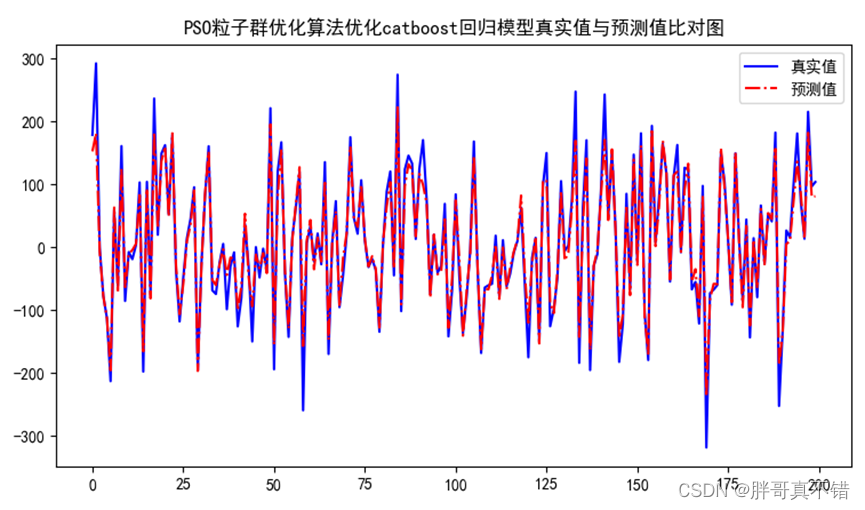
最近有空,把论文中用到的技术和大家分享一下(以组件化的形式),本篇将讲述如何从大量的语料中获取诸多关键词和构建关键词词库或 xx 关键词词库(细分领域)。举例以购物网站的在线评论作为语料库,对其进行分词等操作,最终构建关键词词库(以物流关键词词库为例)和顺便绘制词云图。关键词词库构建完成后,可以做的事情就多了,往后包括权值计算和情感分析,这些都是将关键词作为基础单位的,往前对接 xx 评价指标体系(这些是题外话,可以忽略)。
目录
1 Jieba 分词及词频统计
1.1 自定义词典
1.2 停用词典
1.3 词频统计—初步构建词库
① 语料
② 处理 excel 语料数据
③ 分词及词频统计
④ 初步构建物流关键词词库
2 word2vec 拓展关键词词库
2.1 训练 word2vec 模型
2.2 使用模型—最终构建词库
2.3 Wordcloud 词云图
代码地址:https://gitee.com/yinyuu/nlp_yinyu
1 Jieba 分词及词频统计
jieba 是一种中文分词工具,它可以将中文文本进行分词,将文本中的词语分开,并标注它们的词性。可以通过以下命令进行安装:
pip install jieba
1.1 自定义词典
jieba 进行分词时,绝大部分的词汇都能识别出来,但是对于一些特有名词的识别就比较困难了,比如京东、淘宝、拼多多等等,这些特有词汇与在线评论的语料紧密关联,但是作为特有名词一般不会被记录在 jieba 模型中。
因此需求构建自定义词典,来处理语料中可能出现的特有名词,进而避免过度切分(比如将拼多多切分为拼和多多)。
同时,自定义词典也承担着指导关键词词库的作用,针对购物网站的在线评论,比如构建物流关键词词库,那么就需要补充物流相关特有名词加入自定义词典;比如构建包装关键词词库,那么就需要包装相关特有名词......
