目录
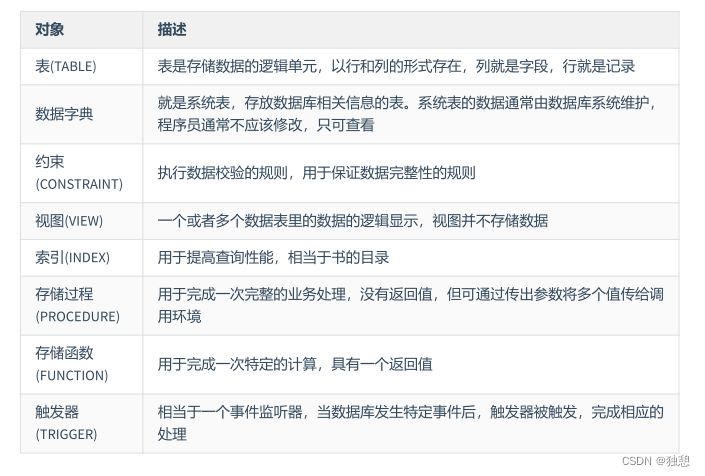
常见的数据库对象
编辑
视图
创建视图
改变视图
优缺点
存储过程与存储函数
创建存储过程
创建存储函数
存储过程和存储函数的区别
存储过程和函数的查看、修改、删除
查看
修改
删除
存储过程的优缺点
优点
缺点
变量
系统变量
查看系统变量
修改变量
用户变量
会话用户变量
局部变量
常见的数据库对象
视图
视图一方面可以帮我们使用表的一部分而不是所有的表,另一方面也可以针对不同的用户制定不同的查询视图。比如,针对一个公司的销售人员,我们只想给他看部分数据,而某些特殊的数据,比如采购的价格,则不会提供给他。再比如,人员薪酬是个敏感的字段,那么只给某个级别以上的人员开放,其他人的查询视图中则不提供这个字段。
在之前的方案中,如果要提取表的一部分,可以使用create table xxx as select xxx的方式创建一个新的表,但是在新表的更改不会影响原始表的数据
而视图则能选择显示原表的一部分,在这部分的更改也能影响到原表的数据
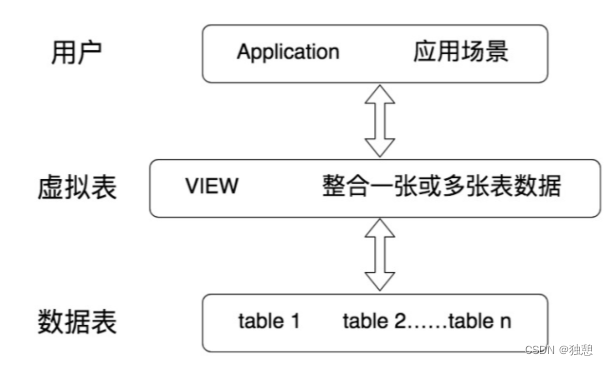
视图是一种虚拟表 ,本身是不具有数据的,占用很少的内存空间,它是 SQL 中的一个重要概念。
视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。视图,是向用户提供基表数据的另一种表现形式。通常情况下,小型项目的数据库可以不使用视图,但是在大型项目中,以及数据表比较复杂的情况下,视图的价值就凸显出来了,它可以帮助我们把经常查询的结果集放到虚拟表中,提升使用效率。理解和使用起来都非常方便。
创建视图
CREATE VIEW emp1view
AS
SELECT employee_id,last_name,department_id
FROM emp1
SELECT *
FROM emp1view或者定义,存在就替换,不存在就创建:
CREATE OR REPLACE VIEW emp1view
AS
SELECT employee_id,last_name,department_id
FROM emp1
SELECT *
FROM emp1view确定视图中的字段名
1、直接使用别名
CREATE VIEW emp1view
AS
SELECT employee_id id,last_name lname,department_id did
FROM emp1
SELECT *
FROM emp1view2、用小括号
CREATE VIEW emp1view(id,lname,did)
AS
SELECT employee_id ,last_name,department_id
FROM emp1
SELECT *
FROM emp1view改变视图
对于试图的增删改查跟基础的表一样
不能更新原表中没有的数据
CREATE VIEW emp1
AS
SELECT department_id,AVG(salary) avg_salary
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
UPDATE emp1
SET avg_salary = 10
WHERE department_id = 10avg_salary这个列是计算得到的,原表中不存在,所以不能对其进行更改
- 在定义视图的时候指定了“ALGORITHM = TEMPTABLE”,视图将不支持INSERT和DELETE操作;
- 视图中不包含基表中所有被定义为非空又未指定默认值的列,视图将不支持INSERT操作; 在定义视图的SELECT语句中使用了 JOIN联合查询 ,视图将不支持INSERT和DELETE操作;
