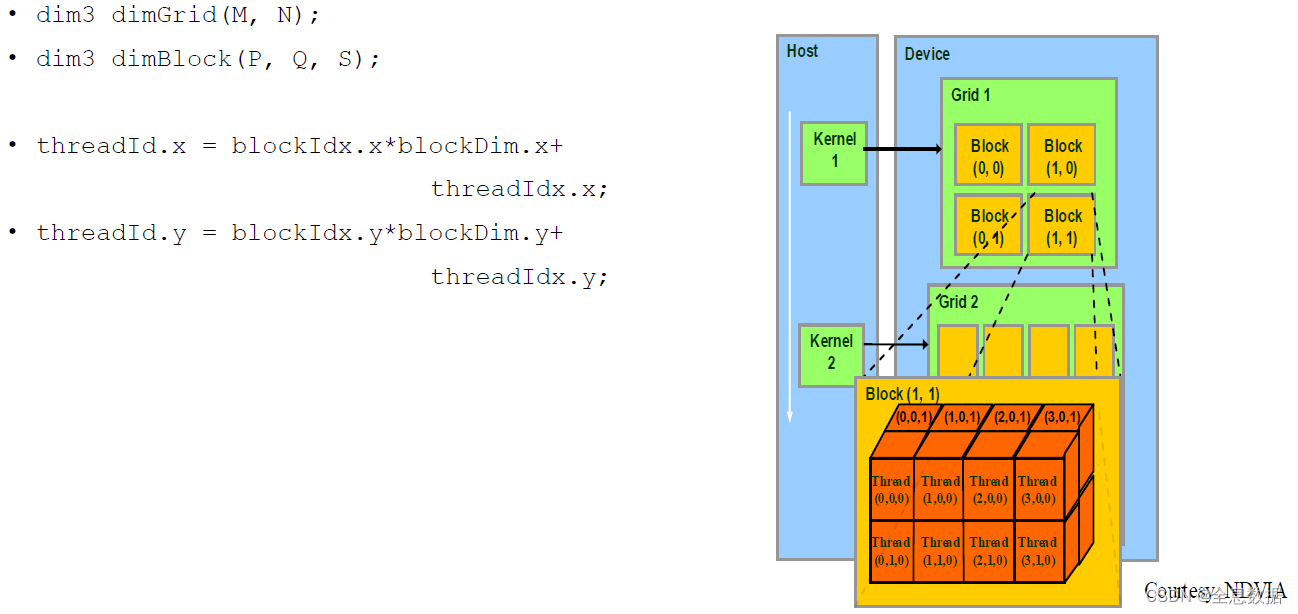
3.2.7 线程束(warp )

4、 并行计算实例:向量相加
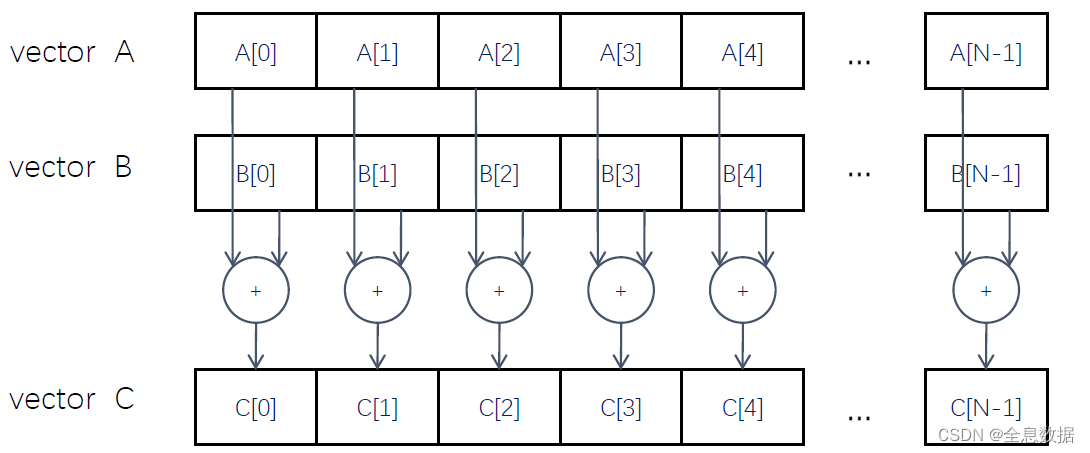

![心法利器[89] | 实用文本生成中的解码方法](https://img-blog.csdnimg.cn/img_convert/9e0f27af632c4e0061e45724bf322b48.png)
![[CVPR‘23] PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360 deg](https://img-blog.csdnimg.cn/610649e5fecc4c14bee9c6f210457e0a.png)