📌 词库网站
这里推荐搜狗输入法的词库网站,涵盖了蛮多领域,词库的选择取决于你研究的对象和语料基础。
https://pinyin.sogou.com/dict/cate/index/96

📌 处理 scel 格式文件
下载完某词库后,它是 scel 格式文件,这不符合 jieba 自定义词典的加载格式,因此需要进行处理。
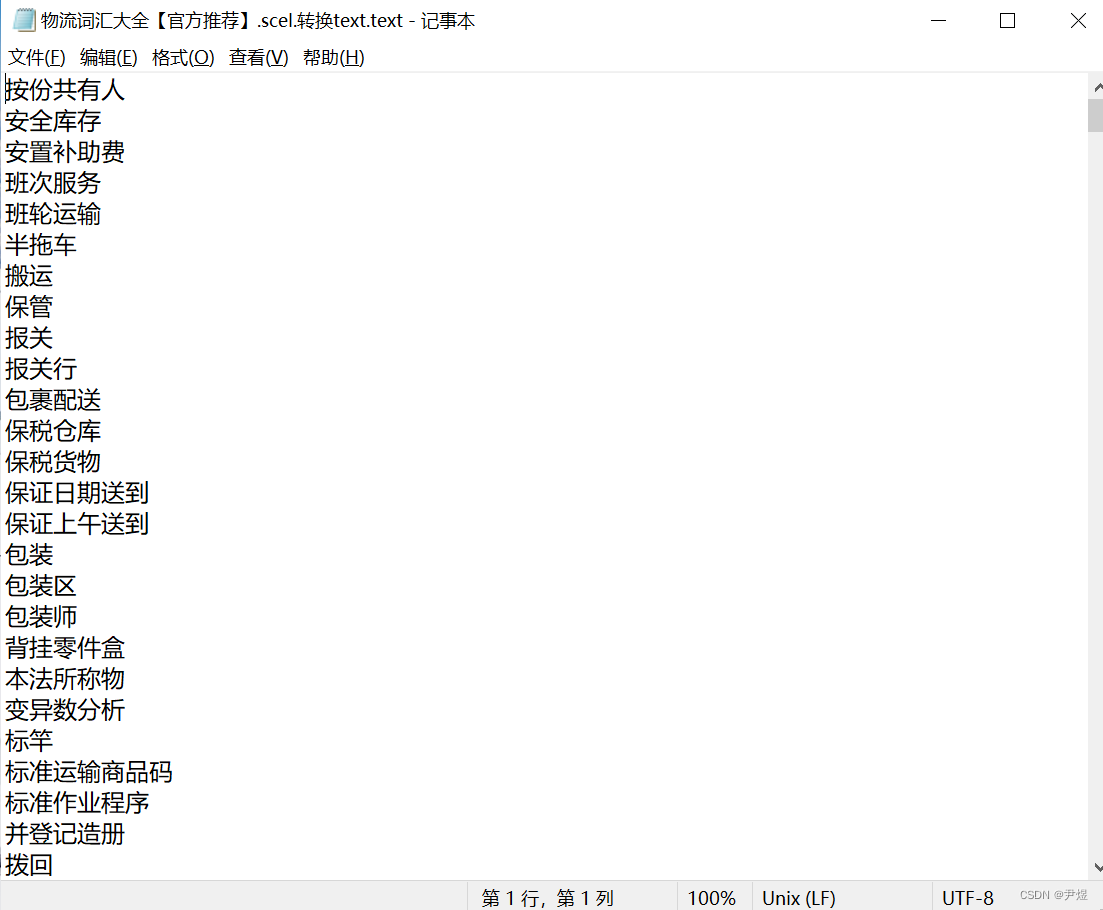
比如物流词汇大全【官方推荐】.scel,大家可以下载深蓝词库工具将其转化为 text 文本(随后可将后缀改为 txt 即可),或者以下在线处理网站:https://www.toolnb.com/tools/scelto.html,这样就更方便了。
处理完后如下:
1.2 停用词典
分词时,其实并没有将数字、符号、虚词等不相关内容做区分,这些词就是停用词,因为这些词对于后面的研究来说意义不大,而且还可能影响文本分析的效率和准确性,因此需要使用停用词典。
之前我整合了百度停用词表+哈工大停用词表+机器智能实验室停用词库等词表,可在项目中自取~
1.3 词频统计—初步构建词库
① 语料
接下来使用 jieba 进行一次简单的词频统计,语料是我之前爬取的京东网站上的 5000 条评论数据,可在文章顶部下载查看,截图如下:

② 处理 excel 语料数据
大家可以看到,目前语料数据还是 excel 格式,这是不满足 jieba 分词的要求的,因此需要对其做进一步的处理,代码如下:
import xlrd
'''
工具类
'''
class BaseHandle(object):
def read_col_merge_file(self, filename):
'''读取合并列表comments列的值输出为txt'''
excel = xlrd.open_workbook(filename) # 打开excel文件
table = excel.sheet_by_index(0) # 根据下标获取工作薄,这里获取第一个
comments_list = table.col_values(1, start_rowx=1) # 获取第一列的内容
comments_str = '\n'.join(comments_list) # 将数组转换成字符串,空行连接,模仿text文本
return comments_str
if __name__ == '__main__':
base = BaseHandle()
comments_str = base.read_col_merge_file('语料库_京东_5000条评论.xlsx')
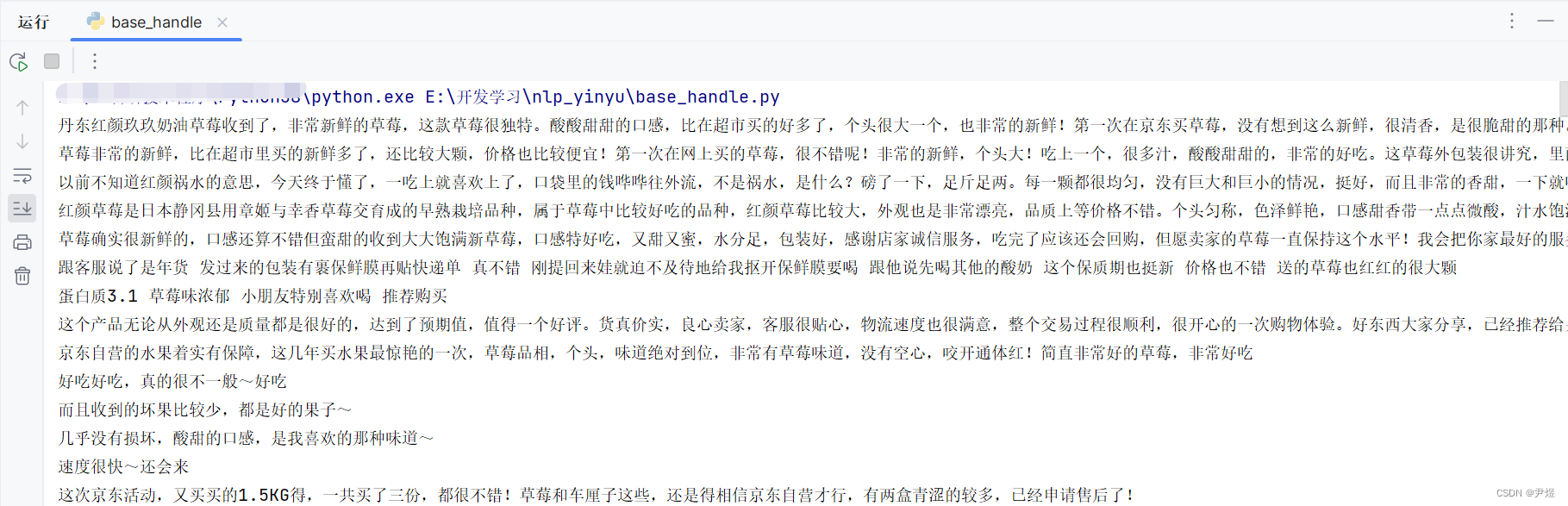
print(comments_str)注意 xlrd 库的版本,需要小于等于 1.2.0,不然无法解析 xlsx 格式文件。同时由于我把文件放在了同目录下,因此 filename 直接使用文件名,不然建议使用绝对路径。