- 在定义视图的SELECT语句后的字段列表中使用了 数学表达式 或 子查询 ,视图将不支持INSERT,也 不支持UPDATE使用了数学表达式、子查询的字段值;
- 在定义视图的SELECT语句后的字段列表中使用 DISTINCT 、 聚合函数 、 GROUP BY 、 HAVING 、 UNION 等,视图将不支持INSERT、UPDATE、DELETE;
- 在定义视图的SELECT语句中包含了子查询,而子查询中引用了FROM后面的表,视图将不支持 INSERT、UPDATE、DELETE;
- 视图定义基于一个 不可更新视图 ;
- 常量视图。
虽然可以更新视图数据,但总的来说,视图作为 虚拟表 ,主要用于 方便查询 ,不建议更新视图的 数据。对视图数据的更改,都是通过对实际数据表里数据的操作来完成的。
删除视图
DROP VIEW emp1优缺点
优点
1. 操作简单 将经常使用的查询操作定义为视图,可以使开发人员不需要关心视图对应的数据表的结构、表与表之间 的关联关系,也不需要关心数据表之间的业务逻辑和查询条件,而只需要简单地操作视图即可,极大简 化了开发人员对数据库的操作。
2. 减少数据冗余 视图跟实际数据表不一样,它存储的是查询语句。所以,在使用的时候,我们要通过定义视图的查询语 句来获取结果集。而视图本身不存储数据,不占用数据存储的资源,减少了数据冗余。
3. 数据安全 MySQL将用户对数据的 访问限制 在某些数据的结果集上,而这些数据的结果集可以使用视图来实现。用 户不必直接查询或操作数据表。这也可以理解为视图具有 隔离性 。视图相当于在用户和实际的数据表之 间加了一层虚拟表。
4. 适应灵活多变的需求 当业务系统的需求发生变化后,如果需要改动数据表的结构,则工作量相对较 大,可以使用视图来减少改动的工作量。这种方式在实际工作中使用得比较多。
5. 能够分解复杂的查询逻辑 数据库中如果存在复杂的查询逻辑,则可以将问题进行分解,创建多个视图 获取数据,再将创建的多个视图结合起来,完成复杂的查询逻辑。
缺点
如果我们在实际数据表的基础上创建了视图,那么,如果实际数据表的结构变更了,我们就需要及时对 相关的视图进行相应的维护。特别是嵌套的视图(就是在视图的基础上创建视图),维护会变得比较复 杂, 可读性不好 ,容易变成系统的潜在隐患。因为创建视图的 SQL 查询可能会对字段重命名,也可能包 含复杂的逻辑,这些都会增加维护的成本。
实际项目中,如果视图过多,会导致数据库维护成本的问题。
所以,在创建视图的时候,你要结合实际项目需求,综合考虑视图的优点和不足,这样才能正确使用视 图,使系统整体达到最优
存储过程与存储函数
存储过程的英文是 Stored Procedure 。它的思想很简单,就是一组经过 预先编译 的 SQL 语句 的封装。
其实说白了就是 自己定义的函数,存储过程是没有返回值的函数,而存储函数是有返回值的函数
创建存储过程
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN
存储过程体
END
characteristics 表示创建存储过程时指定的对存储过程的约束条件,其取值信息如下:
LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
- LANGUAGE SQL :说明存储过程执行体是由SQL语句组成的,当前系统支持的语言为SQL。
- [NOT] DETERMINISTIC :指明存储过程执行的结果是否确定。DETERMINISTIC表示结果是确定 的。每次执行存储过程时,相同的输入会得到相同的输出。NOT DETERMINISTIC表示结果是不确定 的,相同的输入可能得到不同的输出。如果没有指定任意一个值,默认为NOT DETERMINISTIC。
- { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } :指明子程序使 用SQL语句的限制。
CONTAINS SQL表示当前存储过程的子程序包含SQL语句,但是并不包含读写数据的SQL语句;
NO SQL表示当前存储过程的子程序中不包含任何SQL语句;
READS SQL DATA表示当前存储过程的子程序中包含读数据的SQL语句;
MODIFIES SQL DATA表示当前存储过程的子程序中包含写数据的SQL语句。
默认情况下,系统会指定为CONTAINS SQL。
- SQL SECURITY { DEFINER | INVOKER } :执行当前存储过程的权限,即指明哪些用户能够执 行当前存储过程。
DEFINER 表示只有当前存储过程的创建者或者定义者才能执行当前存储过程;
INVOKER 表示拥有当前存储过程的访问权限的用户能够执行当前存储过程。
无输入无输出过程
DELIMITER $
CREATE PROCEDURE see_all_data()
BEGIN
SELECT * FROM employees;
END $
DELIMITER;
CALL see_all_data()这里的DELIMITER代表终止符,因为MySQL默认的语句结束符号为分号‘;’。为了避免与存储过程中SQL语句结束符相冲突,需要使用 DELIMITER改变存储过程的结束符。
比如上面这个例子,先定义终止符 $,等过程定义结束之后再定义回来;
我在自己使用时,加入DELIMITER;会报错,去掉就好了,估计是版本问题
无输入有输出过程
DELIMITER $
CREATE PROCEDURE see_all_data1(OUT ms DOUBLE(8,2))
BEGIN
SELECT MAX(salary) INTO ms FROM employees;
END $
DELIMITER;
CALL see_all_data1(@ms);
SELECT @ms有输入无输出过程
DELIMITER $
CREATE PROCEDURE see_someone_salary(IN empname VARCHAR(10))
BEGIN
SELECT salary
FROM employees
WHERE last_name = empname;
END $
DELIMITER ;
CALL see_someone_salary('Abel');有输出有输出
DELIMITER $
CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DOUBLE)
BEGIN
SELECT salary INTO empsalary FROM employees WHERE last_name = empname;
END $
DELIMITER ;
CALL show_someone_salary2('Abel',@empsalary);
SELECT @empsalary输出和输入定义到一个变量中
DELIMITER $
CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(20))
BEGIN
SELECT last_name INTO empname
FROM employees
WHERE employee_id = (
SELECT manager_id
FROM employees
WHERE last_name = empname
);
END $
DELIMITER ;
SET @empname := 'Abel';
CALL show_mgr_name(@empname);创建存储函数
CREATE FUNCTION 函数名(参数名 参数类型,...)
RETURNS 返回值类型
[characteristics ...]
