highlight: arduino-light
消息存储文件
rocketMQ的消息持久化在我们在搭建集群时都特意指定的文件存储路径,进入指定的store目录下就可以看到。
下面介绍各文件含义
CommitLog
存储消息的元数据。produce发出的所有消息都会顺序存入到CommitLog文件当中。 CommitLog由多个文件组成,每个文件固定大小1G。以第一条消息的偏移量为文件名。
ConsumerQueue
对CommitLog做索引,把消息按照Topic、队列进行归类并存储在ConsumerQueue中,但是存储的并不是消息本身,而是消息在CommitLog的索引。ConsumerQueue中存储的有消息的offset、size、Tag等等,记录当前MessageQueue被哪些消费者组消费到了哪一条CommitLog,方便消费者组快速定位到对应的消息!
Index
类似于ConsumerQueue,也是对CommitLog做索引,与ConsumerQueue不同的是:为消息查询提供了一种通过key或时间区间来查询消息的方法,也是记录消息的offset、size、Tag等等
abort
这个文件是RocketMQ用来判断程序是否正常关闭的一个标识文件。正常情况下,会在启动时创建abort文件,在正常关闭服务时删除。
但是如果遇到一些服务器宕机,或者kill -9这样一些非正常关闭服务的情况,这个abort文件就不会删除。
因此RocketMQ就可以判断上一次服务是非正常关闭的,后续就会做一些数据恢复的操作。
checkpoint
数据存盘检查点,存储CommitLog文件最后一次刷盘时间戳、consumerquueue最后一次刷盘时间,index索引文件最后一次刷盘时间戳。
config/*.json:
这些文件是将RocketMQ的一些关键配置信息以能看懂的json形式进行存盘保存。例如Topic配置、消费者组配置、消费者组消息偏移量Offset 等等一些信息。
其中consumerOffset.json是集群模式下的消费者的消费进度。
md { "offsetTable":{ "ojbk@ojbkConsumer":{0:1,1:1,2:1,3:1,4:1,5:1,6:1,7:1 }, "%RETRY%1048@1048":{0:0 }, "%RETRY%rnmConsumer@rnmConsumer":{0:293 }, "tyrant@group1":{0:11,1:9,2:8,3:11,4:11,5:8,6:9,7:9 }, "tyrant@1048":{0:15,1:13,2:12,3:15,4:15,5:12,6:13,7:13 }, "%RETRY%group1@group1":{0:1608 }, "ok@okConsumer":{0:1,1:1,2:1,3:1,4:1,5:1,6:1,7:1 }, "%RETRY%ojbkConsumer@ojbkConsumer":{0:6 }, "rnm@rnmConsumer":{0:20,1:20,2:20,3:20,4:20,5:20,6:20,7:20 }, "%RETRY%okConsumer@okConsumer":{0:0 } } }
.rocketmq_offsets
C:\Users\彭方亮.rocketmq_offsets\172.18.95.180\@DEFAULT
其中consumerOffset.json是广播模式下的消费者的消费进度。
比如C:\Users\彭方亮.rocketmq_offsets\172.18.95.180\@DEFAULT\tyrantConsumer\offsets.json
md { "offsetTable":{{ "brokerName":"broker-a", "queueId":2, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":3, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":4, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":5, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":6, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":7, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":0, "topic":"tyrantor" }:2,{ "brokerName":"broker-a", "queueId":1, "topic":"tyrantor" }:2 } }
消息存储流程分析
消息存储流程
1.要发送的消息,会按顺序写入commitlog中,这里所有topic和queue共享一个文件
2.存入commitlog后,由于消息会按照topic纬度来消费,会异步构建consumeQueue(逻辑队列)和index(索引文件),consumeQueue存储消息的commitlogOffset/messageSize/tagHashCode, 方便定位commitlog中的消息实体。
3.每个 Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。索引文件(Index)提供消息检索的能力,主要在问题排查和数据统计等场景应用
4.消费者会从consumeQueue取到msgOffset,方便快速取出消息
RocketMQ为了保证消息发送的高吞吐量,采用单一文件存储所有主题消息,保证消息存储是完全的顺序写,但这样给文件读取带来了不便。
为此RocketMQ为了方便消息消费构建了消息消费队列文件ConsumeQueue,基于主题与队列进行组织。
同时RocketMQ为消息实现了Hash索引文件IndexFile,可以为消息设置索引键,根据所以能够快速从CommitLog文件中检索消息。
当消息达到CommitLog后,会通过ReputMessageService线程接近实时地将消息转发给消息消费队列文件ConsumeQueue与索引文件IndexFile。
对于生产者将消息写入broker的时候,broker会直接把消息写入到磁盘的commitLog文件,那么broker是如何提升整个过程的性能的呢?