该方法使用后效果如下:
③ 分词及词频统计
因为本文以构建物流关键词词库为例,因此引入物流词汇自定义词典,主要分为以下三步:
- 引入语料 excel 数据
- jieba 分词
- 对分词结果进行统计,最后生成【高频词统计.xlsx】文件
注意,需要安装 openpyxl 这个库,那么 DataFrame 才能生成 excel 文件。
代码如下:
import jieba
import pandas as pd
from base_handle import BaseHandle # 引入工具类
baseHandle = BaseHandle() #实例化
def split_words_jieba(text):
'''jieba分词操作'''
diy_dict = ('物流词汇大全.txt') # 引入自定义词典
jieba.load_userdict(diy_dict) # 加载自定义字典
comment_cut = jieba.lcut(text) # 分词结果
print(comment_cut)
# 引入停用词表,当文本文件中带有英文双引号时,直接用pd.read_csv进行读取会导致行数减少,因此使用quoting=3
stop_dic = ('百度+哈工大+机器智能实验室停用词库.txt')
stopwords = pd.read_csv(stop_dic, names=['w'], header=None, sep='\t', encoding='utf-8', quoting=3)
datas = [] # 去除停用词提取名词
for word in comment_cut:
if word not in list(stopwords.w) and len(word) > 1:
datas.append(word)
# print("分词+停用词成功\n"+str(data))
return datas
def count_fre_words(datas):
'''高频词统计'''
counts = {} # 新建1个字典
for data in datas:
counts[data] = counts.get(data, 0) + 1
# 将字典列表化,并按频次排序
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
dt = pd.DataFrame(items, columns=['keyword', 'fre']) # list 转换为 df
# print(dt)
dt1 = dt[(dt.fre != 1)] # 删去频次为1的关键词
dt1.to_excel('高频词统计.xlsx') # 储存为表格
if __name__ == "__main__":
