目录
Elasticsearch常用操作_域的属性
分词器_默认分词器
分词器_IK分词器
分词器_拼音分词器
分词器_自定义分词器
Elasticsearch搜索文档_准备工作
Elasticsearch搜索文档_搜索方式
Elasticsearch常用操作_域的属性
index
该域是否创建索引。只有值设置为true,才能根据该域的关键词查询文档。
// 根据关键词查询文档
GET /索引名/_search
{
"query":{
"term":{
搜索字段: 关键字
}
}
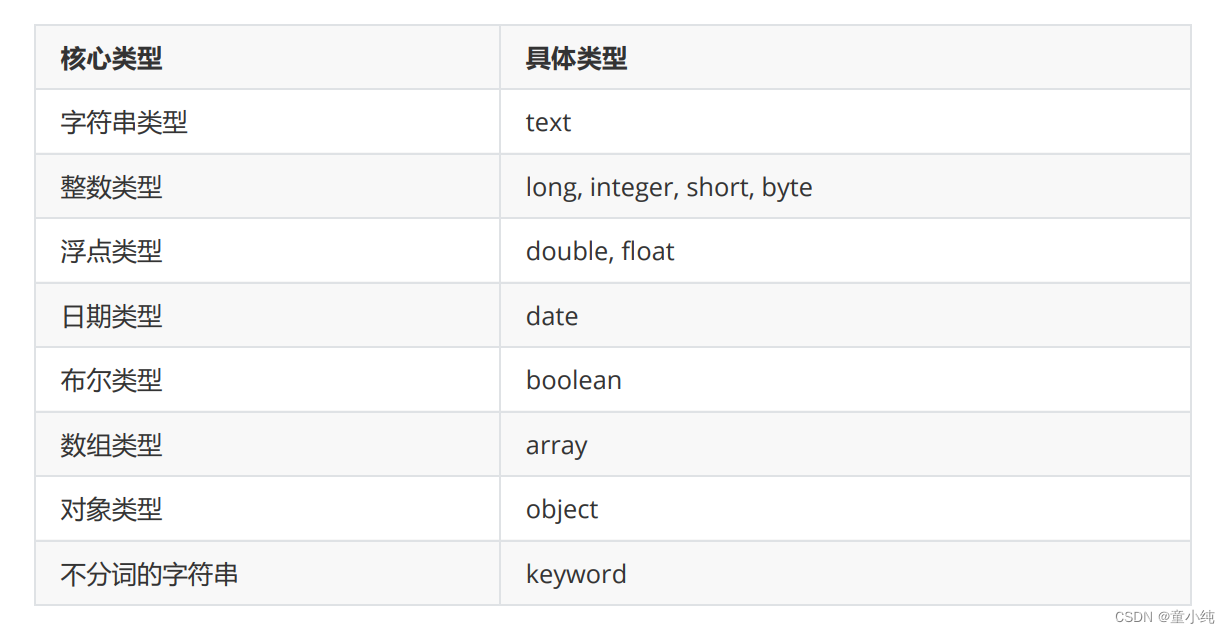
}type
域的类型
store
是否单独存储。如果设置为true,则该域能够单独查询。
// 单独查询某个域:
GET /索引名/_search
{
"stored_fields": ["域名"]
}
实时学习反馈
1. 在Elasticsearch中,只有域的属性设置为true,才能根据该域 的关键词查询文档
A type
B index
C store
D analyzer
2. 在Elasticsearch中,域的属性表示域的数据类型
A type
B index
C store
D analyzer
分词器_默认分词器

ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文 档对应,这样就可以通过关键词查询文档。要想正确的分词,需要 选择合适的分词器。
standard analyzer:Elasticsearch默认分词器,根据空格和标点 符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
查看分词效果
GET /_analyze
{
"text":测试语句,
"analyzer":分词器
}实时学习反馈
1. 在Elasticsearch中,默认分词器为
A standard analyzer
B IKAnalyzer
C pinyin analysis
D 没有默认分词器
2. 在Elasticsearch中,默认分词器对中文的分词
A 根据标点符号分词
B 根据空格符号分词
C 根据词汇分词
D 一字一词
分词器_IK分词器

IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词 工具包。提供了两种分词算法:
1、ik_smart:最少切分
2、ik_max_word:最细粒度划分
安装IK分词器
1、关闭es服务
2 、使用rz命令将ik分词器上传至虚拟机
注:ik分词器的版本要和es版本保持一致。
3、解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis -ik
4、启动ES服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch -d测试分词器效果
GET /_analyze
{
"text":"测试语句",
"analyzer":"ik_smart/ik_max_word"
}
IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。
1、main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
2、IKAnalyzer.cfg.xml:用于配置自定义词库。
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopwords.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>实时学习反馈
1. IK分词器的算法分为
A ik_smart 和 ik_min_word
B ik_min_word 和 ik_max_word
C ik_smart 和 ik_max_word
D ik_smart 和 ik_max_word 和 ik_min_word
2. 在Elasticsearch中,测试分词器效果的方法为
A PUT /_analyze
B GET /_analyze
C POST /_analyze
D DELETE /_analyze
分词器_拼音分词器
拼音分词器可以将中文分成对应的全拼,全拼首字母等。
安装拼音分词器
1、 关闭es服务
2 、使用rz命令将拼音分词器上传至虚拟机
注:拼音分词器的版本要和es版本保持一致。
3、解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis -pinyin
4、启动ES服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch
测试分词效果
GET /_analyze
{
"text":测试语句,
"analyzer":pinyin
}实时学习反馈
1. 在Elasticsearch中,分词器存放的目录为
A bin
B config
C plugins
D log
分词器_自定义分词器