问题分析下:因为这个部分性能会直接提升broker处理消息写入的吞吐量,比如写入一条消息到commitLog磁盘文件假设需要10ms,那么每个线程每秒可以处理100个写入消息,假设有100个线程,每秒钟只能处理1万个写入消息请求。 但是如果将消息写入commitLog磁盘文件的性能优化为只需要1ms,那么每个线程每秒可以处理1000个消息写入,此时100个线程可以处理10万个写入请求,所以明显的可以看到,broker将接收到的消息写入commitLog磁盘文件的性能,对他的TPS有很大的影响.
铺垫【broker是基于OS操作系统的pageCache和顺序写两个机制,来提升commitLog文件的性能的】;
首先broker是以顺序的方式将消息写入commitLog磁盘文件的,也就是每次写入就是在文件的末尾追加一条数据就可以了,文件顺序写的性能要比随机写的性能提升很多,另外,数据写入commitLog文件的时候,其实不是直接写入底层的物理磁盘文件的,而是先进入OS的pagecache内存缓存中,然后后续由OS的后台线程选择一个时间,异步化的将OSPageCache内存缓冲中的数据刷入底层的磁盘文件。
commitLog优化思路总结:采用磁盘文件顺序写+OSPageCache缓存写入+OS异步刷盘的策略,基本上可以让消息写入commitLog的性能和直接写入内存是差不多的,所以broker才可以让broker高吞吐的处理每秒大量的消息写入。异步刷盘可能会导致消息数据丢失,简单提一嘴同步刷盘的机制:同步刷盘就是生产者发送一条消息出去,broker接收到了消息,必须直接强制的将这条消息刷入底层的物理磁盘中,然后返回ack给producer生产者,此时才知道消息写入成功了,只要消息进入了物理磁盘,数据就一定不会丢失,但是性能受了极大的影响;
通过上述优化,就实现了一个效果,写磁盘文件的时候都是进入pageCache的,保证写入的高性能,同时尽可能多的通过map+madvise的映射后预热机制,将磁盘文件中的数据尽可能多的加载到pageCache中来,对consumequeue,commitLog进行读取的时候,才能达到尽可能从内存中读取数据;
实际上在broker读写磁盘的时候,大量的将mmap技术和pagecache技术结合使用,通过mmap技术减少数据拷贝次数,利用pagecache技术尽可能有限读写内存,而不是物理磁盘;
消息顺序存储好处
1.CommitLog 顺序写 ,可以大大提高写人效率,提高堆积能力
2.虽然是随机读,但是利用操作系统的pagecache机制,可以批量地从磁盘读取,作为cache存到内存中,加速后续的读取速度
3.在实际情况中,大部分的 ConsumeQueue能够被全部读入内存,所以这个中间结构的操作速度很快, 可以认为是内存读取的速度
commitlog文件
- 存放该broke所有topic的消息
- 默认1G大小
- 以偏移量为文件名,当一个文件写满时则创建新文件,这样的设计主要是方便根据消息的物理偏移量,快速定位到消息所在的物理文件
- 一个消息存储单元是不定长的
- 顺序写但是支持随机读
消息单元的存储结构
下面的表格说明了,每个消息体不是定长的,会存储消息的哪些内容,包括物理偏移量、consumeQueue的偏移量、消息体等信息