# 1.引入语料excel数据
text = baseHandle.read_col_merge_file('语料库_京东_5000条评论.xlsx')
# 2.jieba分词
datas = split_words_jieba(text)
# 3.对分词结果进行统计,最后生成【高频词统计.xlsx】文件
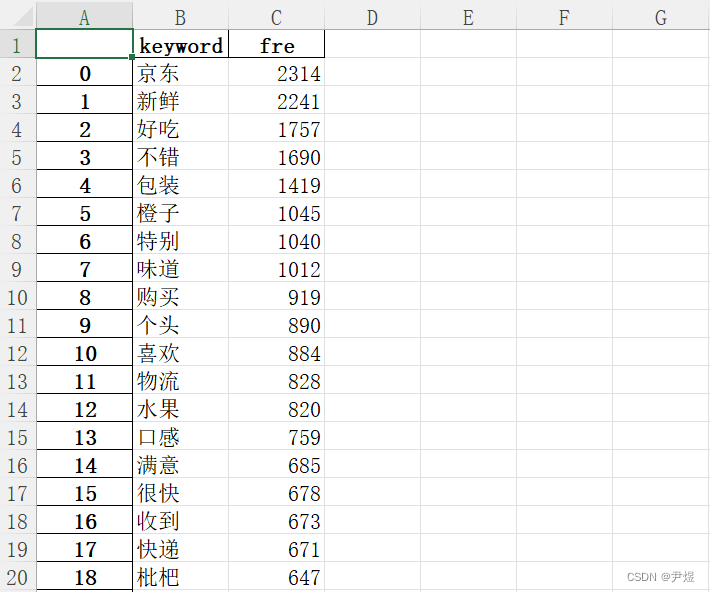
count_fre_words(datas)部分分词结果如下,可以看到语料数据被切分成一个个词汇:

最终输出【高频词统计.xlsx】文件如下:
④ 初步构建物流关键词词库
此时,物流关键词词库已经初具模型了,基于这个高频词统计结果,我们可以将其中联系到物流的关键词筛选出来,作为物流关键词的初步词库。
因为自定义词典已经是【物流词汇大全.txt】了,因此绝大部分物流词汇都将包含在内,这些关键词排名越靠前,那么他在语料中的频次或者说重要性越大。一般来说,取排名靠前的关键词即可,排名越靠后,那么该关键词的影响作用也就越小,对于后边的统计研究意义也不大。
举例来说,我在此取 20 个物流关键词,将其放入工具类中:
class BaseHandle(object):
def __init__(self):
# 物流关键词词库:初步20个
self.logistics_list = ['京东', '新鲜', '包装', '物流', '很快', '快递', '收到','速度', '送货', '推荐',
'小哥', '服务', '发货', '配送', '送到', '到货', '第二天', '冷链', '完好', '送货上门']接下来就是通过 Word2vec 对物流关键词词库进行拓展。
2 word2vec 拓展关键词词库
简单来说,上边的流程已经满足构建基础关键词词库的要求了,不过为了使得研究更加“高级”一些,可以考虑使用 Word2vec 来拓展关键词词库,主要是起到完善关键词词库的作用。
关于 word2vec 的理论知识就暂且不提了,主要是分析词汇间的相关度(相关度越高,两词汇越紧密),以下是如何使用 word2vec 的流程。
Gensim 是 Python 的一个自然语言处理模块,该模块下命名为 word2vec 的模型封装了word2vec 的实现逻辑,可以使用它来进行 word2vec 算法操作:
pip install gensim2.1 训练 word2vec 模型
word2vec 使用第一步是针对语料训练属于该语料数据的模型,特殊的一点在于,它需要针对每条评论/语料的的分词结果进行训练分析,这是因为 word2vec 本质在于分析词汇间的联系,他需要许多独立的分词结果进行解析。
代码如下:
import xlrd
from gensim.models import word2vec
from word_count import split_words_jieba
