作者 | 小戏、Python
标题生成,乍一看似乎并不是一个复杂的任务,要数据简单的爬虫就可以获得许多标题-文本对,要评价通过用户点击与浏览的次数就多少可以区分“好标题”与“坏标题”,万事俱备使用一些经典的监督学习方法似乎就可以将这个问题完美解决。然而,目前现有的标题生成器似乎都不那么尽如人意,先不说有没有恰如其分的总结文章的核心内容,单是几乎套用固定标题党的夸张句式一点就让人们失去了使用甚至是参考的欲望。

大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
如果仔细分析一下,一个真正好的标题,首先要符合原文符合实际,抓住原始文章的亮点,其次还需要具有吸引力,让读者有打开进行阅读的动力。而回顾传统的标题生成方法,如果是基于阅读量进行标题好坏的评判,很容易使得模型被一些假信号所误导,比如“台风临近,航班取消”这种标题虽然阅读量很高但是并不通用于一般文章的标题起名思路,而更为严重的挑战可能是模型开始模仿“标题党”从而生产假新闻,扭曲原始文章的本意甚至传播虚假与错误的信息。
面对这样一些问题,来自北卡罗来纳大学教堂山分校等高校的研究者们提出了一个新颖的标题生成框架 HonestBait,使用 Forward References(FRs) 完成标题生成,并给出了一个包含假新闻与真新闻的数据集 PANCO1,在利用假新闻标题党标题吸引人的风格的同时,生成忠于原文的标题。在实验中,HonestBait 对比人工生成的标题产生出了更加具有吸引力(+11.25%)的标题。
论文题目:
HonestBait: Forward References for Attractive but Faithful Headline Generation
论文链接:
https://arxiv.org/pdf/2306.14828.pdf
Forward References
Forward References 是一种借鉴心理学与新闻学研究用于生成有吸引力标题的方法,具体而言,Forward References 方法的核心思想就是利用标题为读者与新闻内容之间创造信息缺口,以激发读者的阅读兴趣,譬如标题“想要成为令人羡慕的一对吗?12件幸福夫妇必做的事情…就是这么简单!”驱使读者想要了解需要做的事情是什么。从类型上讲,FR 可以被分为以下几种类型:
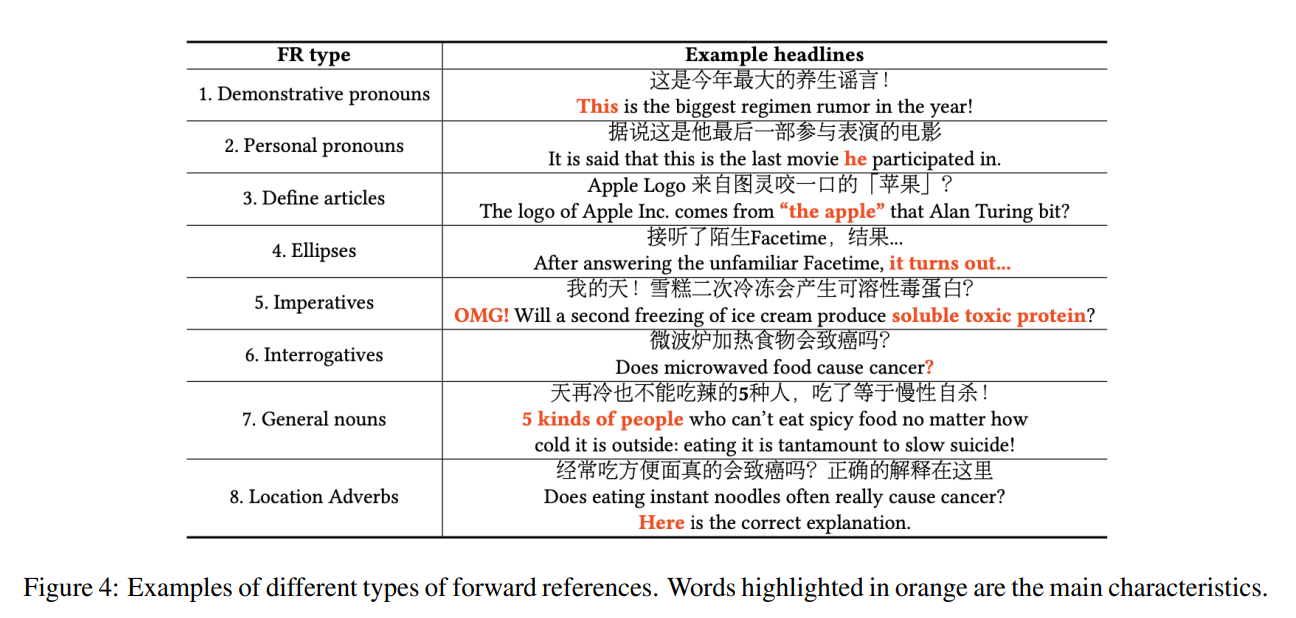
而标题党的假新闻为什么会在网络上大量传播呢?某种程度上讲,相比沉闷的叙述文章的主题观点,标题党更能激发读者的阅读兴趣,基于这种想法,作者提出了两个假设:
- H1:假新闻标题比真实新闻的标题更能激发读者的阅读兴趣;
- H2:在引起读者兴趣的标题中,大量使用了 Forward References 方法
为了验证这两个假设,作者在中文与英文新闻中进行了实证研究,对于英文新闻,论文使用了 FakeNewsNet,一个包含政治与八卦新闻的假新闻数据集,在中文新闻中,作者使用了 WSDM 假新闻挑战数据集。并在亚马逊的众包数据平台 Mechanical Turk 中进行了用户研究,对 H1,论文抽取两个标题,设计了包含四个选项的选择题要求标注者选出希望进一步阅读的标题(标题1,标题2,二者皆是,二者皆不想阅读),对于 H2,作者随机从 H1 中抽样了 1000 道被选择与被拒绝的标题,要求标注者标注出使用了 Forward References 方法的标题。