md 顺序 字段名 说明 1 totalSize(4Byte) 消息大小 2 magicCode(4) 设置为daa320a7 (这个不太明白) 3 bodyCRC(4) 当broker重启recover时会校验 4 queueId(4) 消息对应的consumeQueueId 5 flag(4) rocketmq不做处理,只存储后透传 6 queueOffset(8) 消息在consumeQueue中的偏移量 7 physicalOffset(8) 消息在commitlog中的偏移量 8 sysFlg(4) 事务类型标识 9 bronTimestamp(8) 消息产生端(producer)的时间戳 10 bronHost(8) 消息产生端(producer)地址(address:port) 11 storeTimestamp(8) 消息在broker存储时间 12 storeHostAddress(8) 消息存储到broker的地址(address:port) 13 reconsumeTimes(4) 消息重试次数 14 preparedTransactionOffset(8) 事务消息的物理偏移量 15 bodyLength(4) 消息长度,最长不超过4MB 16 body(body length Bytes) 消息体内容 17 topicLength(1) 主题长度,最长不超过255Byte 18 topic(topic length Bytes) 主题内容 19 propertiesLength(2) 消息属性长度,最长不超过65535Bytes 20 properties(消息属性长度个字节) 消息属性内容
NOT_TYPE/PREPARED_TYPE/COMMIT_TYPE/ROLLBACK_TYPE
consumequeue文件
- 按topic和queueId纬度分别存储消息commitLogOffset、size、tagHashCode
- 以偏移量为文件名
- 一个存储单元是20个字节的定长的
- 顺序读顺序写
- 每个ConsumeQueue文件大小约5.72M
每个Topic下的每个MessageQueue都有一个对应的ConsumeQueue文件 该结构对应于消费者逻辑队列,为什么要将一个topic抽象出很多的queue呢?
这样的话,对集群模式更有好处,可以使多个消费者共同消费,而不用上锁。
消息单元的存储结构
| 顺序 | 字段名 | 说明 | | -- | ----------- | ------------- | | 1 | offset(8) | commitlog的偏移量 | | 2 | size(4) | commitlog消息大小 | | 3 | tagHashCode | tag的哈希值 |
index索引文件
- 以时间作为文件名
- 一个index存储单元是20个字节定长的
索引文件(Index)提供消息检索的能力,主要在问题排查和数据统计等场景应用
存储单元的结构
| 顺序 | 字段名 | 说明 | | -- | ------------- | ---------------- | | 1 | keyHash(4) | key的hashcode | | 2 | phyOffset(8) | commitLog真实的物理位移 | | 3 | timeOffset(4) | 时间偏移量 | | 4 | slotValue(4) | 下一个记录的slot值 |
消息存储源码解析
commitLog写入
参考:【RocketMQ源码学习】消息存储机制
DefaultMessageStore#putMessage
在RocketMQ的Broker启动时,会初始化一个核心组件messageStore.start();这个组件作为消息的存储组件,负责接受Produce发来的消息并保存到commitLog文件中,这个组件最终会调用DefaultMessageStore类中的putMessage()方法,这个方法是消息存储的核心!