def wordcut_listinlist(url):
'''读取excel评论并分别对每条评论进行分词操作'''
excel = xlrd.open_workbook(url) # 打开excel文件
table = excel.sheet_by_index(0) # 根据下标获取工作薄,这里获取第一个
comments_list = table.col_values(1, start_rowx=1) # 获取第一列的内容
list = []
for i in comments_list:
a = split_words_jieba(i)
list.append(a)
return list # [['xx','xx]、['X']、['XXX']]
def word2vec_trainmodel(url): # 训练一次就行了
'''Word2vec关键词扩展——训练模型'''
sentennce = wordcut_listinlist(url)
# 1.建立模型
model = word2vec.Word2Vec(sentennce, vector_size=200) # 训练skip-gram模型,默认window=5
# 2.保存模型,以便重用
model.save(u"word2vec_last.model")
if __name__ == "__main__":
word2vec_trainmodel('语料库_京东_5000条评论.xlsx') #5000条评论,运行2分钟随后同目录下会输出命名为 word2vec_last.model 的文件,这表示训练成功:

2.2 使用模型—最终构建词库
然后就是直接使用该模型就行了,入参是某个关键词,输出 10 个与其相近的关键词,可修改 topn 来控制输出相关关键词的个数。
def similar_words(word):
'''计算某个词的相关词列表——前提是已存在训练好的模型'''
model1 = word2vec.Word2Vec.load("word2vec_last.model") # 模型的加载方式
y2 = model1.wv.most_similar(word, topn=10) # 10个最相关的
print("和{}最相关的词有:".format(word))
for item in y2:
print(item[0], '%.3f' % item[1])
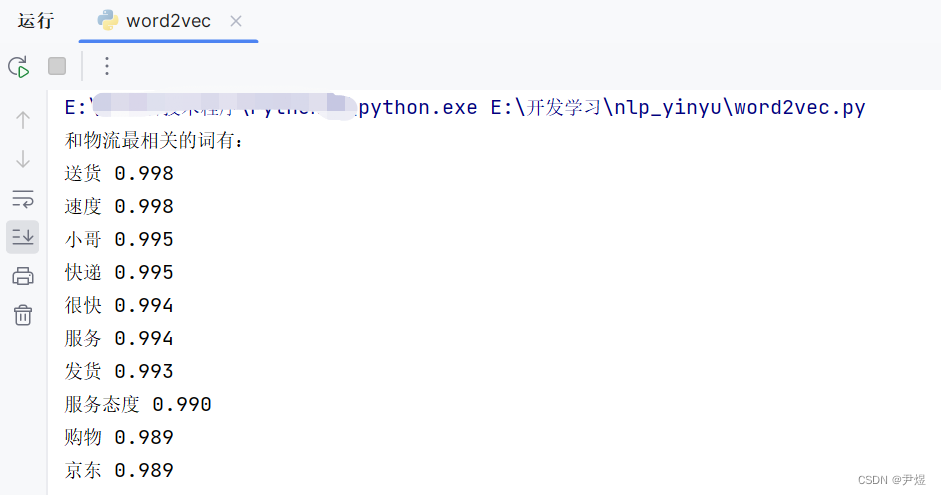
if __name__ == "__main__":
similar_words('物流')比如查询“物流”的在该语料中最相关的关键词:
接下来就可以依据现实情况给关键词词库添加关键词了,这都取决于你。我简单地给之前的物流关键词词库加 10 个关键词:
class BaseHandle(object):
