👑作者主页:@安 度 因
🏠学习社区:StackFrame
📖专栏链接:C++修炼之路
文章目录
- 一、string 为何使用模板
- 二、string 类认识
- 1、构造/析构/赋值运算符重载
- 2、容量操作
- 3、增删查改
- 4、遍历
- 5、迭代器
- 6、非成员函数
- 7、库函数※
- 三、测试扩容
- 四、写时拷贝
- 五、win 下 string 的内存分布
如果无聊的话,就来逛逛 我的博客栈 吧! 🌹
一、string 为何使用模板

string 是 typedef 后的模板,也就相当于是这样:
template<class T>
class basic_string
{
private:
T* _str;
// ...
};
// typedef basic_string<char> string;
int main()
{
string s("hello");
return 0;
}
那 string 不就是字符串,管理字符不就是 char ,为什么使用模板?因为编码问题。
计算机是 usa 发明的,一开始对于计算机只需要显示英文就可以,编码简单,因为表示简单;通过计算机编码,将数据翻译为二进制序列,将其组合,一个字节表示一个 char ,将英文和符号进行一个映射,通过建立映射关系(编码表)完成编码。例如 ascii编码表 – 表示英文。
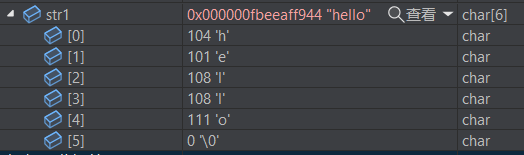
字符根据 ascii 码表中的 ascii 值,以二进制存储在计算机内的就是对应的数值,根据这些,就可以表示出英文。
例如 “helllo” 存储在内存中就是每个字符的 ascii 表对应的数组:
早期计算机只有欧美在用,只有英文的编码方式,但是后来对于世界别国也需要用了,需要让电脑编码能适用于全球,所以后来就诞生了: u n i c o d e unicode unicode ,为了表示全世界文字的编码表(unicode 包含 ascii),它支持各种问题的编码,比如 unicode 就兼容 utf-8, utf-16, utf-32 .
所有的编码通过值与符号建立映射关系,对与英文比较简单,但是对于类似于中文的编码就比较困难。原先一字节存储一个英文字符,但是对于中文可能存不下;所以对于中文字符,可以存储为 2 个字节,这样子 256 * 256 就可以表示 65536 个汉字。但是如果想要扩展更多的话,对于空间的消耗就大了,所以 uft-8 就把常见的汉字用两个字节编,生僻的用若干个字节进行编(Linux 下默认编码就是 uft-8)。
比如:
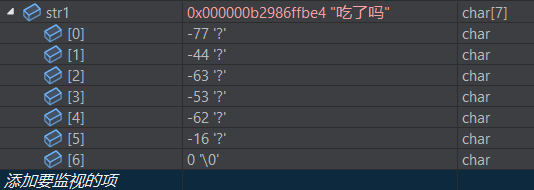
两个字节存储一个中文字符,根据编码表查阅字符。
编译器中也可以更改编码方式:

如果编码对应不上就是所谓的乱码。
中文自己量身定做的编码表 gbk ,windows 下默认 gbk ,linux 下 utf-8,例如 GB2312 就是 gbk .
根据这种方式,也可以让一些不良用语,根据词库,隐藏为 **** .但是仍然可以使用同音字,比如如下现象:

有时候,这种也可以吟唱国粹。由于这些同音字都是挨着的,所以也可以选中国粹中重音的字根据范围屏蔽。
多种编码:

有些字符串会用两个字符表示一个值,例如 wchar_t 宽字节:

就是 wstring . 另外两个也都是为了更好的表示编码。
而 string 就是 basic_string 的一个实例,用来存储 char 字符,我们日常使用 string 即可,特殊情况要灵活使用。
二、string 类认识
认识:
字符串是表示字符序列的类
标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
string类是使用char(即作为它的字符类型,使用它的默认char_traits和分配器类型(关于模板的更多信息,请参阅basic_string)。
string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用char_traits和allocator作为basic_string的默认参数(根于更多的模板信息请参考basic_string)。
注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作。
总结:
string是表示字符串的字符串类
该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator>string;
不能操作多字节或者变长字符的序列。
在使用string类时,必须包含 #include 头文件以及 using namespace std; ,string 在 std 命名空间。
1、构造/析构/赋值运算符重载
七个构造函数:

1(s1),2(s2),4(s3)常用 :
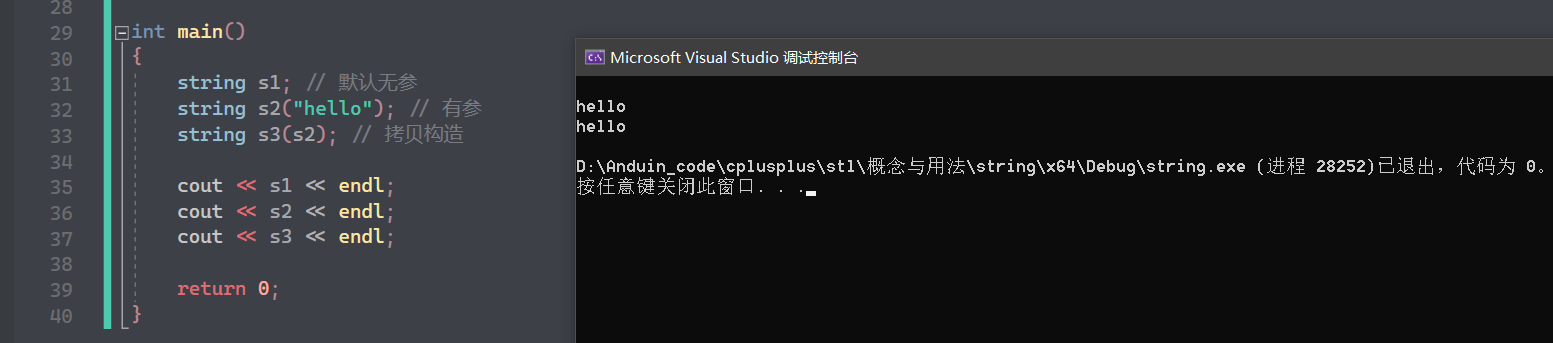
由于 string 重载了 >> 与 << 所以可以直接进行输入输出。
(3):从 pos 位置开始,截取 len 长度,初始化 string ,len 有缺省值 nops 为 -1 ,为静态成员变量。len 类型为 size_t ,转换为一个很大的数字,即截取整个字符串。同理,当 len 长度超过 string 本身长度时,都会截取从 pos 位置开始的整个字符串。
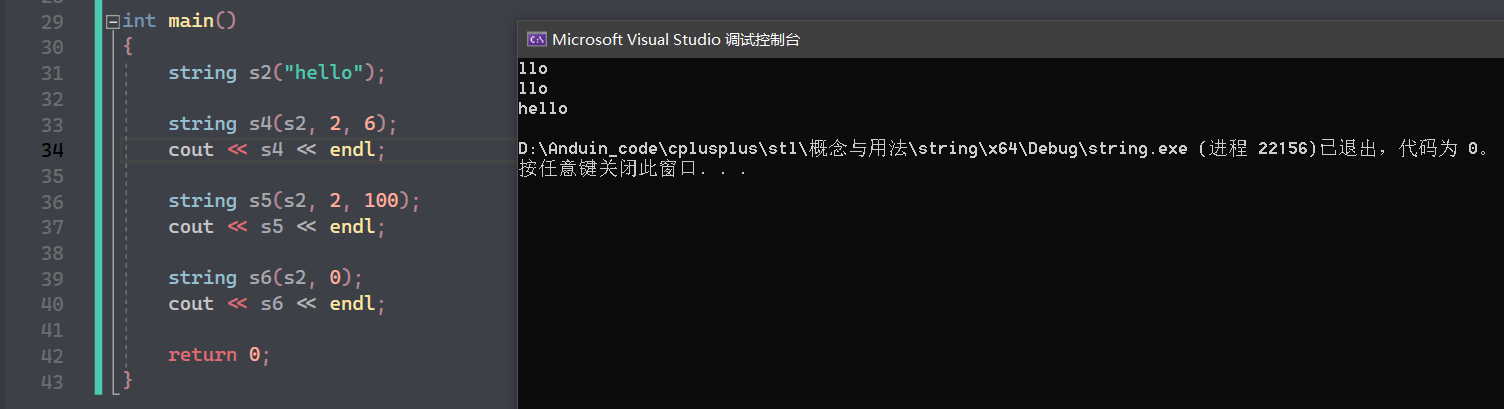
(5):取字符串的前 n 个字符初始化

(6):用 c 来填充 n 个字符

析构函数:
不用管,自动释放:
赋值运算符重载
2、容量操作

1)size/length :计算 string 长度
length 先出现,后来出现的 size ,因为 size 比较适用,因为 length 不符合其他 ds 的大小说明,推荐使用 size .
int main()
{
string s1;
cin >> s1;
cout << s1.size() << endl;
cout << s1.length() << endl;
return 0;
}
2)max_size:string 的最大长度,没有被界定,根据多种情况衡量
cout << s.max_size() << endl; // 2147483647
我的电脑是这么多。
3)capacity:算此刻容量
int main()
{
string s1;
cout << s1.capacity() << endl; // 15
return 0;
}
实际上是 16 ,但是有一个给了 ‘\0’ ,为实际能存储的字符个数。
4)clear:清理数据,不清理空间;清理数据后,可以用 capacity ,检查空间是否被清理

5)empty:判断是否为空,空返回1,非空返回0
关于容量的增长 :
除第一次二倍增长,其他均约呈 1.5 倍正常:

起始空间是放到一个对象的数组(16大小,包含 \0 ,15是有效字符)中,数组满了,对象中就不存在这个数组,在堆上开了一个32容量的空间,之后呈 1,5 倍增长(PJ版本);而 linux 上的是呈二倍增长的(SGI版本)。

一句话,版本不同,时代更新。虽然功能一样,但是每个版本的底层可能都不一样,因为不同版本的源码都在更新。
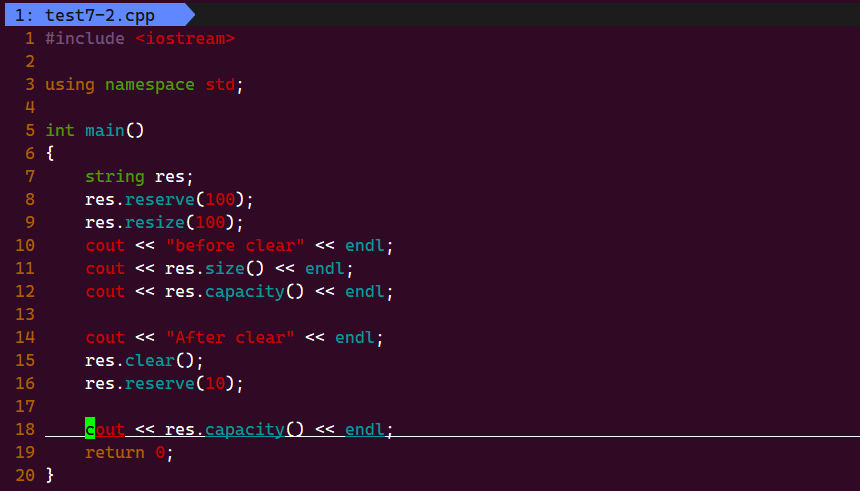
6)reserve :不是 reverse 逆置。reserve 是请求容量的改变,传递参数,来改变容量
频繁扩容有消耗,所以一次性把空间开大,就可以减少增容时的消耗:

但是申请的元素会根据上面说的对齐方式,比如这边申请 1000 个,他会申请1008个,一个给 \0 ,可用 1007 个。
7)reszie:开辟空间并改变数据个数。可以给值对空间进行初始化,不给默认为 \0


reserve/resize 不会对已有的数据进行修改,是扩容/扩容+初始化,不是覆盖:
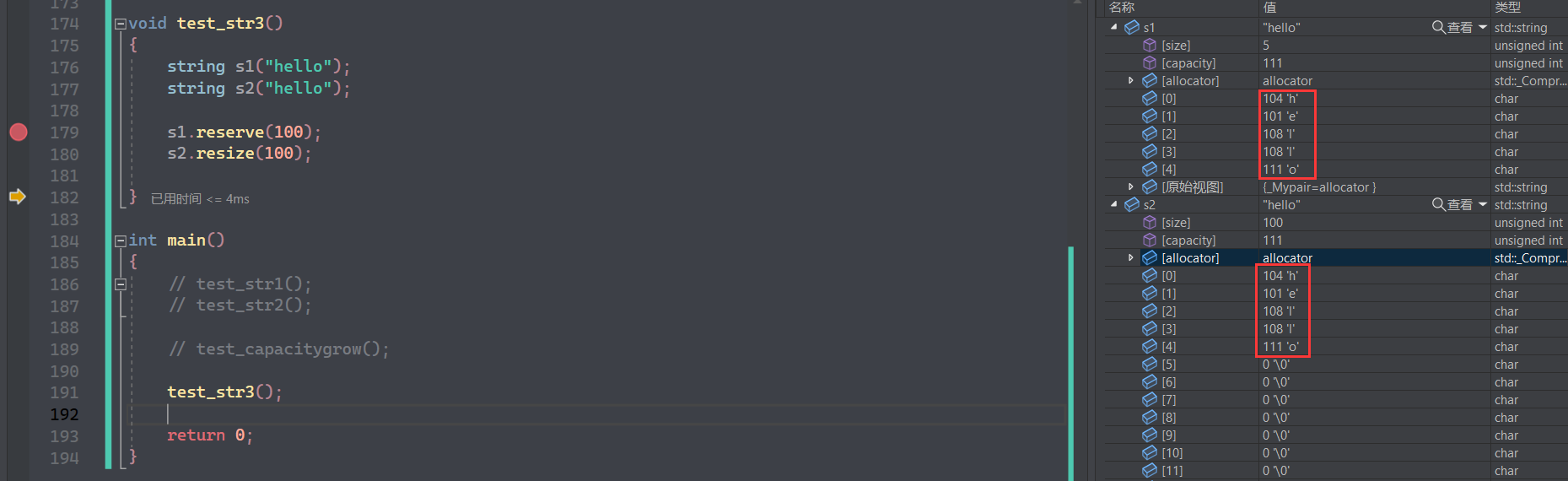
如果 resize 给的空间比初始容量小,则会保留初始数据,后面的被删除:
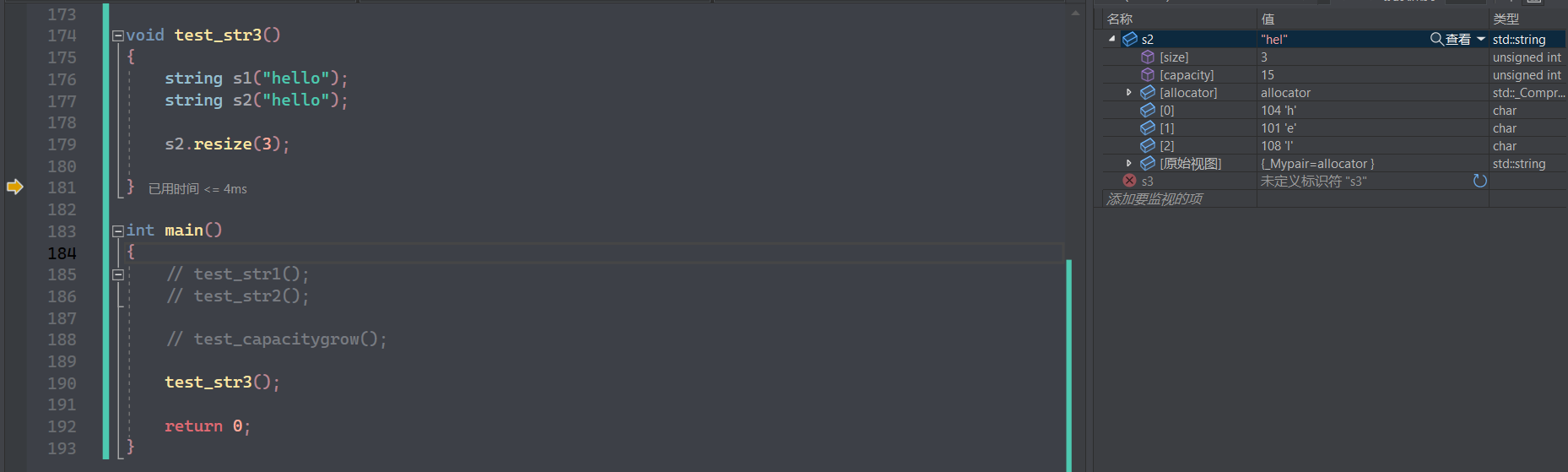
对于 reserve 给的大小比已有容量小时,则不会改变容量大小:
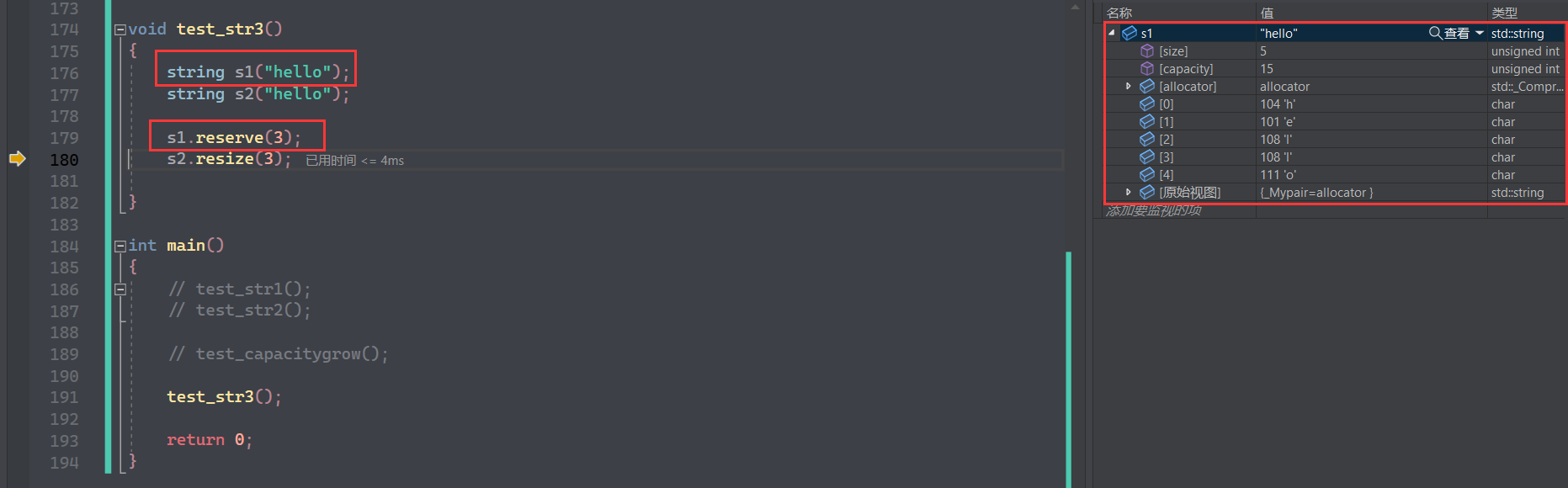
但是如果空间中的数据被清空,则可以减容,由此可见不可约束力:
杭哥说是:数据没有清空,所以仍然可能增容减容,所以并不会缩减容量,但是数据清空就没问题了,就认为不需要空间,就可以减容:

6、7总结:
- reserve :开空间,影响容量
- resize:开空间,改变数据个数 size ,对这些空间给一个初始值并初始化,不给值默认给 \0
3、增删查改

改:
operator[] :可以像数组一样访问
s1[i] <==> s1.operator[](i)
可以 s1[i] 修改 string 的内容,operator[] 类似:
char& operator[] (size_t pos)
{
return _str[pos];
}
这里的引用返回不是为了减少拷贝(char 空间小),而是为了支持修改返回对象。
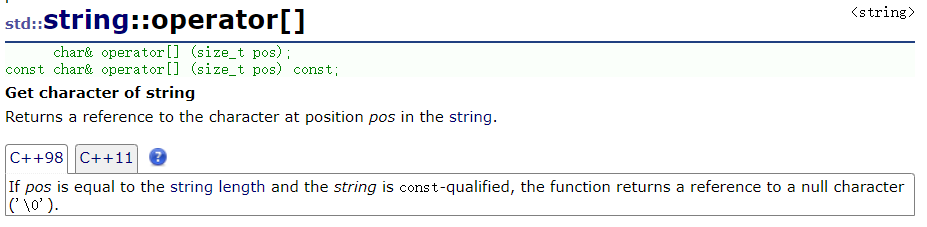
at 和 operator[] 一样,以函数形式使用:
s1.at(i) -= 1; // 例如
它们检查越界的方式不一样,operator[] :使用断言;at:抛异常:
operator[] :s1[100]

at:s1.at(100)
增:
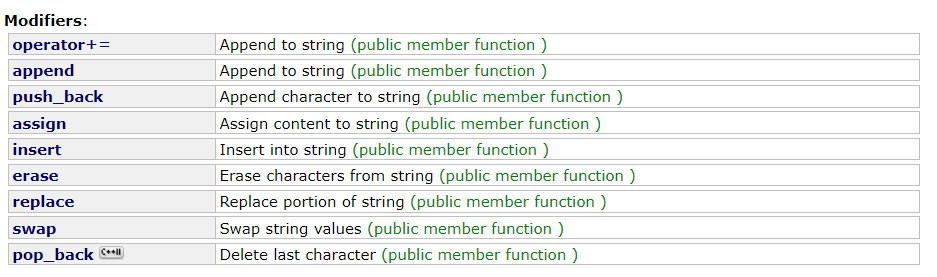
push_back:尾插一个字符;append:尾插一个字符串

operator+= 也可以起到插入的效果,字符和字符串都可以,推荐使用:

insert:插入 string ,可以再任意位置插入,但是效率不高,一般是 O ( N ) O(N) O(N)
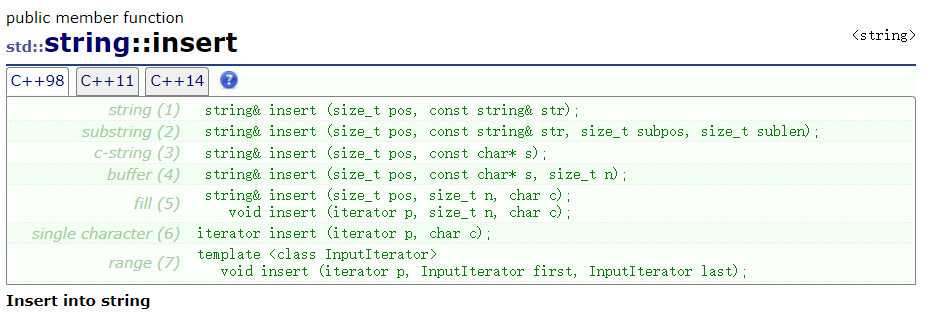
(5):
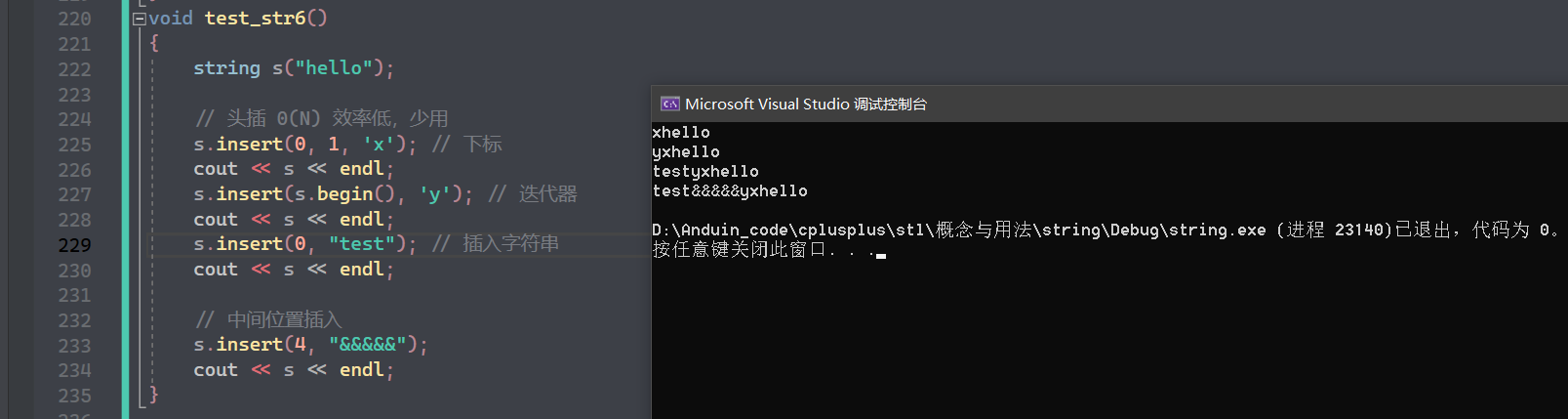
查:
c_str:c_str 返回的是 string 的首元素地址


与 c 库中函数或文件操作时配合使用 c_str :
int main()
{
string file("test.txt");
FILE* out = fopen(file.c_str(), "w"); // 第一个参数为 char*
}
find:在 string 中查找内容(看文档)


(2):找c字符串,返回第一个找到的位置下标;找不到返回 npos ,是无符号的 -1 ,是一个极大的值;当数字很大时,就认定这个位置不存在,因为 stirng 过大,也不实际了
substr:从 pos 位置开始,取 len 个字符,len 缺省值为 npos ,如果不给 len ,默认截取从 pos 位置开始的所有字符串
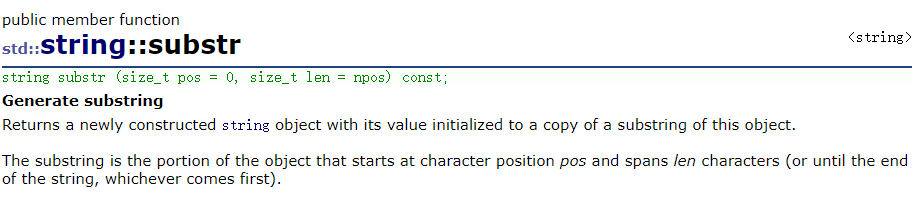
find 和 substr 组合使用:

pos 找到 . 开始的位置,从 . 位置开始截取后面的所有元素。pos 返回的是下标,总长 - 下标 = . 之后的长度;;如果想要直接截到结尾,可以 substr(pos) 一步到位。
如果连续后缀,要取最后一个?可以使用 rfind ,反向取:

第三个 find 使用 :
删 :
erase,三种重载:
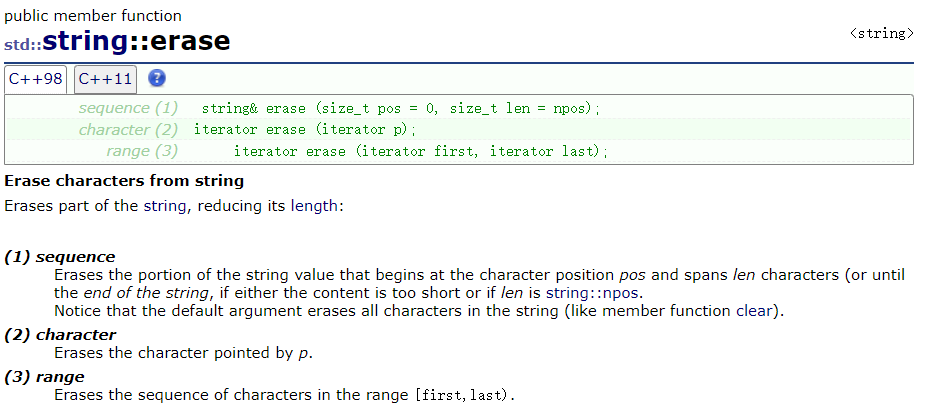
第一个比较常用:从 pos 位置开始删除 len 个字符,如果不给 len ,则默认从该位置删完
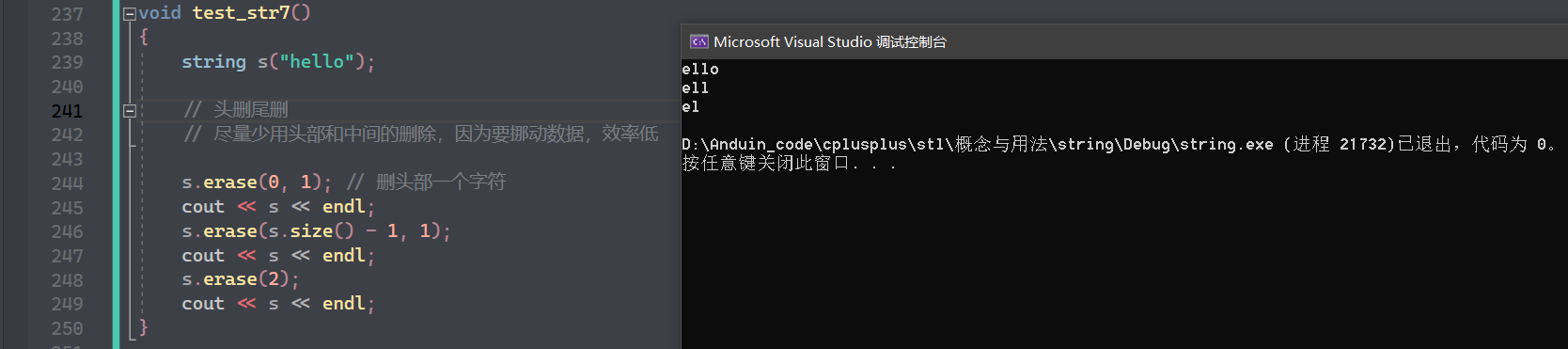
pop_back 是尾删,就不演示了,很简单。
4、遍历
三种遍历和修改的方法:
1)operator[] :
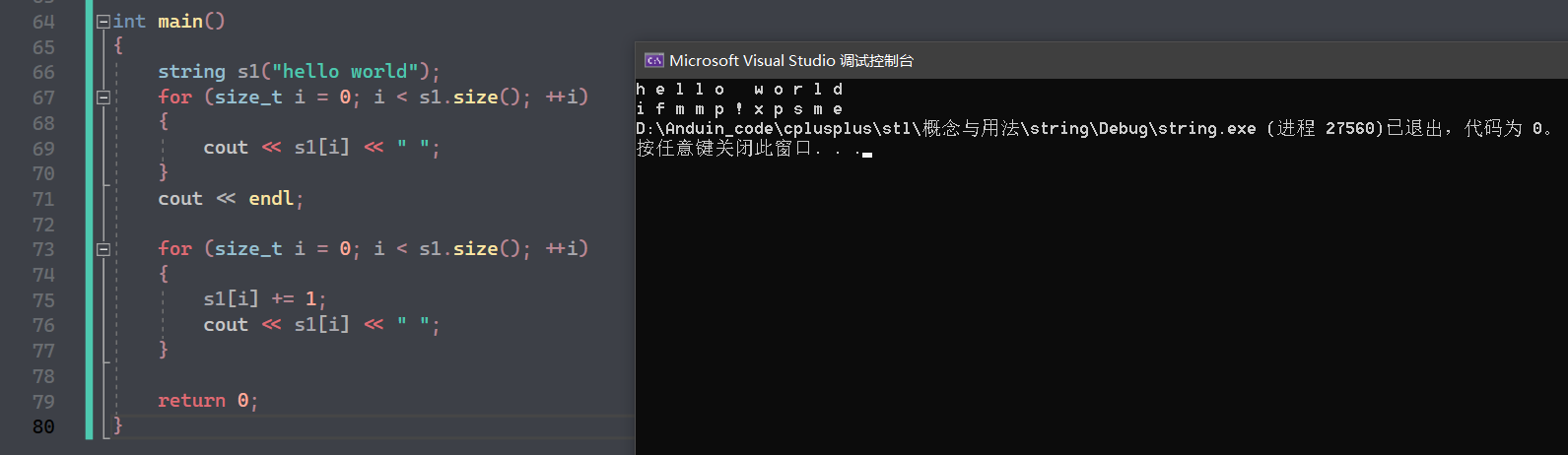
void test_str1()
{
string s1("hello");
for (size_t i = 0; i < s1.size(); i++)
{
s1[i] += 1;
}
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i] << ' ';
}
}
2)迭代器 :
void test_str1()
{
string s1("hello");
string::iterator it = s1.begin();
while (it != s1.end())
{
*it += 1; // 修改
cout << *it << ' ';
++it;
}
cout << endl;
}
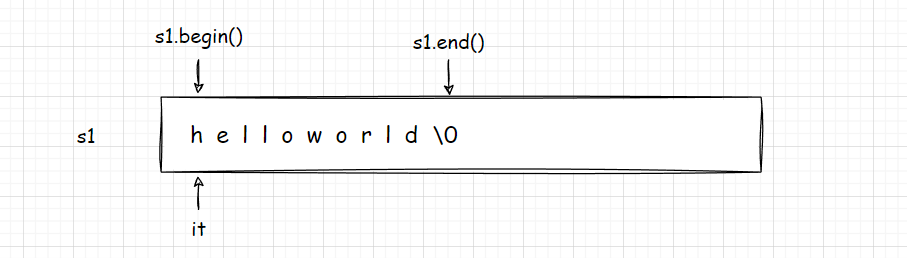
当前理解为 it 就是 h 位置的指针,s1.begin() 返回第一个位置 h 的地址;s1.end() 返回最后一个位置下一个位置的地址 \0 . 迭代器是内嵌类型,是在 类中定义的,类型名称就是 iterator ,全局没有这个迭代器,所以要指定类域。
对于 string 来说,while(it < s1.end()) 也可以进行遍历,因为 string 是连续的;但是推荐用 != ,因为其他容器的迭代器可能不支持。
这里我们先用,把迭代器想象成:像指针一样的类型 ,之后模拟实现时,慢慢理解清楚。
3)范围 for(C++11)
void test_str1()
{
string s1("hello");
for (auto& e : s1) // 加引用修改
{
e += 1;
cout << e << ' ';
}
}
自动取出元素,作为别名,往后迭代,自动判断结束。(底层类似被替换为迭代器遍历)
5、迭代器

