心法利器
本栏目主要和大家一起讨论近期自己学习的心得和体会,与大家一起成长。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。
2022年新一版的文章合集已经发布,累计已经60w字了,获取方式看这里:CS的陋室60w字原创算法经验分享-2022版。(2023在路上了!)
往期回顾
心法利器[84] | 最近面试小结
心法利器[85] | 算法技术和职业规划
心法利器[86] | 毕业4年的算法工程师:进步再进步
心法利器[87] | 填志愿:AI算法方向过来人的建议
心法利器[88] | 有关大模型幻觉问题的思考
最近大模型挺火的,在学习的过程中,偶然间发现在解码上,似乎能有不少花样,而且通过调整似乎也能得到很不一样的回复内容,而且这也是文本生成中很关键的一块,所以最近趁机就把这块内容学习了一下。
本文主要参考了这篇的内容:
英文版:https://huggingface.co/blog/how-to-generate
中文版:https://huggingface.co/blog/zh/how-to-generate
为什么需要解码
在文章中,所有的解码都是指代的自回归式的生成任务,简单的可以理解为每个词的预测其实都是基于上文的词的概率分布对这个位置进行的预测,说白了就是一个很简单的条件概率。然而,模型预测出来的,其实是每个位置的概率分布,即这个位置下每个词在这个位置的可能性,而所谓的解码,就是根据这一系列的概率分布,在每一步选择最优的词汇,从而最终输出一个句子。
假设模型的初始化如下:
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)贪心解码(greedy search)
顾名思义,就是在每一步都选择概率最大的词,这也是速度最快的解码方式了,这个图直接就能用看出来:
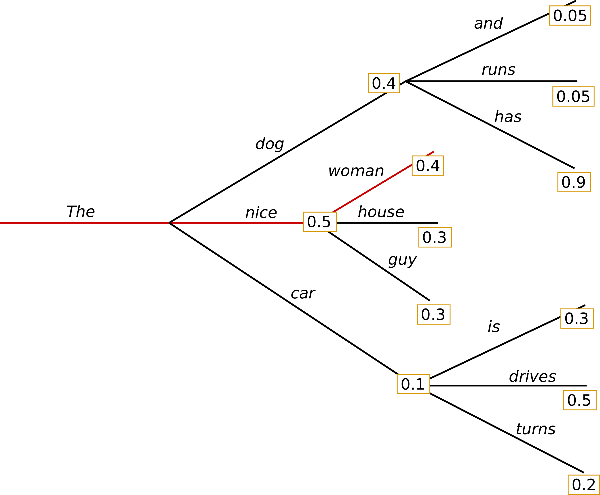
从图里可以看到,每一步其实选择的都是概率最高的那个分支。然后是代码:
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))理论上这个似乎是合理的,但实际上的输出是这样的:
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll大家可以发现,生成的过程中开始重复了,主要原因是贪心搜索只关注眼前最大值,而忽略了后续可能有整体最大的选择,因此我们吸纳更多的选择来综合打分,尽可能选择一个全局最优解。
束搜素(beam search)
很显然,因为词汇过多,所以我们是无法再每一步都遍历所有的可能,这将会是的复杂度,因此我们倒是可以选TOPN的词汇来往后搜索即可。
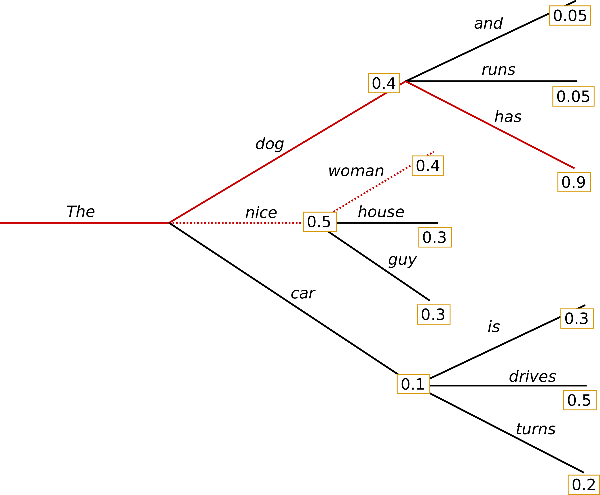
假设这次每次的选择都是TOP2,其实会发现,总结下来似乎确实是能找到更好的解码结果。
# activate beam search and early_stopping
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure if I'll但我们也看到,内容依旧会有重复,从模型的输出角度,我们知道模型总会选出一定范围内最大的选择,有些话确实可能会因为上文而重复循环出现,因此我们需要对这些容易重复的内容进行一定的惩罚。
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to take a break这样重复就得到缓解甚至避免了。当然了,这种避免重复的方式还是需要避免,尤其是某些带有关键话题的内容,如果约束了,某些主题词可能出现的次数就太少了。
另外,我们还可以用num_return_sequences这个字段来控制输出句子的个数,有更多选择也会在一些场景比较方便,注意num_return_sequences<num_beams`。
采样(sampling)
采样,就是在对每一个位置预测的时候,以该位置的概率分布随机选择输出词,这种方式最大的特点就是增加了随机性(注意,是特点,有的时候这样做可能是负效果的,除非固定了random_seed)。
设置采样的开关在do_sample这个字段,为True的时候,就启动了do_sample。
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))这里仔细看看输出:
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog. He just gave me a whole new hand sense."
But it seems that the dogs have learned a lot from teasing at the local batte harness once they take on the outside.
"I take从这里看,输出似乎流畅,但会出现一定的不合理性,核心原因是因为这个采样,运气不好会找到一些不合适的单词的,为了缓解这个问题,可以通过设置温度来进行调整,这个温度实际上是加载softmax中的,用于锐化或拉平这个概率分布,一般温度越小差异越大,此时,概率高的词汇概率会变得更高,从而更容易被选择,从而缓解选出不太可能的词汇的问题。
# set seed to reproduce results. Feel free to change the seed though to get different results
tf.random.set_seed(0)
# use temperature to decrease the sensitivity to low probability candidates
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))Top-K采样和Top-p采样
Top-K采样是指在选择的时候,最大的K个词会被选择出来,选出来后重新归一化,再来进行采样,这种方式能更大限度避免选出不太可能的词汇。
# set top_k to 50
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))但是在某些时候还是有问题,概率分布有时候倾向性可能很明显,有时候又会不那么明显,如果是按照强硬的个数条件进行选择,此时仍有可能选到后面的词汇概率仍旧非常低,此时又有了top-p采样,即按照累计概率进行采样,当前N个词汇的累计概率大于我们预设的概率时,就会停止采样。
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))小结
有关上面的多个生成方案,其实只是通过某个方式串起来而已,他们之间可能没有明显的上下位关系,而是一个优劣势互补的关系,很多时候可能我们要进经过一些筛选。
另外,generate里面,其实有很多可供控制的参数,具体的大家可以参考这几篇文章:
https://huggingface.co/docs/transformers/v4.30.0/en/generation_strategies#customize-text-generation
https://blog.csdn.net/muyao987/article/details/125917234

![[CVPR‘23] PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360 deg](https://img-blog.csdnimg.cn/610649e5fecc4c14bee9c6f210457e0a.png)