@toc
一、环境说明
- 华为数据仓库服务DWS,集群版本8.1.3.320
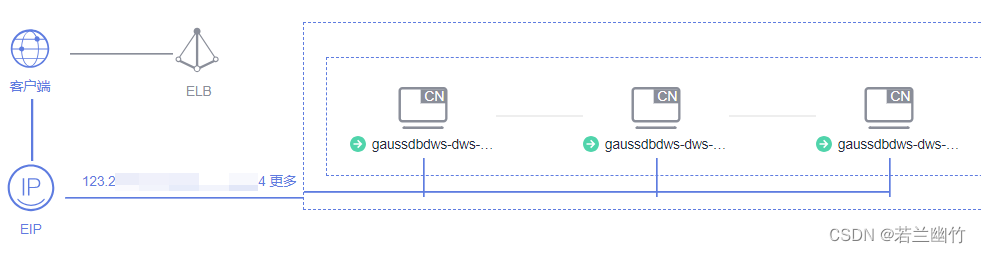
- 集群拓扑结构:
二、数据分布式方式
DWS采用水平分表的方式,将业务数据表的元组打散存储到各个节点内。这样带来的好处在于,查询中通过查询条件过滤不必要的数据,快速定位到数据存储位置,可极大提升数据库性能。
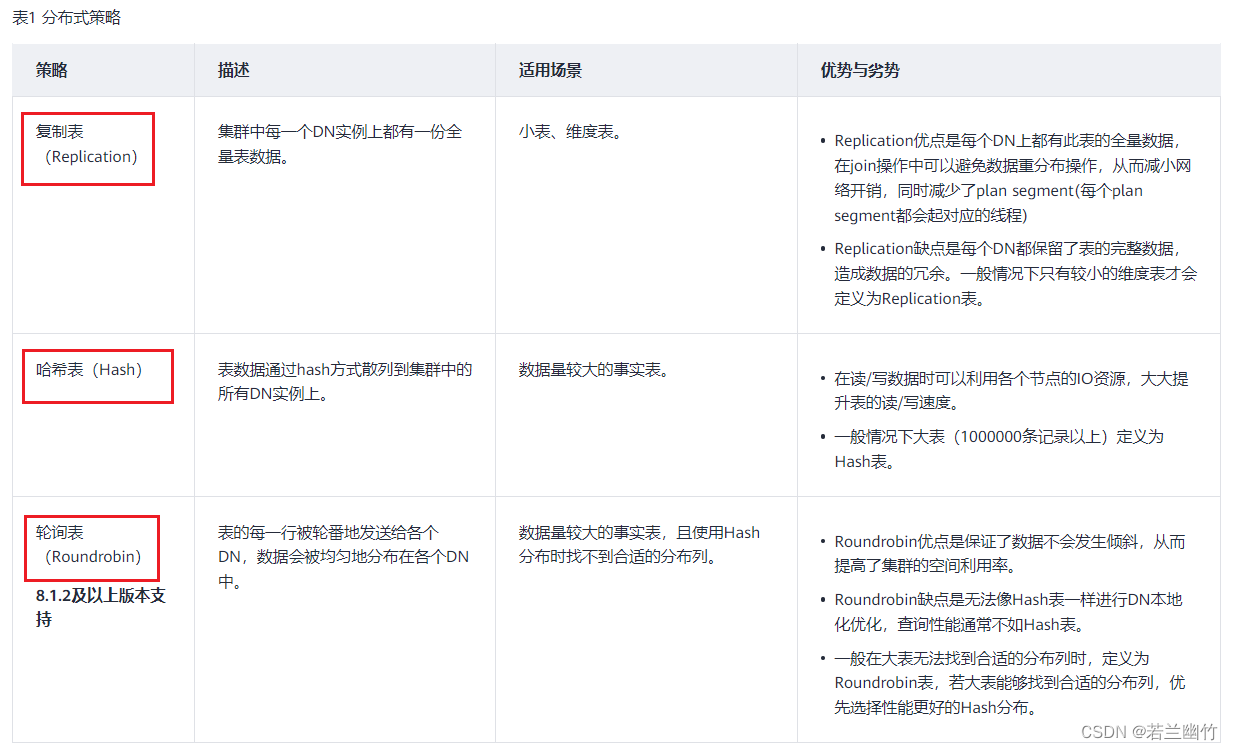
水平分表方式将一个数据表内的数据,按合适分布策略分散存储在多个节点内,DWS支持如表1所示的数据分布策略。用户可在CREATE TABLE时增加DISTRIBUTE BY参数,来对指定的表应用数据分布功能。
分布式策略如下
三、实验验证
- 以下操作是在gsql上,使用系统用户
dbadmin登录,登录语句如下:gsql -d postgres -p 8000 -h xxx.249.99.67 -U dbadmin -W xxxxx@1234 -r注意:在dws数仓下,如使用dbadmin登录,默认的schema是与用户同名的schema,即dbadmin,这点与openGauss和华为GaussDB 云数据库是有区别的,后两者如不指定的情况下使用的是public。 - 创建Replication复制表
- 创建复制表
提示如下:create table t10(id int not null primary key,name varchar(50)) distribute by replication;NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index “t10_pkey” for table “t10”
CREATE TABLE
postgres=> - 查看表结构
postgres=> \d+ t10;
Table “dbadmin.t10”
Column | Type | Modifiers | Storage | Stats target | Description
--------±----------------------±----------±---------±-------------±------------
id | integer | not null | plain | |
name | character varying(50) | | extended | |
Indexes:
“t10_pkey” PRIMARY KEY, btree (id) TABLESPACE pg_default
Has OIDs: no
Distribute By: REPLICATION
Location Nodes: ALL DATANODES
Options: orientation=row, compression=no - 添加数据,添加6条元组
insert into t10 values(1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'); - 查看集群数据节点
结果如下:SELECT node_name,node_type,node_host FROM pgxc_node where node_type='D';node_name | node_type | node_host --------------+-----------+--------------- dn_6001_6002 | D | 172.16.80.96 dn_6003_6004 | D | 172.16.89.109 dn_6005_6006 | D | 172.16.90.239 (3 rows) - 查看数据分布情况
结果如下:每个DN节点上都各自拥有6条数据,即全量数据execute direct on(dn_6001_6002) 'select * from t10'; execute direct on(dn_6003_6004) 'select * from t10'; execute direct on(dn_6005_6006) 'select * from t10';postgres=> execute direct on(dn_6001_6002) 'select * from t10'; id | name ----+------- 1 | test1 2 | test2 3 | test3 4 | test4 5 | test5 6 | test6 (6 rows) postgres=> execute direct on(dn_6003_6004) 'select * from t10'; id | name ----+------- 1 | test1 2 | test2 3 | test3 4 | test4 5 | test5 6 | test6 (6 rows) postgres=> execute direct on(dn_6005_6006) 'select * from t10'; id | name ----+------- 1 | test1 2 | test2 3 | test3 4 | test4 5 | test5 6 | test6 (6 rows)
- 创建复制表
- 创建Hash表
- 创建Hash表
create table t11(id int not null,name varchar(50)) distribute by hash(id); - 查看表结构
postgres=> \d+ t11 Table "dbadmin.t11" Column | Type | Modifiers | Storage | Stats target | Description --------+-----------------------+-----------+----------+--------------+------------- id | integer | not null | plain | | name | character varying(50) | | extended | | Has OIDs: no Distribute By: HASH(id) Location Nodes: ALL DATANODES Options: orientation=row, compression=no - 添加测试数据