用户研究的结果显示,中英文读者都更加喜欢假新闻的标题,在中文中有 39.75% 的假标题被判定为比真标题更有趣,而认为真标题更有吸引力的只有 23.60%,在英文中,这一比例为 34.57% 与 30.33%,统计学的假设检验也支持了假设1成立。而对于 H2,在被接受的标题中有 73.48% 与 85.32% 的标题都使用了 Forward References,而在被拒绝的标题中,比例为 22.35% 与 17.72%,这表明标题是否具有吸引力与是否使用 Forward References 方法相关。
HonestBait
在验证了 FRs 的有效性后,论文提出了 HonestBait 框架,HonestBait 框架结合了 FRs 技术与真实性验证,总的而言,HonestBait 框架包含两个阶段,在阶段1,通过预训练一个 FRs 预测器和一个 FRs 生成器来生成一个标题,预测器用来判断标题是否包含 FRs 结构,而生成器则用于生成对应的 FRs 要素的组合,第一阶段的主要目标在于从假新闻中学习到 FRs 的结构,用于对真实新闻标题进行重写。
阶段2 则是 HonestBait 框架的核心,用于真正生成具有吸引力而又真实的标题,第二阶段如下图所示,其输入为真实新闻的内容,通过一个 Pointer Network 输入真实新闻的内容输出新闻的标题,再利用 FRs 预测器与 FRs 生成器以 FR 类型奖励的方式对生成的标题进行重写,在完成重写后,阶段2 又集成了真实度评分器与轰动性评分器以计算真实度与轰动程度,最终以使得模型生成期望的标题。