BEGIN
函数体 #函数体中肯定有 RETURN 语句
END1、参数列表:指定参数为IN、OUT或INOUT只对PROCEDURE是合法的,FUNCTION中总是默认为IN参数。
2、RETURNS type 语句表示函数返回数据的类型;
RETURNS子句只能对FUNCTION做指定,对函数而言这是强制的。它用来指定函数的返回类型,而且函数体必须包含一个 RETURN value语句。
3、characteristic 创建函数时指定的对函数的约束。取值与创建存储过程时相同,这里不再赘述。
4、函数体也可以用BEGIN…END来表示SQL代码的开始和结束。如果函数体只有一条语句,也可以省略BEGIN…END
我们必须指定我们的函数是
- DETERMINISTIC 不确定的
- NO SQL 没有SQl语句
- READS SQL DATA 只是读取数据
- MODIFIES SQL DATA 要修改数据
- CONTAINS SQL 包含SQL语句
无输入参数:
DELIMITER //
CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQL
BEGIN
RETURN (SELECT email FROM employees WHERE last_name = 'Abel');
END //
DELIMITER ;
有输入参数:
DELIMITER //
CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQL
BEGIN
RETURN (SELECT email FROM employees WHERE employee_id = emp_id);
END //
DELIMITER ;
SELECT email_by_id(111)存储过程和存储函数的区别
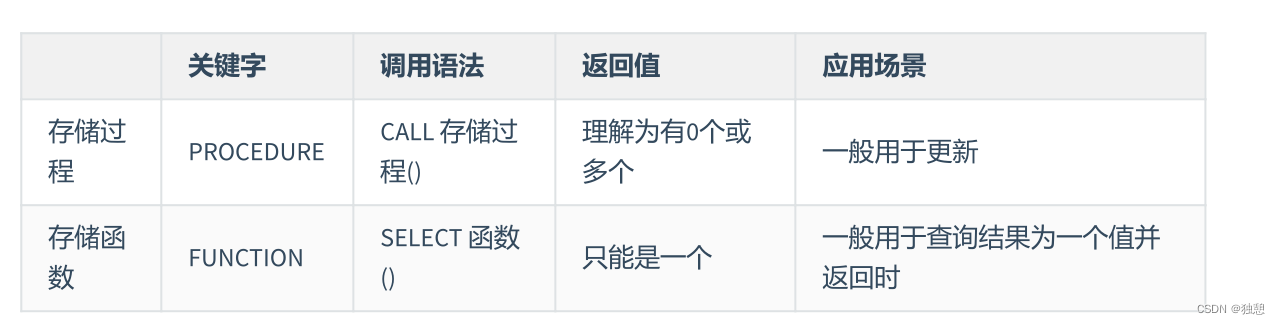
此外,存储函数可以放在查询语句中使用,存储过程不行。反之,存储过程的功能更加强大,包括能够执行对表的操作(比如创建表,删除表等)和事务操作,这些功能是存储函数不具备的。
存储过程和函数的查看、修改、删除
查看
查看某个过程或者函数
show create procedure xxx
show create finction xxxx这种方法一般看不到语句,一般是在cmd里面看“:
show create procedure xxx\G
show create finction xxxx\G查看整体的函数或者函数,或者特定的过程或者函数
show procedure status
show function status
show procedure status like xxxx
show function status like xxxx或者从information_schema.`ROUTINES`表中查看
select *
from information_schema.`ROUTINES`
where routine_name = 'see_all_data' and routine_type = 'PROCEDURE'
修改
不修改函数或者过程的本身,只修改相关的特性
ALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'CONTAINS SQL ,表示子程序包含SQL语句,但不包含读或写数据的语句。
NO SQL ,表示子程序中不包含SQL语句。
READS SQL DATA ,表示子程序中包含读数据的语句。
MODIFIES SQL DATA ,表示子程序中包含写数据的语句。
SQL SECURITY { DEFINER | INVOKER } ,指明谁有权限来执行。
DEFINER ,表示只有定义者自己才能够执行。
INVOKER ,表示调用者可以执行。
COMMENT 'string' ,表示注释信息。
删除
DROP {PROCEDURE | FUNCTION} [IF EXISTS] 存储过程或函数的名存储过程的优缺点
优点
1、存储过程可以一次编译多次使用。存储过程只在创建时进行编译,之后的使用都不需要重新编译, 这就提升了 SQL 的执行效率。
2、可以减少开发工作量。将代码 封装 成模块,实际上是编程的核心思想之一,这样可以把复杂的问题 拆解成不同的模块,然后模块之间可以 重复使用 ,在减少开发工作量的同时,还能保证代码的结构清 晰。
3、存储过程的安全性强。我们在设定存储过程的时候可以 设置对用户的使用权限 ,这样就和视图一样具 有较强的安全性。
4、可以减少网络传输量。因为代码封装到存储过程中,每次使用只需要调用存储过程即可,这样就减 少了网络传输量。
5、良好的封装性。在进行相对复杂的数据库操作时,原本需要使用一条一条的 SQL 语句,可能要连接 多次数据库才能完成的操作,现在变成了一次存储过程,只需要 连接一次即可 。
缺点
1、可移植性差。存储过程不能跨数据库移植,比如在 MySQL、Oracle 和 SQL Server 里编写的存储过 程,在换成其他数据库时都需要重新编写。