java // DefaultMessageStore#putMessage public PutMessageResult putMessage(MessageExtBrokerInner msg) { // 判断该服务是否shutdown,不可用直接返回【代码省略】 // 判断broke的角色,如果是从节点直接返回【代码省略】 // 判断runningFlags是否是可写状态,不可写直接返回,可写把printTimes设为0【代码省略】 // 判断topic名字是否大于byte字节127, 大于则直接返回【代码省略】 // 判断msg中properties属性长度是否大于short最大长度32767,大于则直接返回【代码省略】 if (this.isOSPageCacheBusy()) { // 判断操作系统页写入是否繁忙 return new PutMessageResult(PutMessageStatus.OS_PAGECACHE_BUSY, null); } long beginTime = this.getSystemClock().now(); PutMessageResult result = this.commitLog.putMessage(msg); // $2 查看下方代码,写msg核心 long elapsedTime = this.getSystemClock().now() - beginTime; if (elapsedTime > 500) { log.warn("putMessage not in lock elapsed time(ms)={}, bodyLength={}", elapsedTime, msg.getBody().length); } // 记录写commitlog时间,大于最大时间则设置为这个最新的时间 this.storeStatsService.setPutMessageEntireTimeMax(elapsedTime); if (null == result || !result.isOk()) { // 记录写commitlog 失败次数 this.storeStatsService.getPutMessageFailedTimes().incrementAndGet(); } return result; }
commitLog.putMessage
在方法内部又会调用commitLog.putMessage(msg)方法,如下:
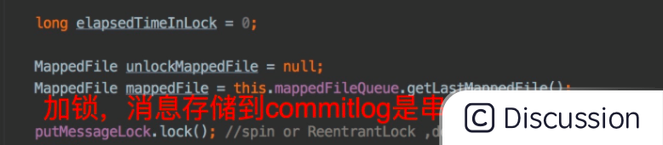
```java public PutMessageResult putMessage(final MessageExtBrokerInner msg) { // Set the storage time msg.setStoreTimestamp(System.currentTimeMillis()); // Set the message body BODY CRC (consider the most appropriate setting // on the client) msg.setBodyCRC(UtilAll.crc32(msg.getBody())); // Back to Results AppendMessageResult result = null; StoreStatsService storeStatsService = this.defaultMessageStore.getStoreStatsService(); String topic = msg.getTopic(); int queueId = msg.getQueueId(); //获取消息的事务类型 final int tranType = MessageSysFlag.getTransactionValue(msg.getSysFlag()); // $1 if (tranType == MessageSysFlag.TRANSACTIONNOTTYPE //对于事务消息中UNKNOW、COMMIT消息,处理topic和queueId, //同时备份realtopic,realqueueId || tranType == MessageSysFlag.TRANSACTIONCOMMITTYPE) { // $2 // Delay Delivery if (msg.getDelayTimeLevel() > 0) { if (msg.getDelayTimeLevel() > this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()) { msg.setDelayTimeLevel(this.defaultMessageStore.getScheduleMessageService().getMaxDelayLevel()); } topic = ScheduleMessageService.SCHEDULETOPIC; queueId = ScheduleMessageService.delayLevel2QueueId(msg.getDelayTimeLevel()); // Backup real topic, queueId MessageAccessor.putProperty(msg, MessageConst.PROPERTYREALTOPIC, msg.getTopic()); MessageAccessor.putProperty(msg, MessageConst.PROPERTYREALQUEUEID, String.valueOf(msg.getQueueId())); msg.setPropertiesString(MessageDecoder.messageProperties2String(msg.getProperties())); msg.setTopic(topic); msg.setQueueId(queueId); } } long elapsedTimeInLock = 0; MappedFile unlockMappedFile = null; //获取最新的mappedFile文件,有可能为空 MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile(); // $3
//给写mappedFile加锁,默认使用的是自旋锁PutMessageSpinLock //AtomicBoolean putMessageSpinLock = new AtomicBoolean(true); //死循环加锁: this.putMessageSpinLock.compareAndSet(true, false); //解锁: this.putMessageSpinLock.compareAndSet(false, true); putMessageLock.lock(); //spin or ReentrantLock ,depending on store config // $4 try { long beginLockTimestamp = this.defaultMessageStore.getSystemClock().now(); this.beginTimeInLock = beginLockTimestamp;