FRs 预测器与 FRs 生成器都使用 BERT 网络进行实现,序列生成器论文使用了 Pointer Network,而作为核心的 FR 类型奖励重写,则在当前时间步使用 FRs 预测器与 FRs 生成器计算平均的 FR 奖励,FR 奖励公式如下:
R f r = 1 T ∑ i T ( 1 − D ( y ^ f , y ^ r 1 : i ) ) R_{fr}=\frac{1}{T}\sum_{i}^{T}(1-D( \hat{y}_f,\hat{y}_r^{1:i})) Rfr=T1i∑T(1−D(y^f,y^r1:i))
其中 D 代表一个计算距离的均方差函数, y ^ r \hat{y}_r y^r 表示由预测器给出的 FR 类型,当其与生成器给出的 y ^ f \hat{y}_f y^f 越接近时, R f r R_{fr} Rfr 越高。在得到奖励之后,论文使用强化学习方法训练模型,最终的奖励和目标函数如下所示:
R = R f r + α R f a i t h + ( 1 − α ) R s e n L R L = − 1 T ∑ i T ( R − R ^ t ) l o g P f i n a l ( y t ) . R=R_{fr}+\alpha R_{faith}+(1-\alpha)R_{sen} \\ L_{RL}=-\frac{1}{T}\sum_{i}^{T}(R-\hat{R}_t)logP_{final}(y_t). R=Rfr+αRfaith+(1−α)RsenLRL=−T1i∑T(R−R^t)logPfinal(yt).
实验结果
作者收集了“Paired News with Content(PANCO)”数据集,共计包含 7930 个真/假新闻对以及其对应的 FR 类型,数据集的一个小例子如下图所示:
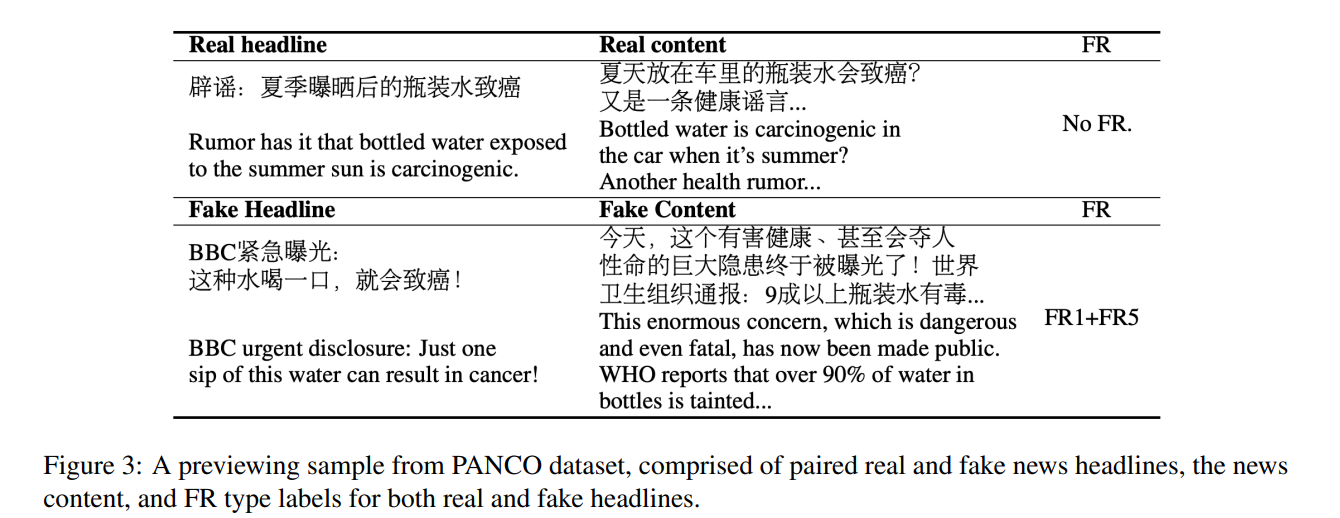
首先,作者对比几种主流的可以完成标题生成任务的模型进行了对比试验,几个对比模型以及 HonestBait 框架生成的标题直观如下,可以看到 HonestBait 框架更加准确与精准的理解了新闻的意思,并以 FRs 的模式生成了一个比较成熟的标题:

同时,作者又对 HonestBait 框架以及其他对比模型生成的标题进行了一项人工评估,评估生成标题的吸引力、真实度以及流畅程度,作者从 PANCO 数据集中随机选择了 100 个样本,要求志愿者根据以下准则进行标题选择:(1)哪个标题使你想要进一步阅读?(2)哪个标题更符合文章内容?(3)哪个标题更加流畅?人工评估的结果如下表所示:

从上表可以看到,无论是在吸引力还是真实度方面,HonestBait 框架都比其余所有对比模型表现出色(包括人类生成的标题),在流畅性方面,也仅有 ProphetNet 与人类编写的标题超过了 HonestBait 框架。

而如果使用类似 ROUGE-n、ROUGE-L、BERT score 等评估指标,HonestBait 框架也展现了良好的性能,在 R 2 , R L R_2,R_L R2,RL 中都取得了最高的得分,而值得注意的是作者使用 FR 预测器监测是否生成标题包含 FRs 结构,上表显示由 HonestBait 生成的标题中有 80.42% 都使用了 FRs 结构。
结论与讨论
这篇论文通过深入考虑“一个好的标题应该包含什么东西”这一问题,不再简单的把神经网络当作一个输入输出的黑箱丢入监督数据获得结果,而是从一个问题本身出发借助对问题的理解去解决标题生成这一问题。同时对假新闻标题的研究以及借助假新闻标题提取“有吸引力”的标题的结构的想法也十分新颖,另辟蹊径的利用了假新闻的数据。
不过虽然这些标题党的标题都十分符合 FRs 的规则,但是当“想要成为令人羡慕的一对吗?12件幸福夫妇必做的事情…就是这么简单!”这种模式的标题欺骗我们许多次以后,可能作为用户或读者并不会有想点开推文的想法,真正好的标题除了这些“套路”以外,还是需要一些天马行空和奇思妙想支持的吧!
大模型AI全栈手册
行业首份AI全栈手册开放下载啦!!
长达3000页,涵盖大语言模型技术发展、AIGC技术最新动向和应用、深度学习技术等AI方向。
微信公众号关注“夕小瑶科技说”,回复“789”下载资料
![[图片]](https://img-blog.csdnimg.cn/dd8812ed0c7b414880fe1a79e6db956e.png)



![[期末网页作业]-小米官网(html+css+js)](https://img-blog.csdnimg.cn/2427fd4b89e840c5b4d1bb9992762837.png)