现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。
作为传统pytorch Dataparallel的一种替代,DeepSpeed的目标,就是为了能够让亿万参数量的模型,能够在自己个人的工作服务器上进行训练推理。
本文旨在简要地介绍Deepspeed进行大规模模型训练的核心理念,以及最基本的使用方法。更多内容,笔者强烈建议阅读HuggingFace Transformer官网对于DeepSpeed的教程:
Transformer DeepSpeed Integration
1. 核心思想 (TLDR)
DeepSpeed的核心就在于,GPU显存不够,CPU内存来凑。
比方说,我们只有一张10GB的GPU,那么我们很可能需要借助80GB的CPU,才能够训练一个大模型。
看一下官网对于这个理念的描述:
Why would you want to use DeepSpeed with just one GPU?
- It has a ZeRO-offload feature which can delegate some computations and memory to the host’s CPU and RAM, and thus leave more GPU resources for model’s needs - e.g. larger batch size, or enabling a fitting of a very big model which normally won’t fit.
- It provides a smart GPU memory management system, that minimizes memory fragmentation, which again allows you to fit bigger models and data batches.
具体点说,DeepSpeed将当前时刻,训练模型用不到的参数,缓存到CPU中,等到要用到了,再从CPU挪到GPU。这里的“参数”,不仅指的是模型参数,还指optimizer、梯度等。
越多的参数挪到CPU上,GPU的负担就越小;但随之的代价就是,更为频繁的CPU,GPU交互,极大增加了训练推理的时间开销。因此,DeepSpeed使用的一个核心要义是,时间开销和显存占用的权衡。
2. 如何安装
直接pip安装:
pip install deepspeed官方更推荐的是用仓库本地编译安装,能够更加适配你的本地硬件环境:
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log另外,HuggingFace提供了对DeepSpeed的友好集成,DeepSpeed使用所需要的很多参数,都可以由Transformer的Trainer来自动指定。可以说,DeepSpeed在HuggingFace Transformer上的使用,会更为便捷(当然,DeepSpeed也可以独立使用,并不依赖于Transformer)。
作为Transformer的附属包安装:
pip install transformers[deepspeed]3. 如何使用
使用DeepSpeed之后,你的命令行看起来就会像下面这样:
deepspeed --master_port 29500 --num_gpus=2 run_s2s.py \
--deepspeed ds_config.json--master_port:端口号。最好显示指定,默认为29500,可能会被占用(i.e., 跑了多个DeepSpeed进程)。--num_gpus: GPU数目,默认会使用当前所见的所有GPU。--deepspeed: 提供的config文件,用来指定许多DeepSpeed的重要参数。
使用DeepSpeed的一个核心要点,就在于写一个config文件(可以是.json,也可以是类json格式的配置文件),在这个配置文件中,你可以指定你想要的参数,例如,权衡时间和显存 (前文所提到的,这是一个很重要的权衡)。因此,上面几个参数里,最重要的便是--deepspeed,即你提供的config文件,即ZeRO。这也是本文接下来要重点介绍的。
3.1 ZeRO概述
Zero Redundancy Optimizer (ZeRO)是DeepSpeed的workhorse. 用户可以提供不同的ZeRO config文件,来实现DeepSpeed的不同功能特性。
来看一下官网教程对ZeRO的描述:
The Zero Redundancy Optimizer (ZeRO) removes the memory redundancies across data-parallel processes by partitioning the three model states (optimizer states, gradients, and parameters) across data-parallel processes instead of replicating them. By doing this, it boosts memory efficiency compared to classic data-parallelism while retaining its computational granularity and communication efficiency.