msg.setStoreTimestamp(beginLockTimestamp); //mappedFile为空时创建mappedFile文件, 创建的mappedFile文件offset为0 //文件名是文件大小 if (null == mappedFile || mappedFile.isFull()) { // $5 mappedFile = this.mappedFileQueue.getLastMappedFile(0); } if (null == mappedFile) { log.error("create mapped file1 error"); beginTimeInLock = 0; return new PutMessageResult (PutMessageStatus.CREATEMAPEDFILEFAILED, null); } //在mappedFile中append消息 result = mappedFile.appendMessage(msg, this.appendMessageCallback); // $6 //转换写入结果 switch (result.getStatus()) { // $7 //写入成功直接break case PUTOK: break; //文件剩下的空间不够写了,重新创建一个mappedFile文件, 重新写消息 case ENDOFFILE: unlockMappedFile = mappedFile; mappedFile = this.mappedFileQueue.getLastMappedFile(0); if (null == mappedFile) { log.error("create mapped file2 error"); beginTimeInLock = 0; return new PutMessageResult (PutMessageStatus.CREATEMAPEDFILEFAILED, result); } result = mappedFile.appendMessage(msg, this.appendMessageCallback); break; //msg超过大小统一返回MESSAGEILLEGAL case MESSAGESIZEEXCEEDED: //properties超出大小统一返回MESSAGEILLEGAL case PROPERTIESSIZEEXCEEDED: beginTimeInLock = 0; return new PutMessageResult(PutMessageStatus.MESSAGEILLEGAL, result); //未知错误,返回错误类型 case UNKNOWNERROR: beginTimeInLock = 0; return new PutMessageResult(PutMessageStatus.UNKNOWNERROR, result); default: beginTimeInLock = 0; return new PutMessageResult(PutMessageStatus.UNKNOWNERROR, result); } elapsedTimeInLock = this.defaultMessageStore .getSystemClock().now() - beginLockTimestamp; beginTimeInLock = 0; } finally { //解锁 putMessageLock.unlock(); } if (elapsedTimeInLock > 500) { log.warn("[NOTIFYME]putMessage in lock cost time(ms)={}, bodyLength={} AppendMessageResult={}", elapsedTimeInLock, msg.getBody().length, result); } if (null != unlockMappedFile && this.defaultMessageStore.getMessageStoreConfig().isWarmMapedFileEnable()) { this.defaultMessageStore.unlockMappedFile(unlockMappedFile); } PutMessageResult putMessageResult = new PutMessageResult(PutMessageStatus.PUTOK, result); // Statistics storeStatsService.getSinglePutMessageTopicTimesTotal(msg.getTopic()).incrementAndGet(); storeStatsService.getSinglePutMessageTopicSizeTotal(topic).addAndGet(result.getWroteBytes()); //执行刷盘 handleDiskFlush(result, putMessageResult, msg); // $8 //执行主从同步 handleHA(result, putMessageResult, msg); // $9 return putMessageResult; } ```
进入commitLog类中的putMessage()方法,方法中先对延时消息进行处理。
然后拿到虚拟内存中的文件(使用零拷贝实现),使用顺序写入的方式把消息追加到虚拟内存里,
在追加时使用lock保证同时只有一个线程往OScache内存写入消息!
mappedFile.appendMessage方法中是真正的写入逻辑
进入mappedFile.appendMessage方法中看一下具体的写入逻辑:就是包装消息的各种附加信息,例如msgId、offset等等,并把这些信息一并写入虚拟内存
由于CommitLog文件有1G的大小限制,当虚拟内存中的CommitLog被写满时,会创建一个新CommitLog文件继续写入。写入的只是虚拟内存,还要进行文件刷盘和主从同步
分发ConsumeQueue和IndexFile
Broker启动时会启动一个消息存储的核心组件messageStore。当CommitLog写入一条消息后,在DefaultMessageStore的start方法中,会启动一个后台线程reputMessageService每隔1毫秒就会去拉取CommitLog中最新更新的一批消息,然后分别转发到ComsumeQueue和IndexFile里去。
过期文件删除
默认情况下, Broker会启动后台线程,每60秒,检查CommitLog、ConsumeQueue文件。然后对超过72小时的数据进行删除。也就是说,默认情况下, RocketMQ只会保存3天内的数据。这个时间可以通过fileReservedTime来配置。注意删除时,并不会检查消息是否被消费了。
刷盘机制
我们之前简单提过一次,写入CommitLog的数据进入到MappedFile映射的一块内存里之后,后续会执行刷盘策略 比如是同步刷盘还是异步刷盘,如果是同步刷盘,那么此时就会直接把内存里的数据写入磁盘文件,如果是异步刷盘,那么就是过一段时间之后,再把数据刷入磁盘文件里去 那么今天我们来看看底层到底是如何执行不同的刷盘策略的。 大家应该还记得之前我们说过,往CommitLog里写数的时候,是调用的CommitLog类的putMessage0这个方法 没错的,其实在这个方法的末尾有两行代码,很关键的,大家看一下下面的源码片段.
