Redis【实战篇】---- UV统计
- 1. UV统计 - HyperLogLog
- 2. UV统计 - 测试百万数据的统计
1. UV统计 - HyperLogLog
首先我们搞懂两个概念:
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
通常来说UV会比PV大很多,所以衡量同一个网站的访问量,我们需要综合考虑很多因素,所以我们只是单纯的把这两个值作为一个参考值
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖,那怎么处理呢?
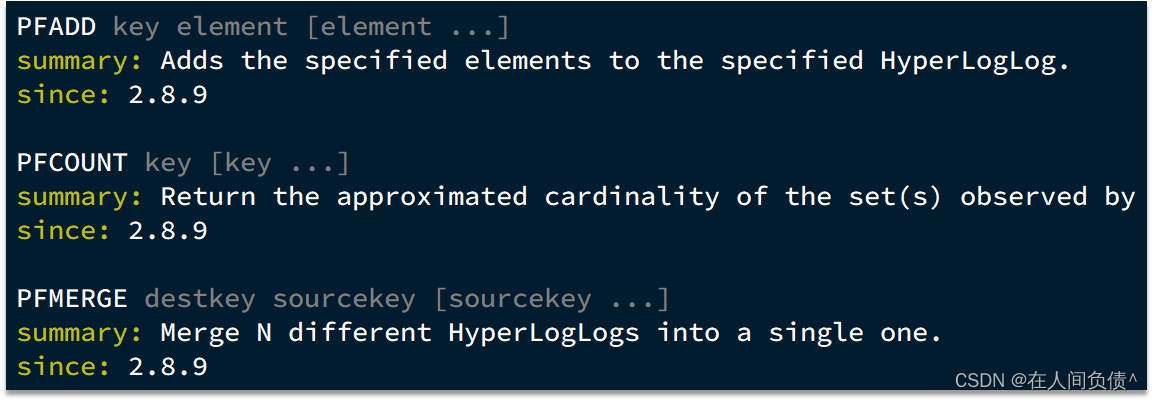
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
2. UV统计 - 测试百万数据的统计
测试思路:我们直接利用单元测试,向HyperLogLog中添加100万条数据,看看内存占用和统计效果如何
@Test
void testHyperLogLog() {
String[] users = new String[1000];
int index = 0;
for (int i = 1; i <= 1000000; i++) {
users[index ++ ] = "user_" + i;
if (i % 1000 == 0) {
index = 0;
stringRedisTemplate.opsForHyperLogLog().add("hl2", users);
}
}
Long size = stringRedisTemplate.opsForHyperLogLog().size("hl2");
System.out.println("size = " + size);
}






![[Vue3]学习笔记-provide 与 inject](https://img-blog.csdnimg.cn/ee9936c7992344bda5b458dc662540eb.png)