一句话总结: partitioning instead of replicating,划分而不是复制。
即,传统的深度学习,模型训练并行,是将模型参数复制多份到多张GPU上,只将数据拆分(如,torch的Dataparallel),这样就会有大量的显存冗余浪费。而ZeRO就是为了消除这种冗余,提高对memory的利用率。注意,这里的“memory”不仅指多张GPU memory,还包括CPU。
而ZeRO的实现方法,就是把参数占用,逻辑上分成三种类型。将这些类型的参数划分:
optimizer states:即优化器的参数状态。例如,Adam的动量参数。gradients:梯度缓存,对应于optimizer。parameters:模型参数。
对应的,DeepSpeed的ZeRO config文件就可以分为如下几类:
ZeRO Stage 1: 划分optimizer states。优化器参数被划分到多个memory上,每个momoey上的进程只负责更新它自己那部分参数。ZeRO Stage 2: 划分gradient。每个memory,只保留它分配到的optimizer state所对应的梯度。这很合理,因为梯度和optimizer是紧密联系在一起的。只知道梯度,不知道optimizer state,是没有办法优化模型参数的。ZeRO Stage 3: 划分模型参数,或者说,不同的layer. ZeRO-3会在forward和backward的时候,自动将模型参数分配到多个memory。
由于ZeRO-1只分配optimizer states(参数量很小),实际使用的时候,我们一般只会考虑ZeRO-2和ZeRO-3。
接下来介绍stage 2和3的常用config文件。
3.2 ZeRO Stage 2
结合官网的介绍,笔者提供一个常用的ZeRO-stage-2的config文件:
{
"bfloat16": {
"enabled": "auto"
},
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"steps_per_print": 1e5
}- 有关于
offload
上述参数中,最重要的一个就是"offload_optimizer"。如上述所示,我们将其”device“设置成了cpu,DeepSpeed就会按照之前提到过的ZeRO操作,在训练过程中,将优化器状态分配到cpu上。从而降低单张GPU的memory占用。
- 有关于
overlap_comm
另外一个需要提到的参数是overlap_comm。简单地理解,它控制着多个memory上进程之间通信的buffer的大小。这个值越大,进程之间通信越快,模型训练速度也会提升,但相应的显存占用也会变大;反之亦然。
因此,overlap_comm也是一个需要进行一定权衡的参数。
- 有关于
auto
我们可以发现,上述大量参数被设置为auto。由于DeepSpeed目前已经被集成到了HuggingFace Transformer框架。而DeepSpeed的很多参数,和Transformer的Trainer参数设置是一模一样的,例如,"optimizer","scheduler"。因此,官方推荐将很多常用的模型训练参数,设置为auto,在使用Trainer进行训练的时候,这些值都会自动更新为Trainer中的设置,或者帮你自动计算。
当然,你也可以自己设置,但一定要确保和Trainer中的设置一样。因为,如果设置错误,DeepSpeed还是会正常运行,不会立即报错。
- 总结
大多数情况下,你只需要注意DeepSpedd-specific参数(如,offload),其他和Trainner重复的参数项,强烈建议设置成auto。而具体这些每一项参数的含义,和值的设置,请参见官网的详细介绍。
总而言之,由于设置了auto,上述config,能够适配大多数的Transformer框架stage-2的use-cases。
3.3 ZeRO Stage 3
和Stage-2类似,笔者也提供一个stage-3的模板config
{
"bfloat16": {
"enabled": false
},
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_fp16_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 1e5,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}- 有关于
“offload_param”
可以看到,除了和stage2一样,有offload_optimizer参数之外,stage3还有一个offload_param参数。即,将模型参数进行划分。
- stage-3相关的其他参数
下面这些参数是stage-3-specific的:
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_fp16_weights_on_model_save": true一样的道理,这些值很多都可以用来控制stage-3的显存占用和训练效率(e.g.,sub_group_size);同时,有一些参数也可以设置为auto,让Trainer去决定值(e.g., reduce_bucket_size,stage3_prefetch_bucket_size,stage3_param_persistence_threshold).
对于这些参数的具体描述,和值的trade-off,详见官网:
ZeRO-3 Config
- 总结
一样的道理,上述config文件,也能够适配绝大多是use-cases。一些stage-3-specific的参数可能需要额外注意一下。具体而言,推荐阅读官方文档。
3.4 ZeRO Infinity
除了stage2和3之外,这里简单介绍一下ZeRO-Infinity。
ZeRO-Infinity可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
官网对于ZeRO-Infinity的详细介绍:
DeepSpeed官方教程 :
ZeRO-Infinity has all of the savings of ZeRO-Offload, plus is able to offload more the model weights and has more effective bandwidth utilization and overlapping of computation and communication.
