写在前面
论文 Improving Language Understanding by Generative Pre-Training
地址 https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
ChatGPT火了,改论文作为ChatGPT的前身,可以从这里看到ChatGPT的原始影子。
摘要
自然语言理解(NLU)涵盖众多不同的任务,比如文本蕴含、问答、语义相似判断及文本分类。虽然大量未标注文本集很丰富,但是标注预料却特别少,训练的模型想要表现出色很具挑战性。我们将展示通过在各种(任务)未标注预料上预训练大语言模型,随后各任务有针对性的微调,来实现在这些任务上都达到很好效果。和其他任务不同,我们在微调阶段使用任务级别的输入来达到很好的效果,与此同时要求模型结构做最小的改动。我们证实在众多NLU任务中,我们的方案取效果显著。我们通用的模型由于那些使用特定结构达到各任务目标的训练模型,特别在研究的12个任务中,有9个达到了SOTA。
简介
在NLP中,在原始文本上高效的学习能力对于减少对于监督学习的依赖是至关重要的。大多数深度学习方法需要大量的人工标注数据,这就制约了它们在许多缺乏标注资源的领域的能力。在这些场景下,比耗时耗力的标注,能从未标注数据中得到语言信息的模型提供了巨大价值。甚至在那些有监督的场景下,无监督方式的学习表现也能提供显著的效果提升。截至目前大量案例使用了预训练词/字Embedding来提升众多NLP效果。
然而,在未标注文本上学习词/字信息之外的其他信息是极具挑战的,主要有以下两个原因。第一,文本表征学习中最有效的是已不是知道优化目标类型是什么,但(在未标注文本上)是不清晰的。近期的研究已经着眼于多目标,比如语言模型、机器翻译和篇章一致,在不同任务上每个方法都优于其他方法(说明每个方法都不具备通用性)第二,在将学到的表征转换成能目标任务的有效方法上没有一个共识。已有的技术方案涉及多个的组成结构:迎合模型结构的特定任务、使用复杂的学习结构以及增加额外的学习目标。这些不确定因素使得研发有效地针对语言处理的半监督学习方法变得很困难。
本文针对NLU任务提出一个半监督方法:无监督预训练+有监督微调。我们的目标是学习一个通用表征的迁移,它可以在各种任务上只做小调整(即可达到好的效果)假设我们有大量未标注预料,以及多个人工标注训练集(目标任务)。我们不要求这些目标任务和未标注预料必须要在同一领域。我使用两个训练阶段。首先,我们使用一个语言模型在未标注预料上学习神经网络的初始参数。继而,我们使用相应的监督目标来调整这些参数以适用目标任务。
我们使用Transformner作为我们的模型结构,它已经在多个任务上表现出色,比如:机器翻译、文本生成、语法分析。模型为了提供了结构化存储用于解决文本上的长依赖问题,相较于之前的研究,在各种任务中体现除了鲁棒性。在迁移学习中我们利用源于遍历思想的特定任务输入适应方法,将结构化文本数输入处理为单一且连续的token序列。正如我们的实验证明,这些适应方法使得在预训练模型结构极小改变的同时,可以有很出色的微调效果。
本文在4中NLU任务(自然语言推理、问答、语义相似、文本分类)上,评估我们的方法。我们通用的模型由于那些使用特定结构达到各任务目标的训练模型,特别在研究的12个任务中,有9个达到了SOTA。比如,我们比常识推理(Stories Cloze Test)任务绝对提高8.9%,问答(RACE)任务提升5.7%,在文本蕴含(MultiNLI)任务上提升1.5%。我们也分析了预训练模型的零样本能力,并且证实它获得了对下游任务有价值的语言知识。
相关研究
NLP的半监督学习 我们的研究内容属于自然语言半监督学习中的一类。该范式已经引起极大关注,且在序列标注和文本分类上得到应用。最早期的方法使用未标注数据,来计算字级别或者短语级别的统计,该统计结果被当做监督模型的特征。再过去的几年里,研究人员已经证实,未标注数据训练得到的word Embedding有助于提升各种任务的效果。然而,这些方法主要获取到的是字级别信息,而我们旨在获得更高级别的语义信息。
近期的方法,在未标注数据中学习和利用比字级别语义更多的信息做了研究。从未标注预料训练得到的短语级别或者句子级别的embedding,在多种任务上已被用于将文本编码成合适的向量表征。
半监督预训练 半监督预训练是半监督学习领域一个特例,它的目标是找到一个不错的初始点,而非修改有监督学习目标。早期在图片分类和回归任务上,使用了该技术。后来研究证实,预训练在深度网络中充当了一个有更好生成能力的通用方案。在近期的研究工作中,该方法在各种任务中被应用于训练深度神经网络,包含图片分类、语音识别、实体消歧和机器翻译。
和我们工作最接近的就是:使用语言模型目标预训练一个神经网络,然后有监督微调目标任务。Dai et al.和 Howard and Ruder使用这一方法提升了文本分类。虽然预训练阶段对于获取语言信息有所帮助,但是他们使用的LSTM方法限制了预测能力。与之相反,我们选择的transformer网络可以捕获更大范围的语言结构,这一点在我们的实验中可以得到证实。进一步,我们还证明了我们的模型在众多任务重表现出色,这些任务包含自然语言推理、释义检测、以及故事续成。其他的方法使用从预训练模型或者机器翻译模型中获取的隐藏层表征作为辅助特征,然后有监督的训练一个目标任务。这样在每个不同的目标任务中,包含了大量新参数,我们需要在迁移时,对我们的模型结构做极小改动。
辅助训练目标增加辅助无监督学习目标是半监督学习一个替换的方法。在Collobert 和 Weston 早期的工作中,使用了许多辅助NLP任务,比如:词性标注、词块分析、命名实体识别以及提升语义角色标注的语言模型。近期,Rei在任务目标上增加了辅助语言模型目标,并证实在序列标注任务中表现优异。我们的实验也使用了辅助目标,但如我们展示的,无监督与旋律已经学习到了和目标任务相关的语言信息。
模型架构
我们的训练过程有两个阶段组成。第一阶段,在大规模文本预料上学习一个包罗万象的语言模型。第二阶段就是微调阶段,在标注数据上我们调整模型来适应特定任务。
无监督预训练
给定无监督预料,其token集为
U
=
u
1
,
.
.
.
,
u
n
U={u_1, ..., u_n}
U=u1,...,un我们是用一个标准的语言模型来最大化以下似然函数
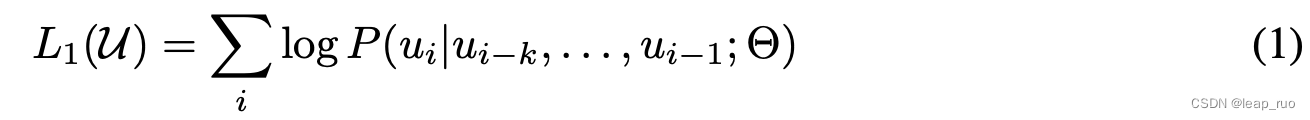
其中k是上下文窗口,条件概率P为使用参数为Θ的神经网络建模后得到。这些参数通过随机梯度下降(SGD)来训练。
在我们的实验中,我们的语言模型使用多层transformer decoder,改语言模型是transform的变种。该模型在输入上下文上应用多头自主力机制,然后在位置前向反馈层生成目标token的输出分布:

其中, U = ( u k , . . . , u 1 ) U=(u_k, ..., u_1) U=(uk,...,u1)是token的文本向量,n是网络层数, W e W_e We是token embedding矩阵, W p W_p Wp是位置embedding矩阵。
有监督微调
使用公式1的目标函数训练之后,我们根据有监督目标任务来调整参数。假设标注数据集
C
C
C,其中每一个样本是输入token序列,
x
1
,
.
.
.
,
x
m
x^1, ..., x^m
x1,...,xm,以及标签
y
y
y。该输入会通过预训练模型得到最终transformer的激活函数
h
l
m
h_l^m
hlm,紧接着喂入附加的线性输入层(其参数举证为
W
y
W_y
Wy)来预测
y
y
y。

这给出以下目标函数并最大化:

我们还发现将语言模型作为微调的辅助目标函数有助于:提高有监督模型的泛化能力;加速收敛。这与先前工作 [50, 43]结论是一致的,先前工作还观察到,使用这个辅助目标函数可提升效果。具体来说,我们优化一下目标函数(权重参数
λ
\lambda
λ):

总之,微调期间只需要额外参数 W y W_y Wy,以及对分隔符做embedding(下一小节)。
特定任务的输入迁移
对于文本分类一类的任务,我们可以直接按照如上描述直接微调模型。像问答、文本蕴含之类的其他任务,将输入结构化为一个有序的句子对或者由文档、问题、答案组成的三元组。由于预训练模型在连续的文本序列上训练,因此我们需要做一些改动以让模型适用那些任务。先前工作在迁移表征的基础上提出了学习任务特定的架构。这种方案再次引入了大量的定制化工作,且那些新增的结构模块没有做迁移学习。与它们不同,我们使用了traversal-style 方法,将结构化输入转化成了预训练模型可处理的有序序列。这些迁移输入使我们避免了在跨任务时做大量结构改造。如图1所示,我们给出了以下迁移输入的简述。所有的迁移内容包含了增加随机初始化的起始token和结束
t
o
k
e
n
s
(
<
s
>
,
<
e
>
)
tokens(<s>, <e>)
tokens(<s>,<e>)。

