通常,很多关系数据项目都使用 MySQL。 它对于标准的 CRUD 操作是有益的,但有时我们需要做额外的过程。 当我们搜索某些内容时,我们会消耗资源或合并多个表。 有时,即使不是,可能仍然需要复杂的 SQL 查询。 也许这不是正确的方法,但这是我们改变技术堆栈的不同方法。 对于这个堆栈,我们首先描述 Logstash。
更多阅读:“Elastic:开发者上手指南” 中的 “数据库数据同步” 章节。
我们什么时候使用 Logstash?
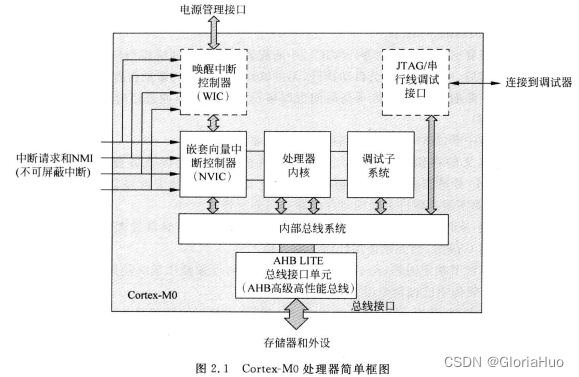
Logstash 用于必须从源接收数据、处理数据然后发送到另一个目的地的场景。 作为起点,Logstash 连接到 MySQL 读取数据,然后对其进行处理,最后将其发送到 Elasticsearch。 如下图所示

Logstash 的操作分为三个步骤:
- 输入 - input
- 过滤器 - filter
- 输出 - output
在添加此代码之前,我创建了一个名为 search.conf 的 Logstash 配置文件。
input{
jdbc {
jdbc_driver_library => "/home/mysql-connector-java-8.0.22.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://${MYSQL_HOST}:3306/product?zeroDateTimeBehavior=convertToNull"
jdbc_user => 'root'
jdbc_password => ''
statement => "Select product.*, DATE_FORMAT(updatedAt, '%Y-%m-%d %T') as lastTransaction from product where updatedAt > :sql_last_value"
tracking_column => "lastTransaction"
tracking_column_type => "timestamp"
use_column_value => true
lowercase_column_names => false
clean_run => true
schedule => "*/15 * * * * *"
}
}此输入运行 MySQL 查询并包含一个存储最新更新日期的跟踪列。 感谢此列,我可以有效地仅检索最后更新的行,而不是获取所有行。 现在我有了数据,我可以继续处理了。
filter {
ruby {
code => "
if event.get('productStatusFK')
productStatusFK = event.get('productStatusFK').to_i
if productStatusFK == 0
event.set('productStatusFK', 'passive')
elsif productStatusFK == 1
event.set('productStatusFK', 'active')
end
end
"
}
mutate {
remove_field => ["@version", "@timestamp"]
}
}下一步是将数据发送到 Elasticsearch。 我们如何执行输出操作?