大家会发现在末尾有两个方法调用,一个是handleDishFlush0,一个是handleHA0 顾名思义,一个就是用于决定如何进行刷盘的,一个是用于决定如何把消息同步给Slave Broker的。 关于消息如何同步给Slave Broker,这个我们就不看了,因为涉及到Broker高可用机制,这里展开说就太多了,其实大家有兴趣可以自己慢慢去研究,我们这里主要就是讲解一些RocketMQ的核心源码原理。 所以我们重点进入到handleDiskFlush0方法里去,看看他是如何处理刷盘的。

刷盘即存盘,刷盘机制是指生产者生产消息到rocketMQ后存入硬盘的方式,RocketMQ需要将消息存储到磁盘上,这样才能保证断电后消息不会丢失。同时这样才可以让存储的消息量可以超出内存的限制。RocketMQ为了提高性能,会尽量保证磁盘的顺序写。消息在写入磁盘时,有两种写磁盘的方式。
同步刷盘:只有在消息真正持久化至磁盘后,RocketMQ的Broker端才会真正地返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用领域。
异步刷盘:能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
异步和同步刷盘的区别在于,异步刷盘时,主线程并不会阻塞,在将刷盘线程唤醒后,就会继续往下执行。
上面代码我们就看的很清晰了,同步刷盘的策略是如何处理的.

其实上面就是构建了一个GroupCommitRequest,然后提交给了GroupCommitService去进行处理,然后调用request.waitForFlush0方法等待同步刷盘成功 万一刷盘失败了,就打印日志。具体剧盘是由GroupCommitService执行的,他的doCommit0方法最终会执行同步刷盘的逻辑,里面有如下代码。

上面那行代码一层一层调用下去,最终刷盘其实是靠的MappedByteBuffer的force0方法,如下所示

这个MappedByteBuffer就是JDK NIO包下的API,他的force0方法就是强追把你写入内存的数据刷入到磁盘文件里去,到此就是同步刷盘成功了 那么如果是异步刷盘呢? 我们先看CommitLog.handleDiskFlush里的的代码片段

其实这里就是唤醒了一个flushCommitLogService组件,那么他是什么呢?
FlushCommitLogService其实是一个线程,他是个抽象父类,他的子类是CommitRealTimeService,所以真正唤醒的是他的子类代表的线程。

具体在子类线程的run0方法里就有定时刷新的逻辑,这里就不赘述了。
其实简单来说,就是每隔一定时间执行一次刷盘,最大间隔是10s,所以一且执行异步刷盘,那么最多就是10秒就会执行一次刷盘。
好了,到此为止,我们把Commitlog的同步刷盘和异步刷盘两种策略的核心源码也讲解完了。我们主要是讲解的核心 源码,而源码里很多细节不可能一行一行进行分析,大家可以顺着文中的思路继续探究
主从复制
如果Broker以一个集群的方式部署,会有一个master节点和多个slave节点,消息需要从Master复制到Slave上。而消息复制的方式分为同步复制和异步复制。
同步复制: 同步复制是等Master和Slave都写入消息成功后才反馈给客户端写入成功的状态。在同步复制下,如果Master节点故障,Slave上有全部的数据备份,这样容易恢复数据。但是同步复制会增大数据写入的延迟,降低系统的吞吐量。
异步复制: 异步复制是只要master写入消息成功,就反馈给客户端写入成功的状态。然后再异步的将消息复制给Slave节点。在异步复制下,系统拥有较低的延迟和较高的吞吐量。但是如果master节点故障,而有些数据没有完成复制,就会造成数据丢失。
配置方式如下:

参考链接:https://blog.csdn.net/qq_45076180/article/details/113806763
mq消息存储相关链接
深入研究一下Broker是如何持久化存储消息
32张图带你解决RocketMQ所有场景问题
putMessage为什么要加锁
broker处理消息commit时加锁应该使用自旋锁还是重入锁
![[工业互联-14]:机器人操作系统ROS与ROS2是如何提升实时性的?](https://img-blog.csdnimg.cn/6075dbd7249e4ee88541cf1ef5e25fce.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5oiR5LiObmFubw==,size_20,color_FFFFFF,t_70,g_se,x_16)