HuggingFace官网:
It allows for training incredibly large models by extending GPU and CPU memory with NVMe memory. Thanks to smart partitioning and tiling algorithms each GPU needs to send and receive very small amounts of data during offloading so modern NVMe proved to be fit to allow for an even larger total memory pool available to your training process. ZeRO-Infinity requires ZeRO-3 enabled.
具体config文件,以及使用事项,请参见官网。
4. 其他
4.1 模型推理
除了模型训练,有时候模型太大,连预测推理都有可能炸显存。
DeepSpeed自然也支持推理。自然,推理的时候,用和stage-3一样参数的config文件就可以,其中某些训练参数是会被自动忽略掉的(如,optimizer,lr)。
具体参考:
ZeRO-Inference
4.2 内存估计
如之前多次强调的,DeepSpeed使用过程中的一个难点,就在于时间和空间的权衡。
分配更多参数到CPU上,虽然能够降低显存开销,但是也会极大地提升时间开销。
DeepSpeed提供了一段简单的memory估算代码:
from transformers import AutoModel
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live
## specify the model you want to train on your device
model = AutoModel.from_pretrained("t5-large")
## estimate the memory cost (both CPU and GPU)
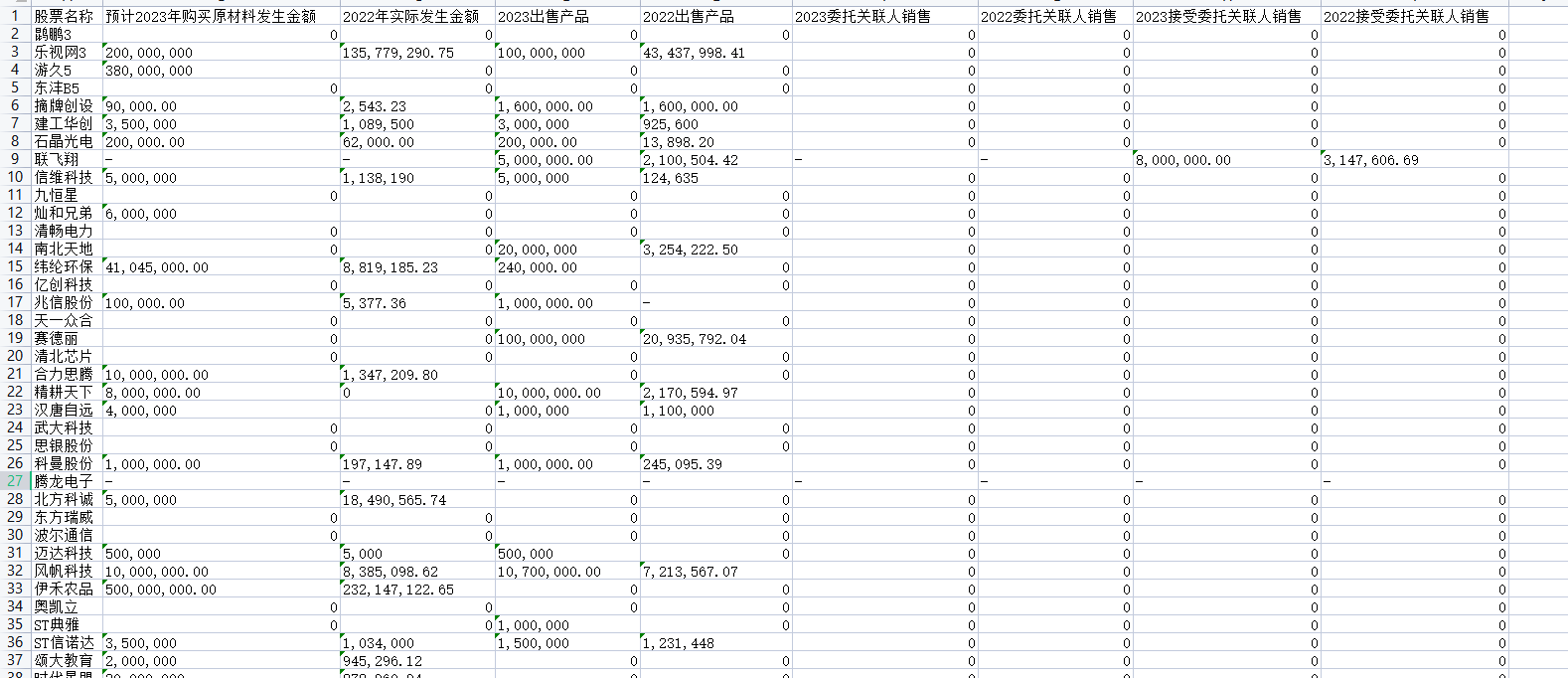
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)以T5-large,只使用一块GPU为例,使用DeepSpeed的开销将会如下:
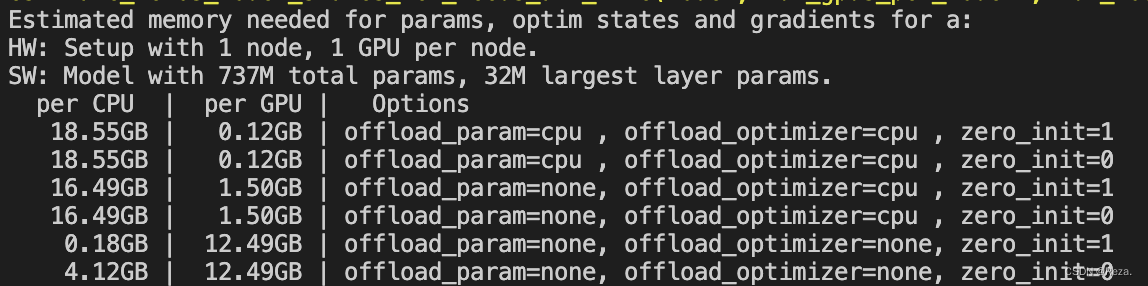
