在Python 的pandas.DataFrame中有一种操作,它可以大大减轻我们的工作量,方便我们更快地进行数据分析,加快处理工作的效率。这就是
.apply(pd.value_counts)
pandas 的强大,越使用,也就越爱了。现在就来夸夸它的作用啦!
.apply(pd.value_counts)它会对DataFrame中的每一列进行操作,并对每一列中的不同值进行计数。返回值时一个新的DataFrame,其中包含每列不同值出现的次数。
来个实例,看一下吧
import pandas as pd
# 创建一个示例DataFrame
data = {
'A': ['小米', '小张', '小磊', '小米', '小康'],
'B': ['小龙', '小李', '小李', '小康', '小张'],
'C': ['小朱', '小文', '小磊', '小李', '小朱']
}
df = pd.DataFrame(data)
print(df)
# 统计每列的不同值出现的次数
value_counts = df.apply(pd.value_counts)
print(value_counts)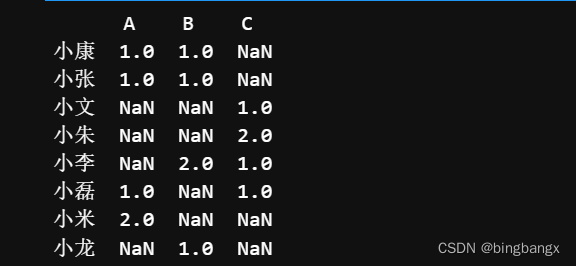
完美~