正向迭代器 begin 和 end 我们已经说过使用方式,下面讲解别的。
rbegin/rend 是反向迭代器 :
void test_str2()
{
string s1("hello world");
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
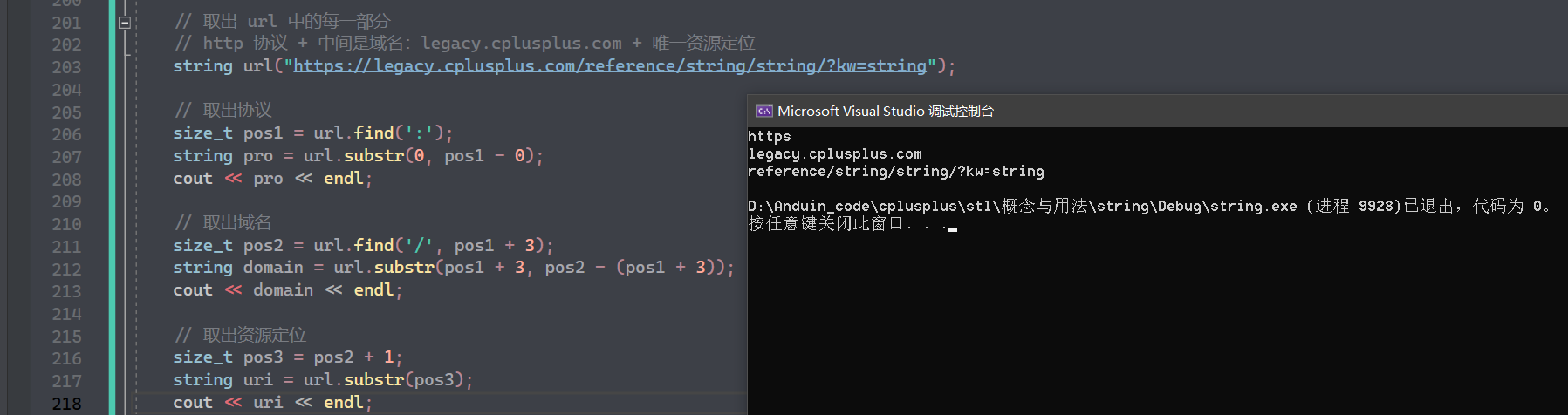
{
*rit += 1;
cout << *rit << ' ';
++rit;
}
}

类似于:
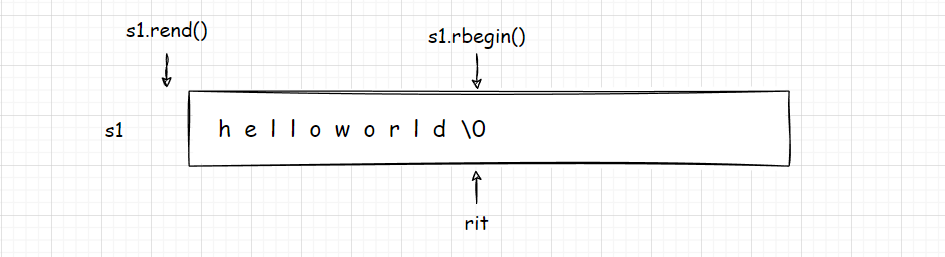
++rit 是往左边走的,与正向迭代器相反。
const 的正向迭代器 :

给 const 对象用的,const 对象调用 const 的迭代器,可读但不可写 :

对于普通的 string 对象,也可以使用 const 迭代器,权限缩小是可以的:

同理,对于 const 的反向迭代器也是一样的。
C++11 中有 cbegin,cend等专门区分 const 的迭代器:
因为当用 auto 进行类型推导时,比如这样:
void foo(const string& s)
{
auto it = s.begin();
}
这里 it 是 auto 推导的,是不是 const 迭代器需要根据参数才能看出,所以后来规定 const 迭代器可以使用 cbegin 等,但是一般不常用。
迭代器遍历的意义是什么?对于 string ,无论是正着遍历还是倒着遍历,下标 + [] 都足够好用,为什么还要迭代器?
迭代器是适用于所有容器的,都可以通过迭代器访问。
对于 string ,下标和 [] 就足够好用,确实可以不用迭代器,但是如果是其他容器(数据结构),其他容器就不支持,比如 list ,map 等,它们都是不支持下标遍历的。
迭代器是用统一的方式支持遍历的。
结论:对于 string ,得会用迭代器,一般用下标。
6、非成员函数

getline :
cin 在遇到空白字符时,会停止读取,其他数据留在缓冲器;getline 可以读取带空格的一行 string :
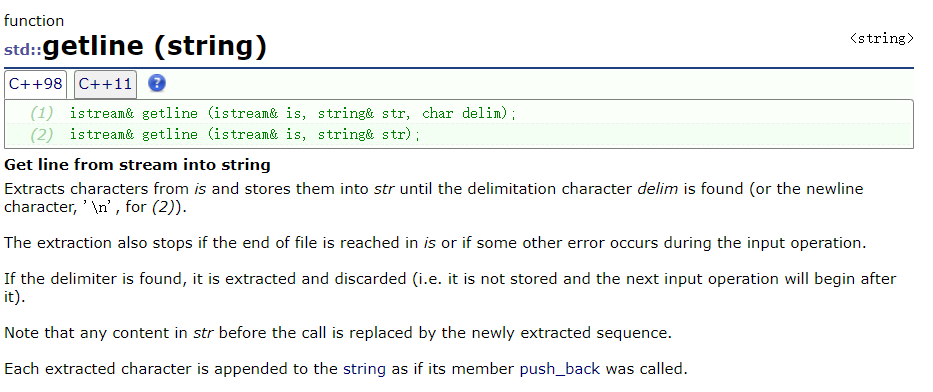
第一个参数是 istream ,即 cin .
原理类似于:
int main()
{
string s1;
char ch = cin.get();
while (ch != '\n')
{
s1 += ch;
ch = cin.get(); // cin 的成员函数,一个字符一个字符拿
}
cout << s1 << endl;
return 0;
}
一个字符一个字符读取。

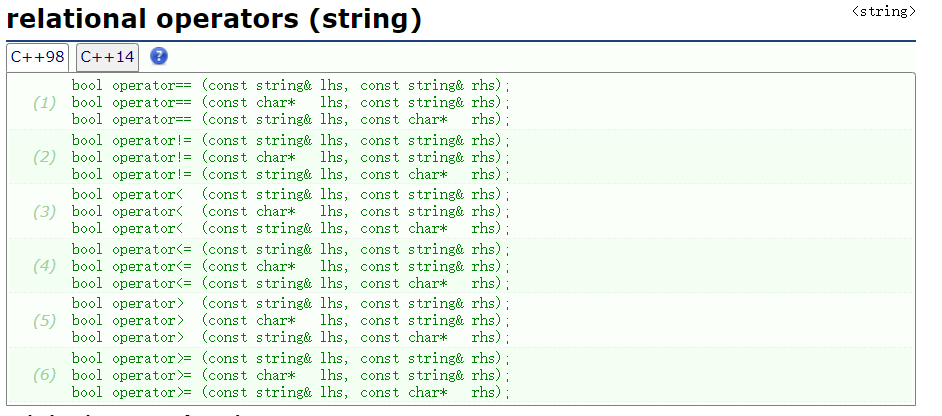
string 的比较;可以支持 string 和 string ,string 和 char,因为重载了:

根据 ascii 码值比较,大的则大一旦比较时不相等,直接返回结果;类似于 strcmp
7、库函数※

一些库函数,比如 atoi 和 itoa ,在 C++ 中并不好用;并且它们并不是标准库下的函数,可能换个 ide 就不好用了。这时这些库函数就发挥了作用。
stoi :string 转 int(默认十进制),平时我们一般用整形,所以其他的可以先不用管。


同理,剩下几个函数,是对不同类型数据的转换。

将数据转换为字符串(C++11):
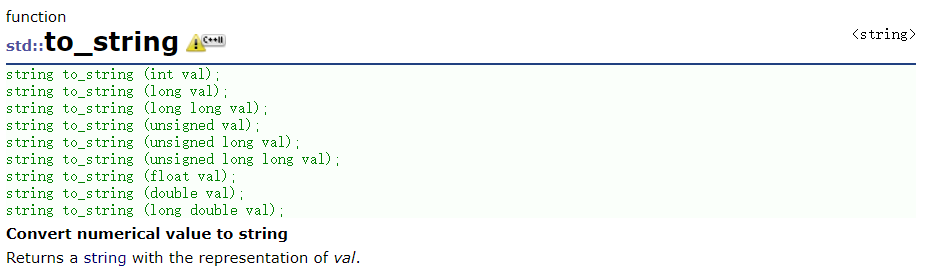

(double 默认转六位)
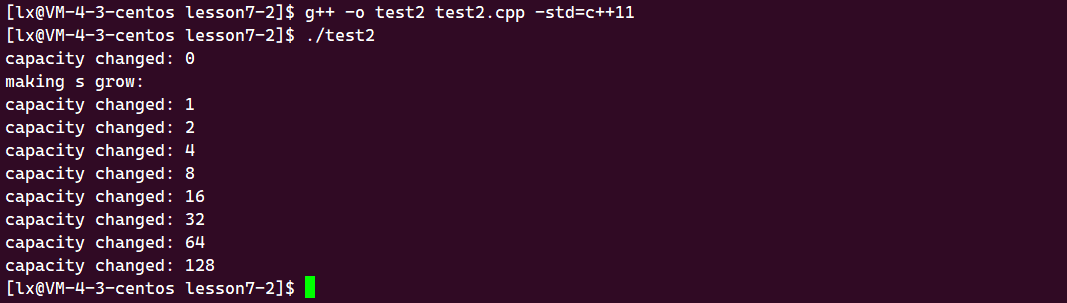
三、测试扩容
void TestPushBackReserve()
{
string s;
s.reserve(100);
size_t sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
cout << "making s grow:\n";
for (int i = 0; i < 100; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}
vs:大约 1.5 倍
初始容量为 15,其实有 16 个,一个是 \0

linux :2 倍
四、写时拷贝
写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源。
当修改对象时,发现引用计数不为 1,则对对象进行深拷贝,并将两个引用计数都置为 1 。
Linux 下为写时拷贝:


一开始为浅拷贝,修改对象时,进行深拷贝。
五、win 下 string 的内存分布
win 下当 string 中有效字符 <= 15 时,sizeof(str) 大小为 28
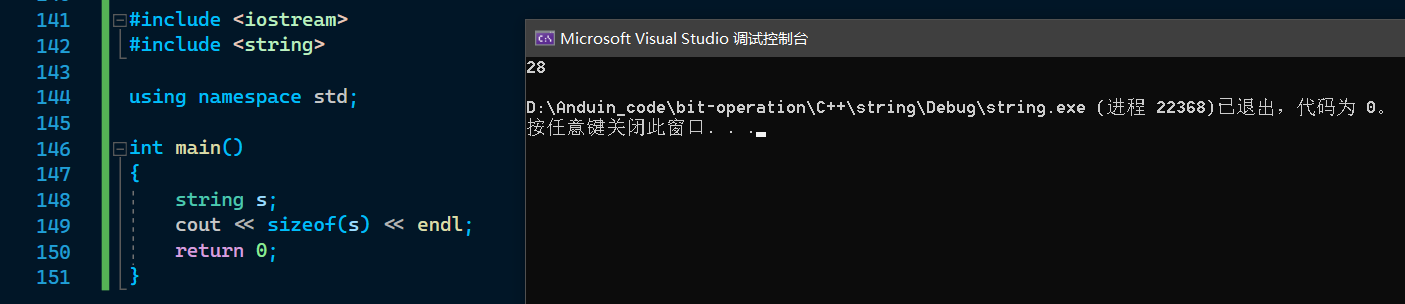

win 财大气粗,在初识状态有一个 16 字节的 _Buf(能存 15 个,有一个给 \0) ,根据对齐,大小为 15 + 1 + 4 + 4 + 4 ,为 28
当 size < 16 时,字符存在 _buf 数组中;size >= 16 存在 _Ptr 指向的堆空间中:

优点:string 小时,效率高
缺点:string 大时,存在空间浪费

![[NSSRound#13 Basic]flask?jwt?解题思路过程](https://img-blog.csdnimg.cn/48e628999efb4a9181f681e4857e5204.png)



![vector [] 赋值出现的报错问题](https://img-blog.csdnimg.cn/19c86224848a4a52b81af53e18617c0f.png)




![[LeetCode周赛复盘] 第 353 场周赛20230709](https://img-blog.csdnimg.cn/aa84a4b3c2f8492b81f2a7358e3c55a2.png)