如上,如果不用stage2和stage3(最下面那两行),训练T5-large需要一张显存至少为12.49GB的显卡(考虑到很多其他的缓存变量,还有你的batch_size,实际上可能需要24GB大小的卡)。而在相继使用了stage2和3之后,显存开销被极大地降低,转而CPU内存消耗显著提升,模型训练时间开销也相应地增大。
建议:
在使用DeepSpeed之前,先使用上述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。
原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3.
具体参见官网:Memory Requirements
4.3 使用测评
笔者尝试使用DeepSpeed进行模型的训练。
首先是stage 2,也就是只把optimizer放到cpu上。下面是使用前后的GPU显存占用和训练速度对比:
- GPU显存:
20513MB =>17349MiB - 训练速度 (由
tqdm估计):1.3iter/s =>0.77iter/s
可以明显看到,GPU的显存占用有了明显降低,但是训练速度也变慢了。以笔者当前的使用体感来说,deepspeed并没有带来什么收益。
笔者的机器配有24000MB的显卡,batch_size为2时,占用20513MB;而DeepSpeed仅仅帮助笔者空出了3000MB的显存,还是完全不够增加batch_size, 导致笔者总训练时长变长。
因此,DeepSpeed或许仅适用于显存极度短缺(i.e., 模型大到 batch_size == 1也跑不了)的情况;亦或是,使用DeepSpped节省下来的显存,刚好够支持更大的batch_size。否则,像笔者当前这种情况下,使用DeepSpeed只会增加时间开销,并没有其他益处。
此后,笔者还尝试使用stage 3,但是速度极其缓慢。一个原先需要6h的训练过程,用了DeepSpeed stage3之后,运行了2天2夜,也没有结束的迹象。无奈笔者只好终止测试。
此外,在使用DeepSpeed stage2时,由于分配了模型参数到多个设备上,console里面也看不到任何输出信息(但是GPU还是在呼呼响,utility也为100%),让人都不知道程序的运行进度,可以说对用户非常不友好了。
4.4 一些常见问题
由于DeepSpeed会通过占用CPU内存来减缓GPU的开销,当系统CPU不够的时候,DeepSpeed进程就会自动被系统停止,造成没有任何报错,DeepSpeed无法启动的现象。建议先用上文介绍的estimation估计一下CPU内存占用,然后用free -h查看一下机器的CPU内存空余量,来判断能否使用DeepSpeed。
另外,还有可能因为训练精度问题,出现loss为NAN的情况。详见:Troubleshooting.