def __init__(self):
# 物流关键词词库:目前30个物流关键词
self.logistics_list = ['京东', '新鲜', '包装', '物流', '很快', '快递', '收到','速度', '送货', '推荐',
'小哥', '服务', '发货', '配送', '送到', '到货', '第二天', '冷链', '完好', '送货上门'
#使用word2vec加的关键词 👇
'运送', '严谨', '保障', '速度快', '效率', '方便快捷', '客服', '省心', '快捷', '严实']当然这只是做个演示,实际研究时很难不上百。
2.3 Wordcloud 词云图
前边我们已经构建完物流关键词词库了,那么为了继续整活,可以给词库里的关键词做个词云图,这不就显得高大上了。
📌 物流关键词词频
虽然前边构建了词库,但是并不知道具体某个关键词的词频是多少,这时之前的【高频词统计.xlsx】就派上用场了。简单来说,就算依据每个物流关键词,遍历【高频词统计.xlsx】,找到属于每个物流关键词的词频,这是做关键词词库词云图的基础。
依旧将他放在工具类里边,代码如下:
import xlrd
import pandas as pd
'''
工具类
'''
class BaseHandle(object):
def __init__(self):
# 物流关键词词库:目前30个物流关键词
self.logistics_list = ['京东', '新鲜', '包装', '物流', '很快', '快递', '收到', '速度', '送货', '推荐',
'小哥', '服务', '发货', '配送', '送到', '到货', '第二天', '冷链', '完好', '送货上门'
# 使用word2vec加的关键词 👇
'运送', '严谨',
'保障', '速度快', '效率', '方便快捷', '客服', '省心', '快捷', '严实']
def words_fre_match(self, filename, lis):
'''关键词批量匹配词频'''
df = pd.read_excel(filename)#'高频词统计.xlsx'
b1 = []
b2 = []
for i in range(len(df)):
keyword = df.loc[i, 'keyword']
if any(word if word == keyword else False for word in lis): # 判断列表(list)内一个或多个元素是否与关键词相同
a1 = df.loc[i, 'keyword']
a2 = df.loc[i, 'fre']
b1.append(a1)
b2.append(a2)
else:
continue
f1 = pd.DataFrame(columns=['关键词', '词频'])