文本蕴含 对于文本蕴含任务,我们将前提P和假设H的token序列拼接起来,并用$在中间作为分隔符。
相似 对于相似任务,两个比较的句子不需要固定顺序。为证明这点,我们将两个句子的位置对调(中间仍有分隔符),分别处理并生成两个句子的表征HML—在喂给线性输层之前element级别添加
问答和尝试推理 对于这类任务,给定文章z,问题q和备选答案集合{ak}。我们将文档、问题以及每个答案拼接起来,中间加上分隔符得到[z;q;$;ak]。每序列都通过我们的模型独立处理,然后在softmax层归一化,针对可能得答案生成输出分布。
实验
实验设置
无监督预训练 我们使用BooksCorpus数据集训练语言模型。数据集包含7000多唯一为出版的书,这些书涉及多种题材:冒险、科幻、浪漫。重要的是,它包含连续长文本,这使得生成模型可以学习到长信息下的条件设置。另一个数据集,有1B单词,使用方法类似。大小一致但是句子被打乱,这就损坏了长信息结构。我们的语言模型在这个语料库上,取得了非常低的token级别的困惑度18.4
模型配置 我们的模型很大程度上沿用原始transfomer的工作。只训练12层decoder,使用mask的自注意力头(768维和12注意力头)。对于位置前向反馈网路,使用3072维(内部状态)。使用最大学习率为2.5e-4的Adam优化策略。经过2000次更新,学习率从0线性增长,并使用余弦退火至0.我们在最小batch上训练100epoch,该batch随机抽取64个512token的连续序列。由于layernorm在模型中使用广泛,因此,服从N(0,0.02)的简单权重初始化已经足够了。我们使用40000BPE词表、残差、embedding及0.1注意力dropouts率来做正则。我们使用参考文献37提到的L2正则,即在非偏移或新增权重上设置w=0.01。使用GELU作为激活函数。我们使用位置Embedding取代之前研究工作提到正弦版本。使用ftfy library2来清洗BooksCorpus原始文本,标准化标点符号和空格,并使用spaCy分词器。
微调细节 除非指定,否则微调复用无监督预训练的超参。给分类器增加0.1dropout率。对于大多数任务,学习率使用6.25e-5,batchsize使用32.大部分情况下,模型微调很快并且训练3个epoch就足够了。使用线性学习率衰减,预热数据比训练阶段超0.2%,入设置为0.5.
有监督微调
我们在多种有监督任务上执行实验,这些任务包含:自然语言推理(NLI)、问答、语义相似和文本分类。其中一些任务可作为我们使用的最近发布的GLUE多任务基准的一部分。图1提供了所有任务和数据集的总览。

自然语言推理 NLI任务也被任务是文本蕴含识别,包含读入句子对并判断是蕴含、矛盾或者中立关系。虽然近期很多人对这些任务感兴趣,但是由于各种各样的(问题)现状他们仍然面临挑战,这些问题包含词义蕴含、指代关系、词语和语法歧义。我们在来源多样的5个数据集上做评测,包括图像说明(SNLI)、转录语音、流行小说和政府报告(MNLI)、维基百科文章(QNLI)、科学考试(SciTail)或新闻文章(RTE).
表2详细说明了我们模型和之前SOTA方案在不同NLI任务上的各种效果。我们的方法在4个数据集(共5个)上效果相当出色。相较于以往各任务最好效果,MultiNLI任务上提升1.5%,在SciTail上提升5%,QNLI上5.85,以及SNLI0.6%。这表明我们的模型有更好的解决多句子推理能力以及更强的解决语义歧义问题。在RTE(我们评估2490个样本中最小的数据集之一)上,我们获取56%的准确率,低于多任务BiLSTM模型的61.7%。鉴于我们的模型在更大NLI数据集上表现出色,好像我们的模型可以受益于多任务训练,但是目前我们并没有探索到这点。


