上篇文章说了逃逸分析和标量,代码实例解析了内存分配先从eden区域开始,当内存不足的时候,才会进入s0和s1,发生yangGC,之后大内存会放入old,因为我们昨天程序运行了一个45M的对象,于是小对象在eden,对象在老年代。
Jvm创建对象之内存分配-JVM(七)
- 大对象直接进入老年代
大对象指需要连续空间存储的对象(字符串,数组)。正常是eden放不下进入老年代,但是我们也可以用参数配置,当大于这个参数直接进入老年代。
-XX:PretenureSizeThreshold=1000 -XX:+UseSerialGC
只有Serial和ParNew垃圾收集器才生效的。

记得参数后面还有加个打印gc的参数-XX:PrintGCDetails
当我们设置了这个参数之后,则看到一个7M的数据明明可以放在eden,但是直接进入了老年代,前面的百分之14并不是我们代码的7M对象,而是eden自己内部的对象。
有什么优点呢?
可以避免大对象内存gc复制操作而降低效率。
- 长期存活的也会进入老年代
既然是分代思想管理的,就必须知道对象哪些属于老年代,哪些属于年轻代,于是每个对象都有他的年龄。
如果对象eden经过第一次yangGc还能存活,并且被survivor容纳,则会进入survivor,这时候年龄会随着每次复制移动而增长,当年龄到了15岁(默认是15,CMS收集器默认6岁),就会进入老年代。
可以通过参数配置年龄代-XX:MaxTenuringThreshold
- 对象动态年龄判断机制
我们有一个对象在eden,当yangGC后,状态还是活跃状态,则会进入survivor,但也会有一种情况直接进入老年代。
当一批对象大于等于survivor的百分之50,这时候则会把survivor里大于等于1年龄代的对象全部都移动到老年代里去,这样做的目的也是为了减少存活时间长的对象避免太多的复制移动。
- 场景实例
- 亿级流量电商(每日点击上亿次)
- 如果平均每个用户点击二三十次,那么就有500万个日活用户。
- 付费转换率是百分之10,那就是每天50万单子
(如果是正常三四小时内完成,那么每秒几十订单影响不大)
- 但如果高峰场景,每秒1000订单
(订单系统是4核8G,300单每秒,三台机器)
假设订单表几十个字段,阿里巴巴规范表字段不可以太多,每个订单有300个字,大概1KB。
- 那么300单*1KB = 300kb,每秒300KB
下单还能涉及到其他对象,比如库存,优惠卷,积分等。
6、300kb*20*10 = 60000 KB每秒
(每秒大概60M进入eden,这60M对象大概会在1s都会变成垃圾对象)
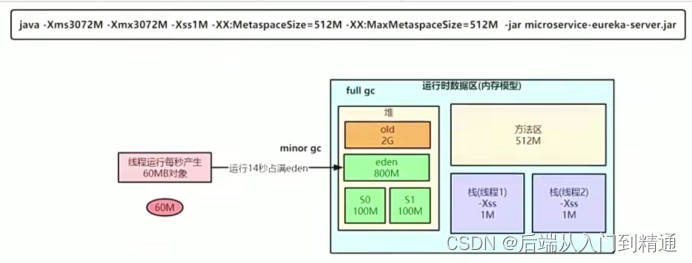
可以通过命令指定堆位3G,对最大值也3G,栈帧1M,元空间512M。
Java -Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=512M
-XX:MaxMetasspaceSize=512M -jar microservice-sureka.jar
这时候知道通过亿级流量日活大概有60M的数据进入eden,14s的60M就会占满我们的eden,满了则会yangGC,这时候前面13s的对象都会被垃圾回收,因为他是垃圾对象,因为回收的时候会STW(stop the word),导致最后1s的还没被回收,这时候eden因为对象动态年龄判断机制,直接进入了old,在old里1s后就属于垃圾了,之后old满之后则会发生fullGC,很明显,这样频繁发生fullGC是不合理的。
所以我们设置jvm参数是要根据实际情况来设置的,那么这种怎么设置呢?
Java -Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=512M -Xmn2048
-XX:MaxMetasspaceSize=512M -jar microservice-sureka.jar
这时候会发生什么呢?
老年代只剩下1个G,年轻代有2个G,那么eden就是1.6G,S0和S1都是200M。
这时候则能放的下S0,不会触发动态年龄判断,这时候则会直接在SURVIVOR会回收,不会进入老年代。