output {
elasticsearch {
hosts => [ "http://${ELASTIC_HOST}:9200" ]
document_id => '%{productPK}'
index => "product"
doc_as_upsert => true
action => "update"
codec => "json"
manage_template => true
template_overwrite => true
}
}我完成了配置文件。 之后,我为 docker-compose 准备 app.yml。 它包含 4 个服务:MySQL,Logstash,Elasticsearch 及 Kibana。 这三个服务位于同一网络上。 由于这个网络,他们能够使用他们的服务名称相互通信。 同样对于 logstash,我创建了一个管道并在文件中对其进行了描述。 该文件使用 search.conf 文件。 所有文件已添加到 Github,下面提供了链接。 详细信息在下面的代码中。
app.yml
version: "3.7"
services:
elasticsearch:
image: elasticsearch:${STACK_VERSION}
volumes:
- type: volume
source: es_data
target: /usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms750m -Xmx750m
- xpack.security.enabled=false
networks:
- elastic
kibana:
image: kibana:${STACK_VERSION}
container_name: kibana
ports:
- target: 5601
published: 5601
depends_on:
- elasticsearch
networks:
- elastic
logstash:
image: logstash:${STACK_VERSION}
depends_on:
- elasticsearch
volumes:
- ./product/pipeline/:/usr/share/logstash/pipeline/
- ./product/config/pipeline.yml:/usr/share/logstash/config/pipeline.yml
- ./mysqlConnector/mysql-connector-java-8.0.22.jar:/home/mysql-connector-java-8.0.22.jar
environment:
- ELASTIC_HOST=elasticsearch
- MYSQL_HOST=mysql
networks:
- elastic
mysql:
image: mysql:8
restart: always
command: --default-authentication-plugin=mysql_native_password
environment:
MYSQL_DATABASE: product