问答与常识推理 另一个需要单一或者多个句子推理的任务是问答任务。我们使用了最近发布的RACE数据集,该数据集由带有相关问题的英文短文组成,这些英文短文来自初中和高中试卷中。该数据集相较于CNN和SQuaD数据集包含更多的推理类型问题,且为我们(可解决长文本情况)的模型提供了很好的评估。此外,我们还在Story Cloze Test数据集上评估,该数据集包含为多句文本在两个选项中选择正确的结尾。在这些任务上,我们的模型以显著优势超越之前最好结果,在故事续成提升8.9%,RACE提升5.7%。这表明我们模型有出色的长文本处理能力。
语义相似 语义相似(语义检测)任务预测两个句子是否相似。这些挑战依赖于识别同义改写、理解否定、解决语义歧义。针对这类任务,我们使用三个数据集:MRPC、QQP和STS-B。我们在2个语义相似任务(共3个)上取到了SOTA效果,其中在STS-B上绝对值提升了一个百分点。在QQP上效果提升显著,相较于单一任务BiLSTM+ ELMo+Attn绝对值提升4.2个百分点。
分类 最后我们也在两个文本分类任务做了评估。CoLA(语言可接受性语料库)包含语句语法是否正确的专家判断,以及训练模型是否有语义偏移的测试。另一方面,SST-2(斯坦福情感树库)是一个标准的二分类任务。在CoLA上我们模型取得了45.4分,相较于之前最好成绩35分已经是一个巨大的进度,展示出我们模型学习到的先天语言偏移。在SST-2上准确率达到91.3%,这一效果可与SOTA相媲美。我们还在GLUE基准上获得了72.8的总体分数,明显优于之前最好成绩68.9。

总之,12个评测数据集上有9个我们的方法达到了最新的SOTA结果,在许多场景表现优异。结果表明,我们的方法在不同规模的数据集上均达到不错的效果,不论是STS-B(=5.7k训练样本)这样的小数据集,还是SNLI(≈550k训练样本)这样的大数据集。
分析
迁移层数影响 从无监督预训练到有监督目标任务,我们观察不同迁移层数的影响。图2展示了在MultiNLI和RACE上,我们方法效果和迁移层数之间的关系。我们观察到的结果是:迁移Embedding提升效果,在MultiNLI上对所有的transfer来说迁移层进一步提供9%效果。这表面预训练模型的每一层都包含对目标任务有价值的功能。

零样本行为 我们更容易理解为什么transformer的预训语言练模型是有效的。假设:底层的生成式模型学习执行我们评估的许多任务,以提升语言模型能力;相较于LSTM,transformer更结构化的注意力记忆有助于迁移。我们设计了一系列启发式解决方案,即使用底层生成式模型来执行任务,且不需要有监督微调。如图2所示,我们将启发式解决方案在生成式预训练过程中的效果可视化。我们发现启发式方案效果稳定,并随训练稳定增长,表明生成式预训练支持各种任务相关功能学习。我们也发现了LSTM在零样本效果上表现出更大的变动,表明transformer的归纳偏置有助于迁移学习。

对于CoLA(语言可接受性) 样本被用生成式模型分配的token对数概率的均值打分,并通过设定阈值预测
对于SST-2(情感分析) 我们给每个样本增加token,然后将语言模型的输入约束在正向词或者负向词,认为更高概率的作为预测结果。
对于RACE(问答) 在给定文档和问题条件下,我们选择生成式模型分配最高的token对数概率均值(对应的答案)作为答案。对于DPRD(威诺格拉德模式),我们用两个可能的指代词替换定义的代词,在替换后,预测结果,即生成式模型将更高的token对数概率分配给其余序列。
消融研究 我们进行了3种不同的消融研究(表5)。首先,在微调期间没有辅助语言模型目标,我们考查模型的效果。观察到辅助目标在NLI和QQP上有帮助。总的来说,表现为更大的数据集可以从辅助模型中获得收益,但是小一点的数据集不行。然后,通过将Transformer与使用相同结构的单层2048单元LSTM比较,我们分析Transformer效果。使用LSTM替换Transformer,我们观察到平均掉5.6分。只有在一个数据集MRPC上,LSTM比Transformer表现出色。最后,我们也和Transformer结构直接应用在有监督的目标任务上且不做预训练进行了比较。我们发现缺失预训练在所有任务上都降低了效果,相较于完整的模型降低了14.8%。
结论
我们介绍了一个框架,该框架通过单一的生成式预训练获得单一的无目标任务模型以及针对性的微调,可以获得强大的自然语言理解能力,通过在各种连续长文本预料上的预训练,我们的模型获得了大量的知识以及处理长依赖的能力,该能力被成功迁移解决多种任务,比如问答、语义相似判断、蕴含判断以及文本分类,提升了9个数据集(我们共研究12个)的SOTA。使用非监督(预)训练在不同任务上提效效果,在机器学习研究中已经是一个重要的目标。我们的研究结果表明:获得显著效果提升是可实现的,同时是提供了什么模型(Transformer)`和数据集(长依赖文本)使用这种方法效果更好的关系。我们希望这能有助于无监督学习的新研究,不论是自然语言理解还是其他领域,进一步提升我们理解非监督学习如何工作。
更多内容欢迎关注“机器爱学习”公众号~