真实开发中我们往往需要对一段内容既进行文字分词,又进行拼音 分词,此时我们需要自定义ik+pinyin分词器。
创建自定义分词器
1、在创建索引时自定义分词器
PUT /索引名
{
"settings" : {
"analysis" : {
"analyzer" : {
"ik_pinyin" : { //自定义分词器名
"tokenizer":"ik_max_word", // 基本分词器
"filter":"pinyin_filter"// 配置分词器过滤
}
},
"filter" : { // 分词器过滤时配置另一个分词器,相当于同时使用两个分词器
"pinyin_filter" : {
"type" : "pinyin", // 另一个分词器
// 拼音分词器的配置
"keep_separate_first_letter" : false, // 是否分词每个字的首字母
"keep_full_pinyin" :true, // 是否分词全拼
"keep_original" : true,// 是否保留原始输入
"remove_duplicated_term": true // 是否删除重复项
}
}
}
},
"mappings":{
"properties":{
"域名1":{
"type":域的类型,
"store":是否单独存储,
"index":是否创建索引,
"analyzer":分词器
},
"域名2":{
...
}
}
}
}
测试自定义分词器
GET /索引/_analyze
{
"text": "你好童小纯",
"analyzer": "ik_pinyin"
}
实时学习反馈
1. 在Elasticsearch中,如果既进行中文分词,又进行拼音分词, 我们可以使用
A 默认分词器
B 拼音分词器
C IK分词器
D 自定义分词器
Elasticsearch搜索文档_准备工作

Elasticsearch提供了全面的文档搜索方式,在学习前我们添加一些文档数据
PUT /students
{
"mappings":{
"properties":{
"id": {
"type": "integer",
"index": true
},
"name": {
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_smart"
},
"info": {
"type": "text",
"store": true,
"index": true,
"analyzer": "ik_smart"
}
}
}
}
POST /students/_doc/
{
"id":1,
"name":"童小纯",
"info":"I love 童"
}
POST /students/_doc/
{
"id":2,
"name":"美羊羊",
"info":"美羊羊是羊村最漂亮的人"
}
POST /students/_doc/
{
"id":3,
"name":"懒羊羊",
"info":"懒羊羊的成绩不是很好"
}
POST /students/_doc/
{
"id":4,
"name":"小灰灰",
"info":"小灰灰的年纪比较小"
}
POST /students/_doc/
{
"id":5,
"name":"沸羊羊",
"info":"沸羊羊喜欢美羊羊"
}
POST /students/_doc/
{
"id":6,
"name":"灰太狼",
"info":"灰太狼是小灰灰的父亲,每次都会说我一定会回来的"
}1、文档搜索
GET /索引/_search
{
"query":{
搜索方式:搜索参数
}
}实时学习反馈
1. 在Elasticsearch中,文档搜索的请求路径为
A /索引/_mget
B /索引/_get
C /索引/_search
D /索引/_doc/id值
Elasticsearch搜索文档_搜索方式

1、match_all:查询所有文档
{
"query":{
"match_all":{}
}
}2、match:全文检索。将查询条件分词后再进行搜索。
{
"query":{
"match":{
搜索字段:搜索条件
}
}
}注:在搜索时关键词有可能会输入错误,ES搜索提供了自动 纠错功能,即ES的模糊查询。使用match方式可以实现模糊 查询。模糊查询对中文的支持效果一般,我们使用英文数据 测试模糊查询。
{
"query": {
"match": {
"域名": {
"query": 搜索条件,
"fuzziness": 最多错误字符数,不能超过2
}
}
}
}实时学习反馈
1. 在Elasticsearch中,查询所有文档的搜索方式为
A match_all
B match
C match_phrase
D range
2. 在Elasticsearch中,自动纠错功能最多纠正的字符数为
A 1
B 2
C 3
D 4
2、range:范围搜索。对数字类型的字段进行范围搜索
{
"query":{
"range":{
搜索字段:{
"gte":最小值,
"lte":最大值
}
}
}
}
gt/lt:大于/小于
gte/lte:大于等于/小于等于3、match_phrase:短语检索。搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配。
{
"query":{
"match_phrase":{
搜索字段:搜索条件
}
}
}4、term/terms:单词/词组搜索。搜索条件不做任何分词解析,在搜索字段对应的倒排索引中精确匹配
{
"query":{
"term":{
搜索字段: 搜索条件
}
}
}
{
"query":{
"terms":{
搜索字段: [搜索条件1,搜索条件2]
}
}
}实时学习反馈
1. 在Elasticsearch中,范围搜索的搜索方式为
A match_all
B match
C match_phrase
D range
2. 在Elasticsearch中,词组检索的搜索方式为
A match_all
B match
C terms
D range