MYSQL_TCP_PORT: 3306
MYSQL_ALLOW_EMPTY_PASSWORD: "true"
volumes:
- ./database/product.sql:/docker-entrypoint-initdb.d/product.sql:ro
ports:
- "3306:3306"
networks:
- elastic
volumes:
es_data:
driver: local
networks:
elastic:
name: elastic
driver: bridge我们需要在 .env 文件中指定我们需要的 Elastic Stack 版本:
$ pwd
/Users/liuxg/data/MySQL2ElasticFlow
$ ls -al
total 24
drwxr-xr-x 9 liuxg staff 288 Jul 9 11:00 .
drwxr-xr-x 184 liuxg staff 5888 Jul 9 10:54 ..
-rw-r--r-- 1 liuxg staff 20 Jul 9 11:00 .env
drwxr-xr-x 12 liuxg staff 384 Jul 9 10:54 .git
-rw-r--r-- 1 liuxg staff 3384 Jul 9 10:54 README.md
-rw-r--r-- 1 liuxg staff 1513 Jul 9 11:01 app.yml
drwxr-xr-x 3 liuxg staff 96 Jul 9 10:54 database
drwxr-xr-x 3 liuxg staff 96 Jul 9 10:54 mysqlConnector
drwxr-xr-x 4 liuxg staff 128 Jul 9 10:54 product
$ cat .env
STACK_VERSION=8.8.2让我们测试一下这个结构。 使用 docker-compose 构建并运行应用程序。如果你已经有 mysqld 正在运行,你可以使用如下的命令来停止它的运行:
mysqladmin -u root shutdown -pdocker-compose -f app.yml up
我们可以使用如下的命令来查看运行的容器:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
662fd611a7a5 mysql:8 "docker-entrypoint.s…" 2 minutes ago Up 2 minutes 0.0.0.0:3306->3306/tcp, 33060/tcp mysql
3c3754292b27 logstash:8.8.1 "/usr/local/bin/dock…" 38 minutes ago Up 2 minutes 5044/tcp, 9600/tcp logstash
5b6b423363b5 kibana:8.8.1 "/bin/tini -- /usr/l…" 38 minutes ago Up 2 minutes 0.0.0.0:5601->5601/tcp kibana