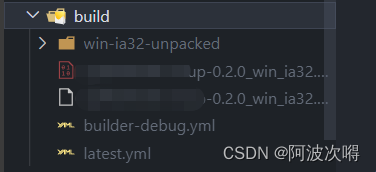
使用DeepSpeed stage2之后,就不能灵活地更改optimizer了。下图是DeepSpeed.py的源代码: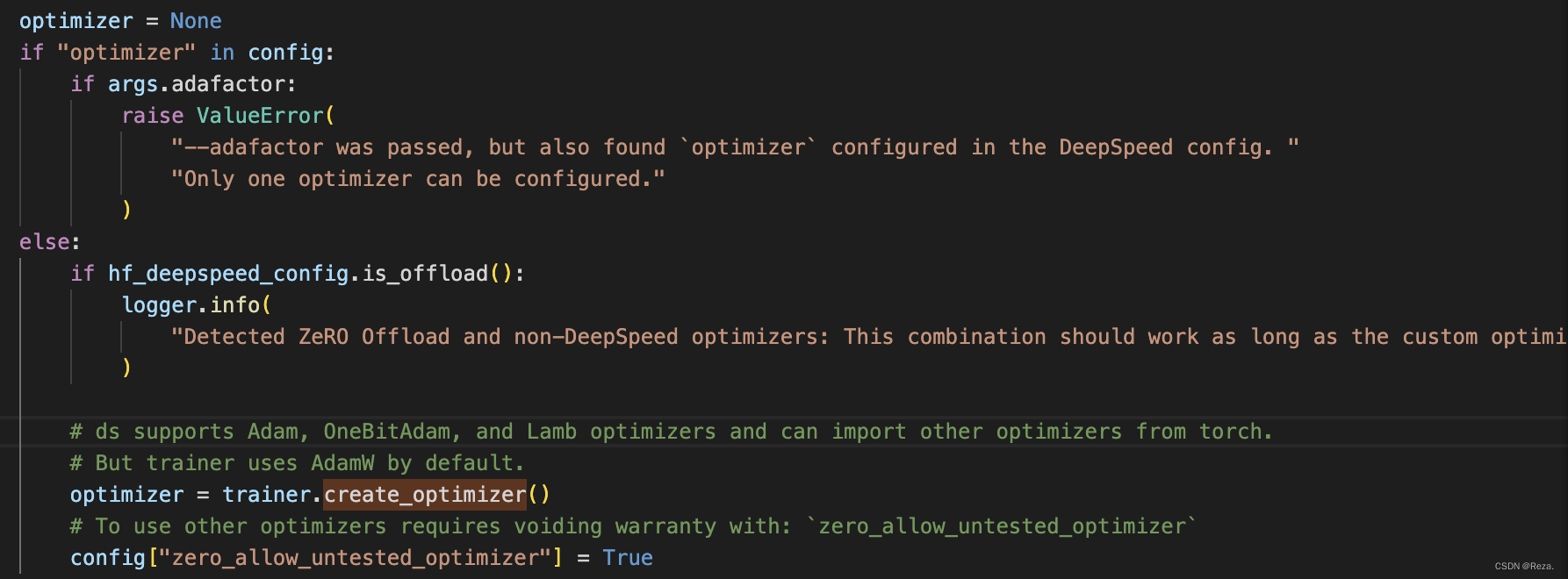
默认optimizer必须在config里面设置好,也就是使用默认的优化器和学习率,不能实现分组学习率。如果要自定义optimizer的初始化过程,必须实现两个版本的optimizer(CPU+GPU)。如官方所述:
Detected ZeRO Offload and non-DeepSpeed optimizers: This combination should work as long as the custom optimizer has both CPU and GPU implementation (except LAMB).
总之这种情况下想要自定义optimizer,就会变得比较麻烦。
最后,有关于VScode的重度依赖患者:
很遗憾,DeepSpeed进程目前还不支持在Vscode进行debug,因为缺少相应的VScode编译插件的支持。详见:github issue
5. 参考:
- HuggingFace Transformer DeepSpeed Integration
- DeepSpeed Tutorial 英文教程
- DeepSpeed Setup 参数说明
# 深度学习# python# 人工智能# pytorch