f1['关键词'] = b1
f1['词频'] = b2
f1.to_excel('物流关键词词频匹配表.xlsx')
if __name__ == '__main__':
base = BaseHandle()
base.words_fre_match('高频词统计.xlsx', base.logistics_list)
pass输出文件内容如下:
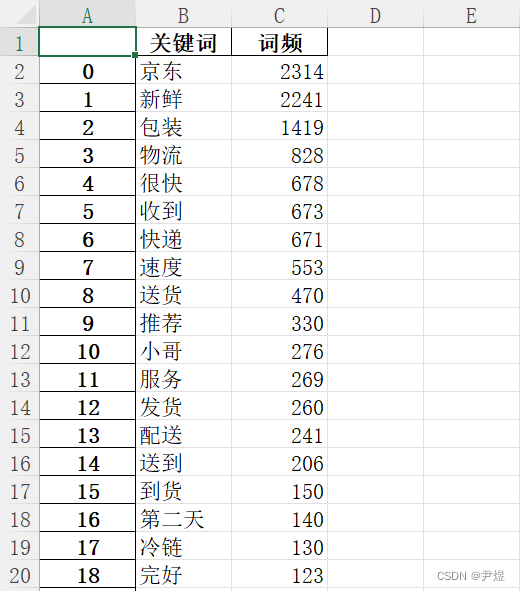
📌 词云图
接下来就可以使用这个匹配表来绘制词云图了富裕的同学可以使用在线网站来进行制作,毕竟要比代码制作美观方便多了,比如:https://design.weiciyun.com/。
以下以 wordcloud 库绘制词云图为例,由于 wordcloud 库依赖 numpy 库和 PIL 库的,因此需要提前安装好这两个库。词云图有两种做法:
- 针对文本,先 jieba 分词,然后进行绘制
- 根据已知的词频进行绘制
那我们正是使用第二种方式,读取【物流关键词词频匹配表.xlsx】文件如下:
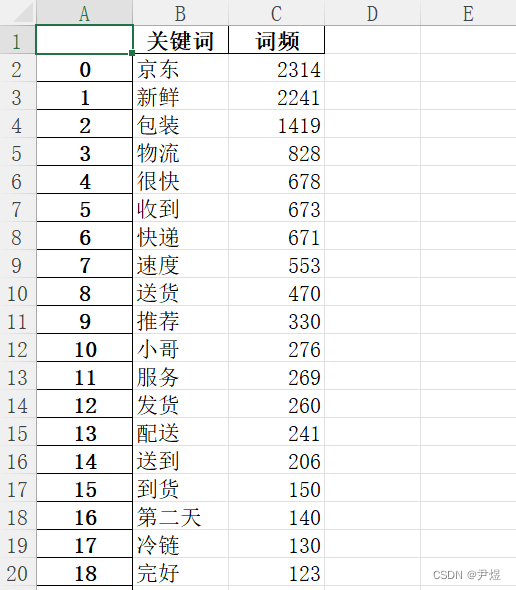
把该方法放在工具类中,以下是简单绘制的代码:
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
class BaseHandle(object):
def wordcloud_by_wordcount(self, filename):
'''根据词汇及对应词频绘制词云图'''
data = pd.read_excel(filename, sheet_name='Sheet1') # 获得数据
data_gr = data.groupby(by='关键词', as_index=False).agg({'词频': int}) # 拿数据
dic = dict(zip(data_gr['关键词'], data_gr['词频'])) # 转化为字典形式
# print(dic)
# fit_word函数,接受字典类型,其他类型会报错
wordcloud = WordCloud(font_path='simhei.ttf', background_color="white", width=4000, height=2000,
margin=10).fit_words(dic)
plt.imshow(wordcloud)
plt.axis("off") # 取消坐标轴
plt.show() # 显示
if __name__ == '__main__':
base = BaseHandle()
base.wordcloud_by_wordcount('物流关键词词频匹配表.xlsx')
pass生成词云图如下:

如果大家想制作更加精美的词云图,可继续深入研究~