b6bd075c5189 elasticsearch:8.8.1 "/bin/tini -- /usr/l…" 38 minutes ago Up 2 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch我们可以看到有四个正在运行的容器。我们可以通过如下的命令来查看 Logstash 的日志:
docker logs -f logstash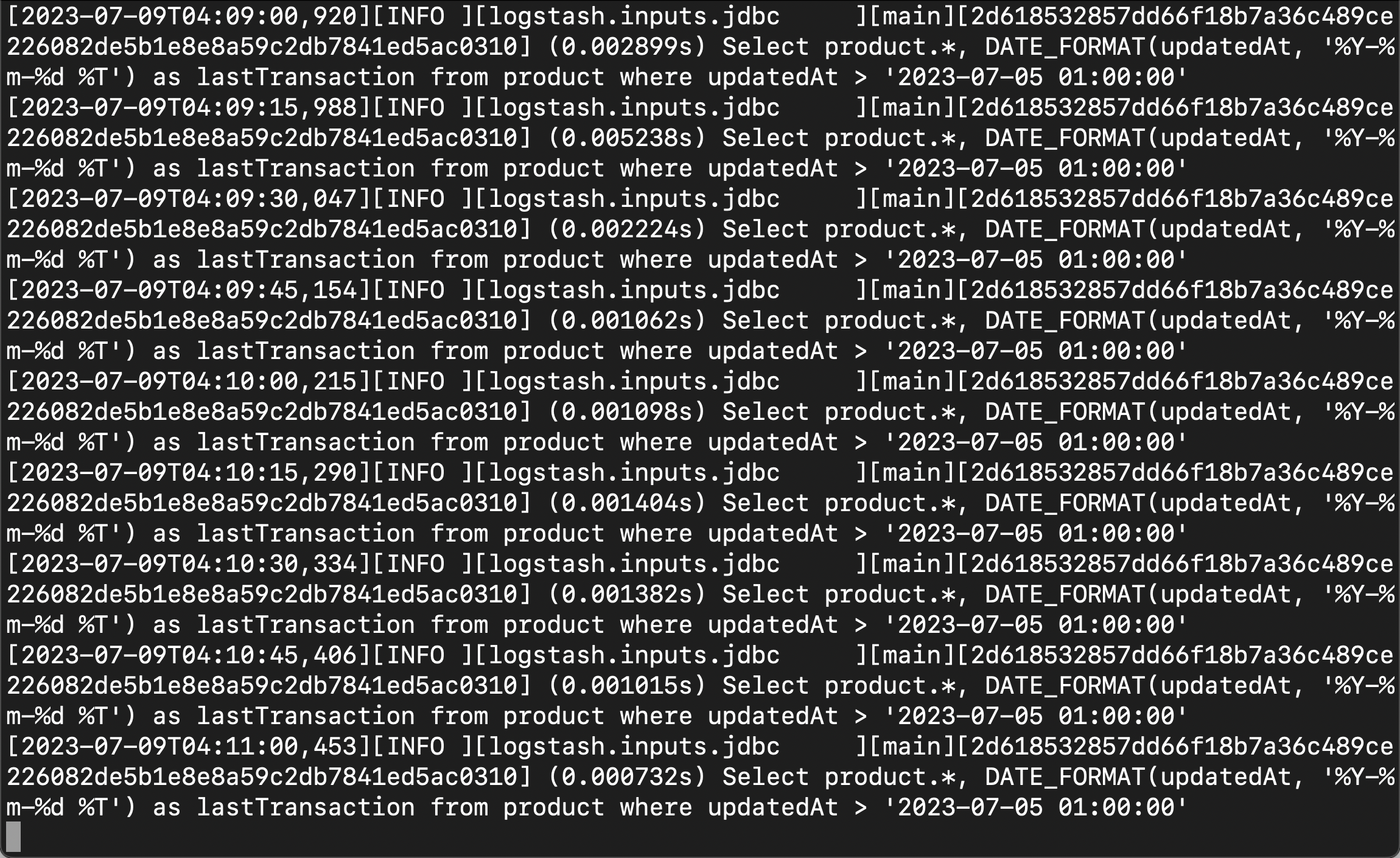
现在是时候在 Kibana 中进行查看了:
GET _cat/indicesyellow open product yUIb3AWPQKqvm6wnbSsoNQ 1 1 4 0 15.6kb 15.6kb我们可以通过如下的方式来查看里面的文档:
GET product/_search我们可以看到有四个文档:
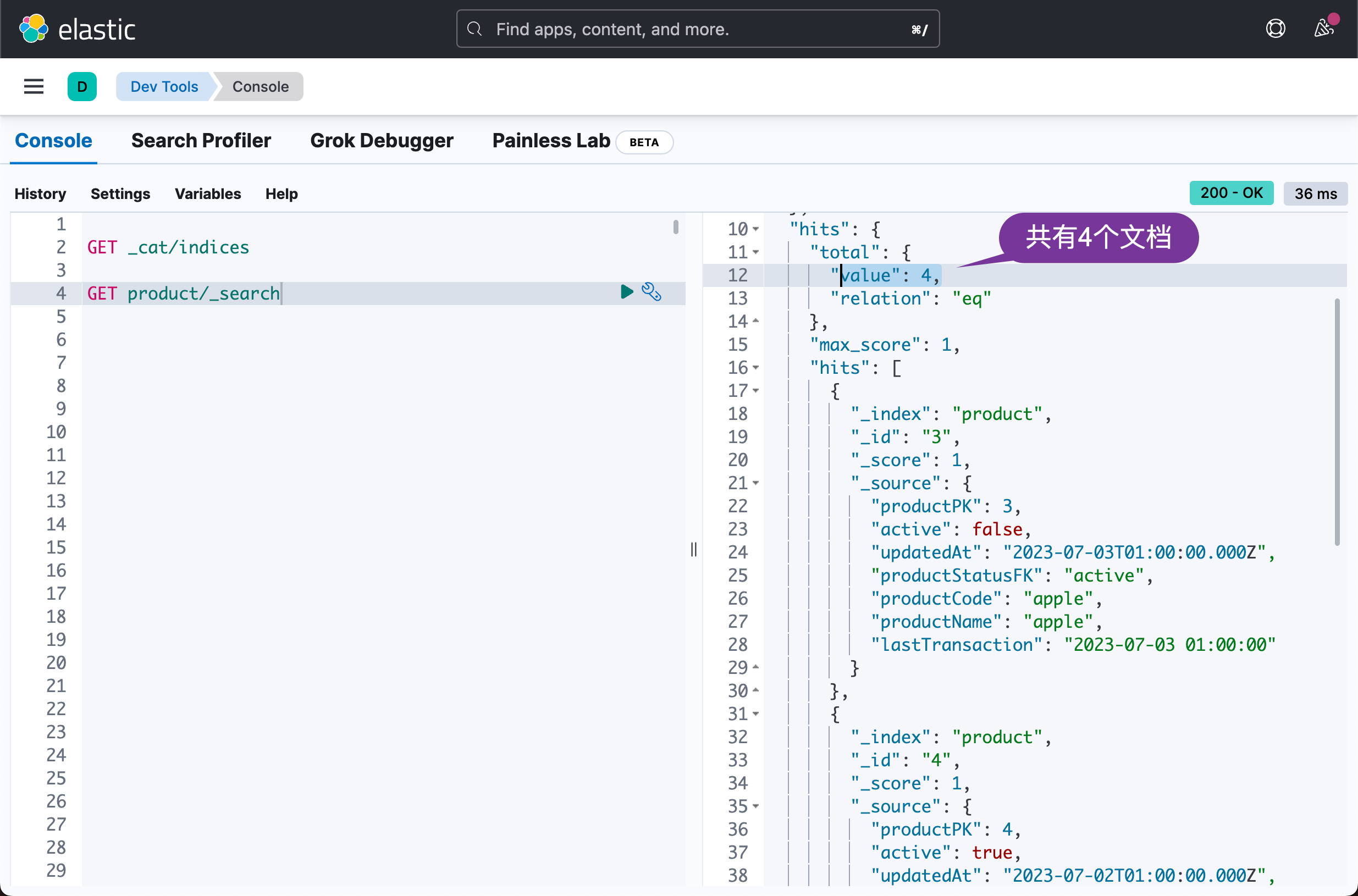
很显然,它是我们之前在 database/product.sql 中写进去的四个文档:
INSERT INTO `product` (`productPK`, `productName`, `productCode`, `productStatusFK`, `active`, `updatedAt`) VALUES
(1, 'logitech', 'logitech', 1, 1, '2023-07-05 01:00:00'),
(2, 'asus', 'asus', 1, 0, '2023-07-04 01:00:00'),
(3, 'apple', 'apple', 1, 0, '2023-07-03 01:00:00'),
(4, 'hewlett packard', 'hewlett packard', 1, 1, '2023-07-02 01:00:00');我们可以对数据进行如下的搜索:
GET product/_search?filter_path=**.hits
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "asu",
"fields": [
"productName",
"productCode"
],
"fuzziness": "auto"
}
}
]
}
}
}我们可以得到如下的结果:
{
"hits": {
"hits": [
{
"_index": "product",
"_id": "2",
"_score": 0.87417156,
"_source": {
"productPK": 2,
"active": false,
"updatedAt": "2023-07-04T01:00:00.000Z",
"productStatusFK": "active",
"productCode": "asus",
"productName": "asus",
"lastTransaction": "2023-07-04 01:00:00"
}
}
]
}
}Hooray! 我们已经完成了从 MySQL 通过 Logstash 把文档写入到 Elasticsearch!