- 新建类
package test01;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(new Configuration());
//设置并行度
executionEnvironment.setParallelism(1);
//监听数据端口
DataStreamSource<String> dataSource = executionEnvironment.socketTextStream("localhost", 9999);
//使用filter对数据进行分流,这里测试如果是以H开头的分为一个流,以M开头的分为一个流。缺点是每条数据都会执行一下各个filter
SingleOutputStreamOperator<String> hWord = dataSource.filter(value -> value.startsWith("H"));
SingleOutputStreamOperator<String> mWord = dataSource.filter(value -> value.startsWith("M"));
//打印分流,这里print可以使用ctrl+p看到print有个参数,这样就可以在打印时在开头位置加上一些信息。
hWord.print("以H开头:");
mWord.print("以M开头:");
executionEnvironment.execute();
}
}
- 启动netcat和程序

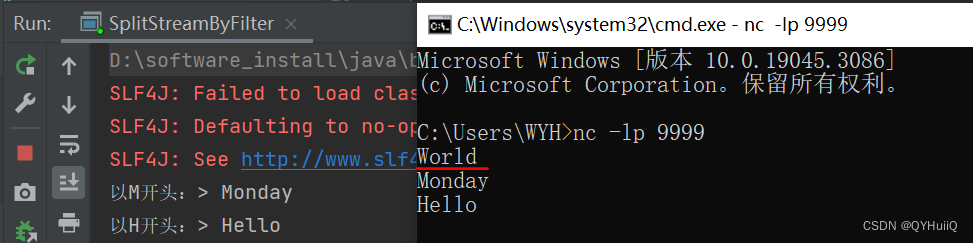 可以看到输入的"World"由于不满足两个filter中的任何一个,所以数据被舍弃。"Monday"和"Hello"分别打印在两个不同的流中。
可以看到输入的"World"由于不满足两个filter中的任何一个,所以数据被舍弃。"Monday"和"Hello"分别打印在两个不同的流中。



![vector [] 赋值出现的报错问题](https://img-blog.csdnimg.cn/19c86224848a4a52b81af53e18617c0f.png)





![[LeetCode周赛复盘] 第 353 场周赛20230709](https://img-blog.csdnimg.cn/aa84a4b3c2f8492b81f2a7358e3c55a2.png)