2、调试困难。只有少数 DBMS 支持存储过程的调试。对于复杂的存储过程来说,开发和维护都不容 易。虽然也有一些第三方工具可以对存储过程进行调试,但要收费。
3、存储过程的版本管理很困难。比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发 软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
4、它不适合高并发的场景。高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方 式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护, 增加数据库的压力 ,显然就 不适用了。
变量
系统变量
分为系统变量(全局系统变量、会话系统变量)和用户变量
查看系统变量
#查看所有全局变量
SHOW GLOBAL VARIABLES;
#查看所有会话变量
SHOW SESSION VARIABLES;
或
SHOW VARIABLES;
#查看满足条件的部分系统变量。
SHOW GLOBAL VARIABLES LIKE '%标识符%';
#查看满足条件的部分会话变量
SHOW SESSION VARIABLES LIKE '%标识符%';
查看指定的变量
作为 MySQL 编码规范,MySQL 中的系统变量以 两个“@” 开头,其中“@@global”仅用于标记全局系统变 量,“@@session”仅用于标记会话系统变量。“@@”首先标记会话系统变量,如果会话系统变量不存在, 则标记全局系统变量。
#查看指定的系统变量的值
SELECT @@global.变量名;
#查看指定的会话变量的值
SELECT @@session.变量名;
#或者
SELECT @@变量名;
例如
select @@global.max_connections修改变量
#为某个系统变量赋值
#方式1:
SET @@global.变量名=变量值;
#方式2:
SET GLOBAL 变量名=变量值;
#为某个会话变量赋值
#方式1:
SET @@session.变量名=变量值;
#方式2:
SET SESSION 变量名=变量值;
针对当前的mysql服务有效,重启就无效了
用户变量
用户变量是用户自己定义的,作为 MySQL 编码规范,MySQL 中的用户变量以 一个“@” 开头。根据作用 范围不同,又分为 会话用户变量 和 局部变量 。
会话用户变量:作用域和会话变量一样,只对 当前连接 会话有效。
局部变量:只在 BEGIN 和 END 语句块中有效。局部变量只能在 存储过程和函数 中使用
会话用户变量
#方式1:“=”或“:=”
SET @用户变量 = 值;
SET @用户变量 := 值;
#方式2:“:=” 或 INTO关键字
SELECT @用户变量 := 表达式 [FROM 等子句];
SELECT 表达式 INTO @用户变量 [FROM 等子句];set @m1 = 1;
set @m2 :=3;
set @me = @m1+@m2;
select @me
select @count = count(*) from employees
#这个只能用select
select avg(salary) into @avg from employees局部变量
定义:可以使用 DECLARE 语句定义一个局部变量
作用域:仅仅在定义它的 BEGIN ... END 中有效
位置:只能放在 BEGIN ... END 中,而且只能放在第一句
BEGIN
#声明局部变量
DECLARE 变量名1 变量数据类型 [DEFAULT 变量默认值];
DECLARE 变量名2,变量名3,... 变量数据类型 [DEFAULT 变量默认值];
#为局部变量赋值
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句];
#查看局部变量的值
SELECT 变量1,变量2,变量3;
END举例
delimiter //
create procedure test_var()
begin
declare a int default 0;
declare b float;
declare rich_man varchar(25);
select avg(salary) into b from employees;
select last_name into rich_man from employees where salary>= all (
select salary from employees
);
select a,b,rich_man;
end //
DELIMITER ;
call test_var();值得注意的是,这里的赋值只能采用
SET 变量名1 = 值;
SELECT 值 INTO 变量名2 [FROM 子句];而不能采用 select xx = xxxx的形式