insert into t11 values(1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'); - 查看数据分布情况
postgres=> execute direct on(dn_6001_6002) 'select * from t11'; id | name ----+------- 3 | test3 (1 row) postgres=> execute direct on(dn_6003_6004) 'select * from t11'; id | name ----+------- 1 | test1 2 | test2 4 | test4 5 | test5 (4 rows) postgres=> execute direct on(dn_6005_6006) 'select * from t11'; id | name ----+------- 6 | test6 (1 row)注意:这里看起来是没有均衡分布的,因其采用的是一致性hash算法,即hash(文件或服务器ip) % 232,是对232取模,具体算法请参考:一致性hash算法
一般Hash表针对的是大数据量的情况下,一般是至少1000000条数据。
- 创建Hash表
- 创建Roundrobin 轮询表
- 创建表,这种创建Roundrobin表的方式是一种隐式创建法。
会打印提示信息:create table t12(id int not null,name varchar(50));NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using round-robin as the distribution mode by default. HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column. - 查看表结构
postgres=> \d+ t12 Table "dbadmin.t12" Column | Type | Modifiers | Storage | Stats target | Description --------+-----------------------+-----------+----------+--------------+------------- id | integer | not null | plain | | name | character varying(50) | | extended | | Has OIDs: no Distribute By: ROUND ROBIN Location Nodes: ALL DATANODES Options: orientation=row, compression=no - 添加数据
insert into t12 values(1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'); - 查看数据分布情况
postgres=> execute direct on(dn_6001_6002) 'select * from t12'; id | name ----+------- 3 | test3 6 | test6 (2 rows) postgres=> execute direct on(dn_6003_6004) 'select * from t12'; id | name ----+------- 1 | test1 4 | test4 (2 rows) postgres=> execute direct on(dn_6005_6006) 'select * from t12'; id | name ----+------- 2 | test2 5 | test5 (2 rows) - 补充:显示创建roundrobin表,如下所示:
查看表结构:create table t13(id int not null,name varchar(50)) with(orientation=row) distribute by roundrobin;postgres=> \d+ t13 Table "dbadmin.t13" Column | Type | Modifiers | Storage | Stats target | Description --------+-----------------------+-----------+----------+--------------+------------- id | integer | not null | plain | | name | character varying(50) | | extended | | Has OIDs: no Distribute By: ROUND ROBIN Location Nodes: ALL DATANODES Options: orientation=row, compression=no
- 创建表,这种创建Roundrobin表的方式是一种隐式创建法。
三种类型表测试完毕,感受是纸上得来终觉浅,绝知此事要躬行。实践出真知,理论需要实践来证明,学习,道阻且长。继续加油吧!!
![[工业互联-18]:常见EtherCAT主站方案:SOEM的Windows/Linux解决方案](https://img-blog.csdnimg.cn/bf230e029edb4274bd884f32ac792541.png)